论文笔记--AlpacaFarm: A Simulation Framework for Methods that Learn from Human Feedback
论文笔记--AlpacaFarm: A Simulation Framework for Methods that Learn from Human Feedback
- 1. 文章简介
- 2. 文章概括
- 3 文章重点技术
-
- 3.1 数据集
- 3.2 LPF(Learnig from pairwise feedback)自动学习人类偏好
- 3.3 自动评估方法
- 3.4 参考方法
- 4. 文章亮点
- 5. 原文传送门
1. 文章简介
- 标题:AlpacaFarm: A Simulation Framework for Methods that Learn from Human Feedback
- 作者:Dubois, Yann, et al.
- 日期:2023
- 期刊:arxiv preprint
2. 文章概括
文章给出了一种模拟人类反馈的模型框架,应用该框架,开发者可以以低于人工反馈45倍的成本对模型输出提供反馈。数值实验表明,文章提供的AlpacaFarm自动反馈方法和人类喜好非常相近,可被用于指令遵循和人类反馈学习等模型研究。
文章提出当前指令遵循模型和人类反馈学习任务面临着三个主要挑战:1) 数据标注昂贵:人类标注员需要对LLM模型的输出进行反馈(比如排序、二选一等),这个过程往往是耗时且昂贵的 2)缺乏自动评估方法:如何对指令遵循模型进行自动评估?3)缺乏参考实现:现有的参考方法哪些可作为可靠的参考?
文章的整体框架如下
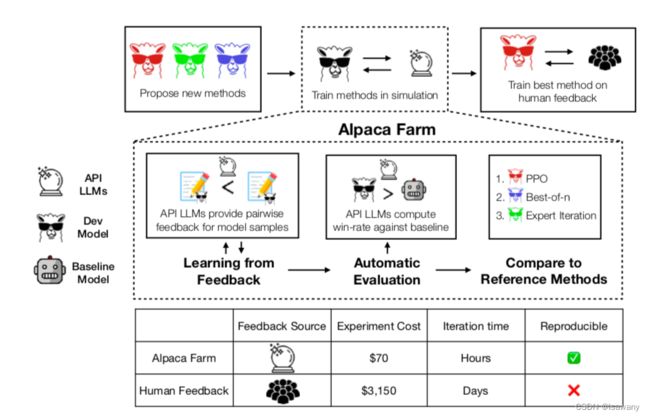
3 文章重点技术
3.1 数据集
文章采用了Alpaca data作为训练数据集,将其中10K的数据(SFT split)用于微调LLM。后续研究文章基于该数据集来学习人类反馈/偏好。
3.2 LPF(Learnig from pairwise feedback)自动学习人类偏好
首先简单介绍下LPF(Learnig from pairwise feedback)。给定样本 x x x和它对应的两个输出 y 0 , y 1 ∈ p θ S F T ( y ∣ x ) y_0, y_1 \in p_{\theta}^{SFT}(y|x) y0,y1∈pθSFT(y∣x),我们要学习到人类偏好:“人类认为这两个输出哪个更好”,即需要学习到一个无法观测的函数 R : X × Y → R \R: \mathcal{X}\times\mathcal{Y}\to \mathbb{R} R:X×Y→R。上述过程即LPF(从成对的输出中学习人类反馈)
现在我们从 p θ S F T p_{\theta}^{SFT} pθSFT中采样 ( x , y 0 ) (x, y_0) (x,y0)和 ( x , y 1 ) (x, y_1) (x,y1),LPF会学习到一个 z ∈ { 0 , 1 } z\in \{0, 1\} z∈{0,1}。 z = 0 z=0 z=0表示 y 0 y_0 y0优于 y 1 y_1 y1,即 R ( y 0 ) > R ( y 1 ) R(y_0)>R(y_1) R(y0)>R(y1), z = 1 z=1 z=1表示 y 1 y_1 y1优于 y 0 y_0 y0.
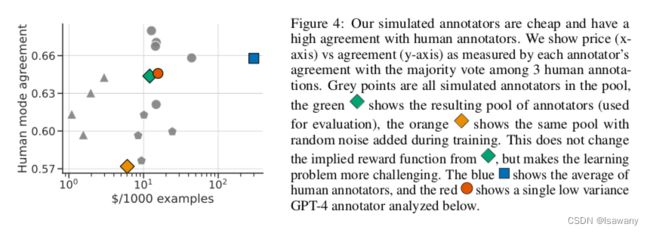
现在我们应用上述Alpaca数据来学习pairwise preferences,即学习一个模拟器 p s i m ( z ∣ x , y 0 , y 1 ) ∈ { 0 , 1 } p_{sim}(z|x, y_0, y_1)\in\{0, 1\} psim(z∣x,y0,y1)∈{0,1}。首先我们测试了GPT-4对人类偏好的捕捉情况,发现GPT-4和人类的偏好65%程度上一致,如下图所示,橙色的原点表示GPT-4和人类标注的一致性。
但我们发现GPT-4不能捕捉到人类标注的可变性(variability),可能造成奖励机制过拟合:见下图,当代理奖励升高时,人类模型(a)会升高直至一个点,但GPT-4会一直升高产生过拟合。
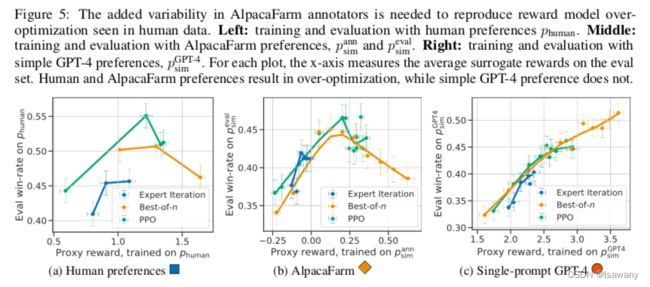
我们希望我们的模拟器更接近人类标注,从而我们通过下述两种方法来捕捉人类标注中的可变性:1)模拟标注员之间的inter-variability:通过访问多个API LLMs、变化prompts的不同形式、变换batch size和in-context示例来模仿一系列的标注员(而非单个);2)模拟标注员个人的intra-variablity:通过直接注入随机噪声,且以25%的概率反转偏好。
通过上述方法,我们得到了一个偏好模拟模型 p s i m a n n p_{sim}^{ann} psimann。在上面两个图中可以看到,我们模拟的偏好和人类偏好的agreement几乎和GPT-4持平,且代价更低;另一方面,我们的偏好很好地模拟了人类标注的可变性,不易产生对奖励的过拟合。
3.3 自动评估方法
为了评估大模型的指令,我们评估大模型LLM p θ p_{\theta} pθ相比于参考模型 p r e f p_{ref} pref的win-rate。所谓win-rate,即在多次实验中给定相同的 x x x, p θ p_{\theta} pθ得到的偏好被 p r e f p_{ref} pref偏爱的比例,win-rate ∈ [ 0 , 1 ] \in [0, 1] ∈[0,1]越高,表示 p θ p_{\theta} pθ模拟的效果越高。文本使用Davinci003作为参考模型。
有了评估方法,我们需要一份评估数据集。为此,文章从几个不同的开源评估数据集以及Alpaca demo的真实世界的交互数据。最终的数据集包含805个指令。
3.4 参考方法
最终,为了解决第三个挑战,文章选取了一系列的LPF方法:
- Binary FeedME:直接采用0/1标记每一个被评估的pair,在评估pair上进行微调
- Binary reward conditioning:对给定的偏好数据对,我们将正样本(被偏爱的)前增加一个token表示好它是被偏好的,如
prompt="prefered: {sentence}",负样本同样前增加一个token,如prompt="not prefered: {sentence}",在此基础上进行微调 - Best-of-n sampling:即每次生成n个答案,返回reward最高的输出
- Expert Itertation:在Best-of-n sampling基础上,通过上述reward最高的输出继续对模型做微调
- Proximal Policy Optimization(PPO):采用RL强化学习方法最大化代理奖励
- Quark:将序列按照奖励进行绑定,然后在最好的bin上进行训练
4. 文章亮点
文章给出了一种低成本的模拟人类反馈的方法,相比于GPT-4更能学习到人类标记员的可变性。AlpacaFarm可用于生成反馈数据以供指令遵循和人类反馈学习的模型训练。同时文章提出了一种自动评估不同模型输出质量的方法,且实验证明我们的方法和Alpaca Demo上的真实交互数据给出的评估结果高度相关(0.97 spearman corr)。
5. 原文传送门
AlpacaFarm: A Simulation Framework for Methods that Learn from Human Feedback
AlpacaFarm代码