各位读者无论是作为候选人还是面试官,想必对 “TCP 三步握手,四步挥手” 都烂熟于心了。
但是百闻不如一见,今天我们就来 在真实环境中把这个过程可视化,实地看一看,TCP的状态到底是如何转化的。
TL;DR
本文生成的结果如图:
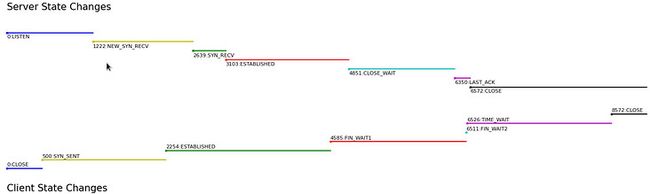
每一段代表一个状态,起始点是相对时间戳和状态名字。
环境
我们用一个 nginx 作为 server(server_ip:server_port),同时用 curl 作为 client,就有了一个简单的真实环境。
那么怎么观测TCP状态转移呢?
inet_sock_set_state
内核为我们提供了一个 tracepoint: inet_sock_set_state。这个 tracepoint 会在 TCP 状态发生变化的时候被调用,于是我们就有了 TCP 状态转移的观测点,这也是《用eBPF/XDP来替代LVS》系列 中使用的技巧。
用 ebpf/libbpf 写下来大概是这样:
SEC("tp_btf/inet_sock_set_state")
int BPF_PROG(trace_inet_sock_set_state, struct sock *sk,
int oldstate, int newstate){
const int type = BPF_CORE_READ(sk,sk_type);
if(type != SOCK_STREAM){//1
return 0;
}
const struct sock_common skc = BPF_CORE_READ(sk,__sk_common);
const struct inet_sock *inet = (struct inet_sock *)(sk);
return track_state((long long)sk,&skc,inet,oldstate,newstate);
}我们监听到状态转移事件后就可以从中提取这个连接的 4元组
static int track_state(long long skaddr,const struct sock_common *skc,
const struct inet_sock *inet,
int oldstate, int newstate){
__u32 dip = (BPF_CORE_READ(skc,skc_daddr));
__u16 dport = (BPF_CORE_READ(skc,skc_dport));
__u32 sip = (BPF_CORE_READ(inet,inet_saddr));
__u16 sport = (BPF_CORE_READ(inet,inet_sport));
return judge_side(skaddr,dip, dport, sip, sport,oldstate,newstate);
}然后依据4元组判断是哪个side
static int judge_side(long long skaddr,__u32 dip,__u16 dport,__u32 sip, __u16 sport,
int oldstate, int newstate){
enum run_mode m = ENUM_unknown;
// server might bind to INADDR_ANY rather than just server_ip
if((sip == server_ip || sip == INADDR_ANY) && sport == server_port){
m = ENUM_server;
fire_sock_release_event(m,oldstate,newstate);
}
else if(dip == server_ip && dport == server_port){
m = ENUM_client;
fire_sock_release_event(m,oldstate,newstate);
}
return 0;
}判断完毕后,将事件发送到用户空间
static void fire_sock_release_event(enum run_mode mode, int oldstate, int newstate){
struct event *e ;
e = bpf_ringbuf_reserve(&rb, sizeof(*e), 0);
if (!e){
return;
}
e->mode = mode;
e->oldstate = oldstate;
e->newstate = newstate;
e->ts = bpf_ktime_get_ns();
bpf_ringbuf_submit(e, 0);
}用户空间打印出来即可
static int handle_event(void *ctx, void *data, size_t data_sz){
const struct event *e = data;
fprintf(stderr, "ts:%llu:%s:%s:%s\n",
e->ts,mode2str(e->mode),state2str(e->oldstate),state2str(e->newstate));
return 0;
}加载程序后,发起请求:curl 172.19.0.2:80。结果:
ts:2220445792791:client:CLOSE:SYN_SENT
ts:2220446761789:client:SYN_SENT:ESTABLISHED
ts:2220447626787:server:LISTEN:SYN_RECV
ts:2220448026786:server:SYN_RECV:ESTABLISHED
ts:2220454118771:client:ESTABLISHED:FIN_WAIT1
ts:2220455075769:server:ESTABLISHED:CLOSE_WAIT
ts:2220455593768:server:CLOSE_WAIT:LAST_ACK
ts:2220456264766:client:FIN_WAIT1:FIN_WAIT2
ts:2220456525766:client:FIN_WAIT2:TIME_WAIT
ts:2220456623765:client:FIN_WAIT2:CLOSE
ts:2220456768765:server:LAST_ACK:CLOSE乍一看似乎没毛病,但是仔细看看,client 中断了连接,不是应该有 TIME_WAIT 这个状态吗?怎么直接就CLOSE了?
且看下文分析。
inet_timewait_sock
在内核源代码中搜索一下相关文件会发现,一个连接有多个 struct 来表示。对于 sock 来说,确实 FIN_WAIT2 后就 CLOSE 了,然后把 time_wait 委托给 inet_timewait_sock 这个 struct 来管理了。具体过程可以查看 tcp_time_wait 这个函数。
查看这个文件 inet_timewait_sock.h 我们大概就能找到一个连接进入和离开 time_wait 状态需要调用的函数了。
进入我们采用fexit,可以获得生成的 inet_timewait_sock 的结构体,便于和离开时作对比:
SEC("fexit/inet_twsk_alloc")
int BPF_PROG(inet_twsk_alloc,const struct sock *sk,struct inet_timewait_death_row *dr,
const int state,struct inet_timewait_sock *tw) {
const int type = BPF_CORE_READ(sk,sk_type);
if(type != SOCK_STREAM){//1
return 0;
}
const struct sock_common skc = BPF_CORE_READ(sk,__sk_common);
const struct inet_sock *inet = (struct inet_sock *)(sk);
const char oldstate = (BPF_CORE_READ(&skc,skc_state));
bpf_printk("tw_aloc,skaddr:%u,skcaddr:%u,twaddr:%u,oldstate:%s,newstate:%s",
sk,&skc,tw,state2str(oldstate),state2str(state));
track_state((long long)sk,&skc,inet,oldstate,state);
return 0;
}离开采用传统的kprobe即可
SEC("kprobe/inet_twsk_put")
int BPF_KPROBE(kprobe_inet_put,struct inet_timewait_sock *tw) {
const struct sock_common skc = BPF_CORE_READ(tw,__tw_common);
const int family = BPF_CORE_READ(&skc,skc_family);
if(family != AF_INET){
return 0;
}
// 省略 tw 对比代码
__u32 dip = (BPF_CORE_READ(&skc,skc_daddr));
__u16 dport = (BPF_CORE_READ(&skc,skc_dport));
__u32 sip = (BPF_CORE_READ(&skc,skc_rcv_saddr));
__u16 sport = bpf_htons(BPF_CORE_READ(&skc,skc_num));
return judge_side((long long)tw,dip, dport, sip, sport,oldstate,TCP_CLOSE);
}现在齐活了:
ts:2220445792791:client:CLOSE:SYN_SENT
ts:2220446761789:client:SYN_SENT:ESTABLISHED
ts:2220447626787:server:LISTEN:SYN_RECV
ts:2220448026786:server:SYN_RECV:ESTABLISHED
ts:2220454118771:client:ESTABLISHED:FIN_WAIT1
ts:2220455075769:server:ESTABLISHED:CLOSE_WAIT
ts:2220455593768:server:CLOSE_WAIT:LAST_ACK
ts:2220456264766:client:FIN_WAIT1:FIN_WAIT2
ts:2220456525766:client:FIN_WAIT2:TIME_WAIT
ts:2220456623765:client:FIN_WAIT2:CLOSE
ts:2220456768765:server:LAST_ACK:CLOSE
ts:2282464966825:client:TIME_WAIT:CLOSE2220456623765 这一条记录我们忽略即可。
可视化
数据有了,用 Python 画一下比较简单,最后可以得到这个图:
核心代码如:
plt.text(start, 1.20, f'Server State Changes',fontsize=15)
plt.plot(sx[:2], sy[:2], colors[0] + '-')
idx = timestamps.index(sx[1])
msg = old_states[idx]
plt.text(start, sy[0] + 0.01, f'({start}:{msg})',fontsize=fontsize)
plt.plot(start, sy[0], colors[0] + 's', alpha=0.5,markersize = markersize)
for i in range(1, len(sx)-1):
upward = (i/25)
plt.plot(sx[i:i+2], [sy[i]+upward,sy[i+1]+upward], colors[i] + '-')
idx = timestamps.index(sx[i])
msg = new_states[idx]
plt.text(sx[i], sy[i]+upward+0.01, f'({sx[i]}:{msg})',fontsize=fontsize)
plt.plot(sx[i], sy[i]+upward, colors[i] + 's', alpha=0.5,markersize = markersize)
plt.show()注:time_wait 状态占用时间非常长,影响展示,这里微调了一下。
TCP_NEW_SYN_RECV
细心的读者可能注意到,上面的时序似乎有点问题:
ts:2220445792791:client:CLOSE:SYN_SENT
ts:2220446761789:client:SYN_SENT:ESTABLISHED
ts:2220447626787:server:LISTEN:SYN_RECV
ts:2220448026786:server:SYN_RECV:ESTABLISHED
ts:2220454118771:client:ESTABLISHED:FIN_WAIT1
ts:2220455075769:server:ESTABLISHED:CLOSE_WAIT
ts:2220455593768:server:CLOSE_WAIT:LAST_ACK
ts:2220456264766:client:FIN_WAIT1:FIN_WAIT2
ts:2220456525766:client:FIN_WAIT2:TIME_WAIT
ts:2220456623765:client:FIN_WAIT2:CLOSE
ts:2220456768765:server:LAST_ACK:CLOSE
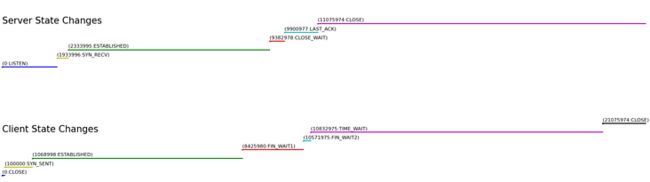
ts:2282464966825:client:TIME_WAIT:CLOSE为什么 client 的 ESTABLISHED 在 server 的 SYN_RECV 前面?
事实上,我的测试内核版本是 6.1.11,它包含了这个commit [https://github.com/torvalds/linux/commit/10feb428a5045d5eb18a5d755fbb8f0cc9645626], 及其系列 [https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linu...]。
所以测试内核中 TCP_SYN_RECV 已经不是原始 TCP 协议中 server 收到第一个 syn 包的状态了,取而代之的是 TCP_NEW_SYN_RECV,TCP_SYN_RECV 本身主要被用于支持 fastopen 特性了。
既然这样,我们怎么还原协议中的状态呢?经过一番检索,发现了这个方法:inet_reqsk_alloc,该方法是内核收到第一个 syn 包后,为连接分配 struct request_sock 这个轻量级数据结构表征的地方,于是我们可以进行追踪:
SEC("fexit/inet_reqsk_alloc")
int BPF_PROG(inet_reqsk_alloc,const struct request_sock_ops *ops,
struct sock *sk_listener,
bool attach_listener,struct request_sock *req ) {
__u64 ts = bpf_ktime_get_boot_ns();
const struct sock_common skc1 = BPF_CORE_READ(sk_listener,__sk_common);
const struct sock_common skc = BPF_CORE_READ(req,__req_common);
const int family = BPF_CORE_READ(&skc,skc_family);
if(family != AF_INET){
return 0;
}
const char oldstate = (BPF_CORE_READ(&skc1,skc_state));
const char newstate = (BPF_CORE_READ(&skc,skc_state));
__u32 dip = (BPF_CORE_READ(&skc1,skc_daddr));
__u16 dport = (BPF_CORE_READ(&skc1,skc_dport));
__u32 sip = (BPF_CORE_READ(&skc1,skc_rcv_saddr));
__u16 sport = bpf_htons(BPF_CORE_READ(&skc1,skc_num));
return judge_side(ctx,ts,(long long)req,dip, dport, sip, sport,oldstate,newstate);
}后面三步握手完成,为连接建立 struct sock 重量级数据结构表征的地方:tcp_v4_syn_recv_sock->tcp_create_openreq_child->inet_csk_clone_lock。
通过这个方法,我们可以将 inet_reqsk_alloc 中的状态转移和前文的 sock 关联起来:
SEC("fexit/inet_csk_clone_lock")
int BPF_PROG(inet_csk_clone_lock,const struct sock *sk,
const struct request_sock *req,
const gfp_t priority,struct sock * newsk) {
bpf_printk("csk_clone,lskaddr:%u,reqaddr:%u,skaddr:%u",
sk,req,newsk);
return 0;
}这样就完整了。可以得到下图,是不是就符合我们预期了:
注:内核中不支持修改 timewait 时间,图中将其缩小才方便展示,其余状态如实展示。
后记
我们在本文再次感受到了 ebpf 的强大,以前只能手工画图帮助我们理解 tcp 状态转移,现在可以依靠丰富的技术手段把这个过程自动化,而且是真实场景,给到你非常直观的感受。