【深度学习】pytorch pth模型转为onnx模型后出现冗余节点“identity”,onnx模型的冗余节点“identity”
情況描述
onnx模型的冗余节点“identity”如下图。
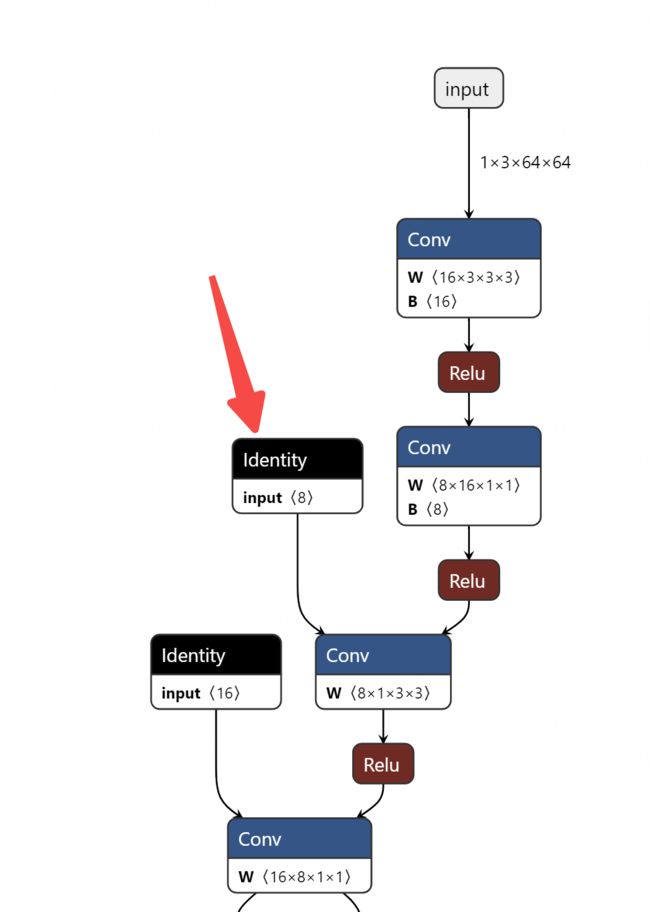
解决方式
首先,确保您已经安装了onnx-simplifier库:
pip install onnx-simplifier
然后,您可以按照以下方式使用onnx-simplifier库:
import onnx
from onnxsim import simplify
# 加载导出的 ONNX 模型
onnx_model = onnx.load("your_model.onnx")
# 简化模型
simplified_model, check = simplify(onnx_model)
# 保存简化后的模型
onnx.save_model(simplified_model, "simplified_model.onnx")
通过这个过程,onnx-simplifier库将会检测和移除不必要的"identity"节点,从而减少模型中的冗余。
请注意,使用onnx-simplifier库可能会改变模型的计算图,因此在使用简化后的模型之前,务必进行测试和验证以确保其功能没有受到影响。
问题原因
在将 PyTorch 模型转换为 ONNX 格式时,有时会出现冗余的"identity"节点的问题。这是因为 PyTorch 和 ONNX 在计算图构建和表示方式上存在一些差异。
在 PyTorch 中,计算图是动态构建的,其中包含了很多临时变量和操作。但在 ONNX 中,计算图是静态定义的,每个操作都显式地表示为一个节点。这种差异可能导致在将 PyTorch 模型转换为 ONNX 格式时引入一些不必要的中间"identity"节点。
一个常见的原因是,PyTorch 中的某些操作或模型结构在 ONNX 中没有直接的等价表示。为了保持模型结构的一致性,转换过程中可能会引入额外的"identity"节点,用于保留原始模型中的特定计算图结构或操作。
另外,有时候这些"identity"节点并不会对模型的性能或功能产生任何影响,它们只是在图形表示上引入了一些冗余。这些冗余节点在模型尺寸较小的情况下可能并不明显,但对于大型模型来说可能会显著增加模型文件的大小。
通过使用onnx-simplifier库,您可以对导出的 ONNX 模型进行后处理,去除这些不必要的"identity"节点,从而减少模型的冗余。
需要注意的是,由于 PyTorch 和 ONNX 之间的差异,无法完全避免所有的冗余节点。但大部分情况下这些冗余节点并不会对模型的性能或功能产生实质性的影响。
我的模型代码
import torch
from torch import nn
import torch.nn.functional as F
from torch.nn import init
class hswish(nn.Module):
def forward(self, x):
out = x * F.relu6(x + 3, inplace=True) / 6
return out
class hsigmoid(nn.Module):
def forward(self, x):
out = F.relu6(x + 3, inplace=True) / 6
return out
# 注意力机制
class SeModule(nn.Module):
def __init__(self, in_channel, reduction=4):
super(SeModule, self).__init__()
self.avgpool = nn.AdaptiveAvgPool2d(1)
self.fc1 = nn.Conv2d(in_channel, in_channel // reduction, kernel_size=1, stride=1, padding=0, bias=False)
self.bn = nn.BatchNorm2d(in_channel // reduction)
self.relu = nn.ReLU(inplace=True)
self.fc2 = nn.Conv2d(in_channel // reduction, in_channel, kernel_size=1, stride=1, padding=0, bias=False)
self.hs = hsigmoid()
def forward(self, x):
out = self.avgpool(x)
out = self.fc1(out)
out = self.bn(out)
out = self.relu(out)
out = self.fc2(out)
out = self.hs(out)
return x * out
# 线性瓶颈和反向残差结构
class Block(nn.Module):
def __init__(self, kernel_size, in_channel, expand_size, out_channel, nolinear, semodule, stride):
super(Block, self).__init__()
self.stride = stride
self.se = semodule
# 1*1展开卷积
self.conv1 = nn.Conv2d(in_channel, expand_size, kernel_size=1, stride=1, padding=0, bias=False)
self.bn1 = nn.BatchNorm2d(expand_size)
self.nolinear1 = nolinear
# 3*3(或5*5)深度可分离卷积
self.conv2 = nn.Conv2d(expand_size, expand_size, kernel_size=kernel_size, stride=stride,
padding=kernel_size // 2, groups=expand_size, bias=False)
self.bn2 = nn.BatchNorm2d(expand_size)
self.nolinear2 = nolinear
# 1*1投影卷积
self.conv3 = nn.Conv2d(expand_size, out_channel, kernel_size=1, stride=1, padding=0, bias=False)
self.bn3 = nn.BatchNorm2d(out_channel)
self.shortcut = nn.Sequential()
if stride == 1 and in_channel != out_channel:
self.shortcut = nn.Sequential(
nn.Conv2d(in_channel, out_channel, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(out_channel),
)
def forward(self, x):
out = self.nolinear1(self.bn1(self.conv1(x)))
out = self.nolinear2(self.bn2(self.conv2(out)))
out = self.bn3(self.conv3(out))
# 注意力模块
if self.se != None:
out = self.se(out)
# 残差链接
out = out + self.shortcut(x) if self.stride == 1 else out
return out
class MobileNetV3_Small_050(nn.Module):
def __init__(self):
super(MobileNetV3_Small_050, self).__init__()
self.conv1 = nn.Conv2d(3, 16, kernel_size=3, stride=2, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(16)
self.hs1 = nn.ReLU(inplace=True)
self.bneck = nn.Sequential(
Block(3, 16, 8, 16, nn.ReLU(inplace=True), SeModule(16), 2),
Block(3, 16, 40, 16, nn.ReLU(inplace=True), None, 2),
Block(3, 16, 56, 16, nn.ReLU(inplace=True), None, 1),
Block(5, 16, 64, 24, hswish(), SeModule(24), 2),
Block(5, 24, 144, 24, hswish(), SeModule(24), 1),
Block(5, 24, 144, 24, hswish(), SeModule(24), 1),
Block(5, 24, 72, 24, hswish(), SeModule(24), 1),
Block(5, 24, 72, 24, hswish(), SeModule(24), 1),
Block(5, 24, 144, 48, hswish(), SeModule(48), 2),
Block(5, 48, 288, 48, hswish(), SeModule(48), 1),
Block(5, 48, 288, 48, hswish(), SeModule(48), 1),
)
self.conv2 = nn.Conv2d(48, 288, kernel_size=1, stride=1, padding=0, bias=False)
self.bn2 = nn.BatchNorm2d(288)
self.hs2 = hswish()
self.avgpool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Linear(288, 6)
self.init_params()
def init_params(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
init.kaiming_normal_(m.weight, mode='fan_out')
if m.bias is not None:
init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
init.constant_(m.weight, 1)
init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
init.normal_(m.weight, std=0.001)
if m.bias is not None:
init.constant_(m.bias, 0)
def forward(self, x):
out = self.hs1(self.bn1(self.conv1(x)))
out = self.bneck(out)
out = self.hs2(self.bn2(self.conv2(out)))
out = self.avgpool(out)
out = out.view(-1, 288)
out = self.fc(out)
return out
class MobileNetV3_Small(nn.Module):
def __init__(self):
super(MobileNetV3_Small, self).__init__()
self.conv1 = nn.Conv2d(3, 16, kernel_size=3, stride=2, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(16)
self.hs1 = hswish()
self.bneck = nn.Sequential(
Block(3, 16, 16, 16, nn.ReLU(inplace=True), SeModule(16), 2),
Block(3, 16, 72, 24, nn.ReLU(inplace=True), None, 2),
Block(3, 24, 88, 24, nn.ReLU(inplace=True), None, 1),
Block(5, 24, 96, 40, hswish(), SeModule(40), 2),
Block(5, 40, 240, 40, hswish(), SeModule(40), 1),
Block(5, 40, 240, 40, hswish(), SeModule(40), 1),
Block(5, 40, 120, 48, hswish(), SeModule(48), 1),
Block(5, 48, 144, 48, hswish(), SeModule(48), 1),
Block(5, 48, 288, 96, hswish(), SeModule(96), 2),
Block(5, 96, 576, 96, hswish(), SeModule(96), 1),
Block(5, 96, 576, 96, hswish(), SeModule(96), 1),
)
self.conv2 = nn.Conv2d(96, 576, kernel_size=1, stride=1, padding=0, bias=False)
self.bn2 = nn.BatchNorm2d(576)
self.hs2 = hswish()
self.avgpool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Linear(576, 6)
self.init_params()
def init_params(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
init.kaiming_normal_(m.weight, mode='fan_out')
if m.bias is not None:
init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
init.constant_(m.weight, 1)
init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
init.normal_(m.weight, std=0.001)
if m.bias is not None:
init.constant_(m.bias, 0)
def forward(self, x):
out = self.hs1(self.bn1(self.conv1(x)))
out = self.bneck(out)
out = self.hs2(self.bn2(self.conv2(out)))
out = self.avgpool(out)
out = out.view(-1, 576)
out = self.fc(out)
return out
if __name__ == '__main__':
# from torchsummary import summary
# net = MobileNetV3_Small_050().train()
# summary(net, (3, 64, 64))
#
# from torchstat import stat
# net = MobileNetV3_Small_050().train()
# stat(net, input_size=(3, 64, 64)) # 输出模型的FLOPs和参数数量
# 转为onnx
import torch.onnx
dummy_input = torch.randn(1, 3, 64, 64)
net = MobileNetV3_Small_050().eval()
torch.onnx.export(net, dummy_input, "mobilenetv3_small_050.onnx", input_names=["input"], output_names=["output"],
opset_version=11, )