python实战|python爬取58同城租房数据并以Excel文件格式保存到本地
python实战|python爬取58同城租房数据并以Excel文件格式保存到本地
一、分析目标网站url
-
目标网站:https://cq.58.com/minsuduanzu/
-
让我们看看网站长啥样:
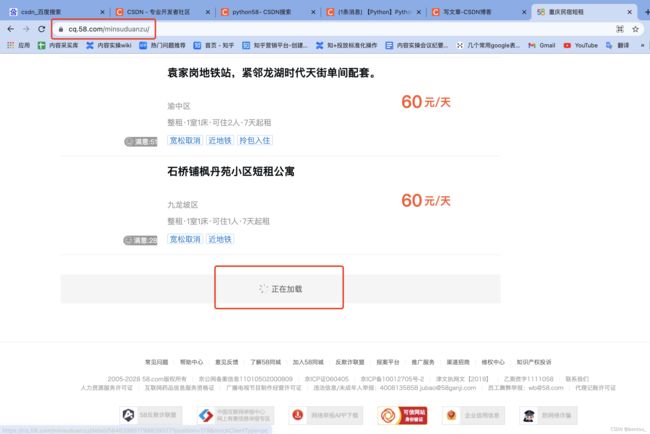
-
网站描述:
- 链接一直不变(爱了爱了
- 没有翻页设计,往下滑会无限加载(得想个办法 -
如何解决网页无限加载不好爬的问题?
- 团队经过讨论和参考一些博主的经验,选择了把网页先保存到本地再进行爬取。虽说是一个笨办法,但确实也是一个办法!
- 注:本方法适合所需数据不是超级大的那种(超过3k条建议另寻他法
二、代码
几个注意点⚠️:
- 本文导入的modules和其作用:requests(请求网页)、bs4的BeautifulSoup(解析html)、openpyxl的Workbook(处理excel表格)、time(页面停留)、random(随机函数)
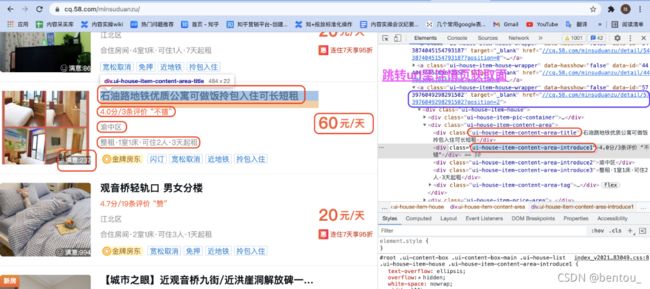
- 爬取的数据: ’短租房名称’, ‘短租房链接’, '短租房地址’, ‘短租房价格 元/日’, ‘短租房居住人数’, ’出租类型’, ’短租房户型’, ’面积/㎡’, ’用户评论数’, ’用户评分’, ’用户满意度"(除面积外均通过css类选择器获得
- 跳转url:爬取的数据中面积需要进到详情页获取数据,本文通过css类选择器,先从列表页获取跳转链接,再进入链接获取面积~
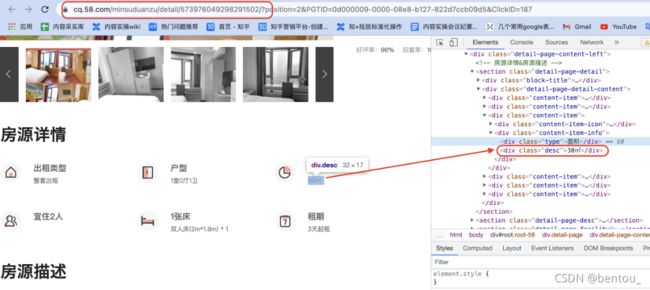
- 价格处理:通过if函数对单位为月的价格进行处理,使价格单位统一为日,便于比较
- 异常值处理:通过try…except函数对缺省值/异常值进行归0处理
- 代码优化:页面跳转时通过 time.sleep(random.random() * 3) 随机生成页面停留时间,从而模拟人的行为
import requests
from bs4 import BeautifulSoup
from openpyxl import Workbook
import time
import random
wb = Workbook() #创建一个workbook
def createSheetObj():
sheet = wb.active #获取当前workbook的第一个worksheet
sheet.title = "58同城" #worksheet的标题
sheet.append(['短租房名称', '短租房链接', '短租房地址', "短租房价格 元/日", "短租房居住人数","出租类型","短租房户型","面积/㎡","用户评论数","用户评分","用户满意度"]) #添加一行表头
return sheet
def getpage1(): #返回网页源码
path = '1.html'
htmlfile = open(path, 'r', encoding='utf-8') #打开1.html文件
htmlhandle = htmlfile.read() #返回整个文件
soup = BeautifulSoup(htmlhandle, "lxml") #使用Beautifulsoup解析
#print(soup)
return soup
def getPage(url):
# 伪造身份
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.18363'
}
resp = requests.get(url, headers=headers)
print(resp.status_code)
resp.encoding = "utf-8"
html = resp.text
soup = BeautifulSoup(html, "lxml")
return soup
def parsePage():
soup = getpage1()
i = 0
lis = soup.find_all("a", attrs={"class": "ui-house-item-house-wrapper"}) #找到所有li的链接地址
for li in lis:
print("第" + str(i) + "条")
i = i + 1
house_name = li.find('div',class_='ui-house-item-content-area-title').get_text()
house_href = 'http:' + li.get('href')
house_location = li.find('div',class_='ui-house-item-content-area-introduce2').get_text()
house_price = li.find('span', class_='ui-house-item-price-area-nowprice-price').get_text()
house_unit = li.find('span', class_='ui-house-item-price-area-nowprice-unit').get_text()
z = house_unit.split('/')
if(z[1] == "月"):
house_price = int(house_price) // 30
house_person_type_huxing = li.find('div', class_='ui-house-item-content-area-introduce3').get_text()
#合住房间·4室1床·可住1人·7天起租
x = house_person_type_huxing.split('·')
house_type = x[0]
house_huxing = x[1]
house_person = x[2][2] #第三个字
#异常/缺省值处理
try:
house_score_comments = li.find('div', class_='ui-house-item-content-area-introduce1').get_text()
y = house_score_comments.split('/')
house_score = y[0][0] + y[0][1] + y[0][2]
house_comments = y[1][0]
except:
house_score = 0
house_comments =0
try:
house_satisfy = li.find('div', class_='ui-house-item-pic-degreeofsatisfaction-number').get_text()
s = house_satisfy.split(':')
house_satisfy_num = s[1]
except:
house_satisfy_num = 0
try:
soup1 = getPage(house_href)
house_square = soup1.find_all('div',class_='desc')[2].get_text()
#print(house_square)
house_square = house_square.strip('㎡')
#print(house_square)
except:
house_square = 0
print(house_name,house_href,house_location,house_price,
house_person,house_type,house_huxing,house_square,house_comments,house_score,house_satisfy_num)
sheet.append([house_name,house_href,house_location,house_price,
house_person,house_type,house_huxing,house_square,house_comments,house_score,house_satisfy_num])
time.sleep(random.random() * 3) #模拟人的行为
if (i > 2000):
print("爬取结束")
break
wb.save("chongqing.xlsx") #将最终的结果导出到本地文件
sheet = createSheetObj()
parsePage()
*本文系重庆大学大数据应用导论课程赖王袁黄陆组的小组作业成果之一。