【困敦】探索RabbitMQ(二)-实战rabbitmq.client
如果这篇文章对您有些用处,请点赞告诉我O(∩_∩)O
序
本系列分三章探索实际应用中的RabbitMQ:
【困敦】探索RabbitMQ(一)--搭建高可用集群(HA)
【困敦】探索RabbitMQ(二)--实战rabbitmq.client
【困敦】探索RabbitMQ(三)--实战spring.amqp
开发rabbitmq常用客户端有两种,原生API,即com.rabbitmq.client,另一种是springboot集成包org.springframework.amqp。后者将一些技术细节以spring的方式(注解)封装起来,更加易用,如:增加了连接/信道管理、并发队列等功能。也正因如此,不适合入手学习rabbitmq,本章从原生API开始。
一、什么是rabbitmq
先了解AMQP(来自百度百科)
AMQP,即Advanced Message Queuing Protocol,一个提供统一消息服务的应用层标准高级消息队列协议,是应用层协议的一个开放标准,为面向消息的中间件设计。基于此协议的客户端与消息中间件可传递消息,并不受客户端/中间件不同产品,不同的开发语言等条件的限制。
AMQP和它的前辈JMS最大的不同就是前者是协议,支持多语言实现,而后者仅限于JAVA API。rabbitmq是AMQP的实现之一,本质是消息代理,负责接收并转发消息。在实际应用场景中的主要用作异步、解耦、消峰。让我们通过实际应用场景,去理解Producer,Consumer,Queue,Exchange,RoutingKey等。
二、应用场景-异步
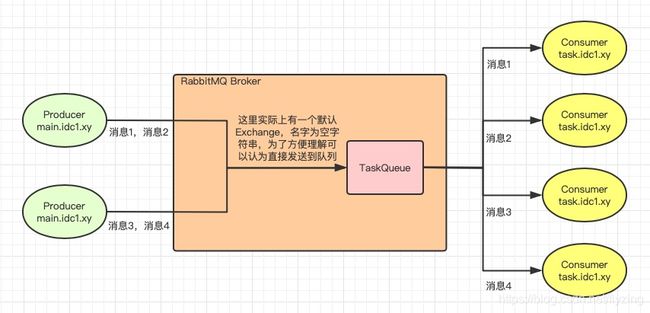
我们实际开发中,多用分布式架构,服务与服务之间通常通过接口连起来,也就是服务调用链。当服务调用链中,出现处理时间较长的服务时,我们就需要考虑将其单独封装为task异步处理,让主流程提前返回。(这里不是指页面ajax,而是服务异步)
流程图设计如下:
实现代码如下:
队列(Queue)负责在rabbitmq中暂存消息,声明队列就像创建数据库中的表,可以提前创建。(建议不要和发送消息放在一起)
public class QueueAdmin {
public final static String QUEUE_NAME = "TaskQueue";
public static Connection createConnection() throws Exception {
ConnectionFactory factory = new ConnectionFactory();
factory.setHost("192.168.56.102");
factory.setPort(6001);
factory.setUsername("admin");
factory.setPassword("admin");
return factory.newConnection();
}
public static void initQueue() throws Exception {
try(Connection connection = QueueAdmin.createConnection();
Channel channel = connection.createChannel();) {
//声明队列,参数:队列名称,队列是否持久化(不是队列中的数据持久化),是否排他,是否自动删除,其他参数(如过期时间、死信队列等) )
channel.queueDeclare(QUEUE_NAME, true, false, false, null);
System.out.println("初始化队列:" + QUEUE_NAME);
}
}
public static void main(String[] args) throws Exception {
QueueAdmin.initQueue();
}
}消费者(Consumer)负责接受并处理消息。
public class Consumer {
public void recevedMessage() throws Exception {
System.out.println("等待接收消息...");
Connection connection = QueueAdmin.createConnection();
Channel channel = connection.createChannel();
DefaultConsumer defaultConsumer = new DefaultConsumer(channel) {
@Override
public void handleDelivery(String consumerTag, Envelope envelope, AMQP.BasicProperties properties, byte[] body) throws IOException {
System.out.println("consumerTag: " + consumerTag);
String message = new String(body, "UTF-8");
doTask(message);
}
};
//定义消费者,参数:队列名称、是否自动应答、回调函数
channel.basicConsume(QueueAdmin.QUEUE_NAME, true, defaultConsumer);
}
public void doTask(String message) {
try {
Thread.sleep(5000);
System.out.println(message);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
public static void main(String[] args) throws Exception {
Consumer consumer = new Consumer();
consumer.recevedMessage();
}
}生产者(Producer)负责发送消息。
public class Producer {
public void doMainWork(int i) throws Exception {
System.out.println("处理主流程" + i);
sendMessage(i);
}
public void sendMessage(int i) throws Exception {
String message = "处理耗时任务" + i;
try(Connection connection = QueueAdmin.createConnection();
Channel channel = connection.createChannel();)
//发布消息,参数:交换机exchange,路由键routingKey,消息属性,消息体
channel.basicPublish("", QueueAdmin.QUEUE_NAME, MessageProperties.PERSISTENT_TEXT_PLAIN, message.getBytes("UTF-8"));
System.out.println("发送消息:" + message);
}
}
public static void main(String[] args) throws Exception {
Producer producer = new Producer();
for (int i = 0; i < 3; i++) {
producer.doMainWork(i);
}
}
}说明:
(1)观察流程图中消息1-4的走向,当一个队列有多个消费者时,默认情况下rabbitmq会按照顺序将每条消息发送到下一个消费者,使得每个消费者平均获得数量近似相同的消息,这称为Round-robin dispatching。由此可以推测,消费者越多能够同时消费的消息也越多。
(2)声明队列(QueueAdmin第17行)
//声明队列,参数:队列名称,队列是否持久化(不是队列中的数据持久化),是否排他,是否自动删除,其他参数(如过期时间、死信队列等) )
channel.queueDeclare(QUEUE_NAME, true, false, false, null);前两个参数好理解,主要看第3,4个参数,
exclusive:排他性,true是指该队列限制在当前Connection中使用,当前连接断开时,删除队列。
autoDelete:是否自动删除,true是指当不再使用此队列时,也就是所有客户端断开连接时,删除队列。
(3)定义消费者(Consumer第15行)
//定义消费者,参数:队列名称、是否自动应答、回调函数
channel.basicConsume(QueueAdmin.QUEUE_NAME, true, defaultConsumer);主要理解第2个参数autoAck:自动应答。如果为true,表示Consumer收到消息时自动应答,如果为false,在业务处理成功后,需要手动调用channel.basicAck手动应答。(后面介绍)
另外,消息在rabbitmq队列管理页面中有两种状态,ready,unacked。其实还有一种删除。状态流转如下:
消息从Producer产生发送到rabbitmq,状态为ready,再从rabbitmq转发给Consumer,状态改为unacked,最后消息被Consumer成功接收并应答。无论手动还是自动应答后,rabbitmq将消息删除。
(3)发布消息(Producer第12行)
//发布消息,参数:交换机exchange,路由键routingKey,消息属性,消息体
channel.basicPublish("", QueueAdmin.QUEUE_NAME, MessageProperties.PERSISTENT_TEXT_PLAIN, message.getBytes("UTF-8"));主要理解下第1~3参数,
exchange:交换机,routingKey:路由键
当exchange为空字符串时,表示默认交换机,此时路由键必须是目标队列。可以先简单理解为生产者直接向目标队列发送消息。(后面介绍)
props:消息属性,其中PERSISTENT_TEXT_PLAIN表示消息持久化。
三、应用场景-解耦
当一个主业务的服务调用链中,需要调用多个非主业务接口时,如记录日志、发送实时报表数据等。我们就需要考虑,能否将多个非主业务接口调用改为发布/订阅的消息模型,将其从主业务中剥离出来,这就是解耦。
第一步优化、我们尝试将调用日志接口和发送实时报表数据接口,改为消息发送。
channel.basicPublish("", "LogQueue", MessageProperties.PERSISTENT_TEXT_PLAIN, message.getBytes("UTF-8"));
channel.basicPublish("", "ReportQueue", MessageProperties.PERSISTENT_TEXT_PLAIN, message.getBytes("UTF-8"));
如此将非主业务接口调用改为发送消息,只是去掉了接口依赖,不会因为接口调用失败或超时影响主业务。但Producer和还是多个Queue耦合在一起,如果此时还需要发送监控数据,就得修改Producer增加发布一种消息。这并不是真正解耦,也不是发布订阅模式。
我们需要在Producer 和 Queue中间添加一个中间人,这就是Exchange。Producer只向Exchange发送消息,交换机(Exchange)负责从Producer中接收消息并推送到与之绑定的多个Queue中。
第二部优化,将多个队列消息发送,改为发送给交换机。
流程设计图如下:
代码实现如下:
public class QueueAdmin {
public final static String QUEUE_NAME1 = "LogQueue";
public final static String QUEUE_NAME2 = "ReportQueue";
public final static String EXCHANGE_NAME = "TestExchage2";
public static Connection createConnection() throws Exception {
ConnectionFactory factory = new ConnectionFactory();
factory.setHost("192.168.56.102");
factory.setPort(6001);
factory.setUsername("admin");
factory.setPassword("admin");
Connection connection = factory.newConnection();
return connection;
}
public static void initQueue() throws Exception {
try(Connection connection = QueueAdmin.createConnection();
Channel channel = connection.createChannel();) {
//声明交换机,参数:交换机名称,类型,是否持久化
channel.exchangeDeclare(EXCHANGE_NAME, "fanout",true);
//声明队列,参数:队列名称,队列是否持久化(不是队列中的数据持久化),是否排他,是否自动删除,
channel.queueDeclare(QUEUE_NAME1, true, false, false, null);
channel.queueDeclare(QUEUE_NAME2, true, false, false, null);
//保定队列,参数:队列名称,交换机名称,routingKey路由键
channel.queueBind(QUEUE_NAME1, EXCHANGE_NAME, "");
channel.queueBind(QUEUE_NAME2, EXCHANGE_NAME, "");
System.out.println("初始化交换机:"
+ EXCHANGE_NAME + ",队列:" + QUEUE_NAME1 + ", " + QUEUE_NAME2);
}
}
public static void main(String[] args) throws Exception {
QueueAdmin.initQueue();
}
}public class Producer2 {
public void doMainWork(int i) throws Exception {
System.out.println("处理主流程" + i);
sendMessage(i);
}
public void sendMessage(int i) throws Exception {
String message = "主流业务数据" + i;
try(Connection connection = QueueAdmin.createConnection();
Channel channel = connection.createChannel();) {
//发布消息,参数:交换机exchange,路由键routingKey,消息属性,消息体
channel.basicPublish(QueueAdmin.EXCHANGE_NAME, "", MessageProperties.PERSISTENT_TEXT_PLAIN, message.getBytes("UTF-8"));
System.out.println("发送消息:" + message);
}
}
public static void main(String[] args) throws Exception {
Producer producer = new Producer();
for (int i = 0; i < 3; i++) {
producer.doMainWork(i);
}
}
}public class LogConsumer {
public void recevedMessage() throws Exception {
System.out.println("等待接收消息...");
Connection connection = QueueAdmin.createConnection();
Channel channel = connection.createChannel();
DefaultConsumer defaultConsumer = new DefaultConsumer(channel) {
@Override
public void handleDelivery(String consumerTag, Envelope envelope, AMQP.BasicProperties properties, byte[] body) throws IOException {
System.out.println("consumerTag: " + consumerTag);
String message = new String(body, "UTF-8");
doTask(message);
}
};
channel.basicConsume(QueueAdmin.QUEUE_NAME1, true, defaultConsumer);
}
public void doTask(String message) {
System.out.println("记录日志:" + message);
}
public static void main(String[] args) throws Exception {
LogConsumer consumer = new LogConsumer();
consumer.recevedMessage();
}
}public class ReportConsumer {
public void recevedMessage() throws Exception {
System.out.println("等待接收消息...");
Connection connection = QueueAdmin.createConnection();
Channel channel = connection.createChannel();
DefaultConsumer defaultConsumer = new DefaultConsumer(channel) {
@Override
public void handleDelivery(String consumerTag, Envelope envelope, AMQP.BasicProperties properties, byte[] body) throws IOException {
System.out.println("consumerTag: " + consumerTag);
String message = new String(body, "UTF-8");
doTask(message);
}
};
channel.basicConsume(QueueAdmin.QUEUE_NAME2, true, defaultConsumer);
}
public void doTask(String message) {
System.out.println("生成实时报表数据:" + message);
}
public static void main(String[] args) throws Exception {
ReportConsumer consumer = new ReportConsumer();
consumer.recevedMessage();
}
}说明:
(1)什么是RoutingKey?
Producer将消息发送给Exchange,Consumer从Queue获取消息,这中间由Exchange将消息转发给Queue。
如果1个Exchange可以对应多个Queue,该如何确定将消息发送给哪些Queue呢?
答案是RoutingKey(路由键),类似于数据库中的多对多的中间表外键,负责绑定队列和交换机。
a、在声明Queue和Exchange后,将Queue和Exchange用RoutingKey绑定在一起。
//保定队列,参数:队列名称,交换机名称,routingKey路由键
channel.queueBind(QUEUE_NAME1, EXCHANGE_NAME, "");b、发布消息时,指明Exchange和RoutingKey,根据这两个值在上一步绑定关系中匹配到一个或多个队列发送。
(匹配规则根据交换机类型不同而不同)
//发布消息,参数:交换机exchange,路由键routingKey,消息属性,消息体
channel.basicPublish(QueueAdmin.EXCHANGE_NAME, "", MessageProperties.PERSISTENT_TEXT_PLAIN, message.getBytes("UTF-8"));(2)声明交换机时,指定其类型(QueueAdmin第20行)
//声明交换机,参数:交换机名称,类型,是否持久化
channel.exchangeDeclare(EXCHANGE_NAME, "fanout",true);第2个参数就是交换机类型,总共有四种:direct,fanout,topic,headers。这里介绍常用的前三种。
a、fanout:交换机将消息发送给与之绑定的所有队列。即无需匹配队列发送,那么RoutingKey对于fanout类型交换机也就无意义,因此设置为空字符串。
b、direct:设置RoutingKey发送消息,交换机将匹配与之绑定时指定的RoutingKey正确的队列发送。
channel.exchangeDeclare(EXCHANGE_NAME, "direct",true);//direct类型交换机
channel.queueBind(QUEUE_NAME1, EXCHANGE_NAME, "rk_test");//需要完全匹配rk_testchannel.basicPublish(QueueAdmin.EXCHANGE_NAME, "rk_test",
MessageProperties.PERSISTENT_TEXT_PLAIN, message.getBytes("UTF-8")); //指定rk_test发送消息c、topic:和direct类似,交换机也是向匹配RoutingKey正确的队列发送消息。区别在于direct是完全匹配,topic是格式匹配。
channel.exchangeDeclare(EXCHANGE_NAME, "topic",true);
channel.queueBind(QUEUE_NAME1, EXCHANGE_NAME, "com.xy.*"); //*匹配一个词
channel.queueBind(QUEUE_NAME2, EXCHANGE_NAME, "lazy.#"); //#匹配多个词channel.basicPublish(QueueAdmin.EXCHANGE_NAME, "com.xy.rk_test",
MessageProperties.PERSISTENT_TEXT_PLAIN, message.getBytes("UTF-8")); //指定com.xy.rk_test发送消息按照上面代码发送消息, 队列1接收到消息,而队列2没有。如果RoutingKey改为lazy.xy.rk_test,则队列2收到消息,队列1没有。
四、应用场景-消峰
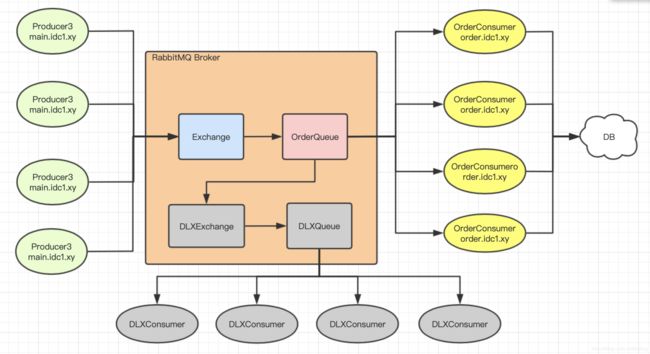
某一时段,大量用户请求涌入,当处理请求的速度远远低于请求产生的速度时,数据库连接会首先被占满,从而应用服务器连接也会被占满,后面产生的连接最后将无法访问。此时我们需要考虑能否将需要写入数据库的请求先暂存起来,按照数据库能够处理的速度,滞后处理,这就是消峰,
流程设计图如下:
 4000个并发写请求转换为4000条消息写入rabbitmq,rabbitmq单机吞吐量万级接收下消息没有问题,我们用4个Consumer消费,每个Consumer同时消费100个消息(默认情况下阻塞轮询方式执行,可以启用多线程增加吞吐量),如此对于DB的并发写压力最多也就400。由一开始4000并发写下降为十分之一,这就是消峰。(MYSQL连接池5.7中最大连接数16384,一般设置5000,不可能同时都给一个应用场景使用)
4000个并发写请求转换为4000条消息写入rabbitmq,rabbitmq单机吞吐量万级接收下消息没有问题,我们用4个Consumer消费,每个Consumer同时消费100个消息(默认情况下阻塞轮询方式执行,可以启用多线程增加吞吐量),如此对于DB的并发写压力最多也就400。由一开始4000并发写下降为十分之一,这就是消峰。(MYSQL连接池5.7中最大连接数16384,一般设置5000,不可能同时都给一个应用场景使用)
为了实现上面的设计,我们需要解决3个问题。
1、如何将OrderQueue中的消息“限流”到Consumer?(图中的400)
自动应答改为手动应答,并限制未消费消息数量。
public class OrderConsumer {
public void recevedMessage() throws Exception {
System.out.println("等待接收消息...");
Connection connection = com.example.mqtest2.QueueAdmin.createConnection();
Channel channel = connection.createChannel();
channel.basicQos(100); //quality of service Unacked状态消息最多100条
DefaultConsumer defaultConsumer = new DefaultConsumer(channel) {
@Override
public void handleDelivery(String consumerTag, Envelope envelope, AMQP.BasicProperties properties, byte[] body) throws IOException {
System.out.println("consumerTag: " + consumerTag);
try {
String message = new String(body, "UTF-8");
doOrder(message);
} finally {
//手动应答,参数:deliveryTag,multiple 如果为true表示到deliveryTag为止之前的消息统一应答
channel.basicAck(envelope.getDeliveryTag(), false);
}
}
};
channel.basicConsume(QueueAdmin.QUEUE_NAME2, false, defaultConsumer);
}
public void doOrder(String message) {
try {
Thread.sleep(5000);
System.out.println("处理订单:" + message);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
public static void main(String[] args) throws Exception {
OrderConsumer consumer = new OrderConsumer();
consumer.recevedMessage();
}
}说明:
(1)上文已经说过消息的多种状态(二、应用场景-异步的说明(3)),消息发送到队列中状态为ready,客户端接收消息状态为unacked,客户端应答后删除。现在我们需要限制的就是该信道没有消费完的消息数量,也就是限制unacked状态的消息数量。
channel.basicQos(100); //quality of service Unacked状态消息最多100条(2)在处理完业务后,需要手动应答,最好放在finally中。
//手动应答,参数:deliveryTag,multiple 如果为true表示到deliveryTag为止之前的消息统一应答
channel.basicAck(envelope.getDeliveryTag(), false); 两个参数都需要理解:
deliveryTag:每个信道每次接受到消息产生一个deliveryTag序号,从1开始,每次加1。
multiple:默认是false,表示消息逐个应答,如果设置为true,表示该信道内批量应答包含deliveryTag在内以及之前所有消息。
如果deliveryTag为5,multiple为true,则会将前面1~5批量应答,否则则是一一应答。
2、当每台Consumer有100个消息同时接收,如何处理并发?
答案并不理想,rabbitmq原生api并不会并发,而是按照顺序阻塞执行。为什么?
让我们看下channel.basicConsume源码的方法调用链:

由此可知核心方法是addWork。
public void addWork(Channel channel, Runnable runnable) { //每次mq发送消息给消费者会触发此方法
if (this.workPool.addWorkItem(channel, runnable)) { //在这里阻塞,第一次调用会唤醒channel执行execute,后面的调用只将回调方法加入回调队列,不执行execute
this.executor.execute(new WorkPoolRunnable()); //启动线程池执行回调队列,只在channel唤醒时执行,即同一时间只有一个线程在执行。
}
}public boolean addWorkItem(K key, W item) { //key是channel,item是回调方法
VariableLinkedBlockingQueue queue;
synchronized (this) {
queue = this.pool.get(key); //一个channel对应一个回调队列
}
// The put operation may block. We need to make sure we are not holding the lock while that happens.
if (queue != null) {
enqueueingCallback.accept(queue, item); //将新的runnable加入回调队列
synchronized (this) {
if (isDormant(key)) { //唤醒信道,返回true,如果已经唤醒(如已在ready),返回false
dormantToReady(key);
return true;
}
}
}
return false;
} private final class WorkPoolRunnable implements Runnable {
@Override
public void run() {
int size = MAX_RUNNABLE_BLOCK_SIZE;
List block = new ArrayList(size);
try {
Channel key = ConsumerWorkService.this.workPool.nextWorkBlock(block, size); //取出回调队列中的回调方法
if (key == null) return; // nothing ready to run
try {
for (Runnable runnable : block) { //循环执行回调方法
runnable.run();
}
} finally {
if (ConsumerWorkService.this.workPool.finishWorkBlock(key)) { //执行完在检查上面执行过程中,是否有新的回调方法加入回调队列
ConsumerWorkService.this.executor.execute(new WorkPoolRunnable()); //递归执行回调方法,不停检查回调队列。
}
}
} catch (RuntimeException e) {
Thread.currentThread().interrupt();
}
}
} 说明:
(1)第一次接受消息唤醒执行线程(同一时间最多只有1个),后面的消息只加入到阻塞队列并不会启动线程执行,在执行线程中从阻塞队列每次取出一批回调方法循环执行。执行完一批递归取出下一批执行。由此可知,消息在Consumer中按照顺序阻塞执行。
(2)既然如此,我们只能考虑在每个Consumer中自己开启线程池执行具体业务,加大吞吐量。另外SpringBoot集成的客户端中可以设置concurrency支持并发。
(3)同时注意并发打乱消息顺序,对某些需要保证消息顺序的业务场景,需要特殊处理,如:消息体需要加发送时间,在收到消息时,判断消息发送时间大于数据最近修改时间,否则为无效消息等。
3、当DB的压力转到rabbitmq的队列中时,如何处理消息积压?
按照流程图中设计,4000并发消息,同时被Consumer最大消费400条,如此DB压力是小了,但多余的3600条会暂存在OrderQueue中,短时间内可以将mq作为临时数据库,一旦消息积压到一定程度,如1000万条,我们估算一下此时发送一条消息多长时间才能被消费,1000 00000 * 5(每5s消费一条消息)/ 400(最多400并发一起消费)/ 3600(1小时3600秒)= 347 小时,也就是14天才能消费完,最糟糕的情况是如果当rabbitmq剩余磁盘空间小于200M时(默认),将会拒绝接受任何消息(消费端正常)。那么如何处理消息积压?
如此压力如果是普遍现象,只能固定增加Consumer数量和并发量,并优化消费一条消息的时间,从而提升消费效率。如果是突然现象,有两种方式缓解:
(1)设置死信队列,暂存数据库等待补偿
首先设置消息的过期时间TTL(Time to Live),如:600000(10分钟),并申请死信交换机DXL(Dead-Letter-Exchange),当消息过期,从正常队列转发到死信交换机。再配置死信队列绑定死信交换机(DXL),启用多个Consumer接收该死信队列消息,Consumer收到消息后不做任何业务处理,将消息暂存数据库,最后定时补偿(补发消息或直接调用接口)。注意死信队列和正常业务队列同时消费消息,无法保证消息顺序。
public class QueueAdmin {
public final static String QUEUE_NAME = "OrderQueue2";
public final static String EXCHANGE_NAME = "TestExchage4";
public final static String DXL_EXCHANGE_NAME = "DXLExchage";
public final static String DXL_QUEUE_NAME = "DXLQueue";
public final static String DXL_ROUTING_KEY = "DXLRoutingKey";
public static Connection createConnection() throws Exception {
ConnectionFactory factory = new ConnectionFactory();
factory.setHost("192.168.56.102");
factory.setPort(6001);
factory.setUsername("admin");
factory.setPassword("admin");
Connection connection = factory.newConnection();
return connection;
}
public static void initQueue() throws Exception {
try(Connection connection = QueueAdmin.createConnection();
Channel channel = connection.createChannel();) {
channel.exchangeDeclare(EXCHANGE_NAME, "fanout",true);
channel.exchangeDeclare(DXL_EXCHANGE_NAME, "direct",true);
Map args = new HashMap<>();
args.put("x-message-ttl", 600000); //过期时间
args.put("x-dead-letter-exchange", DXL_EXCHANGE_NAME); //死信交换机
args.put("x-dead-letter-routing-key", DXL_ROUTING_KEY); //死信路由键
//队列名称,队列是否持久化(不是队列中的数据持久化),是否排他,是否自动删除,
channel.queueDeclare(QUEUE_NAME, true, false, false, args);
channel.queueBind(QUEUE_NAME, EXCHANGE_NAME, "");
channel.queueDeclare(DXL_QUEUE_NAME, true, false, false, null);
channel.queueBind(DXL_QUEUE_NAME, DXL_EXCHANGE_NAME, DXL_ROUTING_KEY);
System.out.println("初始化交换机:"
+ EXCHANGE_NAME + ",队列:" + QUEUE_NAME);
}
}
public static void main(String[] args) throws Exception {
QueueAdmin.initQueue();
}
} public class DXLConsumer {
public void recevedMessage() throws Exception {
System.out.println("等待接收消息...");
Connection connection = com.example.mqtest2.QueueAdmin.createConnection();
Channel channel = connection.createChannel();
channel.basicQos(1);
DefaultConsumer defaultConsumer = new DefaultConsumer(channel) {
@Override
public void handleDelivery(String consumerTag, Envelope envelope, AMQP.BasicProperties properties, byte[] body) throws IOException {
System.out.println("consumerTag: " + consumerTag);
try {
String message = new String(body, "UTF-8");
execute(message);
} finally {
System.out.println("deliveryTag:" + envelope.getDeliveryTag());
channel.basicAck(envelope.getDeliveryTag(), false);
}
}
};
channel.basicConsume(QueueAdmin.DXL_QUEUE_NAME, false, defaultConsumer);
}
public void execute(String message) {
System.out.println("写入数据库等待消息补偿");
System.out.println("消息内容:" + message);
}
public static void main(String[] args) throws Exception {
DXLConsumer consumer = new DXLConsumer();
consumer.recevedMessage();
}
}(2)消息搬移
启用一个监控组件,每隔5分钟检查一次队列消息数量和大小是否超过阀值,如:消息数量超过1000w或者大小超过10g,如果超过阀值,启用搬运消费者,将消息从当前集群的积压队列搬运到备用集群队列中。如果低于阀值,关闭搬运消费者。最后两个集群同时增加消费机器加大消费效率。

public class MsgForwordMonitor {
private Connection connection;
private Channel channel;
//获取队列信息
public String getQueueInfo() throws Exception {
CloseableHttpClient httpClient = null;
CloseableHttpResponse response = null;
try {
CredentialsProvider provider = new BasicCredentialsProvider();
//HTTP basic authentication
UsernamePasswordCredentials credentials
= new UsernamePasswordCredentials("admin", "admin"); //登录mq控制台的用户名密码
provider.setCredentials(AuthScope.ANY, credentials);
httpClient = HttpClientBuilder.create().setDefaultCredentialsProvider(provider).build();
HttpGet httpGet = new HttpGet("http://192.168.56.102:15672/api/queues/%2F/ConfirmQueue");
response = httpClient.execute(httpGet);
HttpEntity responseEntity = response.getEntity();
if (responseEntity != null) {
BufferedReader br = new BufferedReader(
new InputStreamReader(responseEntity.getContent(), "UTF-8"));
StringBuffer buffer = new StringBuffer();
String line;
while ((line = br.readLine()) != null) {
buffer.append(line);
}
return buffer.toString();
}
} finally {
response.close();
httpClient.close();
}
return "";
}
//监控队列消息
public void monitor() throws Exception {
while(true) {
Thread.sleep(5 * 60000); //每5分钟检查一次
String queueInfo = getQueueInfo();
System.out.println("queueInfo:" + queueInfo);
Map queueInfoMap = new Gson().fromJson(queueInfo, HashMap.class);
Double msgCount = (Double) queueInfoMap.get("messages"); //消息数量
BigDecimal msgSize = new BigDecimal(queueInfoMap.get("message_bytes").toString()); //消息大小
BigDecimal size_1g = new BigDecimal(1024 * 1024 * 1024);
//如果消息数量超过1000万或大小超过10G,启用搬运消费者,将消息发送到备用集群队列,否则停用
if (msgCount > 5 || msgSize.compareTo(size_1g.multiply(BigDecimal.TEN)) > 0) {
enableMsgForword();
} else {
disableMsgForword();
}
}
}
//启动消息搬运
public void enableMsgForword() throws Exception {
if (connection == null && channel == null) {
System.out.println("启动消息搬运...");
connection = QueueAdmin.createConnection();
channel = connection.createChannel();
DefaultConsumer defaultConsumer = new DefaultConsumer(channel) {
@Override
public void handleDelivery(String consumerTag, Envelope envelope, AMQP.BasicProperties properties, byte[] body) throws IOException {
System.out.println("consumerTag: " + consumerTag);
String message = new String(body, "UTF-8");
System.out.println("搬运到备用集群,消息:" + message);
}
};
channel.basicConsume(QueueAdmin.QUEUE_NAME, true, defaultConsumer);
}
}
//关闭消息搬运
public void disableMsgForword() throws Exception {
System.out.println("停止消息搬运...");
if (channel != null) {
channel.close();
channel = null;
}
if (connection != null) {
connection.close();
connection = null;
}
}
public static void main(String[] args) throws Exception {
MsgForwordMonitor consumer = new MsgForwordMonitor();
consumer.monitor();
}
}说明:
(1)rabbitmq提供api接口查询各种信息,具体api说明:http://rabbitmq控制台ip:15672/api/index.html。
(2)查看队列信息的api为:/api/queues/vhost/name,示例中vhost是默认"/"转义后为%2F,因此查看ConfirmQueue队列信息的url为:
HttpGet httpGet = new HttpGet("http://192.168.56.102:15672/api/queues/%2F/ConfirmQueue");(3)由于调用rabbitmq api需要做基本的校验,httpclient的调用需要加入授权。
CredentialsProvider provider = new BasicCredentialsProvider();
//HTTP basic authentication
UsernamePasswordCredentials credentials
= new UsernamePasswordCredentials("admin", "admin"); //登录mq控制台的用户名密码
provider.setCredentials(AuthScope.ANY, credentials);
httpClient = HttpClientBuilder.create().setDefaultCredentialsProvider(provider).build();(4)实例中,我们只搬运了ConfirmQueue一个队列,实际可以通过/api/queues查看所有队列信息,判断出所有大于阀值的队列进行搬移,也可以使用Shovel插件搬运消息(Shovel插件使用不在本章)。注意以上设计提供思路,代码仅供参考。
五、防止消息丢失
发送消息相比传统的接口调用有异步、解耦、消峰等长处,但增加了调用链长度,出错的几率也会增大。如消息从Producer -> mq队列 -> Consumer,这个过程中有三处可能造成消息丢失。
1、消息从Producer转发到rabbitmq队列过程中丢失。
发送端增加Confirm监听解决。
public class Producer4 {
private TreeSet unconfirmSet = new TreeSet();
private Connection connection = null;
private Channel channel = null;
public void doConfirmWork() throws Exception {
try {
createConfirmChannel();
for (int i = 0; i < 3; i++) {
sendMessage(i);
}
} finally {
closeConfirmChannel();
}
}
public void sendMessage(int i ) throws Exception {
String message = "需要Confirm" + i;
long nextSeqNo = channel.getNextPublishSeqNo();
channel.basicPublish(QueueAdmin.EXCHANGE_NAME, "", MessageProperties.PERSISTENT_TEXT_PLAIN, message.getBytes("UTF-8"));
unconfirmSet.add(nextSeqNo);
System.out.println("发送消息..." + message);
}
public void createConfirmChannel() throws Exception {
connection = QueueAdmin.createConnection();
channel = connection.createChannel();
channel.confirmSelect();
channel.addConfirmListener(new ConfirmListener() {
@Override
public void handleAck(long deliveryTag, boolean multiple) throws IOException {
System.out.println("handleAck: deliveryTag="+ deliveryTag + ", multiple=" + multiple);
if (multiple) {
unconfirmSet.headSet(deliveryTag + 1).clear();
} else {
unconfirmSet.remove(deliveryTag);
}
}
@Override
public void handleNack(long deliveryTag, boolean multiple) throws IOException {
System.out.println("handleNack: deliveryTag="+ deliveryTag + ", multiple=" + multiple);
if (multiple) {
unconfirmSet.headSet(deliveryTag + 1).clear();
} else {
unconfirmSet.remove(deliveryTag);
}
}
});
}
public void closeConfirmChannel() {
new Thread(new Runnable() {
@Override
public void run() {
//全部确认或超过60s关闭连接和通道
long time = 0;
while (!(unconfirmSet.size() == 0 || time > 60000)) {
try {
Thread.sleep(1000);
time += 1000;
} catch (InterruptedException e) {
e.printStackTrace();
}
}
try {
if (channel != null) {
channel.close();
}
if (connection != null) {
connection.close();
}
} catch (Exception e) {
e.printStackTrace();
}
}
}).start();
}
public static void main(String[] args) throws Exception {
Producer4 producer = new Producer4();
producer.doConfirmWork();
}
} 说明:
(1)要想监听消息是否到达队列,代码其实非常简单。
channel.confirmSelect();
channel.addConfirmListener(new ConfirmListener() {
......
}(2)上面例子中之所以代码复杂,主要是由于关闭信道与连接时机,不能简单的通过finally关闭,如:
try(Connection connection = QueueAdmin.createConnection();
Channel channel = connection.createChannel();) {
......
}如果信道提前关闭,回调函数handleAck,handleNack将不会执行。因此我们需要在每次发送消息时,记录发送的deliveryTag:
unconfirmSet.add(nextSeqNo);然后在回调时,去掉已经确认的deliveryTag,这里注意,不是我们发送几次消息,mq就会confirm回调几次,如:发送deliverTag为1,2,3,4,5,mq回调可能只有一次deliveryTag为5,并且multiple为true,表示包含5之前的所有消息都已转发到队列,随之就需要将其所有deliveryTag从unconfirmSet去掉。当然也有可能是一条一条回调,此时multiple为false。
if (multiple) {
unconfirmSet.headSet(deliveryTag + 1).clear();
} else {
unconfirmSet.remove(deliveryTag);
}最后我们关闭信道和连接的时机就变为了unconfirmSet为空(都已确认)或者超时。
while (!(unconfirmSet.size() == 0 || time > 60000)) {2、消息已到达rabbitmq队列中正在消费,此时rabbitmq宕机重启后丢失。
(1)队列持久化
//队列名称,队列是否持久化(不是队列中的数据持久化),是否排他,是否自动删除,
channel.queueDeclare(QUEUE_NAME, true, false, false, null);(2)交换机持久化
//交换机名称,交换机类型,交换机持久化
channel.exchangeDeclare(EXCHANGE_NAME, "fanout",true);(3)消息持久化
//exchange名称,routingkey,消息持久化,消息
channel.basicPublish("", QueueAdmin.QUEUE_NAME, MessageProperties.PERSISTENT_TEXT_PLAIN, message.getBytes("UTF-8"));3、消息从队列转发到消费端过程中丢失。
使用手动应答方式解决,上文已经说明过。(四、应用场景-消峰-1)
//队列名称,是否自动应答,回调函数
channel.basicConsume(QueueAdmin.QUEUE_NAME, false, defaultConsumer);try {
......
} finally {
//手动应答,参数:deliveryTag,multiple 如果为true表示到deliveryTag为止之前的消息统一应答
channel.basicAck(envelope.getDeliveryTag(), false);
}4、rabbitmq没有配置死信队列,出现以下情况,消息丢失。
(1)消息被拒绝
(2)消息过期
(3)队列达到最大长度
配置死信队列以及如何处理死信的方式,上文已经说明过。(四、应用场景-消峰-3)
六、防止消息重复消费
接口超时需要重复调用,消息超时或其他原因同样需要重推,此时Producer会重复发送消息,Consumer也就会重复消费消息。我们通常使用幂等防止重复消费。
做幂等的方式同样有多种,这里采用Redis分布式锁,思路如下:
(1)消息体中包含唯一id msg_uniq_id
(2)接收到消息时,将msg_uniq_id做为key,从redis时尝试取出结果key = "msg_result_" + msg_uniq_id。
(3)如果value不为空表示,之前有请求过,返回上一次成功的结果。
(4)如果value为空,表示之前没有请求过,此时使用redis setnx方法,key="msg_uniq_" + msg_uniq_id。
(5)如果setnx成功,正常处理业务,成功后将结果存入redis,key = "msg_result_" + msg_uniq_id。处理业务异常,删除setnx的key。
(6)如果setnx失败,表示存在并发请求,只能一个成功,其他都失败,此时返回页面提示处理失败,请重试。
(7)setnx的key和存储结果的key都需要设置超时时间,setnx的key可以设置短一些,如3分钟,存储结果的key可以设置长一些,如24小时。
(未完)