详解浏览器渲染原理及流程
今天来分享一下浏览器的渲染原理及流程。
前言
先来看看 Chrome 浏览器的多进程架构:
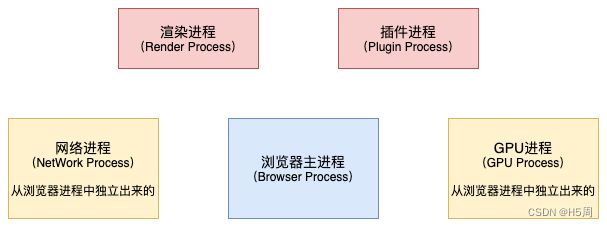
通常,我们打包出来的 HTML、CSS、JavaScript 等文件,经过浏览器运行之后就会显示出页面,这个过程就是浏览器的渲染进程来操作实现的,渲染进程的主要任务就是将静态资源转化为可视化界面:

对于中间的浏览器,它就是一个黑盒,下面就来看看这个黑盒是如何将静态资源转化为前端界面的。由于渲染机制比较复杂,所以渲染模块在执行过程中会被划分为很多子阶段,输入的静态资源经过这些子阶段,最后输出页面。我们将一个处理流程称为渲染流水线,其大致流程如下图所示:
![]()
这里主要包含五个过程:
● DOM树构建:渲染引擎使用HTML解析器(调用XML解析器)解析HTML文档,将各个HTML元素逐个转化成DOM节点,从而生成DOM树;
● CSSOM树构建:CSS解析器解析CSS,并将其转化为CSS对象,将这些CSS对象组装起来,构建CSSOM树;
● 渲染树构建:DOM 树和 CSSOM 树都构建完成以后,浏览器会根据这两棵树构建出一棵渲染树;
● 页面布局:渲染树构建完毕之后,元素的位置关系以及需要应用的样式就确定了,这时浏览器会计算出所有元素的大小和绝对位置;
● 页面绘制:页面布局完成之后,浏览器会将根据处理出来的结果,把每一个页面图层转换为像素,并对所有的媒体文件进行解码。
对于这五个流程,每一阶段都有对应的产物:DOM树、CSSOM树、渲染树、盒模型、界面。
下图为渲染引擎工作流程中各个步骤所对应的模块:
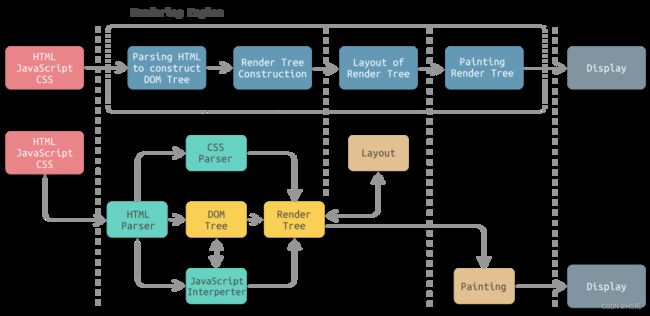
从图中可以看出,渲染引擎主要包含的模块有:
● HTML 解析器:解析HTML文档,主要作用是将HTML文档转换成DOM树;
● CSS 解析器:将DOM中的各个元素对象进行计算,获取样式信息,用于渲染树的构建;
● JavaScript 解释器:使用JavaScript可以修改网页的内容、CSS规则等。JavaScript解释器能够解释JavaScript代码,并通过DOM接口和CSSOM接口来修改网页内容、样式规则,从而改变渲染结果;
● 页面布局:DOM创建之后,渲染引擎将其中的元素对象与样式规则进行结合,可以得到渲染树。布局则是针对渲染树,计算其各个元素的大小、位置等布局信息。
● 页面绘制:使用图形库将布局计算后的渲染树绘制成可视化的图像结果。
DOM树构建
在说构建DOM树之前,我们需要知道,为什么要构建DOM树呢? 这是因为,浏览器无法直接理解和使用 HTML,所以需要将HTML转化为浏览器能够理解的结构——DOM树。
了解过数据结构的小伙伴对于树结构应该不陌生,树是由结点或顶点和边组成的且不存在着任何环的一种数据结构。一棵非空的树包括一个根结点,还有多个附加结点,所有结点构成一个多级分层结构。下面通过一张图来看看什么是树结构:
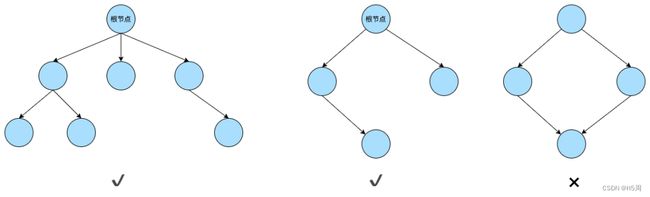
对于上面的三个结构,前两个都是树,他们都只有唯一的根节点,而且不存在环结构。而第三个存在环,所以就不是一个树结构。
在页面中,每个HTML标签都会被浏览器解析成文档对象。HTML本质上就是一个嵌套结构,在解析时会把每个文档对象用一个树形结构组织起来,所有的文档对象都会挂在document上,这种组织方式就是HTML最基础的结构——文档对象模型(DOM),这棵树的每个文档对象就叫做DOM节点。
在渲染引擎中,DOM 有三个层面的作用:
● 从页面的视角来看,DOM 是生成页面的基础数据结构;
● 从 JavaScript 脚本视角来看,DOM 提供给 JavaScript 脚本操作的接口,通过这套接口,JavaScript 可以对 DOM 结构进行访问,从而改变文档的结构、样式和内容;
● 从安全视角来看,DOM 是一道安全防护线,一些不安全的内容在 DOM 解析阶段会被拒之门外。
在渲染引擎内部,HTML 解析器负责将 HTML 字节流转换为 DOM 结构,其转化过程如下:

1. 字符流 → 词(token)
HTML结构会首先通过分词器将字节流拆分为词(token)。Token分为Tag Token 和文本 Token。下面来看一个HTML代码是如何被拆分的:
<body>
<div>
<p>hello world</p>
</div>
</body>
对于这段代码,可以拆成词:

可以看到,Tag Token 又分 StartTag 和 EndTag,、就是 StartTag ,、
这里会通过状态机将字符拆分成token,所谓的状态机就是将每个词的特征逐个拆分成独立的状态,然后再将所有词的特征字符合并起来,形成一个连通的图结构。那为什么要使用状态机呢?因为每读取一个字符,都要做一次决策,这些决策都和当前的状态有关。
实际上,状态机的作用就是用来做词法分析的,将字符流分解为词(token)。
2. 词(token)→ DOM树
接下来就需要将 Token 解析为 DOM 节点,并将 DOM 节点添加到 DOM 树中。这个过程是通过栈结构来实现的,这个栈主要用来计算节点之间的父子关系,上面步骤中生成的token会按顺序压入栈中,该过程的规则如下:
● 如果分词器解析出来是StartTag Token,HTML 解析器会为该 Token 创建一个 DOM 节点,然后将该节点加入到 DOM 树中,它的父节点就是栈中相邻的那个元素生成的节点;
● 如果分词器解析出来是 文本 Token,那么会生成一个文本节点,然后将该节点加入到 DOM 树中,文本 Token 是不需要压入到栈中,它的父节点就是当前栈顶 Token 所对应的 DOM 节点;
● 如果分词器解析出来的是EndTag Token,比如是 EndTag div,HTML 解析器会查看 Token 栈顶的元素是否是 StarTag div,如果是,就将 StartTag div从栈中弹出,表示该 div 元素解析完成。
通过分词器产生的新 Token 就这样不停地入栈和出栈,整个解析过程就这样一直持续下去,直到分词器将所有字节流分词完成。
下面来看看这的Token栈是如何工作的,有如下HTML结构:
<html>
<body>
<div>hello juejin</div>
<p>hello world</p>
</body>
</html>
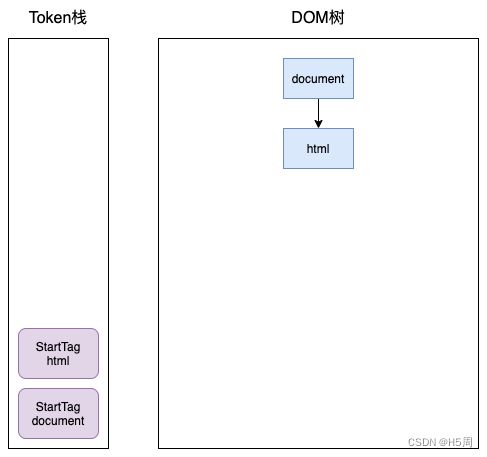
开始时,HTML解析器会创建一个根为 document 的空的 DOM 结构,同时将 StartTag document 的Token压入栈中,然后再将解析出来的第一个 StartTag html 压入栈中,并创建一个 html 的DOM节点,添加到 document 上,这时 Token 栈和 DOM树 如下:
接下来body和div标签也会和上面的过程一样,进行入栈操作:

随后就会解析到 div标签中的文本Token,渲染引擎会为该 Token 创建一个文本节点,并将该 Token 添加到 DOM 中,它的父节点就是当前 Token 栈顶元素对应的节点:

接下来就是第一个EndTag div,这时 HTML 解析器会判断当前栈顶元素是否是 StartTag div,如果是,则从栈顶弹出 StartTag div,如下图所示:
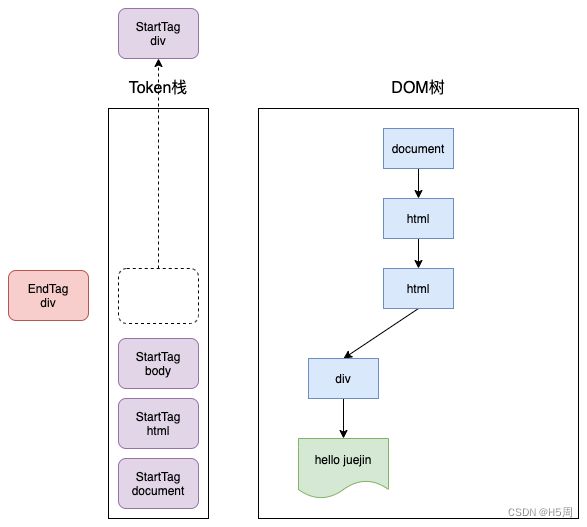
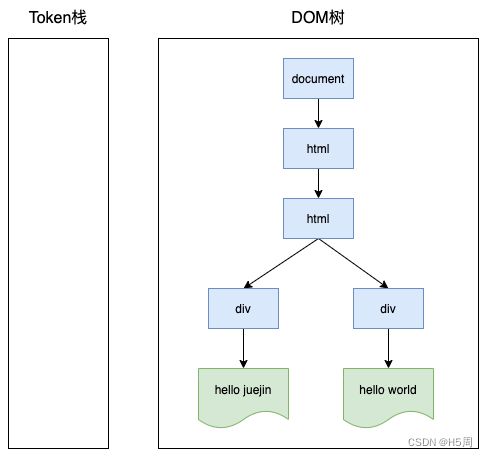
再之后的过程就和上面类似了,最终的结果如下:
CSSOM树构建
上面已经基本了解了DOM的构建过程,但是这个DOM结构只包含节点,并不包含任何的样式信息。下面就来看看,浏览器是如何把CSS样式应用到DOM节点上的。
同样,浏览器也是无法直接理解CSS代码的,需要将其浏览器可以理解的CSSOM树。实际上。浏览器在构建 DOM 树的同时,如果样式也加载完成了,那么 CSSOM 树也会同步构建。CSSOM 树和 DOM 树类似,它主要有两个作用:
● 提供给 JavaScript 操作样式的能力;
● 为渲染树的合成提供基础的样式信息。
不过,CSSOM 树和 DOM 树是独立的两个数据结构,它们并没有一一对应关系。DOM 树描述的是 HTML 标签的层级关系,CSSOM 树描述的是选择器之间的层级关系。可以在浏览器的控制台,通过document.styleSheets命令来查看CSSOM树:

那CSS样式的来源有哪些呢?

CSS样式的来源主要有三种:
● 通过 link 引用的外部 CSS 样式文件;
●