数学建模系列-预测模型(一)灰色预测模型
目录
1 灰色预测模型
1.1 灰色系统的定义与特点
1.2 灰色预测模型优缺点
1.3 灰色生成数列
1.4 灰色模型GM(1,1)实操步骤
1 数据检验
2 构建灰色模型
3 检验预测值
4 灰色预测模型实例代码
目前我们学习预测模型的第一类:灰色预测模型。
1 灰色预测模型
Gray Forecast Model 是通过少量的、不完全的信息,建立数学模型并给出预测的一种预测方法。
目前常用的一些预测方法(如回归分析等),需要较大的样本。若样本较小,则会造成较大误差,使预测目标失效。
灰色预测模型所需建模信息少,运算方便,建模精度高,在各种预测领域都有着广泛的应用,是处理小样本预测问题的有效工具.
1.1 灰色系统的定义与特点
灰色系统是黑箱概念的一种推广。我们把既含有已知信息又含有未知信息的系统称为灰色系统。
(1)用灰色数学处理处理不确定量,使之量化
(2)充分利用已知信息寻求系统的运动规律
(3)灰色系统理论能处理贫信息系统
1.2 灰色预测模型优缺点
适用范围:该模型使用的不是原始数据的序列, 而是生成的数据序列。 核心体系是 Grey Model, 即对原始数据作累加生成(或其他处理生成) 得到近似的指数规律再进行建模的方法。
优点:在处理较少的特征值数据, 不需要数据的样本空间足够大, 就能解决历史数据少、 序列的完整性以及可靠性低的问题, 能将无规律的原始数据进行生成得到规律较强的生成序列。
缺点:只适用于中短期的预测, 只适合近似于指数增长的预测。需要构建一阶常微分方程来求解拟合函数的函数表达式。
1.3 灰色生成数列
关键在于如何选择合适的方式去挖掘和利用事物的内在规律。一切灰色序列都能通过某种生成弱化其随机性,显现其规律。数据生成的常用方式有累加生成、累减生成和加权累加生成。
(1)累加生成(AGO)
设原始数列为x_0=[x_0(1),x_0(2).....x_0(n)],则x_1(k)=x_0(1)+x_0(2)+......+x_0(n)为原始数列的1次累加生成数列。

称为x_0的r次累加生成数列。
(2)累减生成(IAGO)
设原始数列为x_1=[x_1(1),x_1(2).....x_1(n)],则x_0(k)=x_1(1)+x_1(2)+......+x_1(n)是原始数列的1次累减生成数列。通过累加数列得到的数列可以通过累减生成还原成原始数列。
(3)加权邻值生成
设原始数列为x_1=[x_1(1),x_1(2).....x_1(n)],称任意一对相邻元素x_0(k-1),x_0(k)互为邻值。对于常数0 由此得到的数列称为邻值生成数,权a称为生成系数。当a=0.5时,则称数列为均值生成数。 建模前需要对数据进行检验,首先计算数列的级比 如果所有的级比都落在可容覆盖区间内 则数列可以进行灰色预测,否则需要对数据进行适当的变换处理,如平移等。 以下为数据检验的matlab代码: 定义x_1的灰导数为 令z_1(k)为数列x_1的邻值生成数列,即 于是定义GM(1,1)的微分方程模型为 用回归分析求得a、b的估计值,于是相应的白化模型为 解为 于是得到预测值 实操: 将k=1,2,3,,,n代入式子中得: 引入矩阵向量记号 于是GM(1,1)模型可表示为Y=Bu。 那么现在的问题是求a和b的问题,我们可以用一元线性回归,也就是最小二乘法求他们的估计值为: 以下是matlab代码: (一)残差检验:计算相对误差 如果所有得相对误差都小于0.1,则认为达到较高的要求。小于0.2,则达到一般要求。 (二)关联度检验 (三)方差比C检验 (四)小误差概率p检验 以下为matlab代码: 原始数据:A=[71.1 72.4 72.4 72.1 71.4 72.0 71.6]'
1.4 灰色模型GM(1,1)实操步骤
1 数据检验



%数据检验
function [G, params] = GM(A)
% G为预测数据,Q为相对残差Q检验,C为方差比C检验
% p为小误差概率p检验
%建立符号变量a(发展系数)和b(灰作用量)
% syms a b;
% c = [a u]';
n = length(A);
%% 级比检验
% 对原始数列 A 做累加得到数列 B
B = cumsum(A);
% 计算级比和光滑比
sig = zeros(1,n);
rho = zeros(1,n);
for i = 2:n
sig(i) = B(i)/B(i-1);
rho(i) = A(i)/B(i-1);
end
if sum(sig(4:end) >=2 ) == 0 && sum(rho(5:end) >= 0.5) == 0
disp('数据满足光滑条件和指数规律')
else
disp('数据不满足光滑条件和指数规律')
end2 构建灰色模型
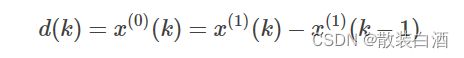




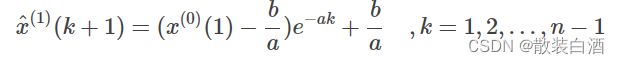
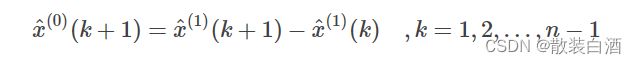



%% 数据预测
% 对数列 B 做紧邻均值生成
C = zeros(n,1);
for i = 2:n
C(i) = (B(i) + B(i - 1))/2;
end
C(1) = [];
% 构造数据矩阵
B = [-C,ones(n-1,1)];
Y = A; Y(1) = [];
% 使用最小二乘法计算参数 a(发展灰数)和b(内控制灰数)
c = inv(B'*B)*B'*Y;
a = c(1);
u = c(2);
% 预测后续数据
F(1) = A(1);
for i = 2:n+2 % 预测两年的数据
F(i) = (A(1)-u/a)/exp(a*(i-1))+ u/a;
end
% 对数列 F 累减还原,得到预测出的数据
G(1) = A(1);
for i = 2:n+2
G(i) = F(i) - F(i-1); %得到预测出来的数据
end
G = G';3 检验预测值
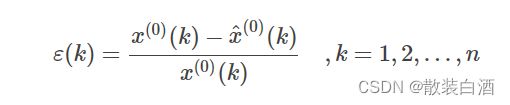
%% 精度检验
H = G(1:n);
% 计算残差序列
epsilon = A - H;
% 法一:相对残差Q检验(MAPE)
% 计算相对残差
delta = abs(epsilon./A);
% 计算相对误差平均值Q
Q = mean(delta);
% 计算所对应的的绝对误差百分比
MAPE = abs(sum(epsilon./A)/(n-1))*100;
% 法二:关联度检验
r = sum((min(min(abs(epsilon)))+0.5*max(max(abs(epsilon))))./(abs(epsilon)+0.5*max(max(abs(epsilon)))))/n;
% 法三:方差比C检验
C = std(epsilon, 1)/std(A, 1);
% 法四:小误差概率P检验
S1 = std(A, 1);
tmp = find(abs(epsilon - mean(epsilon))< 0.6745 * S1);
P = length(tmp)/n;
params = [a,u,r,C,P,MAPE];
end4 灰色预测模型实例代码
function [G, params] = GM(A)
% G为预测数据,Q为相对残差Q检验,C为方差比C检验
% p为小误差概率p检验
%建立符号变量a(发展系数)和b(灰作用量)
% syms a b;
% c = [a u]';
n = length(A);
%% 级比检验
% 对原始数列 A 做累加得到数列 B
B = cumsum(A);
% 计算级比和光滑比
sig = zeros(1,n);
rho = zeros(1,n);
for i = 2:n
sig(i) = B(i)/B(i-1);
rho(i) = A(i)/B(i-1);
end
if sum(sig(4:end) >=2 ) == 0 && sum(rho(5:end) >= 0.5) == 0
disp('数据满足光滑条件和指数规律')
else
disp('数据不满足光滑条件和指数规律')
end
%% 数据预测
% 对数列 B 做紧邻均值生成
C = zeros(n,1);
for i = 2:n
C(i) = (B(i) + B(i - 1))/2;
end
C(1) = [];
% 构造数据矩阵
B = [-C,ones(n-1,1)];
Y = A; Y(1) = [];
% 使用最小二乘法计算参数 a(发展灰数)和b(内控制灰数)
c = inv(B'*B)*B'*Y;
a = c(1);
u = c(2);
% 预测后续数据
F(1) = A(1);
for i = 2:n+2 % 预测两年的数据
F(i) = (A(1)-u/a)/exp(a*(i-1))+ u/a;
end
% 对数列 F 累减还原,得到预测出的数据
G(1) = A(1);
for i = 2:n+2
G(i) = F(i) - F(i-1); %得到预测出来的数据
end
G = G';
%% 精度检验
H = G(1:n);
% 计算残差序列
epsilon = A - H;
% 法一:相对残差Q检验(MAPE)
% 计算相对残差
delta = abs(epsilon./A);
% 计算相对误差平均值Q
Q = mean(delta);
% 计算所对应的的绝对误差百分比
MAPE = abs(sum(epsilon./A)/(n-1))*100;
% 法二:关联度检验
r = sum((min(min(abs(epsilon)))+0.5*max(max(abs(epsilon))))./(abs(epsilon)+0.5*max(max(abs(epsilon)))))/n;
% 法三:方差比C检验
C = std(epsilon, 1)/std(A, 1);
% 法四:小误差概率P检验
S1 = std(A, 1);
tmp = find(abs(epsilon - mean(epsilon))< 0.6745 * S1);
P = length(tmp)/n;
params = [a,u,r,C,P,MAPE];
end