【毕业设计】大数据房价数据分析可视化 - python
文章目录
- 0 前言
- 1 课题背景
- 2 数据爬取
-
- 2.1 爬虫简介
- 2.2 房价爬取
- 3 数据可视化分析
-
- 3.1 ECharts
- 3.2 相关可视化图表
- 4 最后
0 前言
Hi,大家好,这里是丹成学长的毕设系列文章!
对毕设有任何疑问都可以问学长哦!
这两年开始,各个学校对毕设的要求越来越高,难度也越来越大… 毕业设计耗费时间,耗费精力,甚至有些题目即使是专业的老师或者硕士生也需要很长时间,所以一旦发现问题,一定要提前准备,避免到后面措手不及,草草了事。
为了大家能够顺利以及最少的精力通过毕设,学长分享优质毕业设计项目,今天要分享的新项目是
大数据房价数据分析及可视化
学长这里给一个题目综合评分(每项满分5分)
- 难度系数:4分
- 工作量:4分
- 创新点:3分
选题指导, 项目分享:
https://gitee.com/yaa-dc/BJH/blob/master/gg/cc/README.md
1 课题背景
房地产是促进我国经济持续增长的基础性、主导性产业。如何了解一个城市的房价的区域分布,或者不同的城市房价的区域差异。如何获取一个城市不同板块的房价数据?
本项目利用Python实现某一城市房价相关信息的爬取,并对爬取的原始数据进行数据清洗,存储到数据库中,利用pyechart库等工具进行可视化展示。
2 数据爬取
2.1 爬虫简介
网络爬虫是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。爬虫对某一站点访问,如果可以访问就下载其中的网页内容,并且通过爬虫解析模块解析得到的网页链接,把这些链接作为之后的抓取目标,并且在整个过程中完全不依赖用户,自动运行。若不能访问则根据爬虫预先设定的策略进行下一个 URL的访问。在整个过程中爬虫会自动进行异步处理数据请求,返回网页的抓取数据。在整个的爬虫运行之前,用户都可以自定义的添加代理,伪 装 请求头以便更好地获取网页数据。
爬虫流程图如下:
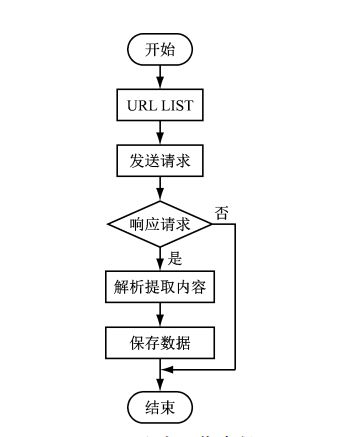
实例代码
# get方法实例
import requests #先导入爬虫的库,不然调用不了爬虫的函数
response = requests.get("http://httpbin.org/get") #get方法
print( response.status_code ) #状态码
print( response.text )
2.2 房价爬取
累计爬取链家深圳二手房源信息累计18906条
- 爬取各个行政区房源信息;
- 数据保存为DataFrame;
相关代码
from bs4 import BeautifulSoup
import pandas as pd
from tqdm import tqdm
import math
import requests
import lxml
import re
import time
area_dic = {'罗湖区':'luohuqu',
'福田区':'futianqu',
'南山区':'nanshanqu',
'盐田区':'yantianqu',
'宝安区':'baoanqu',
'龙岗区':'longgangqu',
'龙华区':'longhuaqu',
'坪山区':'pingshanqu'}
# 加个header以示尊敬
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.146 Safari/537.36',
'Referer': 'https://sz.lianjia.com/ershoufang/'}
# 新建一个会话
sess = requests.session()
sess.get('https://sz.lianjia.com/ershoufang/', headers=headers)
# url示例:https://sz.lianjia.com/ershoufang/luohuqu/pg2/
url = 'https://sz.lianjia.com/ershoufang/{}/pg{}/'
# 当正则表达式匹配失败时,返回默认值(errif)
def re_match(re_pattern, string, errif=None):
try:
return re.findall(re_pattern, string)[0].strip()
except IndexError:
return errif
# 新建一个DataFrame存储信息
data = pd.DataFrame()
for key_, value_ in area_dic.items():
# 获取该行政区下房源记录数
start_url = 'https://sz.lianjia.com/ershoufang/{}/'.format(value_)
html = sess.get(start_url).text
house_num = re.findall('共找到 (.*?) 套.*二手房', html)[0].strip()
print('{}: 二手房源共计「{}」套'.format(key_, house_num))
time.sleep(1)
# 页面限制 每个行政区只能获取最多100页共计3000条房源信息
total_page = int(math.ceil(min(3000, int(house_num)) / 30.0))
for i in tqdm(range(total_page), desc=key_):
html = sess.get(url.format(value_, i+1)).text
soup = BeautifulSoup(html, 'lxml')
info_collect = soup.find_all(class_="info clear")
for info in info_collect:
info_dic = {}
# 行政区
info_dic['area'] = key_
# 房源的标题
info_dic['title'] = re_match('target="_blank">(.*?)