简析集成学习算法
集成学习在第一次写关于决策树的时候简单提到过,所以今天来更详细的总结一下。
概念
集成学习(ensemble learning)是时下非常流行的机器学习算法,本身不是一个单独的机器学习算法,而是通过在数据上构建多个模型(称为基础模型或弱学习器)集成所有模型的建模结果。基本上所有的机器学习领域都可以看到集成学习的身影,在各种算法竞赛中,随机森林,梯度提升树(GBDT),Xgboost等集成算法应用也很广。
集成算法会考虑多个评估器的建模结果,得到一个综合的结果,以次达到比单个模型更好的回归或分类表现。
组成集成评估器的每个模型都叫做基评估器(弱学习器)
为什么叫弱学习器內?
因为在大多数情况下,这些基本模型本身的性能不是很好,要么具有较高的偏差,训练出来的模型在训练集上的准确度;要么方差太大,导致鲁棒性不强,模型容易过拟合。
通常来说,弱模型是偏差高(在训练集上准确率低)方差小(防止过拟合能力强)的模型。
分类:
通常有三类集成算法:
- 装袋法(Bagging)
基模型是相互独立的。从训练集进行子抽样组成多个基模型所需的子训练集,对所有基模型预测的结果进行综合(通常是进行平均或多数表决原则来决定集成评估器的结果)
典型代表模型就是随机森林。 - 提升法(Boosting)
基评估器是相关的,是按顺序构建的。基模型的训练集按照某种策略每次都进行一定的转化。核心是结合弱评估器的力量一次次对难以评估的样本进行预测,从而构成一个强评估器。
代表模型有Adaboost和梯度提升树。 - 堆叠法(stacking)

bagging 的重点在于获得一个方差比其组成部分更小的集成模型,而 boosting 和 stacking 则将主要生成偏差比其组成部分更小的强模型。
sklearn提供了sklearn.ensemble库,支持众多集成学习算法和模型。
Bagging
1. 随机森林
随机森林是非常具有代表性的Bagging集成算法。它的所有基评估器都是决策树,分类树组成的森林就叫做随机森林分类器,回归树所集成的森林就叫做随机森林回归器。
sklearn.ensemble.RandomForestClassifier类
参数
- 控制基评估器(决策树)的参数
和前面学习的决策树一样,只要是不纯度的衡量指标criterion和几个重要的剪枝参数.
- criterion
“entropy” -----信息熵(以信息熵为选择标准,选择信息熵差值最高的特征作为节点进行分枝。(信息熵是一个重要概念)
“gini" ------基尼系数 - random_state
值为数值型,用来设置随机模式的参数,可以让模型稳定下来。
下面是剪枝参数(防止树深度很深,划分过于精细,造成过拟合)
- max_depth-----限制树的最大深度
- min_samples_leaf-----限定一个节点在分枝后每个子节点必须至少包含min_samples_leaf个样本
- min_samples_spilt----一个节点必须包含min_samples_spilt个样本才可以被分枝。
单个决策树的准确率越高,随机森林的准确率也会越高,因为装袋法Bagging是依赖于平均值或者少数服从多数原则来决定集成的结果的。
- n_estimators
森林中树木的数量,即基基评估器的数量。通常n_estimators 越大,模型的效果往往越好。但是任何模型都有决策边界,n_estimators达到一定的程度之后,随机森林的精确性达到饱和,这时如果一昧地调大n_estimators会加大计算量,消耗内存也越大,训练的时间也会越来越长
下面试着建一片森林(用的是sklearn自带的乳腺癌的数据集)
from sklearn.datasets import load_breast_cancer from sklearn.ensemble import RandomForestClassifier from sklearn.model_selection import GridSearchCV from sklearn.model_selection import cross_val_score import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
data = load_breast_cancer()
#先简单的建立一个模型
rfc=RandomForestClassifier(n_estimators=100,random_state=90) score_pre =cross_val_score(rfc,data.data,data.target,cv=10).mean()

#下面开始利用学习曲线开始调参
#首先调整n_estimators(第一步),它对模型的准确度影响很大!!
scorel = []
for i in range(0,200,10):
rfc = RandomForestClassifier(n_estimators=i+1,
n_jobs=-1,
random_state=90)
score = cross_val_score(rfc,data.data,data.target,cv=10).mean()
scorel.append(score)
print(max(scorel),(scorel.index(max(scorel))*10)+1)
plt.figure(figsize=[20,5])
plt.plot(range(1,201,10),scorel)
plt.show()
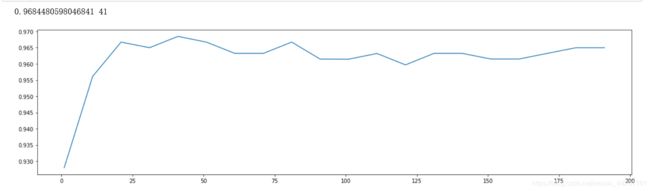
#得出一个范围,在这个范围里n_estimators取值开始变得平稳,而且一直推动模型整体准确率的上升。35-45
scorel = []
for i in range(35,45):
rfc = RandomForestClassifier(n_estimators=i,
n_jobs=-1,
random_state=90)
score = cross_val_score(rfc,data.data,data.target,cv=10).mean() scorel.append(score)
print(max(scorel),([*range(35,45)][scorel.index(max(scorel))])) plt.figure(figsize=[20,5])
plt.plot(range(35,45),scorel)
plt.show()
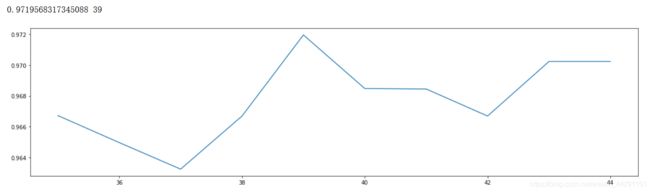
#最后调整好的参数
rfc = RandomForestClassifier(n_estimators=39,random_state=90) score = cross_val_score(rfc,data.data,data.target,cv=10).mean()
score

boosting
boosting核心思想是针对同一个训练集训练不同的学习算法,即弱学习器,然后将这些弱学习器集合起来,构造一个强学习器。
各弱学习器之间有强依赖关系。
代表的算法有AdaBoost和提升树。
- Adaboost
AdaBoost,即自适应增强:在每一次迭代中,前一个基本评估器中被错误分类的样本的权值会增大,而正确分类的样本的权值会减小,并加入一个新的弱分类器,直到达到某个足够小的错误率或最大迭代次数。
主要步骤如下:
-
首先需要选定一个弱学习算法 h 1 h_1 h1,初始训练集中每个样本权重相同,都为 1 n \frac{1}{n} n1,利用该训练集训练弱学习算法
-
第一次学习后,进行错误率的统计: 被 错 误 分 类 的 样 本 数 目 所 有 样 本 的 数 目 \frac{被错误分类的样本数目}{所有样本的数目} 所有样本的数目被错误分类的样本数目
-
根据错误率重新调整样本的权重,使得在第一分类中被错分的样本的权重增大,在接下来的学习中可以重点对其进行学习。同时利用错误率计算弱学习器的权重
-
然后利用更新权重后的样本和弱学习器进行下一次学习
-
这样迭代直到达到足够小的错误率或者最大迭代次数。。。