内存管理(三)——内存分页
前言
上一篇介绍了内存分段,这一篇将介绍内存分页。
分页管理
分页是把整个虚拟和物理内存空间切成一段段固定尺寸的大小。即划分逻辑地址空间至固定大小的页(Page),划分物理内存空间至固定大小的帧(Frame),并建立方案,转换逻辑地址为物理地址(pages to frames)。在 Linux 下,每一页的大小通常为 4KB。
页是连续的虚拟内存,帧是非连续的物理内存,不是所有的页都有对应的帧。
虚拟地址与物理地址之间通过页表来映射,页表是存储在内存里的,CPU 种的内存管理单元 (MMU,Memory Management Unit)就做将虚拟地址转换成物理地址的工作。
由于页的大小是固定的,就不会产生外部内存碎片问题,只有少量的内部碎片。
如果内存空间不够,操作系统会把其他正在运行的进程中的最近没被使用的内存页面给释放掉,也就是暂时写在硬盘上,一旦需要,再加载进来。所以,一次性写入磁盘的也只有少数的一个页或者几个页,不会花太多时间,内存交换的效率就相对比较高。
分页的方式使得我们在加载程序的时候,不再需要一次性都把程序加载到物理内存中。我们完全可以在进行虚拟内存和物理内存的页之间的映射之后,并不真的把页加载到物理内存里,而是只有在程序运行中,需要用到对应虚拟内存页里面的指令和数据时,再加载到物理内存里面去。
在分页机制下,虚拟地址分为两部分,页号和页内偏移。
由于每一页的 长度L 固定,所以可以根据 逻辑地址A 计算得到 页号P 和 段内偏移量W。
- P = A / L
- W = A mod L
页号作为页表的索引,页表包含物理页每页所在物理内存的基地址,这个基地址与页内偏移的组合就形成了物理内存地址。

页表条目
操作系统要为每个进程建立一张页表,页表通常在 PCB(进程控制块,Process Control Block) 中。在 32 位页表项中,高 20 位来存放页面的物理基地址,因此剩下的 12 位可用于存放属性信息。

- P–位 0 是存在(Present)标志,用于表示该虚拟页目前是否在物理内存中。1 表示存在;0 表示不存在。
- R/W–位 1 是读/写(Read/Write)标志。如果等于 1,表示页面可以被读、写或执行。如果为 0,表示页面只读或可执行。当处理器运行在超级用户特权级时,则R/W位不起作用。
- U/S–位 2 是用户/超级用户(User/Supervisor)标志。如果为1,那么运行在任何特权级上的程序都可以访问该页面。如果为 0,那么页面只能被运行在超级用户特权级上的程序访问。
- A–位 5 是已访问(Accessed)标志。当处理器访问页表项映射的页面时,页表项的这个标志就会被置为 1。处理器只负责设置该标志,操作系统可通过定期地复位该标志来统计页面的使用情况。
- D–位 6 是页面已被修改(Dirty)标志。当处理器对一个页面执行写操作时,就会设置对应页表项的 D 标志。
- AVL–该字段保留专供程序使用。处理器不会修改这几位,以后的升级处理器也不会。
页表的索引代表逻辑地址的页号。
当虚拟页不在物理内存中时,即第 0 位为 0 时,会存在以下两种情况:
- 从 1 位至 31 位为空,表示需要请求调页
- 从 1 位至 31 位至少有一位不为空,表示该页已经被换到硬盘中去了。此时,除 0 位外,其他位都用来表示在硬盘中的存储位置。即 1-7 被表示交换区的区号,8-31 位表示页槽索引。
多级页表
因为页表一定要覆盖全部虚拟地址空间,所以在 32 位的环境下,虚拟地址空间共有 4GB,假设一个页的大小是 4KB(2^12),那么就需要大约 100 万 (2^20) 个页,每个「页表项」需要 4 个字节大小来存储,那么整个 4GB 空间的映射就需要有 4MB 的内存来存储页表。每个进程都需要使用 4MB 的内存来存储页表,所以会占据比较大的内存空间。
因为二级页表项只有在需要的时候才会被创建。所以可以通过多级页表的方式解决空间问题,比如使用二级页表的方式,原本需要 100多万个页表项才能表示所有虚拟地址,现在就只需要 1024 个页表项了。

把二级分页推广到多级页表,就会发现页表占用的内存空间更少了。对于 64 位的系统,两级分页肯定不够了,就变成了四级目录。
TLB
多级页表虽然解决了空间上的问题,但是虚拟地址到物理地址的转换就多了几道转换的工序,带来了额外的时间开销。
但是可以利用程序的局部性原理,在 CPU 芯片中加入一个专门存放程序最常访问的页表项的 Cache,这个 Cache 就是 TLB(Translation Look-aside Buffer) ,通常称为页表缓存、转址旁路缓存、快表等。
TLB 存在于 CPU 中,属于 MMU 的一部分,可以简单地理解为页表的 Cache,其内容为部分页表的副本。
局部性原理
程序的局部性原理(Principle of locality):程序在执行过程中的一个较短时期,所执行的指令地址和指令的操作数地址,分别局限于一定区域。
- 时间局部性:一条指令的一次执行和下次执行,一个数据的一次访问和下次访问都集中在一个较短的时间内。
- 空间局部性:当前指令和邻近的几条指令,当前访问的数据和邻近的几个数据都集中在一个较小的区域内。
举个例子,比如你在玩飞机大战时,开始指令只在最开头执行一次,而移动飞机和发射炮弹进行射击这些指令,则在开始后一大段时间内持续地执行,这就体现了时间局部性。再比如一个数组是连续存储在一起的,所以顺序遍历时就具备空间局部性。
TLB失效
当访问的页面存在于 TLB 当中,则称为 TLB 命中,否则称为 TLB 失效。失效分为以下两种:
-
软失效(soft miss):物理页在内存中,但是不在 TLB 中,此时需要刷新 TLB,将物理页加入到 TLB 中。
-
硬失效(hard miss):物理页既不在内存中,也不在 TLB 中,则需要从磁盘中加载。此时会触发一个缺页中断,将原有的读取内存的线程阻塞,然后从磁盘中读取数据到内存中,再触发中断更新 TLB,并唤醒线程进入就绪队列等待执行。
如果 TLB 已经满了,则需要使用缓存置换算法选择一个已经存在的条目进行覆盖。常用的缓存置换算法为 LRU(Least Recently Used,最近最不常用算法)。
TLB设计
TLB 有三种常见的设计方式:
- 全相联映射:把所有缓存数据都放到一个数组里,每次查找时都遍历整个缓存。
- 直接映射:通过哈希函数进行映射,可以直接查询。但是由于哈希碰撞,所以可能产生冲突导致 TLB miss。不支持各种缓存置换算法。
- n 路组相联映射:把所有的 TLB 表项分成多个组,每个线性地址块对应一个 TLB 表项组。CPU 做地址转换时,首先计算线性地址块对应哪个 TLB 表项组,然后就可以在这个 TLB 表项组的 n 个位置中使用 LRU 算法进行置换。
8 路组相联映射是现在常用的方式。
缺页异常
在逻辑地址到物理地址的转换过程中,如果因某种原因导致无法访问到最终的物理内存单元,CPU 会产生一次缺页异常(Page Fault),从而进入缺页异常处理程序。
原因
- 导致缺页异常的线性地址不在进程的虚拟地址空间中。
- 线性地址在虚拟地址空间中,但是访问权限不足。
- 有访问权限,但是没有建立映射关系。(可能是第一次访问,需要建立映射关系)
- 有映射关系,但是页面不在物理内存中。(可能是换出到交换分区中了,需要换入)
- 页面在内存中。但是访问权限不够。
缺页中断
分页的方式使得我们在加载程序的时候,不再需要一次性都把程序加载到物理内存中。我们完全可以在进行虚拟内存和物理内存的页之间的映射之后,并不真的把页加载到物理内存里,而是只有在程序运行中,需要用到对应虚拟内存页里面的指令和数据时,再通过触发却也中断的方式加载到物理内存里面去。
在请求页面的过程中,如果访问的页面不在物理内存中,就会产生一次缺页中断,在外部存储器中找到所缺的页面并将其载入物理内存。具体过程如下:
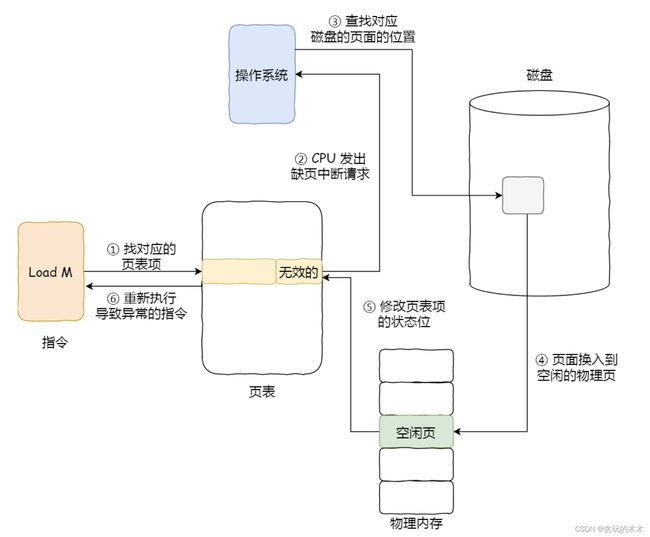
- 在 CPU 里访问一条 Load M 指令,然后 CPU 会去找 M 所对应的页表项。
- 如果该页表项的状态位是「有效的」,那 CPU 就可以直接去访问物理内存了;如果状态位是「无效的」,则 CPU 则会发送缺页中断请求。
- 操作系统收到了缺页中断,则会执行缺页中断处理函数,先会查找该页面在磁盘中的页面的位置。
- 找到磁盘中对应的页面后,需要把该页面换入到物理内存中,但是在换入前,需要在物理内存中找空闲页,如果找到空闲页,就把页面换入到物理内存中。
- 页面从磁盘换入到物理内存完成后,则把页表项中的状态位修改为「有效的」。
- 最后,CPU 重新执行导致缺页异常的指令。
再加上 TLB 和考虑内存是否已满,整个分页管理的过程如下:

其实这张图还不够完整,比如并没有考虑到 TLB 满了需要置换的情况等。
缺页中断是由硬件所产生的一种特殊的中断,与一般的中断存在区别:
- 在指令执行期间产生和处理缺页中断信号
- 一条指令在执行期间,可能产生多次缺页中断
- 缺页中断返回是执行产生中断的指令,而一般的中断返回是执行下一条指令。
总结
内存分页是把物理内存和虚拟内存都分成大小固定且相等的页进行使用,从而解决了内存分段有外部碎片的问题。
可以通过多级页表的方式减小页表所占的内存空间,但是太多级页表会降低地址转换的效率。
由于程序存在局部性,所以在 CPU 的 MMU 中设置了 TLB,即页表的缓存来加速常用的页表项的转换。
另外,给进程分配虚拟内存空间时,并不会直接分配所有的物理内存,而是在进程第一次使用页的时候触发缺页中断,进行内存映射,并将数据和代码载入内存中。