实现代理IP的自动获取
前言:
作者简介:我是Morning,计算机的打工人,想要翻身做主人
个人主页:Morning的主页
系列专栏::Morning的Python专栏
如果小编的内容有欠缺或者有改进,请指正拙著。期待与大家的交流
如果感觉博主的文章还不错的话,点赞 + 关注 + 收藏

目录
一.代理IP
1.为什么要使用代理:
2.请求过程:
无代理
有代理
3.代理分类:
3.1透明代理:
3.2匿名代理:
3.3高匿代理:
4.IP的使用方法
4.1 IP的语法
4.2 IP的获取
4.3 其他情况的出现
5.超时参数
6.通过代码实现IP的自动获取
二.SSL报错
正文
一.代理IP
1.为什么要使用代理:
1.让网站服务器认为不是同一个客户端在请求
2.防止我们的真实地址被泄露,防止被服务器认出同一个的用户身份,导致被反爬的几率大大提高
2.请求过程:
无代理
数据(请求响应)
由用户发起请求,直接到达服务器
服务器也是直接将响应返回到用户
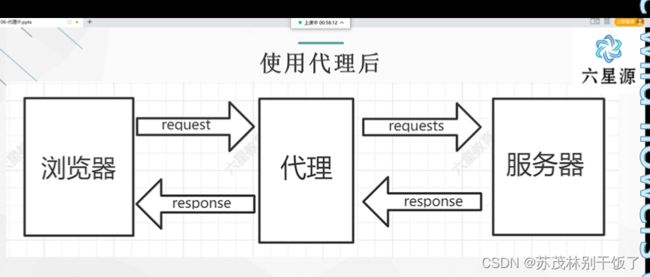
有代理
用户发起请求➡️代理服务器(转发)➡️网站服务器
网站服务器➡️代理服务器➡️(转发) ➡️用户
使用代理之后,请求或响应可能发生变化
当代对于请求的改变,情况不多
3.代理分类:
3.1透明代理:
透明代理虽然可以直接“隐藏”你的IP地址,但是还是可以查到你是谁
3.2匿名代理:
使用匿名代理,别人只能知道你使用了代理,无法知道你是谁
3.3高匿代理:
高匿代理让别人根本无法发现你是在使用代理,所以是最好的选择
平台上获取的代理IP一般都有有效期,短则几分钟,长则几个月甚至一年,爬虫会经常性的修改代理IP,所以一般选择几分钟的代理IP即可。
4.IP的使用方法
4.1 IP的语法
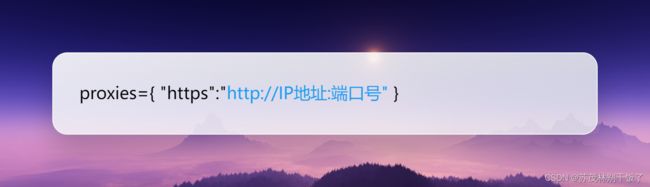
proxies={
"https":"http://IP地址:端口号",
"https":"http://IP地址:端口号",
} #在有些情况中http会自动跳转为https,所以写成这种形式可以避免这种自动跳转造成的报错如果url的协议头是http,那么proxies字典中的键就要写为http。
但是不管是http键还是https键,值必须都为http
完整使用
headers={"User-Agent":""}
proxies={"https":"http://IP地址:端口号"}
response=requests.get(url,headers=headers,proxies=proxies)
print(response.content.decode())4.2 IP的获取
我们可以在一些网站上找到代理IP,但是那些免费的可靠性很低,100个中都不一定能有一个是有效的。
所以还是推荐在一些收费网站上找代理IP,天启, API获取-芝麻HTTP代理 (zmhttp.com) 都是可以的。而且收费也不高。我使用的是芝麻IP用来举例。
在注册账号之后获取IP链接
打开链接后就可以得到IP
使用此代码运行后便可以成功获取到该页面的文本内容。
import requests
import re
headers={"User-Agent":"User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36 Edg/106.0.1370.42"}
url="https://www.zmhttp.com/getapi/"
# proxies={"https://http"+"IP"}
proxies={"https":"http://113.235.65.147:4251"}
response=requests.get(url,headers=headers,proxies=proxies)
print(response.content.decode())4.3 其他情况的出现
在获取到链接之后直接转到该链接,可能会出现以下情况
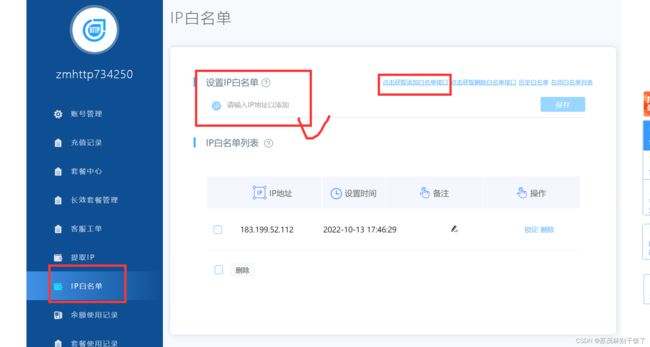
4.3.1

需要复制IP然后在获取IP的网站个人中心➡️白名单➡️添加,将复制的IP添加到白名单,再次转到生成的链接便可以获取到完整的代理IP了
各个网站的操作都是大同小异
4.3.2 代理不可用
如果出现错误提示:

这个就代表着是IP地址不可用,在我们复制的链接页面进行刷新,IP地址也会刷新,然后在进行尝试。
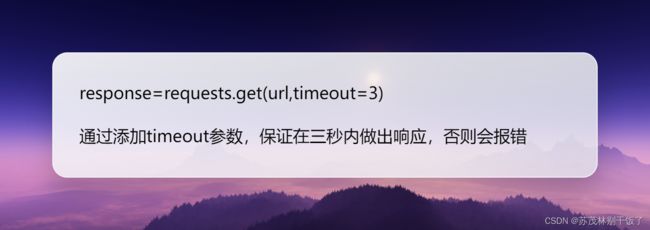
5.超时参数
6.通过代码实现IP的自动获取
有一个新的问题,那就是一直请求,一直换新的IP地址就很烦。
我们学计算机可不是做无味的重复动作的,是用来偷懒的
下面用代码来一步一步实现简化IP代理的替换:
import requests
import re
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36 Edg/106.0.1370.42'}
url='https://www.zmhttp.com/getapi/'
proxies={
"https":"http://IP地址:端口号"
}
#通过循环来一直获取IP直到IP可用
while 1:
try:
response = requests.get(url, headers=headers, proxies=proxies, timeout=3) #此处的url为我们要请求的url
print(response.content.decode())
#如果请求失败就去请求新的IP
except:
response=requests.get(url,headers=headers) #此处的url为我们在收费网站获取到的url
print(response.content.decode()) #获取新的IP
str_ip = response.content.decode()
#白名单添加逻辑
if '白名单' in str_ip: #判断是否需要新的白名单
write_ip=re.findall('\{"code":1010,"msg":"当前IP\((.*?)\)不在白名单内,请先设置IP白名单或联系客户经理"\}',str_ip)[0]
#通过正则提取出需要的IP,提取出的为一个集合,所以只需要第一个元素
print(write_ip)
requests.get(url=f'https://wapi.http.linkudp.com/index/index/save_white? neek=2208310&appkey=386af49701f1b0b7a57e4a5b084f5086&white={write_ip})',headers=headers) #此处的url为我们在收费网站找到的白名 单接口,并且将url中的ip改为write_ip
proxies["https"]="http://"+str_ip.strip() #消除str_ip前后的空格
print(str_ip) #看一下我们获取到的IP可以让我们知道有时候的代理不可使用是因为需要添加新的白名单
continue
else:
print("该代理可以使用")
break此例中正则的实现:
{"code":1010,"msg":"当前IP(175.9.141.204)不在白名单内,请先设置IP白名单或联系客户经理"}
先将{}与()取消转义,在其前面添加\
然后再将175.9.141.204改为(.*?)
有人可能有疑问,为什么我们获取到的IP就是纯数字呀,为什么还需要使用正则呢?
注意!!当出现白名单提示时,无论循环多少次都只会是无效IP,需要使用正则先将我们需要的IP给提取出来。
那我们为什么又要使用strip方法呢?
我们可以直接打印代理IP的字节码print(response.content)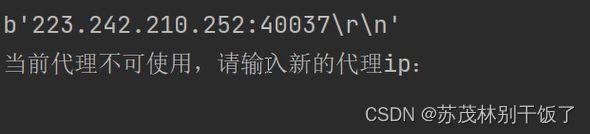
我们就会发现后面还有\r\n。注意!!那些空格,回车我们都是用肉眼看不到的,这些空格也会被代码直接认为是IP。所以导致IP不可用。
如果感觉太麻烦也可以使用笨方法来一个一个手动添加
except:
response = requests.get(url, headers=headers) # 此处的url为我们在收费网站获取到的url
print(response.content.decode()) # 获取新的IP
proxies["https"]="http://"+input("代理IP不可用,请输入新的代理IP")二.SSL报错
这是在浏览某些网站时会出现的情况
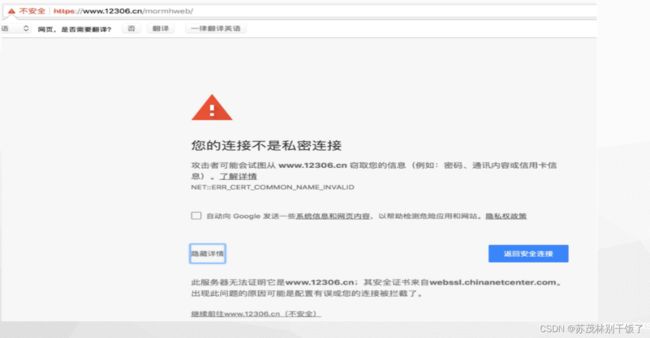
原因:ssl的证书不安全导致
代码报错:
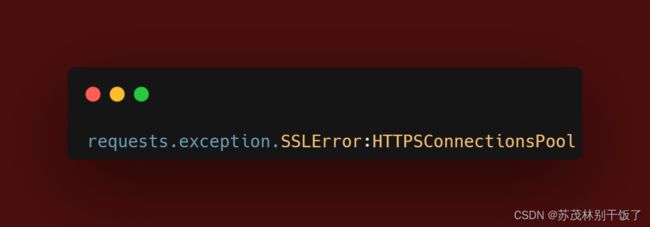
解决方法:
response=requests.get(url.verify=False)
verify的默认值为True
出现SSLError时:首先检查url到底是否正确,如果是标准模式的话,那么就添加verify参数来忽略掉证书的验证