背景
- 主键生成效率用数据库自增效率也是比较高的,为什么要用主键生成器呢?是因为需要insert主表和明细表时,明细表有个字段是主表的主键作为关联。所以就需要先生成主键填好主表明细表的信息后再一次过在一个事务内插入。或者是产生支付流水号时要全局唯一,所以要先生成后插入,不能靠数据库主键。
- 网上有很多主键生成器方式,其中有算法部分和实现部分。算法部分一般就是雪花算法或者以业务编号前缀+年月日形式。
- 一般算法设计没有问题,而在实现方案上,只是同学利用Redis很多实现起来的都是不高效的,他们没考虑Redis都是单线程的情况下多个同时请求生成会有等待的时间。下面我们来对比2款实现方式,看看他们的问题点在哪里,还有我的改进实现方案。
点赞再看,关注公众号:【地藏思维】给大家分享互联网场景设计与架构设计方案
掘金:地藏Kelvin https://juejin.im/user/5d67da8d6fb9a06aff5e85f7
目的
- 减少网络连接Redis的次数,来减少TCP次数。
- 减少因Redis的单线程串行造成的等待
- 两个进程、docker或者说两个服务器之间隔离
- 减少Redis内存使用率
最终实现工具
- Redis: incr、get、set以达到控制进程隔离
- 只连接一次Redis
- LUA脚本保持原子
- syncronize
- 雪花算法以达到不重复键
算法场景
算法场景一:雪花算法
生成出来的主键使用了long类型,long类型为8字节工64位。可表示的最大值位2^64-1(18446744073709551615,装换成十进制共20位的长度,这个是无符号的长整型的最大值)。
单常见使用的是long 不是usign long所以最大值为2^63-1(9223372036854775807,装换成十进制共19的长度,这个是long的长整型的最大值)

- 时间戳这个很容易得,搞个Date转换成Timestamp就好了。
- 数据中心这个字段,可以人为读环境变量填写,毕竟linux服务器不知道你把这个机器放在哪个中心(这个中心是指异地多活的时候说的那个中心)。
- 机器识别号(就是你系统所在的服务器电脑)如何保持唯一是本章内容一个问题。
- 序列编号如果要用自增形式,用那种实现会比较高效率呢?很多阻塞不高效的问题出现在这个地方。
算法场景二:按业务要求规则生成(多数用于流水号,如支付流水)
这种因为long值太大,所以拼接后,会作为String形式。如支付宝的流水号
| 业务号 | 年 | 月 | 日 | 时 | 分 | 秒 | 毫秒 | 自增 | |
|---|---|---|---|---|---|---|---|---|---|
| 000 | 0000 | 00 | 00 | 00 | 00 | 00 | 000 | 000 |
同样序列编号如果要用自增形式,用那种实现会比较高效率呢?
是否需要加上数据中心、机器识别号来隔离进程呢?
然而上面的都是算法,只是确定了这个主键的组成部分,但是因为数据中心位和机器识别位没有确定,就还是需要看如何实现出进程隔离,自增序列如何做才高效。
实现方案
方案一
网上有一种做法,生成时间戳、自增部分的逻辑都在redis里面做,先提前写好LUA脚本,然后通过Redis框架eval执行脚本。
脚本内做以下Redis内容:
- 生成时间
- 以时间作为redis的key自增(如主键需要数据中心位和系统所在服务器编号可拼在key上),这个步骤得到自增序列。为了保持一毫秒内不重复。
- 设置超时时间。
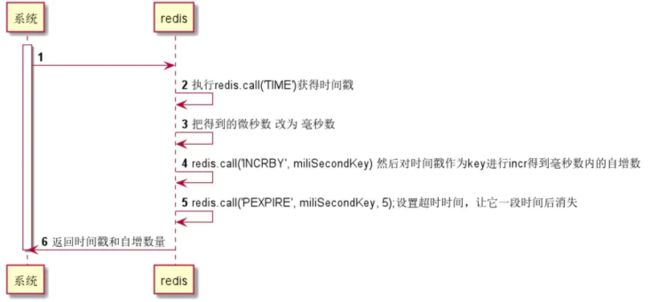
这种方式其实是有问题的,假设A系统,有4个负载均衡节点,同一个时候,每个节点有10万个请求生成主键。下一秒也有10万个请求生成主键。
因为Redis是单线程处理每个命令,所以是串行的。
无论你用上述算法方案两种的哪一种,那现在就有40万个生成主键的网络tcp请求打到redis,一个是网络TCP数量比较多,产生多次握手,另外一个是串行问题导致系统一直在等结果,所以就会有效率问题。
万一第一秒的40万个都没做完,第二秒的40万个都在等待了。何况有10个系统都连这个redis呢?redis内存够用吗?
方案二
自增部分都在redis里面做。
- 服务生成时间戳
- 获取数据中心识别号、机器识别号(如果是雪花算法)
- 获取业务编码(如果是按业务生成)
- 到redis生成同一毫秒内的自增序列
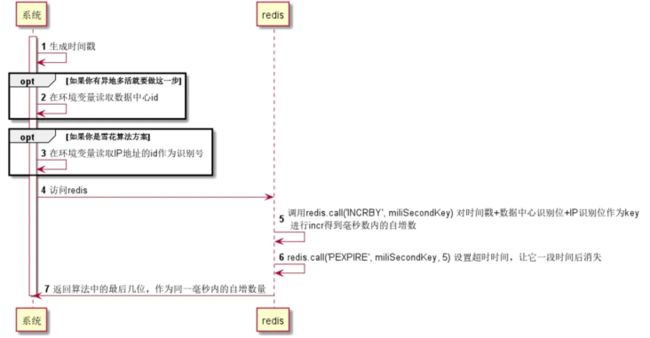
这样的方案心里是在想,把精确到毫秒后,以自增序列之前的那一排数字作为key,请求到redis,incr就好了,这样就可以不同毫秒之间就可以同时incr了吧?
这个方案其实也是有同样上述方案一问题的,多机器同时访问一个redis。
虽然redis要做的命令变少了,但是因为redis是单线程的,可能第一秒内有10万个incr进redis,导致第二秒10万个进来incr的时候,也是由于redis的单线程而等待着的。既然这样也是等待,还不如直接在系统里面syncronize内存的等待还少一次redis网络连接呢。
讨论
- 解决这个问题有人说,可不可以使用合并请求,然后用redis的pipeline一次过丢一堆命令到redis,这样就可以减少tcp连接的次数了。
然而即使只有一个tcp请求,但是也是有很多个命令要一个redis去处理,只是减少tcp而已,用请求合并还要搞个定时任务去做呢,这个定时任务的间隔时间还要特别短,非常影响CPU。
- 也会有说,那就加多几个redis吧。让系统访问redis时,带上一个redis识别号。这样就能达到多个线程处理了。
如:有三台redis,分别请求三个redis时,都带上一个号叫分片号,表明是哪台redis生成的。
| redis机器 | 自增序列带上下面的数字作为前缀 | |
|---|---|---|
| A | 0 | |
| B | 1 | |
| C | 2 |
这样也不是不可以,只是说还是每次访问Redis有网络连接的消耗和redis单线程处理让系统等待。
方案三:改进实现,只访问一次Redis确定雪花算法中的机器识别号,然后系统各自生成。
实现概述
这个方案是基于内存实现,没有为了统一自增序列而每次网络连接访问redis,也不用负载均衡4个节点而导致的4个节点的redis命令都丢给一个redis。只需要系统的4个负载均衡节点自己内部完成,这样就把redis单线程的缺点改为4个进程自己完成,想要增加效率,只需要增加机器就可以了,不用多次依赖中间件。
| 时间戳 | 数据中心号 | 机器识别号 | 自增序列 | |
|---|---|---|---|---|
| 41个位 | 5个位 | 5个位 | 12个位 |
- 时间戳由系统生成没有疑问
- 数据中心号从环境变量里面读取
- 为了不同的进程,意思也是为了相同的系统,但是不同的负载均衡节点之间相互隔离,保证每个负载节点生成的雪花算法结果都是不一样的。所以必须带上机器识别号,即使是使用按业务规则生成的算法方案,也是需要添加机器识别号的。获取识别后就可以保存在静态变量,并初始化雪花算法实例。(访问Redis的就只有这一步,在系统启动的时候完成,后续不用再访问redis)
- 确定第三步后,按照雪花算法生成主键的逻辑,都在java系统里面做。自增序列在java系统里实现,不通过redis。
所以我们对系统启动时的代码和需要生成主键时的代码分开来看。
主要关键点
在于机器识别号生成必须不相同,所以生成机器识别号的逻辑是在redis,而redis部分必须要用LUA脚本实现,保持原子性。
代码流程
1~11 步是系统启动的时候做的。
12~16 步是在系统跑起来后,要生成主键的时候触发的。
如何保持不同的进程之间隔离,在第5到第10步,请留意。

系统启动时
- 你的系统启动完后触发
- java句柄读取本机的IP地址
- 在LUA脚本中调用 redis.call('GET',dmkey); 以数据中心+IP地址作为Key来GET,获取一个数字作为机器识别号。如果能获取到,就证明不是第一次访问,就可以返回给系统
- 如果获取不到,以一个固定字符串“__idgenerator_”作为key,触发incr
- 因原子性,所以incr得一个数字,用这个来作为本次线程访问redis得出的machineId机器识别号。
- 然后以数据中心号和ip地址 拼接后作为key,调用redis的set key, value为刚刚的machineId。
这样就可以让相同的数据中心,并且相同的IP地址在下次直接get到机器识别号。
- 这个号码保存在静态成员变量里面,这样就不用每次生成主键的时候都需要去访问,因为数据中心+IP地址是恒定的。
(注意这几步必须在LUA里面实现,如果在java代码里面实现,很有可能会incr出来的号,在set key那一步被其他机器覆盖了)
截止到流程图的11步结束:这些redis的逻辑都只需要在服务启动的时候触发一次就好了(这里完成目的的第一点减少网络连接)。因为触发一次后就可以保存在代码静态变量里面。
根据ip来确定出机器识别号后,这样生成主键的过程都是保持进程间隔离的。完成目的的第三点,数据隔离。而且利用redis保证了原子性,机器识别号不会重复。
代码贴不全,大家明白思路就好,具体实现在下方Gitee。
private String LUA_SCRIPT = "/redis-script.lua";
List-- need redis 3.2+
local prefix = '__idgenerator_';
local datacenterId = KEYS[1];
local ip = KEYS[2];
if datacenterId == nil then
datacenterId = 0
end
if ip == nil then
return -1
end
local dmkey= prefix ..'_' .. datacenterId ..'_' .. ip;
local machineId ;
machineId = redis.call('GET',dmkey);
if machineId!=nil then
return machineId
end
machineId = tonumber(redis.call('INCRBY', prefix, 1));
if machineId > 0 then
redis.call('SET',dmkey,machineId);
return machineId;
end当需要生成主键时
- 开启syncronize
- 根据雪花算法或者按业务规则算法生成时间戳
- 如果你有异地多活就要在环境变量读取数据中心id
- 主要是读取系统启动后获取到的machineId
- 依赖syncronize,自增序列+1。
代码贴不全,大家明白思路就好,具体实现在下方Gitee。
public synchronized long nextId() {
long timestamp = timeGen();
// 获取当前毫秒数
// 如果服务器时间有问题(时钟后退) 报错。
if (timestamp < lastTimestamp) {
throw new RuntimeException(String.format(
"Clock moved backwards. Refusing to generate id for %d milliseconds", lastTimestamp - timestamp));
}
// 如果上次生成时间和当前时间相同,在同一毫秒内
if (lastTimestamp == timestamp) {
// sequence自增,因为sequence只有12bit,所以和sequenceMask相与一下,去掉高位
sequence = (sequence + 1) & sequenceMask;
// 判断是否溢出,也就是每毫秒内超过4095,当为4096时,与sequenceMask相与,sequence就等于0
if (sequence == 0) {
timestamp = tilNextMillis(lastTimestamp);
// 自旋等待到下一毫秒
}
} else {
sequence = 0L;
// 如果和上次生成时间不同,重置sequence,就是下一毫秒开始,sequence计数重新从0开始累加
}
lastTimestamp = timestamp;
// 最后按照规则拼出ID。
// 000000000000000000000000000000000000000000 00000 00000 000000000000
// time datacenterId workerId sequence
// return ((timestamp - twepoch) << timestampLeftShift) | (datacenterId <<
// datacenterIdShift)
// | (workerId << workerIdShift) | sequence;
// 因为雪花算法没那么多位置给workerId 如果要改,那就要改雪花算法数据中心id和workerId的占位位置
long longStr = ((timestamp - twepoch) << timestampLeftShift) | (datacenterId << datacenterIdShift)
| (workerId << workerIdShift) | sequence;
// System.out.println(longStr);
return longStr;
}
}在这一步实现自增加一,内存态完成,无须依赖redis。
这里完成目的的第二点,不再需要依赖redis的单线程来做等待。改为由系统那么多个负载均衡节点并行处理,因为反正在redis中incr都是内存态的也是串行的。
并且生成的主键变量都是局部变量,用完就销毁,不需要存放于redis增加redis压力。
完成目的4减少Redis内存使用率。
但是要注意,因为machineId只能站5位,所以最大是31,如果到32了,就会变0了。因为雪花算法没那么多位置给machineId 如果要改,那就要改雪花算法数据中心id和machineId的占位数量。
总结
到这里,我们基于雪花算法,用Redis做控制进程的隔离,只需要一次连接,保证不同的服务负载节点上生成的主键不一致,来减少网络TCP连接的访问。也利用了syncronize来保证自增序列不重复的方式,来减少Redis单线程处理的等待时间。
代码样例
代码太多长,不贴那么多了,看Gitee吧
https://gitee.com/kelvin-cai/IdGenerator
欢迎关注公众号,文章更快一步
我的公众号 :地藏思维

掘金:地藏Kelvin
简书:地藏Kelvin
我的Gitee: 地藏Kelvin https://gitee.com/kelvin-cai