前言
焱融文件存储 YRCloudFile 作为一款通用型的高性能分布式文件存储系统,广泛适用于 AI/自动驾驶、 HPC 、量化分析、 视效渲染以及大数据等场景,这些场景有的需要具备大文件的极限带宽,有的需要大文件的高 IOPS,有的则需要支撑海量小文件,而这些需求会涉及到很多的设计决策和优化。
今天,我们将探讨在 AI 训练场景中如何进行海量小文件的性能优化,由于训练场景中的文件访问都是以只读方式打开的,所以本文将着重介绍只读小文件的优化部分。
文件读写的流程
首先,我们先简单了解下读文件所需的操作流程。以 cat 一个小文件为例:首先,读文件之前需要通过 lookup 查看文件是否存在,确定存在则需要通过 open 打开文件,通过 read 来读取文件内容,读取完文件内容后再通过 close关闭文件。对于网络文件系统如:YRCloudFile, NFS 等,还有 revalidate 和 stat 来刷新 inode。注意,lookup 仅在文件系统第一次打开文件时调用。我们可以通过 strace 来验证以上流程: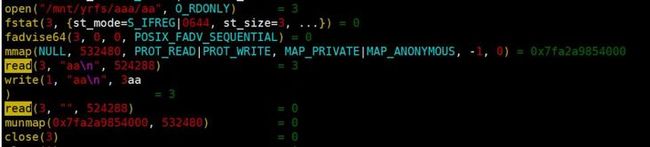
上图中的操作 fadvise 和 mmap 是 cat 独有的操作,这里无需深入了解。此外,关于 lookup 和 revalidate,这两个操作之所以没有出现在上图中是因为它们隐藏在文件系统内部,并没有通过系统调用暴露出来。
小文件的元数据瓶颈
在小文件操作中,元数据操作占据了很大的比重,甚至可以达到 70%-80% 的比重,而真正的业务读写,仅仅占了其中很小一部分,这时元数据性能成为性能瓶颈。
通过以上讨论我们了解到读取文件所需的操作有:lookup、open、read、close、stat、revalidate,每次操作都伴随着一次网络开销。其中 lookup 仅在文件系统第一次读取文件时调用,对于多次读取文件的开销基本可以忽略,为易于叙述,以下暂不讨论 lookup。而 open、close、stat、revalidate 都是元数据操作,并且只有一次调用,而只有 read 是业务真正所需的数据操作,文件越大调用次数越多。我们可以通过推算得知,文件越大,read 次数越多,数据操作占比就越高,元数据操作占比就越低,反之亦然。接下来,我们通过分别读取大小文件场景,再进一步了解:
首先,先讨论读取大文件的场景。如读取一个 100M 的文件,每次读取 1M 数据,那么就需要 100 次read 调用。而对应的元数据操作有 open、close、stat、revalidate 共4个。总操作次数有 104 次,那么可以算出,数据操作占比 100/104 100%= 96%,而元数据操作占比 4/104 100%=4%。
在读取小文件的场景中,如读取一个 1M 的文件,每次读取 1M 数据,只需要一次 read 调用。对应的元数据操作同样有 open、close、stat、revalidate 共4个。总操作次数有 5 次,同样可以算出,数据操作占比为 1/5 100%=20%。而元数据操作占比为 4/5 100%=80%。
通过上述分析清晰看到,对于越小的文件,元数据操作占比越高,元数据性能成为严重限制 ops 性能的瓶颈。对于其优化,我们需要降低元数据操作占比,进而提高 ops。
技术解决方案
基于以上讨论,我们了解到在处理小文件时,元数据性能方面存在着严重的瓶颈。这是因为对于每个小文件,系统都需要频繁读取并处理其对应的元数据信息,包括 open、close、stat 以及 revalidate 等等,这些操作会占用大量的网络和磁盘资源。因为我们需要针对这些问题进行优化。
首先,为了支撑对元数据访问路径的低延迟和高 ops 能力,焱融分布式文件存储 YRCloudFile 采用的 io 框架可提供百万级的 iops 能力。由于元数据需要保证 posix 语义,所以性能上无法和普通读写 io 一样,但同样可以提供数十万的交互能力。
其次,依赖客户端缓存机制,焱融分布式文件存储 YRCloudFile 提供了基于内存缓存的元数据管理技术,在保证语义的前提下,能安全的命中缓存,减少跨网络和磁盘访问开销。
再次,我们实现的 lazy size,lazy close,batch commit,metadata readhead 机制,能同时保证在文件系统语义的前提下,将部分逻辑 offload 到客户端,这样的好处是能够很好的降低元数据服务的压力,并且集群的元数据性能得到很大的提升,包括在延迟和 ops 等方面。
综上,焱融分布式文件存储 YRCloudFile 通过一系列技术操作优化小文件的元数据性能,包括基于内存缓存的元数据管理、轻量级 open、延迟 close 以及批量 close 等。这些技术的应用,可以显著提高焱融分布式文件存储 YRCloudFile 在处理小文件时的性能表现,从而更好地满足用户的需求。
优化前后性能对比
接下来,我们将在具体的 vdbench 测试中来看下焱融分布式文件存储 YRCloudFile 的优化效果。集群配置多副本模式,其中 3 组 mds,3 组 oss,mds 和 oss 均由 nvme ssd 构建。vdbench 脚本为:
hd=default,vdbench=/root/vdbench50406,shell=ssh,user=root
hd=hd01,system=10.16.11.141
fsd=fsd1_01,anchor=/mnt/yrfs/vdbench/4k-01/,depth=1,width=5,files=1000,size=4k,openflags=o_direct
fwd=fwd1_01,fsd=fsd2_01,host=hd01,operation=read,fileio=random,fileselect=random
rd=randr_4k,fwd=fwd5_*,xfersize=4k,threads=64,fwdrate=max,format=restart,elapsed=30,interval=1,pause=1m优化前
Miscellaneous statistics:
(These statistics do not include activity between the last reported interval and shutdown.)
READ_OPENS Files opened for read activity: 540,793 95,986/sec
FILE_BUSY File busy: 5,129 570/sec
FILE_CLOSES Close requests: 540,793 95,986/sec优化后
Miscellaneous statistics:
(These statistics do not include activity between the last reported interval and shutdown.)
READ_OPENS Files opened for read activity: 4,589,603 653,742/sec
FILE_BUSY File busy: 56,129 1,870/sec
FILE_CLOSES Close requests: 4,589,603 653,742/sec通过上述数据,可以看到焱融分布式文件存储 YRCloudFile 显著提高了在处理小文件时的性能表现,性能提高 6 倍以上,以上是基于大量的测试和评估所得出的结论。
总结
在这篇文章,我们探讨了焱融分布式文件存储 YRCloudFile 在只读小文件场景下的优化。我们首先回顾了文件的基本读写流程,分析了其中小文件存在的问题,进而设计了一系列的优化方案来解决 AI 训练场景下只读小文件的性能瓶颈。焱融分布式文件存储 YRCloudFile 的优化技术可以为业务应用尤其是 AI 训练场景下提供更快速、更高效、更可靠的服务,进而提高用户的体验和满意度,同时,也为未来的技术发展提供了借鉴和启示。