Postgresql杂谈 13—Postgresql中的BRIN索引
一、BRIN索引原理
本文我们继续学习下Postgresql中另外一个比较有特色的索引——BRIN索引。BRIN索引是Block Range Index索引的简写,它将数据在磁盘上的block按照一定的数目进行分组,这个数目可以通过创建BRIN时的参数pages_per_range进行设置,默认是128。分组之后,计算每组的取值范围。在 查找数据时,会遍历这些取值范围,排除掉不在范围之内的分组。
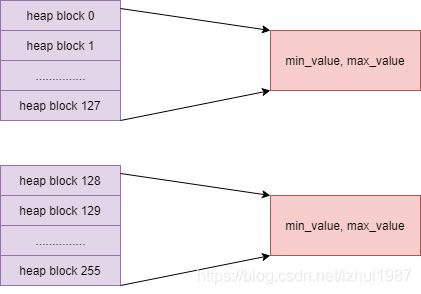
与其它索引不同:
(1)BTree等其它索引在查找数据时是根据数据定位到数据行的位置,而BRIN索引是先排除不再范围内的数据块,一旦找到包含目标数据的数据块范围之后,采用位图扫描获取相应数据行。
(2)由于BRIN是将相邻的磁盘块组合,所以它适合在数值上线性增长的数据列建立索引,而且数据行应该不经常执行删除操作,否则就可能因为删除操作进行频繁的重建索引。
(3)BRIN按照一定数目将磁盘块整合,因此在占用空间上要比BTree小,但是因为采用遍历方式排除数据,性能上势必差于BTree。
下面,笔者结合实例,来验证下BRIN索引的这些特点。
二、BRIN索引和BTree索引空间比较
首先,我们验证下,BRIN索引和BTree索引在存储空间上的区别。在此之前,我们还是需要先建立两个测试表t1和t2,两个表除了表名和建立的索引类型之外,其它完全相同,而且都插入1000W条数据。
分别建立t1和t2:
stock_analysis_data=# create table t1 (id serial,name varchar(32));
CREATE TABLE
stock_analysis_data=# create table t2 (id serial,name varchar(32));
CREATE TABLE分别向t1和t2表中插入1000W条数据:
stock_analysis_data=# insert into t1 (name) select 't1'||t.d from generate_series(1,10000000) as t(d);
INSERT 0 10000000
stock_analysis_data=# insert into t2 (name) select 't2'||t.d from generate_series(1,10000000) as t(d);
INSERT 0 10000000在t1的id字段建立BTree索引:
stock_analysis_data=# create index t1_id_btree_inx on t1 using btree(id);
CREATE INDEX
Time: 13437.652 ms (00:13.438)我们看到,1000W条数据,建立过程花费了13秒的时间。然后在t2表上建立BRIN索引,先按照默认的pages_per_range(128)进行建立:
stock_analysis_data=# create index t2_id_brin_inx on t2 using brin(id);
CREATE INDEX
Time: 5037.331 ms (00:05.037)单单从建立索引的耗时来说,要小于BTree索引,1000W条数据建立BRIN索引,只需要5秒钟。我们来查看下两个索引的大小:
stock_analysis_data=# select relname,pg_size_pretty(pg_relation_size(oid)) from pg_class where relname ='t1_id_btree_inx';
relname | pg_size_pretty
-----------------+----------------
t1_id_btree_inx | 214 MB
(1 row)
Time: 0.896 msstock_analysis_data=# select relname,pg_size_pretty(pg_relation_size(oid)) from pg_class where relname ='t2_id_brin_inx';
relname | pg_size_pretty
----------------+----------------
t2_id_brin_inx | 32 kB
(1 row)
Time: 0.557 ms可以看到,BRIN索引整整比BTree索引小了7000倍,下面我们在创建BRIN索引时尝试设置较小的pages_per_range:
stock_analysis_data=# create index t2_id_brin_inx on t2 using brin(id) WITH (pages_per_range=64, autosummarize=on);
CREATE INDEX把pages_per_range设置为64,也就是现在按照64个磁盘叶为一组,查看此时的BRIN索引的大小,就会发现,整个索引占用的空间的确比以前大了。
stock_analysis_data=# select relname,pg_size_pretty(pg_relation_size(oid)) from pg_class where relname ='t2_id_brin_inx';
relname | pg_size_pretty
----------------+----------------
t2_id_brin_inx | 40 kB
(1 row)三、BRIN索引和BTree索引查询性能比较
上面,我们比较了BRIN索引和BTree索中所占空间的大小,接下来,我们比较下两者的查询性能,首先从t1表中查询id为100W的数据:
stock_analysis_data=# explain(analyze,verbose,costs,timing) select * from t1 where id=1000000;
QUERY PLAN
----------------------------------------------------------------------------------------------------------------------------
Index Scan using t1_id_btree_inx on public.t1 (cost=0.43..8.45 rows=1 width=13) (actual time=0.026..0.028 rows=1 loops=1)
Output: id, name
Index Cond: (t1.id = 1000000)
Planning Time: 0.096 ms
Execution Time: 0.059 ms
(5 rows)然后,再从t2表中利用BRIN索引查询id为100W的数据:
stock_analysis_data=# explain(analyze,verbose,costs,timing) select * from t2 where id=1000000;
QUERY PLAN
------------------------------------------------------------------------------------------------------------------------------
Bitmap Heap Scan on public.t2 (cost=20.02..28620.29 rows=1 width=13) (actual time=16.657..26.042 rows=1 loops=1)
Output: id, name
Recheck Cond: (t2.id = 1000000)
Rows Removed by Index Recheck: 11839
Heap Blocks: lossy=64
-> Bitmap Index Scan on t2_id_brin_inx (cost=0.00..20.02 rows=11834 width=0) (actual time=0.247..0.247 rows=640 loops=1)
Index Cond: (t2.id = 1000000)
Planning Time: 0.135 ms
Execution Time: 26.076 ms
(9 rows)可以看到,从查询效率上来说,BRIN索引的确不如BTree索引。
四、总结
综上所述,我们可以得到如下结论:
(1)BRIN索引通过将磁盘块分组,在查询时遍历排除不包含目标数据的分组,每组的块数可以在创建BRIN索引时通过参数pages_per_range设置。
(2)BRIN索引适合在数值线性增长的列上使用,如时序性的记录类型数据等等,且要求数据不能频繁删除。
(3)BRIN索引和BTree索引比较,前者节省大量的存储空间,但是查询性能要逊于后者。在处理大数据时,为了节省存储成本,可以考虑使用BRIN索引。