视屏处理优化工具
一直想做视屏目标跟踪之类的,在这里记录下自己点滴摸索过程:
1、视屏抽帧
一段视屏其实就是就是一段连续的图片,由于人的肉眼识别频率有限(一般24张/秒),当超过这个极限就给人眼造成的感觉就是画面是运动的,这就是所谓的视频,而一秒内播放的图片数就是帧率(fps/s)。将每张图片从视屏中剥离出来就是抽帧。一般常见的抽帧方法如下:
(1)利用 FFmpeg 工具
该方法可实现跨平台对音频或视屏进行截断、抽帧,简单方便,安装可以参考官网。具体使用操作如下:
ffmpeg -i testvideo.avi -vf select='eq(pict_type\,I)' -vsync 2 -f image2 frame-%03d.jpg -hide_banner具体参数很多,可以查阅官网,一般使用
-i :后面的视频的名字也是路径,这个参数一定要放在最前面
-f :图片的命名格式及保存格式,不加这个也行,直接把保存格式写上就好
-s :分辨率,如-s 160×90则将图片的分辨率统一设定成160×90
-vsync :阻止每个关键帧产生多余的拷贝,其实只有两个值可以输入,1或2
-vf :表示过滤图形的描述,选择过滤器select会选择帧进行输出:包括过滤器常量
eq(pict_type\,I):PICT_TYPE_I 表示是I帧,即关键帧,如果是1,7秒视频输出201个图片,换成2,7秒视频输出101个图片。
-vframes :指抽取的帧数
-ss :指起始时间
-t :持续时间,单位是秒
-r :指抽取的帧率,即从视频每秒钟抽取图片的数量,1即每秒抽取一帧
参考链接:https://blog.csdn.net/Will_Ye/article/details/84192734
基于python的fffmpy或者pyav,以及cmd命令来直接操作fmpeg,
import subprocess
def get_image(video_path, image_path):
img_count = 1
crop_time = 0.0
while crop_time <= 15.0:# 转化 15s 的视频
cmd_str = f'ffmpeg -i {video_path} -f image2 -ss {crop_time} -vframes 1 {image_path}/{img_count}.png'
subprocess.run(cmd_str, encoding="utf-8" , shell=True)
img_count += 1
print(f'Geting Image {img_count}.png from time {crop_time: .5g}')
crop_time += 2 # 每 2 秒截取一张照片
print('视频转化完成!!!')import os
import re
import logging
from django.conf import settings
from django.core.cache import cache
from ffmpy import FFmpeg
from course.constant import VIDEOSTATE
logger = logging.getLogger(__name__)
def cut_change(video_path, out_path, out_path2, out_path3, base_path, fps_r):
"""
操作ffmpeg执行
:param video_path: 处理输入流视频
:param out_path: 合成缩略图 10×10
:param out_path2: 封面图路径
:param out_path3: 合成Ts流和 *.m3u8文件
:param fps_r: 对视频帧截取速度
"""
ff = FFmpeg(inputs={video_path: None},
outputs={out_path: '-f image2 -vf fps=fps={},scale=180*75,tile=10x10'.format(fps_r),
out_path2: '-y -f mjpeg -ss 0 -t 0.001',
None: '-c copy -map 0 -y -f segment -segment_list {0} -segment_time 1 -bsf:v h264_mp4toannexb {1}/cat_output%03d.ts'.format(
out_path3, base_path),
})
print(ff.cmd)
ff.run()
def execCmd(cmd):
"""
执行计算命令时间
"""
r = os.popen(cmd)
text = r.read().strip()
r.close()
return text
# 获取完整的上传文件路径
def has_video(video_path):
MEDIA_DIR = settings.MEDIA_ROOT
FULL_PATH = os.path.join(MEDIA_DIR, video_path)
flag = False
if os.path.exists(FULL_PATH):
flag = True
return flag, FULL_PATH, MEDIA_DIR
def handle_video_cut(instance):
video_path = instance.video.name
video_name = os.path.splitext(video_path.split('/')[-1])[0][:5]
flag, full_path, media_path = has_video(video_path)
base_preview_path = os.path.join(media_path, 'video_trans/preview')
base_poster_path = os.path.join(media_path, 'video_trans/poster')
base_path = os.path.join(media_path, 'video_trans/video_change', str(instance.id))
# 必须先创建路径, ffmpeg不会自己创建
if not os.path.exists(base_path):
os.makedirs(base_path)
if not os.path.exists(base_poster_path):
os.makedirs(base_poster_path)
if not os.path.exists(base_preview_path):
os.makedirs(base_preview_path)
preview_path = os.path.join(base_preview_path, video_name + '{}_out.png'.format(str(instance.id)))
poster_path = os.path.join(base_poster_path, video_name + '{}_poster.jpeg'.format(str(instance.id)))
video_change = os.path.join(base_path, 'playlist.m3u8')
if not flag:
logger.info('this video_path({}) is not exists'.format(full_path))
return None
cmd = "ffmpeg -i {} 2>&1 | grep 'Duration' | cut -d ' ' -f 4 | sed s/,//".format(full_path)
text = execCmd(cmd)
search_group = re.search('(\d+):(\d+):(\d+)', text)
if search_group:
time_hours = int(search_group.group(1))
time_minutes = int(search_group.group(2))
time_seconds = int(search_group.group(3))
all_count_seconds = time_hours * 60 * 60 + time_minutes * 60 + time_seconds
# print(all_count_seconds)
else:
logger.info('this video({}) is no time'.format(full_path))
return None
# 因无法精确分配100分压缩图片,存在误差, 以下函数会有错误但是并不会影响结果, 会有exception
try:
cut_change(full_path, preview_path, poster_path, video_change, base_path, r)
except:
pass
# print('change video code success')
logger.info('change video code success and clean cache')
return None
(2)利用opencv
可以通过调用opencv的VideoCapture、imgwrite 来提取
import cv2
vc = cv2.VideoCapture('SampleVideo_1280x720_1mb.mp4') # 读入视频文件
c=1
if vc.isOpened(): # 判断是否正常打开
rval, frame = vc.read()
else:
rval = False
timeF = 5 # 视频帧计数间隔频率
while rval:
# 循环读取视频帧
rval, frame = vc.read()
#gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
# Display the resulting frame
try:
cv2.imshow('frame', frame)
except:
pass
if (c % timeF == 0): # 每隔timeF帧进行存储操作
cv2.imwrite('crop/image' + str(c) + '.jpg', frame) # 存储为图像
c = c + 1
if cv2.waitKey(1) & 0xFF == ord('q'):
break
vc.release()
cv2.destroyAllWindows()(3)imutils
感觉比opencv效果更好,丢包更少。
import cv2
import imutils
from imutils.video import VideoStream
import threading
import multiprocessing
import time
def cam1():
cap=VideoStream("D:/pycharm/project/yolo_test/test_demo1.mp4").start()
n=0
while True:
img=cap.read()
n+=1
cv2.putText(img,str(n),(50,300),cv2.FONT_HERSHEY_SIMPLEX,1.2,(255,255,255),2)
cv2.imshow("frame11",img)
cv2.waitKey(1)
cap.release()
def cam2():
n=0
cap=cv2.VideoCapture("D:/pycharm/project/yolo_test/test_demo1.mp4")
while True:
ret,img=cap.read()
if ret:
n+=1
cv2.putText(img,str(n),(50,300),cv2.FONT_HERSHEY_SIMPLEX,1.2,(255,255,255),2)
cv2.imshow("frame22",img)
cv2.waitKey(1)
cap.release()
if __name__=="__main__":
# thread1=threading.Thread(target=cam1)
# thread2=threading.Thread(target=cam2)
# th=[thread1,thread2]
# for t in th:
# t.start()
proc1=multiprocessing.Process(target=cam1)
proc2=multiprocessing.Process(target=cam2)
proc1.start()
proc2.start()
2、目标跟踪
通常目标跟踪面临几大难点(吴毅在VALSE的slides):外观变形,光照变化,快速运动和运动模糊,背景相似干扰。目标视觉跟踪(Visual Object Tracking),大家比较公认分为两大类:生成(generative)模型方法和判别(discriminative)模型方法,目前比较流行的是判别类方法,也叫检测跟踪tracking-by-detection,为保持回答的完整性,以下简单介绍。
生成类方法,在当前帧对目标区域建模,下一帧寻找与模型最相似的区域就是预测位置,比较著名的有卡尔曼滤波,粒子滤波,mean-shift等。举个例子,从当前帧知道了目标区域80%是红色,20%是绿色,然后在下一帧,搜索算法就像无头苍蝇,到处去找最符合这个颜色比例的区域,推荐算法ASMS vojirt/asms:
Vojir T, Noskova J, Matas J. Robust scale-adaptive mean-shift for tracking [J]. Pattern Recognition Letters, 2014.
ASMS与DAT并称“颜色双雄”(版权所有翻版必究),都是仅颜色特征的算法而且速度很快,依次是VOT2015的第20名和14名,在VOT2016分别是32名和31名(中等水平)。ASMS是VOT2015官方推荐的实时算法,平均帧率125FPS,在经典mean-shift框架下加入了尺度估计,经典颜色直方图特征,加入了两个先验(尺度不剧变+可能偏最大)作为正则项,和反向尺度一致性检查。作者给了C++代码,在相关滤波和深度学习盛行的年代,还能看到mean-shift打榜还有如此高的性价比实在不容易(已泪目~~),实测性能还不错,如果您对生成类方法情有独钟,这个非常推荐您去试试。(某些算法,如果连这个你都比不过。。天台在24楼,不谢)
判别类方法,OTB50里面的大部分方法都是这一类,CV中的经典套路图像特征+机器学习, 当前帧以目标区域为正样本,背景区域为负样本,机器学习方法训练分类器,下一帧用训练好的分类器找最优区域:
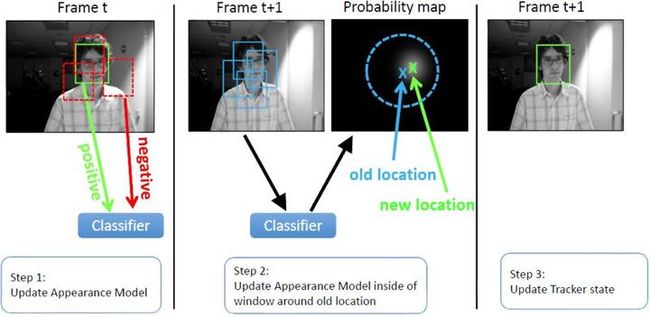
与生成类方法最大的区别是,分类器采用机器学习,训练中用到了背景信息,这样分类器就能专注区分前景和背景,所以判别类方法普遍都比生成类好。举个例子,在训练时告诉tracker目标80%是红色,20%是绿色,还告诉它背景中有橘红色,要格外注意别搞错了,这样的分类器知道更多信息,效果也相对更好。tracking-by-detection和检测算法非常相似,如经典行人检测用HOG+SVM,Struck用到了haar+structured output SVM,跟踪中为了尺度自适应也需要多尺度遍历搜索,区别仅在于跟踪算法对特征和在线机器学习的速度要求更高,检测范围和尺度更小而已。这点其实并不意外,大多数情况检测识别算法复杂度比较高不可能每帧都做,这时候用复杂度更低的跟踪算法就很合适了,只需要在跟踪失败(drift)或一定间隔以后再次检测去初始化tracker就可以了。其实我就想说,FPS才TMD是最重要的指标,慢的要死的算法可以去死了(同学别这么偏激,速度是可以优化的)。经典判别类方法推荐Struck和TLD,都能实时性能还行,Struck是2012年之前最好的方法,TLD是经典long-term的代表,思想非常值得借鉴。
相关滤波类方法correlation filter简称CF,也叫做discriminative correlation filter简称DCF,注意和后面的DCF算法区别,包括前面提到的那几个,也是后面要着重介绍的。深度学习(Deep ConvNet based)类方法,因为深度学习类目前不适合落地就不瞎推荐了,可以参考Winsty的几篇 Naiyan Wang - Home,还有VOT2015的冠军MDNet Learning Multi-Domain Convolutional Neural Networks for Visual Tracking,以及VOT2016的冠军TCNN http://www.votchallenge.net/vot2016/download/44_TCNN.zip,速度方面比较突出的如80FPS的SiamFC SiameseFC tracker和100FPS的GOTURN davheld/GOTURN,注意都是在GPU上。基于ResNet的SiamFC-R(ResNet)在VOT2016表现不错,很看好后续发展,有兴趣也可以去VALSE听作者自己讲解 VALSE-20160930-LucaBertinetto-Oxford-JackValmadre-Oxford-pu,至于GOTURN,效果比较差,但优势是跑的很快100FPS,如果以后效果也能上来就好了。做科研的同学深度学习类是关键,能兼顾速度就更好了。
数据集:
OTB包括25%的灰度序列,但VOT都是彩色序列。
参考链接:
https://blog.csdn.net/weixin_40245131/article/details/79754531