集合中的常用方法
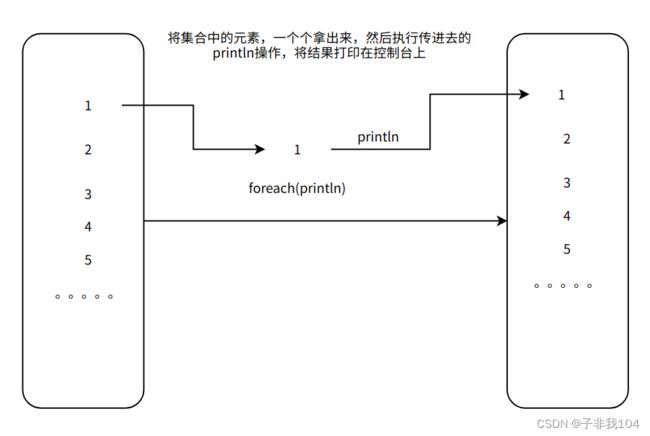
7.8.1forEach
迭代遍历集合中的每个元素,对每个元素进行处理 ,但是没有返回值 ,常用于打印结果数据 !
| Scala
val ls = List(1,3,5,7,9)
ls.foreach(println) // 打印每个元素
ls.foreach(println(_))// 打印每个元素
ls.foreach(x=>println(x*10)) // 每个元素乘以10 打印结果
ls.foreach(x=>print(x+" "))// 打印每个元素 空格隔开 |
7.8.2map
适用于任意集合
注意Map集合的用法:map函数遍历每个元素处理返回原集合类型的新集合 , 也可以不返回数据列表,数组,Map中都有map函数 元组中没有map函数
| Scala
val arr = Array[String]("JAVA", "C++", "SCALA")
val ls = List(1, 3, 5, 7, 9)
val set = Set(1, 3, 5, 7)
val mp = Map[String, Int]("ZSS" -> 100, "LSS" -> 99)
// map函数遍历每个元素处理返回原集合类型的新集合
val new_arr: Array[String] = arr.map(x => x)
val new_list: List[Int] = ls.map(x => x)
val new_set: Set[Int] = set.map(x => x)
// Map集合使用map函数
val new_Map1: Map[String, Int] = mp.map({ case v: (String, Int) => (v._1, v._2 * 10) })
val new_Map2: Map[String, Int] = mp.map(e => (e._1, e._2 + 100))
// map函数也可以不返回数据
ls.map(println(_)) |

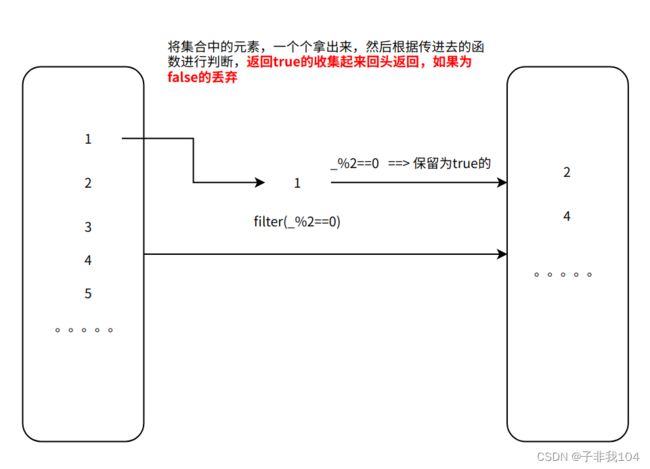
7.8.3filter和filterNot
适用于: 数组 List Map
filter返回符合自己条件的新的集合,filterNot返回不符合自己条件的新的集合
| Scala
val ls: List[Int] = List.range(1,10)
ls.filter(x=>x%2==0)
val new_list: List[Int] = ls.filter(_ % 2 == 0)// _ 代表每个元素
new_list .foreach(x=>print(x+" ")) // 2 4 6 8
ls.filterNot(_%2!=1).foreach(x=>print(x+" ")) 1 3 5 7 9 |
每个元素进行过滤
| Scala
val set = Set("spark" , "scala" , "c++" , "java")
val new_set: Set[String] = set.filter(_.startsWith("s"))
set.filter(_.length>3) |
多条件filter进行条件过滤
| Scala
val ls = "spark":: "scala" :: "c++"::"java"::1::2::12.34::Nil
// 过滤出String类型的和Double类型的数据
ls.filter{
case i:String => true
case i:Int=>false
case i:Double=>true
} |
连续使用多次filter进行条件过滤
| Scala
// 连续使用多次filter进行条件过滤
val map = Map[String,Int](("zss" ,91),("zww",89),("zzx",92) , ("ww",23))
map.filter(_._1.startsWith("z")).filter(_._2>90) |
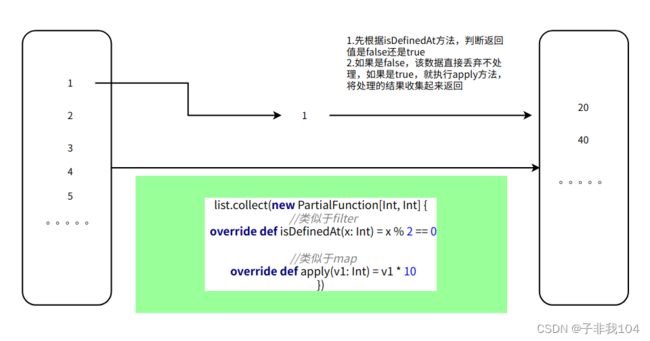
7.8.4collect
常用于: Array List Map
collect函数也可以遍历集合中的每个元素处理返回新的集合
| def map[B](f: (A) ⇒ B): List[B]
def collect[B](pf: PartialFunction[A, B]): List[B] |
主要支持偏函数
| Scala
val ls = List(1,2,3,4,"hello")
// 主要支持偏函数
val new_list: List[Int] = ls.collect({case i:Int=>i*10})
new_list.foreach(x=>print(x+" "))//10 20 30 40
// collect实现filter和map特性
list.collect({ case i: Int => i * 10
case i: String => i.toUpperCase
}).foreach(println)
val new_list2: List[Int] = ls.map({case x:Int=>x*10})
new_list2.foreach(x=>print(x+" "))// 错误 hello (of class java.lang.String) |
因为collect支持偏函数 , 所以我们可以使用collect实现filter和map的特性!!!
| Scala
val res: List[Int] = List(1, 2, 3, 4, 5, 6,"hello").collect({case i:Int if i%2==0=>i*10})
res.foreach(println) // 40 60 是不是牛逼闪电?? |
7.8.5min和max
适用于:数组 List Map
| Scala
val arr = Array(1,2,345,67,5)
arr.min
arr.max
arr.sum |
| Scala
val ls = List(1,2,345,67,5)
ls.min
ls.max
ls.sum |
| Scala
val set = Set(1,2,345,67,5)
set.min
set.max
set.sum |
| Scala
val map = Map[String,Int]("a"->10, "b"->99 , "c"->88)
// map默认按照key排序获取最大和最小数据
map.min //(a,10)
map.max //(c,88) |
7.8.6minBy和maxBy
适用于: 数组 List Map
集合中的min和max可以获取任意集合中的最小和最大值 ,但是如果集合中存储的是用户自定义的类 , 或者是按照Map集合中的key, value规则排序的话就需要用户指定排序规则
| Scala
val map = Map[String,Int]("a"->10, "b"->99 , "c"->88)
// map默认按照key排序获取最大和最小数据
// 指定map排序 按照value排序
map.maxBy(x=>x._2) //(b,99)
map.minBy(x=>x._2) //(a,10) |
| Scala
class User(val name:String ,val age:Int) {} |
方式一 隐式转换
| Scala
implicit def ordersUser(user:User)={
new Ordered[User] {
override def compare(that: User) = {
user.age.compareTo(that.age)
}
}
}
val ls = List(new User("zs",22),new User("ww",18) ,new User("tq",34))
println(ls.max.name)
println(ls.min.name) |
| Scala
println(ls.maxBy(x => x.age).name) |
方式二:
7.8.7sum
适用于 数组 List Set
求集合中的所有元素的和 ,下面三种集合类型常用
| Scala
val arr = Array(1,2,345,67,5)
arr.sum
val ls = List(1,2,345,67,5)
ls.sum
val set = Set(1,2,345,67,5)
set.sum |
7.8.8count
适用于 数组 List Map
def count(p: ((A, B)) => Boolean): Int
计算满足指定条件的集合元素数量
| Scala
val arr = Array(1,2,345,67,5)
arr.count(_>5) // array list set 统用
val ls = List("hello" , "hi" , "heihei" , "tom")
ls.count(_.startsWith("h"))
ls.count(_.equals("hello"))
ls.count(_ == "hello")
// 忽略大小写
ls.count(_.equalsIgnoreCase("HELLO"))
// 统计符合条件的map元素的数量
val map = Map[String,Int]("a"->10,"ab"->10, "b"->99 , "c"->88)
map.count(x=>x._1.startsWith("a"))
map.count(_._2>10) |
7.8.9find
适用于 数组 List Map
查找符合要求的元素 , 匹配到就反回数据 ,最多只返回一个
Option中的数据要么是Some(T) 要么是None标识没有找到
| Scala
val arr = Array(1,2,345,67,5)
val e: Option[Int] = arr.find(x=>x>1)
val ls = List("hello" , "hi" , "heihei" , "tom")
val res: Option[String] = ls.find(_.contains("a"))
if(res.isDefined){
println(res) //Some(hello)
println(res.get) //hello
}
val map = Map[String,Int]("a"->10,"ab"->10, "b"->99 , "c"->88)
val res_map: Option[(String, Int)] = map.find(x=>x._2>20)
if(res_map.isEmpty){
"没有匹配到内容"
}else{
// 打印数据
println(res_map.get)
} |
7.8.10flatten
适用于 数组 List
压平 将一个集合展开 组成一个新的集合
| Scala
val arr = Array(1,2,345,67,5.23)
//val res1: Array[Nothing] = arr.flatten I数值了类型的无法压平
val ls = List("hello" , "hi" , "heihei" , "tom")
val res2: Seq[Char] = ls.flatten // 压成单个字符 因为字符串属于序列集合的一种
val map = Map[String,Int]("a"->10,"ab"->10, "b"->99 , "c"->88)
// map无法直接压平
//val flatten: immutable.Iterable[Nothing] = map.flatten
// 压平存储Map集合的list 获取Map中每个元素
val ls1 = List[Map[String,Int]](Map[String,Int]("a"->10,"ab"->10) , Map[String,Int]("jim"->100,"cat"->99))
ls1.flatten // List((a,10), (ab,10), (jim,100), (cat,99))
val res: List[Int] = List(Array(1,2,3),Array(4,5,6)).flatten
// 错误 注意压平的数据的类型
val res4 = List(Array(1,2,3),Array("hel",5,6)).flatten |

7.8.11flatMap
适用于 数组 List
map+flatten方法的组合 ,先遍历集合中的每个元素 , 再按照指定的规则压平, 返回压平后的新的集合
| Scala
val ls = List("today is my first day of my life" , "so I feel so happy")
// map处理每个元素 就是处理每句话
ls.map(x=>println(x))
// 获取集合中的每个元素 获取两句话 然后再扁平成字符
ls.flatMap(x=>x)
// 指定扁平化的规则 按照空格压平 压平的规则
ls.flatMap(x=>x.split(" ")).foreach(println) // 获取到每个单词
// 读取外部文件
val bs: BufferedSource = Source.fromFile("d://word.txt")
// 读取所有的数据行
val lines: Iterator[String] = bs.getLines()
// m遍历每行数据按照 \\s+ 切割返回一个新的迭代器
val words: Iterator[String] = lines.flatMap(_.split("\\s+"))
// 遍历迭代器 获取每个单词
words.foreach(println)
// 读取外部文件
val bs2: BufferedSource = Source.fromFile("d://word.txt")
// 获取所有的行数据
val lines2: Iterator[String] = bs2.getLines()
// 处理每行数据 切割单词后 每行返回一个数组 将所有的数组封装在迭代器中
val arrs: Iterator[Array[String]] = lines2.map(_.split("\\s+")) |

7.8.12 mapValues
适用于 Map
mapValues方法只对Map集合的value做处理!
7.8.13sorted
适用于 数组 List Map
sorted 使用域简单的数字, 字符串等排序规则简答的集合进行排序 , 如果需要定制化排序建议使用sortBy 和 sortWith函数
List对数值
| Scala
val list = List (1, 34 , 32 , 12 , 20 ,44 ,27)
// 返回排好序的list集合 默认从小到达排序
val sorted: List[Int] = list.sorted |
对Array字符串
| Scala
val arr = Array("jim" , "cat" , "jong" , "huba")
// 字符串默认按照先后排序
val sorted_arr: Array[String] = arr.sorted |
对map
| Scala
val map = Map[String , Int]("aeiqi"->4 , "qiaozhi"->2 , "baji"->34)
// map集合也没有sorted 函数 只有转换成List或者Array集合 默认按照key字典先后排序
val sorted_map: Seq[(String, Int)] = map.toList.sorted
sorted_map.foreach(println) |
7.8.14sortBy和sortWith
适用于 数组 List Map
| Scala
var arr = Array(1, 11, 23, 45, 8, 56)
val arr1 = arr.sortBy(x => x) //ArraySeq(1, 8, 11, 23, 45, 56)
//按照数据倒序排列
val arr2 = arr.sortBy(x => -x) //(56, 45, 23, 11, 8, 1)
// 按照字典顺序排序
val arr3 = arr.sortBy(x => x.toString) //ArraySeq(1, 11, 23, 45, 56, 8)
// x 前面的元素 y 后面的元素
arr.sortWith((x, y) => x > y)
arr.sortWith((x, y) => x < y)
var list = List("hello", "cat", "happy", "feel")
// 字典顺序
list.sortBy(x => x)
// 执行排序
list.sortWith((x, y) => x > y)
list.sortWith((x, y) => x < y)
val map = Map("peiqi" -> 5, "jong" -> 3, "baji" -> 12)
map.toList.sortBy(x => x._1) //List((baji,12), (jong,3), (peiqi,5))
map.toList.sortBy(x => x._2) //List((jong,3), (peiqi,5), (baji,12))
// 指定key排序
map.toArray.sortWith((x,y)=>x._1>y._1)
map.toArray.sortWith((x,y)=>x._1
//指定value排序规则
map.toArray.sortWith((x,y)=>x._2>y._2)
map.toArray.sortWith((x,y)=>x._2 |
自定义类型在集合中的排序
| Scala
val u1 = new User("wuji", 34)
val u2 = new User("zhiruo", 24)
val u3 = new User("zhoamin", 44)
val u4 = new User("cuishan", 64)
var arr = Array(u1, u2, u3, u4)
// 按照姓名字典排序
arr.sortBy(user => user.name)
//年龄小到大
arr.sortBy(user => user.age)
//数值类型的排序可以直接使用- 来倒序排列 年龄大到小
arr.sortBy(user => -user.age)
// 年龄大到小
arr.sortWith((user1, user2) => user1.age > user2.age)
// 年龄小到大
arr.sortWith((user1, user2) => user1.age < user2.age)
// 姓名字典升序
arr.sortWith((user1, user2) => user1.name < user2.name)
//姓名字典降序
arr.sortWith((user1, user2) => user1.name > user2.name) |
7.8.15partition和span (了解)
partition将数组按照指定的规则分组 ,适用于 数组 List Map
| Scala
val list = List(1,2,3,4,5,6,7,8,9)
// 将集合根据条件分成两组返回一个存储集合的元组第一个集和实符合要求的元素
//(List(3, 6, 9),List(1, 2, 4, 5, 7, 8))
val res: (List[Int], List[Int]) = list.partition(x=>x%3==0)
//从第一个元素开始处理 配到不符合条件的就结束
list.span(_<3) // (List(1, 2),List(3, 4, 5, 6, 7, 8, 9))
val list2 = List("scala" , "is" , "option" , "fucntion")
// (List(scala, is, fucntion),List(option))
list2.partition(_.hashCode%2==0)
map集合******************************************
val map = Map("peiqi" -> 5, "jong" -> 3, "baji" -> 12)
// (Map(baji -> 12),Map(peiqi -> 5, jong -> 3))
val tuple: (Map[String, Int], Map[String, Int]) = map.partition(x=>x._1.contains("b"))
val tuple2: (Map[String, Int], Map[String, Int]) = map.partition(x=>x._2 >5) |
7.8.16grouped
将集合中的元素按照指定的个数进行分组
| Scala
val list1 = List(1,2,3,4,5,6,7,8,9)
val list2 = List("scala" , "is" , "option" , "fucntion")
val map = Map[String,Int]("peiqi" -> 5, "jong" -> 3, "baji" -> 12)
// 两个元素分成一组 ,9个元素总共分成5组
val res: Iterator[List[Int]] = list1.grouped(2)
var i = 0
// 遍历每个元素
res.foreach(list=>{
i+=1
list.foreach(x=>println(x+"----"+i)) // 打印每个元素和它所对应的组
})
// 将map集合按照个数进行分组
val res2: Iterator[Map[String, Int]] = map.grouped(2)
res2.foreach(i=>i.foreach(x=>println((x._1,x._2)))) |
7.8.17groupBy
将集合中的数据按照指定的规则进行分组
序列集合
| Scala
val list1 = List(1,2,3,4,5,6,7,8,9)
val list2 = List("scala" , "is" , "option" , "fucntion")
// 对序列数据进行分组
val res1: Map[Boolean, List[Int]] = list1.groupBy(x=>x>3) //HashMap(false -> List(1, 2, 3), true -> List(4, 5, 6, 7, 8, 9))
val res2: Map[Boolean, List[Int]] = list1.groupBy(x=>x%2==0)//HashMap(false -> List(1, 3, 5, 7, 9), true -> List(2, 4, 6, 8))
list2.groupBy(x=>x.hashCode%2==0)
//HashMap(false -> List(is, option, fucntion), true -> List(scala))
val res: Map[Boolean, List[String]] = list2.groupBy(x=>x.startsWith("s")) |
键值映射集合分组
| Scala
val map = Map[String,Int]("peiqi" -> 5, "jong" -> 3, "baji" -> 12)
val arr = Array(("cat",21),("lucy",33),("book",22),("jack",34))
// 按照key和value的内容分组
println(map.groupBy(mp => mp._1))
println(map.groupBy(mp => mp._2))
// 根据key 或者 value 分成两组 满足条件的和不满足条件的
println(map.groupBy(mp => mp._1.hashCode%2==0))
println(map.groupBy(mp => mp._2>2))
// 对偶元组集合 和map的分组方式是一样的
arr.groupBy(arr=>arr._1)
arr.groupBy(arr=>arr._2) |
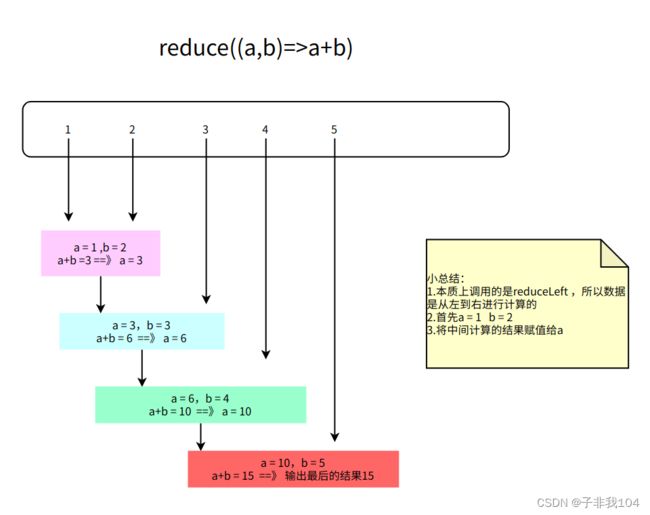
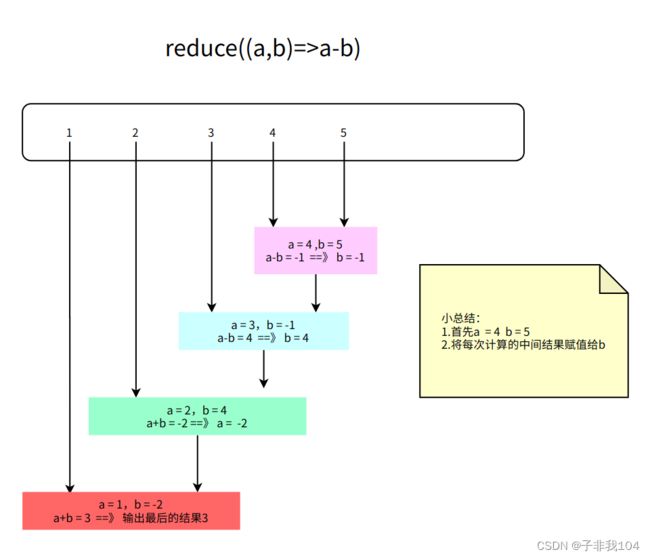
7.8.18reduce
底层调用的是reduceLeft , 从左边开始运算元素
| Scala
val list = List(1,3,5,7,9)
// 每个元素累加 从左到右相加
val res1: Int = list.reduce(_+_) // 25
//1-3)-5)-7)-9
val res2: Int = list.reduce(_ - _) // -23
val arr = Array("haha", "heihei", "hehe")
// x 前面的元素 y 后面的元素 实现集合中字符串的拼接
val res3: String = arr.reduce((x, y) => x + " " + y) //haha heihei hehe
// 键值对元素的
val map = Map(("shaolin",88),("emei", 77),("wudang",99))
//(shaolin emei wudang,264) key value分别做归约操作
val res4: (String, Int) = map.reduce((m1,m2)=>(m1._1+" "+m2._1 , m1._2+ m2._2)) |
7.8.19reduceLeft和reduceRight
| Scala
val list = List(1, 3, 5, 7, 9)
val arr = Array("a", "b", "c","d","e")
val map = Map(("shaolin",88),("emei", 77),("wudang",99))
// 执行顺序是 1+3)+5)+7)+9
val res1: Int = list.reduceLeft(_+_)
// 1-3)-5)-7)-9
val res01: Int = list.reduceLeft(_-_)
val res2: String = arr.reduceLeft((a1, a2)=>a1+","+a2)
val res3: (String, Int) = map.reduceLeft((m1,m2)=>(m1._1+" "+m2._1 , m1._2+ m2._2))
println(res1) //25
println(res2) //a,b,c,d,e
println(res3)//(shaolin emei wudang,264)
val res11: Int = list.reduceRight(_+_) // 25
// 执行顺序是 a,(b,(c,(d,e))) a2 右边的最后一个元素
val res12: String = arr.reduceRight((a1, a2)=>a1+","+a2)//a,b,c,d,e
val res13: (String, Int) = map.reduceRight((m1,m2)=>(m1._1+" "+m2._1 , m1._2+ m2._2))//(shaolin emei wudang,264)
// 5-(7-9)-->5-(7-9)-->3-(5-(7-9))-->1-(3-(5-(7-9)))
val res14: Int = list.reduceRight(_-_)
println(res14) // 5
println(res11) //25
println(res12) //a,b,c,d,e
println(res13)//(shaolin emei wudang,264)
// 字符串的拼接
arr.reduce(_ ++ _)
// 字符串的拼接
println(arr.reduce(_ ++"."++ _)) |
7.8.20fold,foldLeft 和foldRight
归约操作类似于reduce函数 ,但是fold函数中多出来一个初始值
| Scala
val arr = Array("tom" , "cat" , "jim" , "rose")
// 遍历集合中的每个元素进行拼接 比reduce函数多出一个初始值
val res = arr.fold("hello")(_+" "+_)
val ls = List(1,3,5,7)
// 100+1)+3)+5)+7 底层调用的是 foldLeft
val res2 = ls.fold(100)(_+_) // 116
ls.foldLeft(100)(_+_) // 116
从右边开始运算 默认的值先参与运算进来
// 7-10)-->5-(-3)-->3-8 -->1-(-5)
val res01: Int = ls.foldRight(10)(_-_) //6 |

7.8.21交集差集并集
| Scala
val arr1 = Array(1, 3, 5, 7, 0)
val arr2 = Array(5, 7, 8, 9)
val res1: Array[Int] = arr1.intersect(arr2) // 交集 5 7
val res2: Array[Int] = arr1.diff(arr2) // 差集 1 3
// 单纯的合并两个元素中的数据
val res3: mutable.ArraySeq[Int] = arr1.union(arr2) // 1,3,5,7 ,5,7,8,9
// 去除重复数据
val res4: mutable.ArraySeq[Int] = res3.distinct //,3,5,7,8,9 |
7.8.22distinct和distinctBy
去除集合中的重复的元素 ,可以去除简单类型的数据, 也可以除去自定义的类型(底层依然是hashcode和equals)
| Scala
val arr1 = Array("a", "a","ab","cat" ,"hellocat" ,"hicat")
val newarr: Array[String] = arr1.distinct
newarr.foreach(println) |
条件去重
| Scala
val arr1 = Array(new User("ls",21),new User("ls",22),new User("zss",21))
// 去除重名的重复数据
val res: Array[User] = arr1.distinctBy(x=>x.age)
res.foreach(x=> println(x.name)) |
7.8.23zip
实现拉链式拼接, 只要操作的集合是迭代集合就可以拼接
| Scala
val list1 = List("a" , "b" , "c" , "d")
val arr1 = Array(1,2,3,4)
val map = Map[String,Int]("aa"->11,"cc"->22,"dd"->33)
// 以两个迭代集合中少的一方为基准对偶拼接List((a,1), (b,2), (c,3))
val res: List[(String, Int)] = list1.zip(arr1)
//ArraySeq((1,(aa,11)), (2,(cc,22)), (3,(dd,33)))
val res2: Array[(Int, (String, Int))] = arr1.zip(map) |
7.8.24zipWithIndex
简单理解为 遍历集合中的每个元素 , 将每个元素打上对应的索引值 , 组成元组(element , index) 返回新的集合 !
| Scala
val list1 = List("a" , "b" , "c" , "d")
val arr1 = Array(1,2,3,4)
val map = Map[String,Int]("aa"->11,"cc"->22,"dd"->33)
// List(((a,1),0), ((b,2),1), ((c,3),2), ((d,4),3))
list1.zip(arr1).zipWithIndex
//List((a,0), (b,1), (c,2), (d,3))
list1.zipWithIndex |
7.8.25scan
一个初始值开始,从左向右遍历每个元素,进行积累的op操作
| Scala
val arr = Array("cat" , "jim" , "tom")
// ArraySeq(hello, hello cat, hello cat jim, hello cat jim tom)
arr.scan("hello" )(_ +" "+ _)
val nums = List(1,2,3)
// List(10,10+1,10+1+2,10+1+2+3) = List(10,11,13,16)
val result = nums.scan(10)(_+_)
nums.foldLeft(10)(_+_) // 16 |
7.8.26mkString
将集合中的每个元素拼接成字符串
| Scala
val arr = Array("a", "b", "c")
val str = arr.mkString
arr.mkString(" ")
arr.reduce(_+_)
arr.reduce(_ + " " + _) |
7.8.27slice,sliding
slice(from: Int, until: Int): List[A] 提取列表中从位置from到位置until(不含该位置)的元素列表, 起始位置角标从0开始;
| Scala
val arr = Array("a", "b", "c" ,"d","e","f")
arr.slice(0 ,2) // res0: Array[String] = ArraySeq(a, b) |
sliding(size: Int, step: Int): Iterator[List[A]] 将列表按照固定大小size进行分组,步进为step,step默认为1,返回结果为迭代器;
| Scala
val nums = List(1,1,2,2,3,3,4,4)
// 参数一:子集的大小 参数二:步进
val res: Iterator[List[Int]] = nums.sliding(2,2)
res.toList // List(List(1, 1), List(2, 2), List(3, 3), List(4, 4)) |
7.8.28take,takeRight,takeWhile
| Scala
val arr = Array("a", "b", "c" ,"d","e","f")
// 从左边获取三个元素,组成新的数组集合
arr.take(3) |
| Scala
val nums = List(1,1,1,1,4,4,4,4)
val right = nums.takeRight(4) // List(4,4,4,4) |
| Scala
// 小于4 终止
nums.takeWhile(_ < 4)
val names = Array ("cat", "com","jim" , "scala" ,"spark")
// 从左到右遍历符合遇到不符合条件的终止,储存在新的集合中
names.takeWhile(_.startsWith("c")) |
7.8.29Aggregate聚合
全局聚合
aggregate方法是一个聚合函数,接受多个输入,并按照一定的规则运算以后输出一个结果值,在2.13+版本中被foldLeft取代!
7.8.30集合间的转换函数
可变集合和不可变集合的转换