python基于卷积神经网络实现自定义数据集训练与测试
注意:
如何更改图像尺寸在这篇文章中,修改完之后你就可以把你自己的数据集应用到网络。如果你的训练集与测试集也分别为30和5,并且样本类别也为3类,那么你只需要更改图像标签文件地址以及标签内容(如下面两图所示)。 图片名-标签文件如何生成请看这篇文章。
如果你想扩大数据集量,那么你只需要更改对应的文件内标签长度以及数据集图像量。


再次注意:我已经扩大了数据集的数量,展示在正文1的后面!
正文1:
样本取自岩心照片,识别岩心是最基础的地质工作,如果用机器来划分岩心类型则会大大削减工作量。
下面叙述中0指代Anhydrite_rock(膏岩),1指代Limestone(灰岩),2指代Gray Anhydrite_rock(灰质膏岩)。
原本自定义训练集与测试集是这样的:
训练集x_train:

标签是这样的y_train:

测试集x_test:
标签是这样的y_test:

但是由于图片像素为3456*5184,电脑内存不足,所以只能统一修i该为下面(256*256):
训练集:

测试集:

两个数据集的标签没有更改。
#导入库
import os
import cv2
import torch
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
from torchvision.io import read_image
from torch.utils.data import Dataset
from torch.utils.data import DataLoader
from torchvision import transforms
import tensorflow.keras as ka
import datetime
import tensorflow as tf
import os
import PySide2
from tensorflow.keras.layers import Conv2D,BatchNormalization,Activation,MaxPooling2D,Dropout,Flatten,Dense
from tensorflow.keras import Model
import tensorflow as tf
'''加载数据集'''
#创建自定义数据集类,参考可见:http://t.csdn.cn/gkVNC
class Custom_Dataset(Dataset):
#函数,设置图像集路径索引、图像标签文件读取
def __init__(self, img_dir, img_label_dir, transform=None):
super().__init__()
self.img_dir = img_dir
self.img_labels = pd.read_csv(img_label_dir)
self.transform = transform
#函数,设置数据集长度
def __len__(self):
return len(self.img_labels)
#函数,设置指定图像读取、指定图像标签索引
def __getitem__(self, index):
#'所在文件路径+指定图像名'
img_path = os.path.join(self.img_dir + self.img_labels.iloc[index, 1])
#读指定图像
#image = cv2.imdecode(np.fromfile(img_path,dtype=np.uint8),-1)
image=plt.imread(img_path)
#height,width = image.shape[0],image.shape[1] #获取原图像的垂直方向尺寸和水平方向尺寸。
#image = image.resize((height//4,width//4))
#'指定图像标签'
label = self.img_labels.iloc[index, 0]
return image, label
'''画图函数'''
def tensorToimg(img_tensor):
img=img_tensor
plt.imshow(img)
#python3.X必须加下行
plt.show()
#标签指示含义
label_dic = {0: '膏岩', 1: '灰岩', 2: '灰质膏岩'}
'''图像集及标签路径'''
label_path = "C:/Users/yeahamen/AppData/Local/Programs/Python/Python310/train_label.csv"
img_root_path = "C:/Users/yeahamen/Desktop/custom_dataset/train_revise/"
test_image_path="C:/Users/yeahamen/Desktop/custom_dataset/test_revise/"
test_label_path="C:/Users/yeahamen/AppData/Local/Programs/Python/Python310/test_label.csv"
#加载图像集与标签路径到函数
#实例化类
dataset = Custom_Dataset(img_root_path, label_path)
dataset_test = Custom_Dataset(test_image_path,test_label_path)
'''查看指定图像(18)'''
#索引指定位置的图像及标签
image, label = dataset.__getitem__(18)
#展示图片及其形状(tensor)
print('单张图片(18)形状:',image.shape)
print('单张图片(18)标签:',label_dic[label])
#批量输出
dataloader = DataLoader(dataset, batch_size=1, shuffle=True)
'''查看图像的形状'''
for imgs, labels in dataloader:
print('一批训练为1张图片(随机)形状:',imgs.shape)
#一批图像形状:torch.Size([5, 3456, 5184, 3])
print('一批训练为1张图片(随机)标签:',labels)
#标签:tensor([3, 2, 3, 3, 1])
break
#仅需要查看一批
'''查看自定义数据集'''
showimages=[]
showlabels=[]
#把图片信息依次加载到列表
for imgs, labels in dataloader:
c = torch.squeeze(imgs, 0)#减去一维数据形成图片固定三参数
d = torch.squeeze(labels,0)
showimages.append(c)
showlabels.append(d)
#依次画出图片
def show_image(nrow, ncol, sharex, sharey):
fig, axs = plt.subplots(nrow, ncol, sharex=sharex, sharey=sharey, figsize=(10, 10))
for i in range(0,nrow):
for j in range(0,ncol):
axs[i,j].imshow(showimages[i*4+j])
axs[i,j].set_title('Label={}'.format(showlabels[i*4+j]))
plt.show()
plt.tight_layout()
#给定参数
#show_image(2, 4, False, False)
'''创建训练集与测试集'''
dataloader_train = DataLoader(dataset, batch_size=30, shuffle=True)
for imgs, labels in dataloader_train:
x_train=imgs
y_train=labels
print('训练集图像形状:',x_train.shape)
print('训练集标签形状:',y_train.shape)
dataloader_test = DataLoader(dataset_test, batch_size=5, shuffle=True)
for imgs, labels in dataloader_test:
x_test=imgs
y_test=labels
print('测试集图像形状:',x_test.shape)
print('测试集标签形状:',y_test.shape)
'''将图像转变为网络可用的数据类型'''
x_train,x_test = tf.cast(x_train/255.0,tf.float32),tf.cast(x_test/255.0,tf.float32)
y_train,y_test = tf.cast(y_train,tf.int16),tf.cast(y_test,tf.int16)
#参考:http://t.csdn.cn/eRQX2
print('注意:',x_train.shape)
'''归一化灰度值'''
x_train = x_train/255
x_test = x_test/255
'''标签转为独热编码,注意:如果标签不是从0开始,独热编码会增加1位(即0)'''
y_train = ka.utils.to_categorical(y_train)
y_test = ka.utils.to_categorical(y_test)
print('独热后训练集标签形状:',y_train.shape)
print('独热后测试集标签形状:',y_test.shape)
#获取测试集特征数
num_classes = y_test.shape[1]
'''CNN模型'''
#输入3456*5184*3
model = ka.Sequential([ka.layers.Conv2D(filters = 32,kernel_size=(5,5),input_shape=(256,256,3),data_format="channels_last",activation='relu'),
#卷积3456*5184*32、卷积层;参量依次为:卷积核个数、卷积核尺寸、单个像素点尺寸、使用ReLu激活函数、解释可见:http://t.csdn.cn/6s3dz
ka.layers.MaxPooling2D(pool_size=(4,4),strides = None,padding='VALID'),
#池化1—864*1296*32、最大池化层,池化核尺寸4*4、步长默认为4、无填充、解释可见:http://t.csdn.cn/sES2u
ka.layers.MaxPooling2D(pool_size=(2,2),strides = None,padding='VALID'),
#池化2—432*648*32再加一个最大池化层,池化核尺寸为2*2、步长默认为2、无填充
ka.layers.Dropout(0.2),
#模型正则化防止过拟合, 只会在训练时才会起作用,随机设定输入的值x的某一维=0,这个概率为输入的百分之20,即丢掉1/5神经元不激活
#在模型预测时,不生效,所有神经元均保留也就是不进行dropout。解释可见:http://t.csdn.cn/RXbmS、http://t.csdn.cn/zAIuJ
ka.layers.Flatten(),
#拉平432*648*32=8957952;拉平池化层为一个向量
ka.layers.BatchNormalization(),
#批标准化层,提高模型准确率
ka.layers.Dense(10,activation='relu'),
#全连接层1,10个神经元,激活函数为ReLu
ka.layers.Dense(num_classes,activation='softmax')])
#全连接层2,3个神经元(对应标签0-2),激活函数为softmax,作用是把神经网络的输出转化为概率,参考可见:http://t.csdn.cn/bcWgu;http://t.csdn.cn/A1Jyn
'''模型参数展示、编译与训练'''
model.summary()
model.compile(loss='categorical_crossentropy',optimizer='adam',metrics=['accuracy'])
startdate = datetime.datetime.now()
#训练轮数epochs=n,即训练n轮
model.fit(x_train,y_train,validation_data=(x_test,y_test),epochs=100,batch_size=1,verbose=2)
#训练样本、训练标签、指定验证数据为测试集、训练轮数、显示每一轮训练进程,参考可见:http://t.csdn.cn/oE46K
#获取训练结束时间
enndate=datetime.datetime.now()
print("训练用时:"+str(enndate-startdate))程序运行结果是这样的:
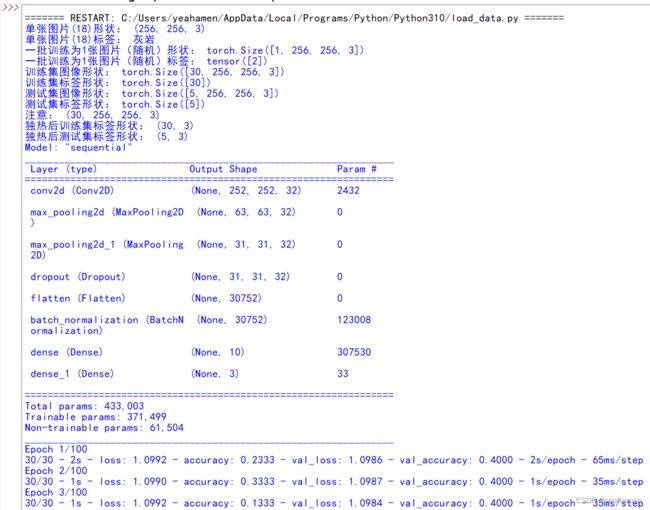
显然由于样本过少,模型训练精度并不高,3轮训练达到0.4;如果有时间再进一步增加样本数量并完善。
正文2
由之前的30个训练集、5个测试集扩大到320个训练集,40个测试集:
训练集:
测试集 :
修改后的代码如下,你可以与上面的代码进行对比,从而修改数据集量为适合你的大小!
#导入库
import os
import cv2
import torch
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
from torchvision.io import read_image
from torch.utils.data import Dataset
from torch.utils.data import DataLoader
from torchvision import transforms
import tensorflow.keras as ka
import datetime
import tensorflow as tf
import os
import PySide2
from tensorflow.keras.layers import Conv2D,BatchNormalization,Activation,MaxPooling2D,Dropout,Flatten,Dense
from tensorflow.keras import Model
import tensorflow as tf
'''加载数据集'''
#创建自定义数据集类,参考可见:http://t.csdn.cn/gkVNC
class Custom_Dataset(Dataset):
#函数,设置图像集路径索引、图像标签文件读取
def __init__(self, img_dir, img_label_dir, transform=None):
super().__init__()
self.img_dir = img_dir
self.img_labels = pd.read_csv(img_label_dir)
self.transform = transform
#函数,设置数据集长度
def __len__(self):
return len(self.img_labels)
#函数,设置指定图像读取、指定图像标签索引
def __getitem__(self, index):
#'所在文件路径+指定图像名'
img_path = os.path.join(self.img_dir + self.img_labels.iloc[index, 1])
#读指定图像
#image = cv2.imdecode(np.fromfile(img_path,dtype=np.uint8),-1)
image=plt.imread(img_path)
#height,width = image.shape[0],image.shape[1] #获取原图像的垂直方向尺寸和水平方向尺寸。
#image = image.resize((height//4,width//4))
#'指定图像标签'
label = self.img_labels.iloc[index, 0]
return image, label
'''画图函数'''
def tensorToimg(img_tensor):
img=img_tensor
plt.imshow(img)
#python3.X必须加下行
plt.show()
#标签指示含义
label_dic = {0: '膏岩', 1: '灰岩', 2: '灰质膏岩',3: '膏质灰岩'}
'''图像集及标签路径'''
label_path = "C:/Users/yeahamen/AppData/Local/Programs/Python/Python310/train_label.csv"
img_root_path = "C:/Users/yeahamen/Desktop/custom_dataset/train_revise/"
test_image_path="C:/Users/yeahamen/Desktop/custom_dataset/test_revise/"
test_label_path="C:/Users/yeahamen/AppData/Local/Programs/Python/Python310/test_label.csv"
#加载图像集与标签路径到函数
#实例化类
dataset = Custom_Dataset(img_root_path, label_path)
dataset_test = Custom_Dataset(test_image_path,test_label_path)
'''查看指定图像(18)'''
#索引指定位置的图像及标签
image, label = dataset.__getitem__(18)
#展示图片及其形状(tensor)
print('单张图片(18)形状:',image.shape)
print('单张图片(18)标签:',label_dic[label])
#批量输出
dataloader = DataLoader(dataset, batch_size=1, shuffle=True)
'''查看图像的形状'''
for imgs, labels in dataloader:
print('一批训练为1张图片(随机)形状:',imgs.shape)
#一批图像形状:torch.Size([5, 256, 256, 3])
print('一批训练为1张图片(随机)标签:',labels)
#标签:tensor([3, 2, 3, 3, 1])
break
#仅需要查看一批
'''查看自定义数据集'''
showimages=[]
showlabels=[]
#把图片信息依次加载到列表
for imgs, labels in dataloader:
c = torch.squeeze(imgs, 0)#减去一维数据形成图片固定三参数
d = torch.squeeze(labels,0)
showimages.append(c)
showlabels.append(d)
#依次画出图片
def show_image(nrow, ncol, sharex, sharey):
fig, axs = plt.subplots(nrow, ncol, sharex=sharex, sharey=sharey, figsize=(10, 10))
for i in range(0,nrow):
for j in range(0,ncol):
axs[i,j].imshow(showimages[i*4+j])
axs[i,j].set_title('Label={}'.format(showlabels[i*4+j]))
plt.show()
plt.tight_layout()
#给定参数
#show_image(2, 4, False, False)
'''创建训练集与测试集'''
dataloader_train = DataLoader(dataset, batch_size=320, shuffle=True)
for imgs, labels in dataloader_train:
x_train=imgs
y_train=labels
print('训练集图像形状:',x_train.shape)
print('训练集标签形状:',y_train.shape)
dataloader_test = DataLoader(dataset_test, batch_size=40, shuffle=True)
for imgs, labels in dataloader_test:
x_test=imgs
y_test=labels
print('测试集图像形状:',x_test.shape)
print('测试集标签形状:',y_test.shape)
'''将图像转变为网络可用的数据类型'''
X_test = x_test#这里保留是为了预测时查看原始图像
Y_test = y_test#这里保留是为了预测时查看原始标签
x_train,x_test = tf.cast(x_train/255.0,tf.float32),tf.cast(x_test/255.0,tf.float32)
y_train,y_test = tf.cast(y_train,tf.int16),tf.cast(y_test,tf.int16)
#参考:http://t.csdn.cn/eRQX2
print('注意:',x_train.shape)
'''归一化灰度值'''
x_train = x_train/255
x_test = x_test/255
'''标签转为独热编码,注意:如果标签不是从0开始,独热编码会增加1位(即0)'''
y_train = ka.utils.to_categorical(y_train)
y_test = ka.utils.to_categorical(y_test)
print('独热后训练集标签形状:',y_train.shape)
print('独热后测试集标签形状:',y_test.shape)
#获取测试集特征数
num_classes = y_test.shape[1]
'''CNN模型'''
#输入256*256*3
model = ka.Sequential([ka.layers.Conv2D(filters = 32,kernel_size=(5,5),input_shape=(256,256,3),data_format="channels_last",activation='relu'),
#卷积252*252*32、卷积层;参量依次为:卷积核个数、卷积核尺寸、单个像素点尺寸、使用ReLu激活函数、解释可见:http://t.csdn.cn/6s3dz
ka.layers.MaxPooling2D(pool_size=(4,4),strides = None,padding='VALID'),
#池化1—63*63*32、最大池化层,池化核尺寸4*4、步长默认为4、无填充、解释可见:http://t.csdn.cn/sES2u
ka.layers.MaxPooling2D(pool_size=(2,2),strides = None,padding='VALID'),
#池化2—31*31*32再加一个最大池化层,池化核尺寸为2*2、步长默认为2、无填充
ka.layers.Dropout(0.2),
#模型正则化防止过拟合, 只会在训练时才会起作用,随机设定输入的值x的某一维=0,这个概率为输入的百分之20,即丢掉1/5神经元不激活
#在模型预测时,不生效,所有神经元均保留也就是不进行dropout。解释可见:http://t.csdn.cn/RXbmS、http://t.csdn.cn/zAIuJ
ka.layers.Flatten(),
#拉平432*648*32=8957952;拉平池化层为一个向量
ka.layers.BatchNormalization(),
#批标准化层,提高模型准确率
ka.layers.Dense(50,activation='relu'),
#全连接层1,10个神经元,激活函数为ReLu
ka.layers.Dense(num_classes,activation='softmax')])
#全连接层2,4个神经元(对应标签0-3),激活函数为softmax,作用是把神经网络的输出转化为概率,参考可见:http://t.csdn.cn/bcWgu;http://t.csdn.cn/A1Jyn
'''模型参数展示、编译与训练'''
model.summary()
model.compile(loss='categorical_crossentropy',optimizer='adam',metrics=['accuracy'])
startdate = datetime.datetime.now()
#训练轮数epochs=n,即训练n轮
history = model.fit(x_train,y_train,validation_data=(x_test,y_test),epochs=40,batch_size=5,verbose=2)
#训练样本、训练标签、指定验证数据为测试集、训练轮数、显示每一轮训练进程,参考可见:http://t.csdn.cn/oE46K
#获取训练结束时间
enndate=datetime.datetime.now()
print("训练用时:"+str(enndate-startdate))
#模型损失值与精度画图展示
#参考http://t.csdn.cn/fUdtO
print(history.history)
loss = history.history['loss'] #训练集损失
val_loss = history.history['val_loss'] #测试集损失
acc = history.history['accuracy'] #训练集准确率
val_acc = history.history['val_accuracy'] #测试集准确率
plt.figure(figsize=(10,3))
plt.subplot(121)
plt.plot(loss,color='b',label='train')
plt.plot(val_loss,color='r',label='test')
plt.ylabel('Loss')
plt.legend()
plt.subplot(122)
plt.plot(acc,color='b',label='train')
plt.plot(val_acc,color='r',label='test')
plt.ylabel('Accuracy')
plt.legend()
plt.show()
plt.figure(2)
'''使用模型进行预测'''
for i in range(10):#在测试集中随机选10个
random_test = np.random.randint(1,40)
plt.subplot(2,5,i+1)
plt.axis('off')#去掉坐标轴
plt.imshow(X_test[random_test])#展示要预测的图片
predict_image = tf.reshape(x_test[random_test],(1,256,256,3))
y_label_predict = np.argmax(model.predict(predict_image))#使用模型进行预测
plt.title('R_value:'+str(Y_test[random_test])+'\nP_value:'+str(y_label_predict))#图名显示预测值与实际标签值进行对比
plt.show()
在这里我展示无论训练几轮都会有的输出面板:

下面展示训练5轮、10轮、20轮、40轮的结果。
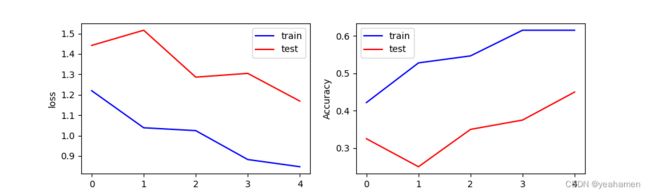
训练5轮结果:


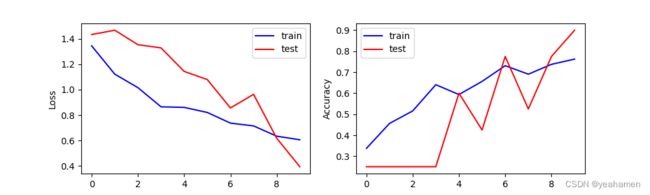
训练10轮结果:


训练20轮结果:



训练40轮结果:


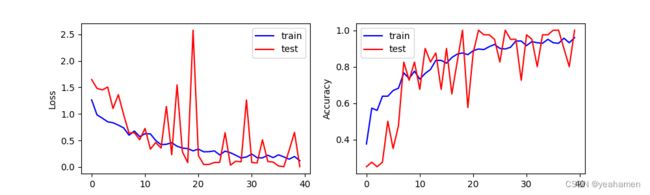
 识别精度的提升是显而易见的!
识别精度的提升是显而易见的!
最后放上整个实践过程用到的模块:
| import os |
| import cv2 |
| import torch |
| import pylab |
| import PySide2 |
| import datetime |
| import numpy as np |
| import pandas as pd |
| from PIL import Image |
| import tensorflow as tf |
| import tensorflow.keras as ka |
| from torchvision import models |
| import matplotlib.pyplot as plt |
| from tensorflow.keras import Model |
| from torchvision import transforms |
| from torch.utils.data import Dataset |
| from torchvision.io import read_image |
| from torch.utils.data import DataLoader |
| import tensorflow.keras.applications.vgg19 as vgg19 |
| import tensorflow.keras.preprocessing.image as imagepre |
| from tensorflow.keras.layers import Conv2D,BatchNormalization,Activation,MaxPooling2D,Dropout,Flatten,Dense |