原文链接:http://tecdat.cn/?p=2687
原文出处:拓端数据部落公众号
什么是MCMC,什么时候使用它?
MCMC只是一个从分布抽样的算法。
这只是众多算法之一。这个术语代表“马尔可夫链蒙特卡洛”,因为它是一种使用“马尔可夫链”(我们将在后面讨论)的“蒙特卡罗”(即随机)方法。MCMC只是蒙特卡洛方法的一种,尽管可以将许多其他常用方法看作是MCMC的简单特例。
我为什么要从分布中抽样?
从分布中抽取样本是解决一些问题的最简单的方法。
可能MCMC最常用的方法是从贝叶斯推理中的某个模型的后验概率分布中抽取样本。通过这些样本,你可以问一些问题:“参数的平均值和可信度是多少?”。
如果这些样本是来自分布的独立样本,则 估计均值将会收敛在真实均值上。
假设我们的目标分布是一个具有均值m和标准差的正态分布s。
作为一个例子,考虑用均值m和标准偏差s来估计正态分布的均值(在这里,我将使用对应于标准正态分布的参数):
我们可以很容易地使用这个rnorm 函数从这个分布中抽样
seasamples<-rn 000,m,s)样本的平均值非常接近真实平均值(零):
mean(sa es)
## \[1\] -0. 537事实上,在这种情况下,$ n $样本估计的预期方差是$ 1 / n $,所以我们预计大部分值在$ \ pm 2 \,/ \ sqrt {n} = 0.02 。
summary(re 0,mean(rnorm(10000,m,s))))
## Min. 1st Qu. Median Mean 3rd Qu. Max.
## -0.03250 -0.00580 0.00046 0.00042 0.00673 0.03550这个函数计算累积平均值之和。
cummean<-fun msum(x)/seq_along(x)
plot(cummaaSample",ylab="Cumulative mean",panel.aabline(h=0,col="red"),las=1)
将x轴转换为对数坐标并显示另外30个随机方法:

可以从您的一系列采样点中抽取样本分位数。
这是分析计算的点,其概率密度的2.5%低于:
p<-0.025
a.true<-qnorm(p,m,s)
a.true
1## \[1\] -1.96我们可以通过在这种情况下的直接整合来估计这个
aion(x)
dnorm(x,m,s)
g<-function(a)
integrate(f,-Inf,a)$value
a.int<-uniroot(function(x)g(a10,0))$roota.int
1## \[1\] -1.96并用Monte Carlo积分估计点:
a.mc<-unnasamples,p))
a.mc
## \[1\] -2.023
a.true-a.mc
## \[1\] 0.06329但是,在样本量趋于无穷大的极限内,这将会收敛。此外,有可能就错误的性质作出陈述; 如果我们重复采样过程100次,那么我们得到一系列与均值附近的误差相同幅度的误差的估计:
a.mc<-replicate(anorm(10000,m,s),p))
summary(a.true-a.mc)
## Min. 1st Qu. Median Mean 3rd Qu. Max.
## -0.05840 -0.01640 -0.00572 -0.00024 0.01400 0.07880这种事情真的很常见。在大多数贝叶斯推理中,后验分布是一些(可能很大的)参数向量的函数,您想对这些参数的子集进行推理。
在一个等级模型中,你可能会有大量的随机效应项被拟合,但是你最想对一个参数做出推论。在
贝叶斯框架中,您可以计算您感兴趣的参数在所有其他参数上的边际分布(这是我们上面要做的)。
为什么“传统统计”不使用蒙特卡洛方法?
对于传统教学统计中的许多问题,不是从分布中抽样,可以使函数最大化或最大化。所以我们需要一些函数来描述可能性并使其最大化(最大似然推理),或者一些计算平方和并使其最小化的函数。
然而,蒙特卡罗方法在贝叶斯统计中的作用与频率统计中的优化程序相同,这只是执行推理的算法。所以,一旦你基本知道MCMC正在做什么,你可以像大多数人把他们的优化程序当作黑匣子一样对待它,像一个黑匣子。
马尔可夫链蒙特卡罗
假设我们想要抽取一些目标分布,但是我们不能像从前那样抽取独立样本。有一个使用马尔科夫链蒙特卡洛(MCMC)来做这个的解决方案。首先,我们必须定义一些事情,以便下一句话是有道理的:我们要做的是试图构造一个马尔科夫链,它抽样的目标分布作为它的平稳分布。
定义
假设我们有一个三态马尔科夫过程。让我们P为链中的转移概率矩阵:
P<-rbind(a(.2,.1,.7),c(.25,.25,.5))
P
## \[,1\] \[,2\] \[,3\]
## \[1,\] 0.50 0.25 0.25
## \[2,\] 0.20 0.10 0.70
## \[3,\] 0.25 0.25 0.50
rowSums(P)
## \[1\] 1 1 1P[i,j]给出了从状态i到状态的概率j。
请注意,与行不同,列不一定总和为1:
colSums(P)
## \[1\] 0.95 0.60 1.45这个函数采用一个状态向量x(其中x[i]是处于状态的概率i),并通过将其与转移矩阵相乘来迭代它P,使系统前进到n步骤。
iterate.P<-function(x,P,n){
res<-matrix(NA,n+1,len
a<-xfor(iinseq_len(n))
res\[i+1,\]<-x<-x%*%P
res}从处于状态1的系统开始(x向量 [1,0,0] 也是如此,表示处于状态1的概率为100%,不处于任何其他状态)
同样,对于另外两种可能的起始状态:
y2<-iterate.P(c(0,1,0),P,n)
y3<-iterate.P(c(0,0,1),P,n)这表明了平稳分布的收敛性。
ma=1,xlab="Step",ylab="y",las=1)
matlines(0:n,y2,lty=2)
matlines(0:n,y3,lty=3)
我们可以使用R的eigen函数来提取系统的主要特征向量(t()这里转置矩阵以便得到左特征向量)。
v<-eigen(t(P)
ars\[,1\]
v<-v/sum(v)# 归一化特征向量然后在之前的数字上加上点,表明我们有多接近收敛:
matplot(0:n,y1a3,lty=3)
points(rep(10,3),v,col=1:3)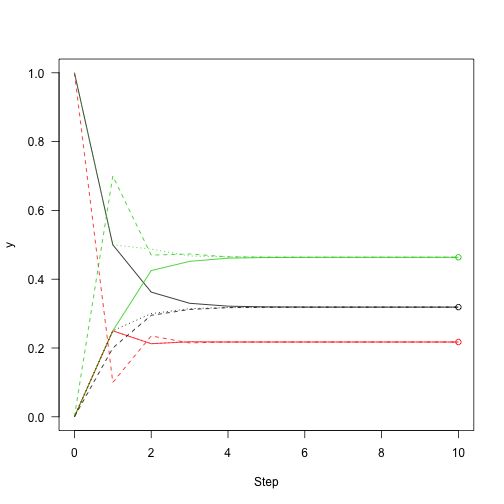
上面的过程迭代了不同状态的总体概率; 而不是通过系统的实际转换。所以,让我们迭代系统,而不是概率向量。
run<-function(i,P,n){
res<-integer(n)
for(a(n))
res\[\[t\]\]<-i<-sample(nrow(P),1,pr=P\[i,\])
res}这链条运行了100个步骤:
samples<-run(1,P,100)
ploaes,type="s",xlab="Step",ylab="State",las=1)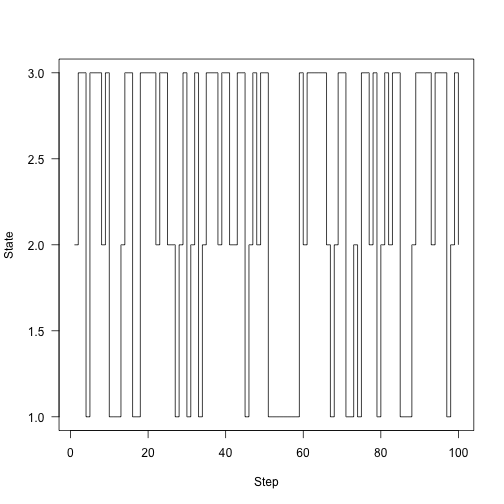
绘制我们在每个状态随时间变化的时间分数,而不是绘制状态:
plot(cummean(samplesa2)
lines(cummean(samples==3),col=3)
再运行一下(5000步)
n<-5000
set.seed(1)
samples<-run(1,P,n)
plot(cummeanasamples==2),col=2)
lines(cummean(samples==3),col=3)
abline(h=v,lty=2,col=1:3)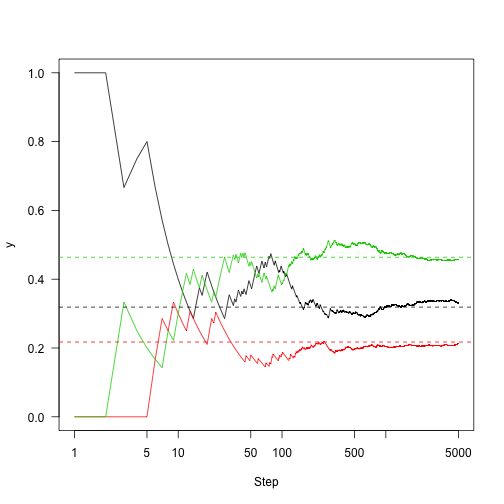
所以这里的关键是:马尔可夫链有一些不错的属性。马尔可夫链有固定的分布,如果我们运行它们足够长的时间,我们可以看看链条在哪里花费时间,并对该平稳分布进行合理的估计。
Metropolis算法
这是最简单的MCMC算法。
MCMC采样1d(单参数)问题
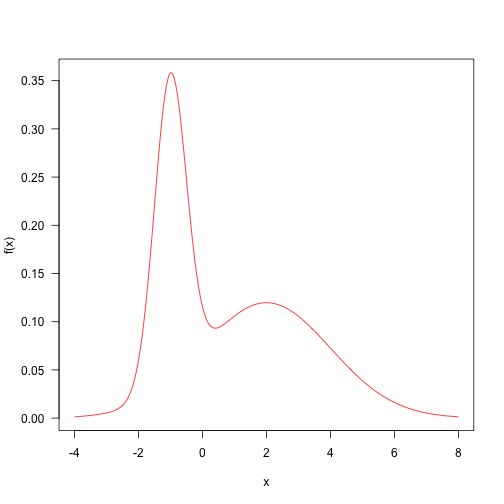
这是两个正态分布的加权和。这种分布相当简单,可以从MCMC中抽取样本。
这里是一些参数和目标密度的定义。
p<-0.4ma1,2)
sd<-c(.5,2)
f<-function(x)p\*dnora\],sd\[1\])+(1-p)\*dnorm(x,mu\[2\],sd\[2\])概率密度绘制
我们来定义一个非常简单的算法,该算法从以当前点为中心的标准偏差为4的正态分布中抽样
而这只需要运行MCMC的几个步骤。它将从点x返回一个矩阵,其nsteps行数和列数与x元素的列数相同。如果在标量上运行, x它将返回一个向量。
run<-funagth(x))
for(iinseq_len(nsteps))
res\[i,\]<-x<-step(x,f,q)
drop(res)}这里是马尔可夫链的前1000步,目标密度在右边:
layout(matrix(ca,type="s",xpd=NA,ylab="Parameter",xlab="Sample",las=1)
usr<-par("usr")
xx<-seq(usr\[a4\],length=301)
plot(f(xx),xx,type="l",yaxs="i",axes=FALSE,xlab="")
hist(res,5aALSE,main="",ylim=c(0,.4),las=1,xlab="x",ylab="Probability density")
z<-integrate(f,-Inf,Inf)$valuecurve(f(x)/z,add=TRUE,col="red",n=200)
运行更长时间,结果开始看起来更好:
res.long<-run(-10,f,q,50000)
hist(res.long,100,freq=FALSE,main="",ylim=c(0,.4),las=1,xlab
现在,运行不同的方案 - 一个标准差很大(33),另一个标准差很小(3)。
res.fast<-run(-10action(x)
rnorm(1,x,33),1000)
res.slow<-run(-10,f,functanorm(1,x,.3),1000)注意三条轨迹正在移动的不同方式。

相反,红色的痕迹拒绝其中的大部分空间。
蓝色的踪迹提出了倾向于被接受的小动作,但是它随着大部分的轨迹随机行走。它需要数百次迭代才能达到概率密度的大部分。
您可以在随后的参数中看到不同方案步骤在自相关中的效果 - 这些图显示了不同滞后步骤之间自相关系数的衰减,蓝线表示统计独立性。
par(mfrow=c(1,3ain="Intermediate")
acf(res.fast,las=1,m
由此可以计算独立样本的有效数量:
1coda::effectiveSize(res)
1 2## var1 ## 187
1coda::effectiveSize(res.fast)
1 2## var1 ## 33.19
1coda::effectiveSize(res.slow)
1 2## var1 ## 5.378这更清楚地显示了链条运行时间更长的情况:
naun(-10,f,q,n))
xlim<-range(sapply(saa100)
hh<-lapply(samples,function(x)
hist(x,br,plot=FALSE))
ylim<-c(0,max(f(xx)))显示100,1,000,10,000和100,000步:
for(hinhh){plot(h,main="",freq=a=300)}
MCMC在两个维度
给出了一个多元正态密度,给定一个均值向量(分布的中心)和方差 - 协方差矩阵。
make.mvn<-function(mean,vcv){
logdet<-as.numeric(detea+logdet
vcv.i<-solve(vcv)function(x){
dx<-x-meanexp(-(tmp+rowSums((dx%*%vcv.i)*dx))/2)}}如上所述,将目标密度定义为两个mvns的总和(这次未加权):
mu1<-c(-1,1)mu2<-c(2,-2)
vcv1<-ma5,.25,1.5),2,2)
vcv2<-matrix(c(2,-.5,-.5,2aunctioax)+f2(x)x<-seq(-5,6,length=71)
y<-seq(-7,6,lena-expand.grid(x=x,y=y)
z<-matrix(aaTRUE)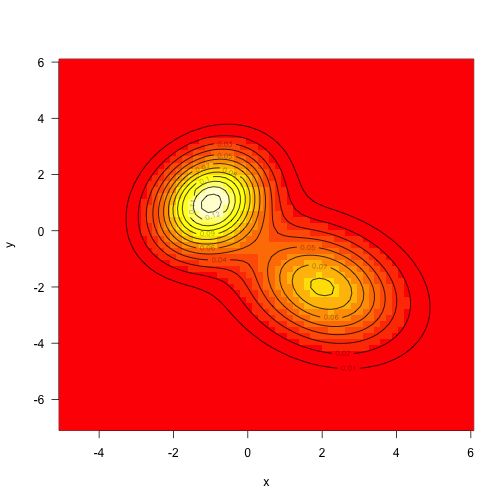
从多元正态分布取样也相当简单,但我们将使用MCMC从中抽取样本。
这里有一些不同的策略 - 我们可以同时在两个维度上提出动作,或者我们可以独立地沿着每个轴进行采样。这两种策略都能奏效,虽然它们的混合速度会有所不同。
假设我们实际上并不知道如何从mvn中抽样 ,让我们提出一个在两个维度上一致的提案分布,从每边的宽度为“d”的正方形取样。

比较抽样分布与已知分布:

例如,参数1 的边际分布是多少?
hisales\[,1\],freq=FALSa",xlab="x",ylab="Probability density")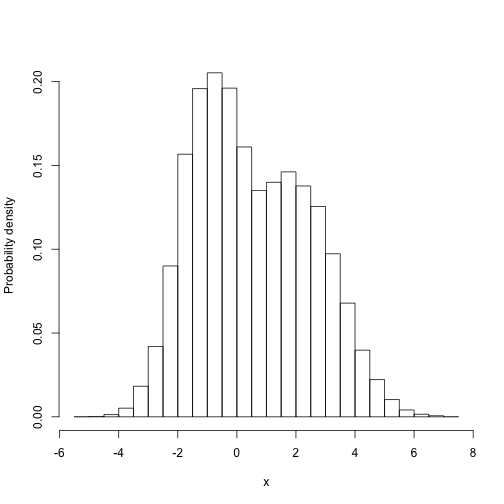
我们需要整合第一个参数的第二个参数的所有可能值。那么,因为目标函数本身并不是标准化的,所以我们必须将其分解为一维积分值 。
m<-function(x1){
g<-Vectorize(function(x2)f(c(x1,ae(g,-Inf,Inf)$value}
xx<-seq(mina\]),max(sales\[,1\]),length=201)
yy<-s
ue
hist(samples\[,1\],freq=FALSE,ma,0.25))
lines(xx,yy/z,col="red")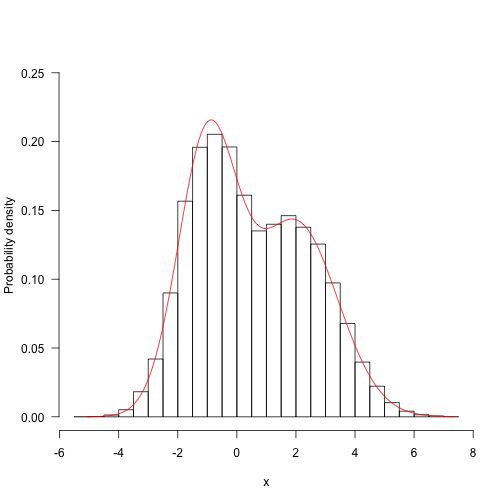

最受欢迎的见解
1.R语言中的马尔科夫机制转换(Markov regime switching)模型模型")
4.用机器学习识别不断变化的股市状况—隐马尔科夫模型(HMM)的应用的应用")
6.matlab中的隐马尔可夫模型(HMM)实现实现")
7.matlab实现MCMC的马尔可夫切换ARMA – GARCH模型