爬虫实战5:豆瓣读书爬取
文章目录
- 前言
- 一、页面解析
- 二、代码展示
- 1.引入库
- 2.主要代码展示
- 总结
前言
一、页面解析
第一步:本次爬取的内容是豆瓣网站上的读书标签,主要爬取的内容是文学下面的热门标签,涉及到的字段有
['大类别','小类别','类别数目','封面','书名','国家','作者','翻译人','出版社','出版日期','价格','评分','评价人数','简介']
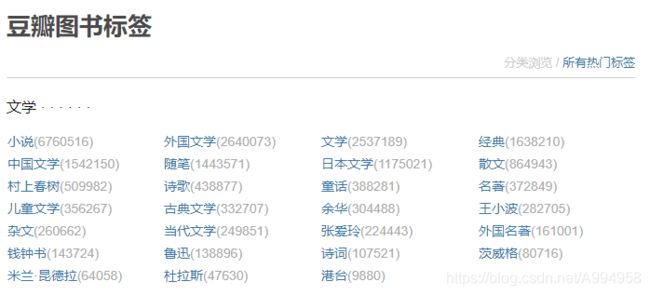

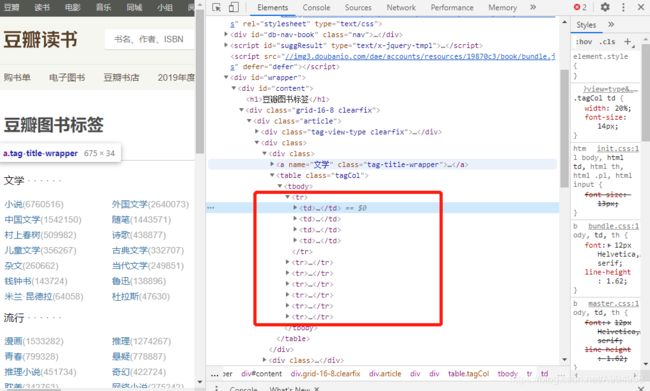
第二步:对需要爬取的字段进行页面解析,右键检查元素,找到需要爬取的字段元素
二、代码展示
1.引入库
import requests
from lxml import etree
import csv
import time2.代码书写
本次爬取的共有两个不同的页面,需要链接跳转到详细页面,构造跳转页面代码
def get_parse(result):
items = etree.HTML(result)
# print(items)
# 共6页,分为文学,流行,文化,生活,经管,科技
for i in range(1, 7):
item = items.xpath('//*[@id="content"]/div/div[1]/div[2]/div[{}]'.format(i))
for it in item:
# 归属大类
category = it.xpath('./a/@name')[0]
print(category)
# 辅助列
fuzhu = it.xpath('./table/tbody/tr')
for its in fuzhu:
try:
for j in range(1, 50):
# 小类型
leixing = its.xpath('./td[{}]/a/text()'.format(j))[0]
# 小类型链接
lianjie = its.xpath('./td[{}]/a/@href'.format(j))[0]
# 书籍数目
shumu = its.xpath('./td[{}]/b/text()'.format(j))[0].strip('(').strip(')')
print(leixing)
print(lianjie)
print(shumu)
# 书籍解析
get_content(category,leixing,lianjie,shumu)
except:
pass
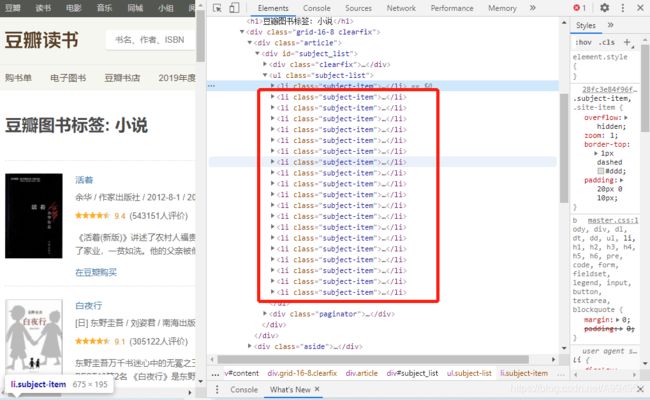
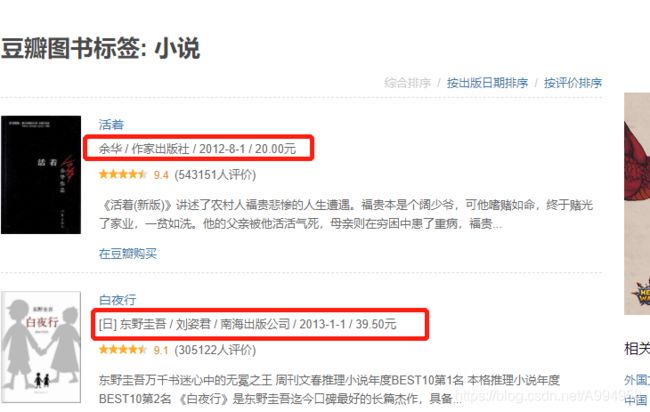
接下来对详情页进行爬取,需要对字段进行判断爬取,其中中文书籍和外文书籍有所不同,多一个翻译字段,需要进行判断爬取
def get_content(category,leixing,lianjie,shumu):
D=[]
# 最多展示50页
for i in range(0, 50):
time.sleep(1)
print('+++++++++++++++++++++',i)
# 链接
# https://book.douban.com/tag/%E5%B0%8F%E8%AF%B4?start=40&type=T
lianjie1 = 'https://book.douban.com/tag/' + leixing + '?start={}&type=T'.format(i * 20)
print(lianjie1)
response = requests.get(url=lianjie1, headers=headers)
# print(response)
items = etree.HTML(response.text)
item = items.xpath('//*[@id="subject_list"]/ul/li')
# print(item)
for its in item:
# 封面
fengmian = its.xpath('./div[1]/a/img/@src')[0]
# print(fengmian)
# 书名
shuming = its.xpath('./div[2]/h2/a/text()')[0]
# 删除不需要的单元格
shuming1 = shuming.replace('\n', '').replace('\t', '').strip()
# 保存图片
# save1(shuming1,fengmian)
# print(shuming)
# 辅助列
fuzhu = its.xpath('./div[2]/div[1]/text()')[0]
fuzhu = fuzhu.replace('\n', '').replace('\t', '').strip().split('/')
# print(fuzhu)
# print(len(fuzhu))
if len(fuzhu) == 5:
guojia=fuzhu[0].split(']')[0].strip('[')
# print(guojia)
# 作者
zuozhe = fuzhu[0]
# 翻译人
fanyi = fuzhu[1].strip()
# 出版社
chuban = fuzhu[2].strip()
# 出版日期
riqi = fuzhu[3].strip()
# 价格
jiage = fuzhu[4].strip()
# print(zuozhe)
# print(fanyi)
# print(chuban)
# print(riqi)
# print(jiage)
elif len(fuzhu) == 4:
# 国家
guojia='中'
# 作者
zuozhe = fuzhu[0]
fanyi = ''
# 出版社
chuban = fuzhu[1].strip()
# 出版社日期
riqi = fuzhu[2].strip()
# 价格
jiage = fuzhu[3].strip()
guojia=guojia
zuozhe=zuozhe
fanyi=fanyi
chuban=chuban
riqi=riqi
jiage=jiage
# print(zuozhe)
# print(fanyi)
# print(chuban)
# print(riqi)
# print(jiage)
# 评分
pingfen = its.xpath('./div[2]/div[2]/span[2]/text()')[0]
# print(pingfen)
# 评价人数
pingjiarenshu = its.xpath('./div[2]/div[2]/span[3]/text()')[0]
pingjiarenshu=pingjiarenshu.replace('\n', '').replace('\t','').strip().strip('(').strip(')')
# print(pingjiarenshu)
# 书籍简介
jianjie = its.xpath('./div[2]/p/text()')[0].replace('\n', '').replace('\t','')
# print(jianjie)
data=[category,leixing,shumu,fengmian,shuming1,guojia,zuozhe,fanyi,chuban,riqi,jiage,pingfen,pingjiarenshu,jianjie]
print(data)
D.append(data)
save(D)三.总结
在爬取时设计到的问题
(1)豆瓣字段限制,每个标签下面只能爬取到50页
(2)豆瓣IP反爬,豆瓣对IP进行了限制访问,如果需要大量爬取需要使用IP代理
更多精彩内容:关注公众号【有趣的数据】