redis面试题详解
缓存
缓存穿透
缓存穿透:查询一个不存在的数据,MySQL查询不到数据也不会直接写入缓存,就会导致每次请求都查数据库。
解决方案一:缓存空数据,查询返回的数据为空,仍把这个空结果进行缓存
解决方案二:布隆过滤器


Redission,Guava都提供了对布隆过滤器的实现方法,可以设置一个误判率,一般在%5以内,不至于在高并发下压倒数据库。
缓存击穿
缓存击穿:给一个key设置了过期时间,当key过期的时候,恰好这个时间点对这个key有大量的并发请求过来,这些并发的请求可能会瞬间把DB压垮
解决方案一:互斥锁
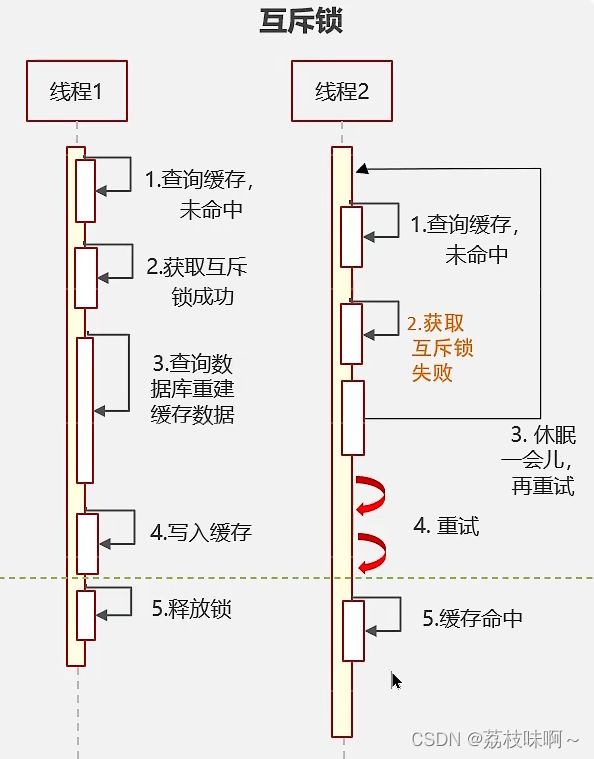
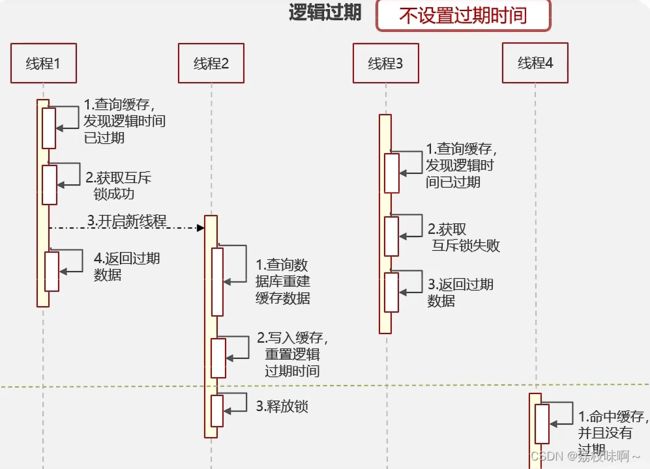
解决方案二:逻辑过期
缓存雪崩
缓存雪崩:是指在同一时段大量的缓存key同时失效或者Redis服务宕机,导致大量请求到达数据库,带来巨大压力。
解决方案一:给不同的key的TTL添加随机值
解决方案二:利用Redis集群提高服务的可用性(哨兵模式,集群模式)
解决方案三:给缓存业务添加降级策略 (nginx或spring cloud gateway)
解决方案四:给业务添加多级缓存(Guava或Caffeine)
双写一致性
双写一致性:当修改了数据库的数据也要同时更新缓存的数据,缓存和数据库的数据要保持一致
根据业务场景分两种。
一致性要求高:
读操作:缓存命中,直接返回;缓存未命中查询数据库,写入缓存,设定超时时间
写操作:延迟双删

这两个操作都会导致脏数据,于是采用延迟双删策略,删除两次缓存

数据库一般是主从模式,需要延时一会,让主节点把数据同步到从节点

允许短暂不一致:
方案一:异步通知保证数据的最终一致性(使用mq中间件,更新数据之后,通知缓存删除)

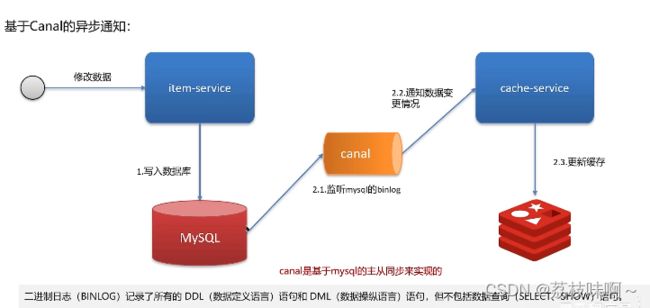
方案二:使用canal中间件,不需要修改业务代码,伪装为MySQL的一个从节点,canal通过读取
binlog数据更新缓存
持久化
在redis中提供了两种数据持久化的方式:1,RDB 2,AOF
RDB:redis数据备份文件,也叫redis数据快照。简单来说就是把内存中的所有数据都记录到磁盘中。当redis实例故障重启后,从磁盘读取快照文件,恢复数据


AOF:追加文件,redis处理的每一个写命令都会记录在AOF文件,可以看作是命令日志文件


数据过期策略
数据过期策略:Redis对数据设置数据的有效时间,数据过期后,就需要将数据从内存中删除掉。可以按照不同的规则进行删除,这种删除规则就被称之为数据的过期策略。
惰性删除:设置该key过期时间后,我们能不去管他,当需要该key时,我们再检查其key是否过期,如果过期,我们就删掉它,反之返回该key。
优点:对cpu友好,只会在使用该key时才会进行过期检查,对于很多用不到的key不用浪费时间进行过期检查。
缺点:对内存不友好,如果一个key已经过期,但是一直没有使用,那么该key就会一直在内存中,内存永远不会释放。
定期删除:每隔一段时间,我们就会对一些key进行检查,删除里面过期的key(从一定数量的数据库中取出一定数量的随机key进行检查,并删除其中过期key)。
定期删除有slow和fast两种模式,slow执行频率默认10hz,每次不超过25ms;fast模式执行频率不固定,但两次间隔不低于2ms,每次耗时不超过1ms
优点:可以通过限制删除操作执行的时长和频率来减少删除操作对cpu的影响,另外定期删除,也能有效释放过期的键占用的内存。
缺点:难以确定删除操作执行的时长和频率。
redis的过期删除策略:惰性删除+定期删除两种策略进行配合使用
数据淘汰策略
数据淘汰策略:当redis中的内存不够用时,此时再向redis中添加新的key,那么redis就会按照某一种规则将内存中的数据删除掉,这种数据的删除规则被称之为内存的淘汰策略。
noeviction:不淘任何key,但是内存满时不允许写入新数据,默认就是这种策略
volatile-ttl:对设置了TTL的key,比较key的剩余TTL值,TTL越小越先被淘汰
allkeys-random:对全体key,随机进行淘汰。
volatile-random:对全体设置了ttl的key,随机进行淘汰。
allkeys-lru:对全体key,基于LRU算法进行淘汰
volatile-lru::对全体设置了ttl的key,基于LRU算法进行淘汰
allkeys-lfu:对全体key,基于LFU算法进行淘汰
volatile-lfu::对全体设置了ttl的key,基于LFU算法进行淘汰



分布式锁

服务时集群的话用syconize锁只能在本地起作用,所以要用分布式锁。
redis实现分布式锁主要利用Redis的setnx命令,setnx是SET if not exists(如果不存在,则SET)的简写。

设置超时时间是为了防止因业务超时或服务宕机导致死锁。
 redis实现的锁可重入。
redis实现的锁可重入。
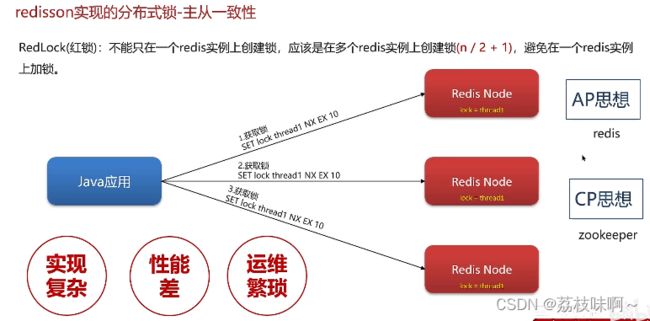
redisson实现的分布式锁-主从一致性


redis中提供的集群方案总共有三种:主从模式,哨兵模式,分片集群。
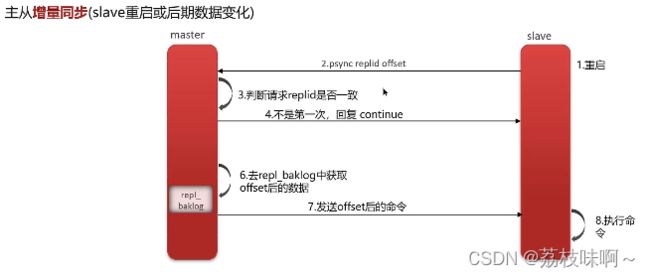
主从模式


哨兵模式



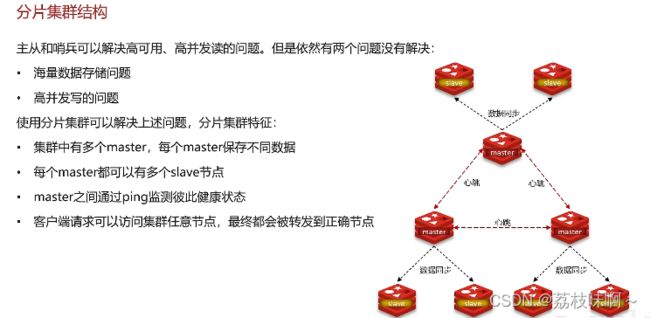
分片集群
分片集群解决海量数据存储和高并发写的问题。

其他redis面试题





