2.淘宝购买行为分析项目——Hive查询、Sqoop的介绍与使用、SQLyog的安装与使用、Superset的概述与安装使用
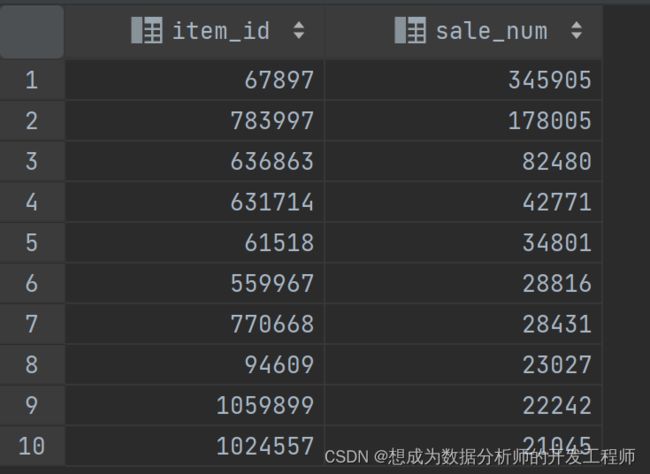
1.热卖商品Top10

思路:对于表中,需要求最热卖的商品,其实就是对商品的it进行分组,然后求有多少个用户id出现过(同一个用户可以反复购买,所以不需要去重),排序后再取前10个即可。
select item_id, count(user_id) sale_num
from to_user_log
group by item_id
order by sale_num desc
limit 10
**查询当前的HiveSQL执行进度 **
[root@node3 ~]# tail -f nohup.out
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=
In order to set a constant number of reducers:
set mapreduce.job.reduces=
Starting Job = job_1683334882009_0003, Tracking URL = http://node4:8088/proxy/application_1683334882009_0003/
Kill Command = /opt/hadoop-3.1.3/bin/mapred job -kill job_1683334882009_0003
Hadoop job information for Stage-1: number of mappers: 8; number of reducers: 8
2023-05-06 09:43:30,458 Stage-1 map = 0%, reduce = 0%
2023-05-06 09:46:00,536 Stage-1 map = 25%, reduce = 0%, Cumulative CPU 11.11 sec
2023-05-06 09:46:07,886 Stage-1 map = 29%, reduce = 0%, Cumulative CPU 399.97 sec
2023-05-06 09:46:11,326 Stage-1 map = 33%, reduce = 0%, Cumulative CPU 402.3 sec
Hadoop job information for Stage-2: number of mappers: 1; number of reducers: 1
**HiveSQL优化:**全局排序,hsql转化后的mapreduce作业只有应该reduce任务。当数据量比较大时order by就要慎用,很有可能导致reduce需要较长的时间仓能完成或者完不成。需要对sql进行优化
select item_id, count(user_id) sale_num
from to_user_log
where user_id is not null
group by item_id
distribute by sale_num //按照分布式排
sort by sale_num desc //按照降序排
limit 10
不过由于我们的节点还是在同一台机器上,所以时间可能还是会稍微久一些。
建立商品热卖的结果表
create table if not exists tm_hot_sale_product(
item_id int comment "商品id",
sale_num int comment "销售数量",
date_day string comment "分析日期"
)
row format delimited
fields terminated by ","
lines terminated by "\n";
将结果保存到Hive表中
-- 将执行后的结果插入表中
from to_user_log
insert into tm_hot_sale_product
select item_id, count(user_id) sale_num, '20230509'
where user_id is not null
group by item_id
order by sale_num desc
limit 10;

将hive表中的数据导入到mysql表中
2.Sqoop概述
Sqoop:将关系数据库(oracle、mysql、sqlserver等)数据与hadoop、hive、hbase等数据进行转换的工具。同类产品DataX(阿里顶级数据交换工具)

官网:http://sqoop.apache.org/
版本介绍:(两个版本完全不兼容,sqoop1使用最多)
- sqoop1:1.4.x
- sqoop2:1.99.x
sqoop架构非常简单,是hadoop生态系统的架构最简单的框架。
sqoop1由client端直接接入hadoop,任务通过解析生成对应的 mapreduce执行

MR中通过InputFormat和OutputFormat配置MR的输入和输出
3.Sqoop原理剖析
从HDFS import导出
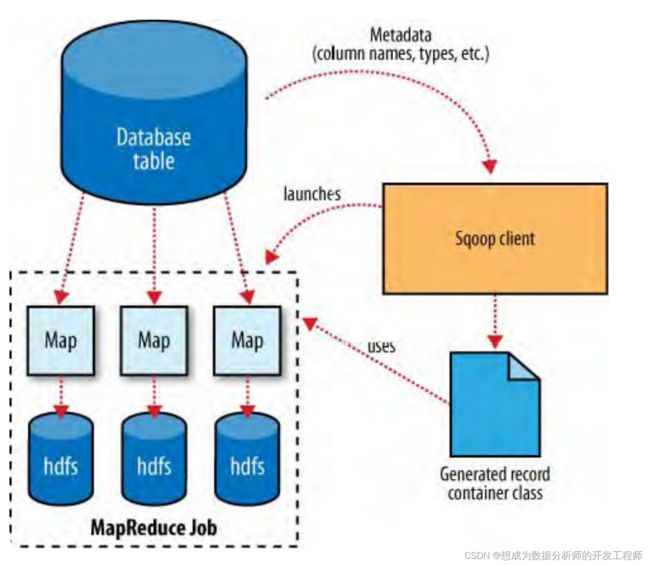
export导出:

4.Sqoop安装
使用时1.4.7,具体的下载地址如下:
http://archive.apache.org/dist/sqoop/1.4.7/sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz
选择安装了hive的服务器node3安装sqoop,以下为具体的安装步骤:
1 上传:将sqoop安装包上传到node3的/opt/apps目录
2 解压并改名
[root@node3 apps]# tar -zxvf sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz -C /opt/
[root@node3 apps]# cd ../
[root@node3 opt]# mv sqoop-1.4.7.bin__hadoop-2.6.0/ sqoop-1.4.7
3 配置环境变量
[root@node3 opt]# cd sqoop-1.4.7/
[root@node3 sqoop-1.4.7]# pwd
/opt/sqoop-1.4.7 #复制路径
[root@node3 sqoop-1.4.7]# vim /etc/profile
# sqoop环境变量
export SQOOP_HOME=/opt/sqoop-1.4.7
export PATH=$PATH:$SQOOP_HOME/bin
[root@node3 sqoop-1.4.7]# source /etc/profile
4 检查环境变量是否生效
[root@node3 ~]# cd
[root@node3 ~]# sqoop version
Warning: /opt/sqoop-1.4.7/../hcatalog does
not exist! HCatalog jobs will fail.
Please set $HCAT_HOME to the root of your
HCatalog installation.
Warning: /opt/sqoop-1.4.7/../accumulo does
not exist! Accumulo imports will fail.
Please set $ACCUMULO_HOME to the root of
your Accumulo installation.
......
INFO sqoop.Sqoop: Running Sqoop version:
1.4.7
Sqoop 1.4.7
5 关闭sqoop警告

6 配置sqoop-env.sh 不需要修改
[root@node3 bin]# cd ../conf
[root@node3 conf]# ls
oraoop-site-template.xml sqoop-envtemplate.sh sqoop-site.xml
sqoop-env-template.cmd sqoop-sitetemplate.xml
[root@node3 conf]# cp sqoop-envtemplate.sh sqoop-env.sh
8 sqoop命令帮助
[root@node3 ~]# sqoop help
......
usage: sqoop COMMAND [ARGS]
Available commands:
codegen Generate code to
interact with database records
create-hive-table Import a table
definition into Hive
eval Evaluate a SQL
statement and display the results
`export` Export an HDFS
directory to a database table
help List available
commands
`import` Import a table from
a database to HDFS
import-all-tables Import tables from a
database to HDFS
import-mainframe Import datasets from
a mainframe server to HDFS
job Work with saved jobs
list-databases List available
databases on a server
list-tables List available tables
in a database
merge Merge results of
incremental imports
metastore Run a standalone
Sqoop metastore
`version` Display version
information
See 'sqoop help COMMAND' for information
on a specific command.
sqoop COMMAND [ARGS]
‘sqoop help COMMAND’
[root@node3 conf]# sqoop help import
9 添加数据库驱动包mysql-connector-java-5.1.37.jar将它上传到
node3:/opt/sqoop-1.4.7/lib
5.SQLyog保姆级安装
这个软件就类似与Navicat
启动mysqld命令
[root@node1 ~]# systemctl status mysqld
● mysqld.service - MySQL Server
1 首先将 软件\SQLyog.rar 解压到一个没有中文和空格的目录,比如:
D:\devsoft
2 进入到解压后的目录,找到 SQLyog.exe 双击
3 进入注册码录入界面
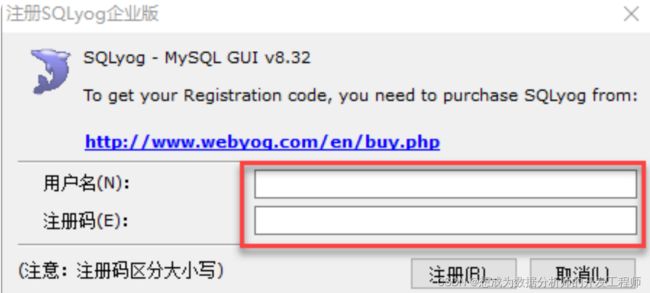
4 在 SQLyog.exe 所在的目录找到Key.txt文件打开
5 拷贝用户名和注册码到对应的输入框中

6 然后点击"注册"按钮,提示注册成功界面,便可以使用了。

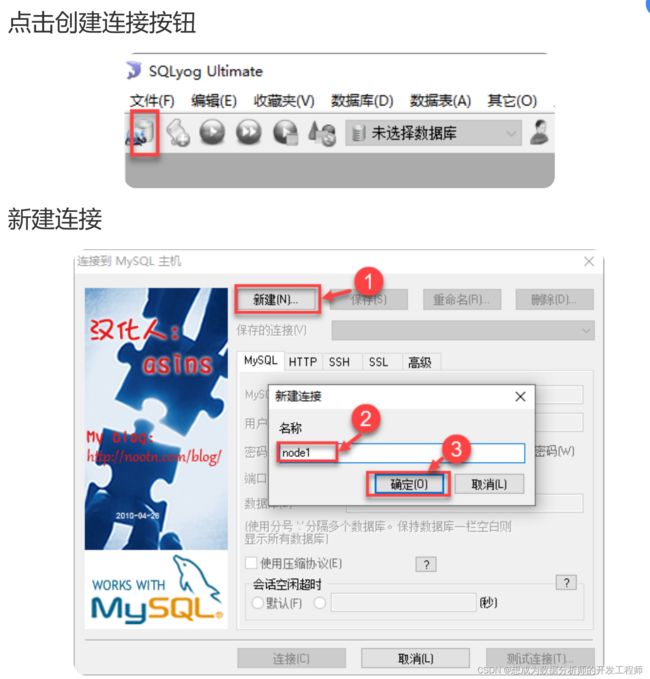
填写MySQL主机名、密码等信息

点击连接按钮,保存连接信息。

6.Sqoop导出数据到MySQL
首先在SQLyog中连接MySQL中创建数据库
CREATE DATABASE taobao;
SQLyog可视化创建表

导出hive数据库到mysql官方文档
Syntax
$ sqoop export (generic-args) (export-args)
$ sqoop-export (generic-args) (export-args)
Table 27. Common arguments
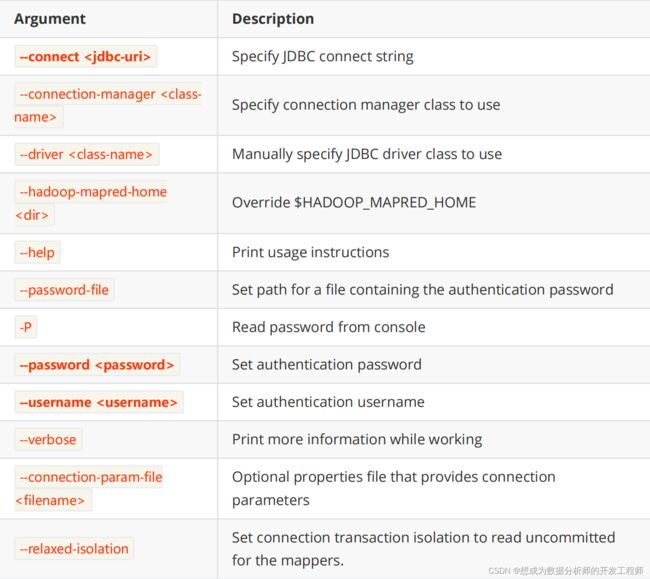
Table 29. Export control arguments:
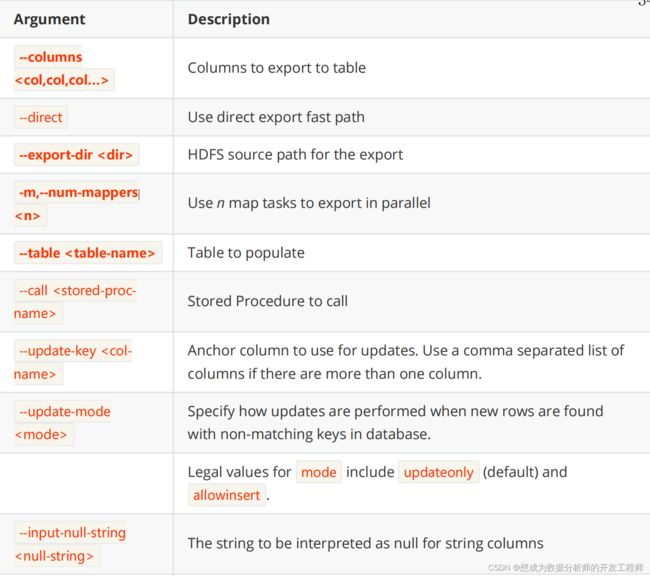

编写导出hive数据库到mysql数据库的脚本
[root@node3 ~]# cat export_tm_hot_sale_product.txt
export
--connect
jdbc:mysql://node1:3306/taobao
--username
root
--password
123456
-m
1
--table
tm_hot_sale_product
--columns
item_id,sale_num,date_day
--export-dir
/user/hive_remote/warehouse/taobao.db/tm_hot_sale_product
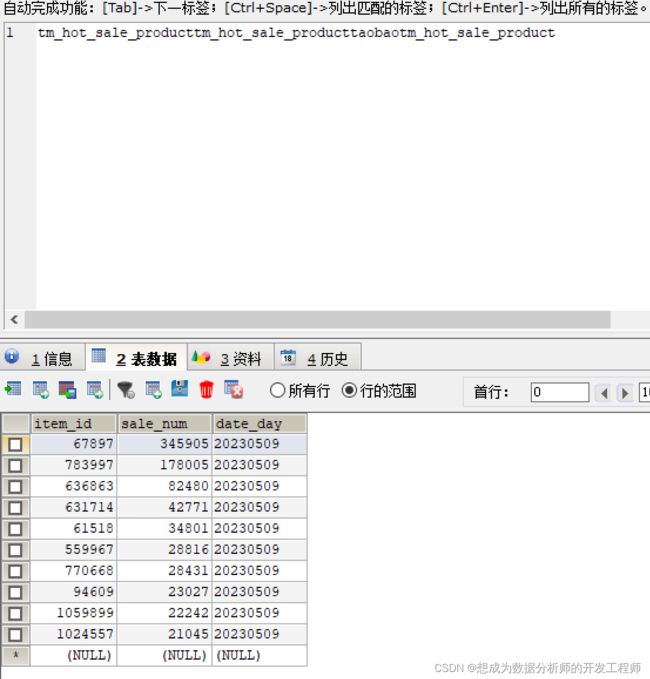
执行脚本命令
[root@node3 ~] sqoop --options-file export_tm_hot_sale_product.txt
7. Superset的概述与安装使用
7.1 Superset概述
Superset 是一款由 Airbnb 开源的“现代化的企业级 BI(商业智能)Web 应用程序”,其通过创建和分享 dashboard,为数据分析提供了轻量级的数据查询和可视化方案。
Superset官网:https://superset.apache.org/

Superset 的前端主要用到了 React 和 NVD3/D3,而后端则基于Python 的 Flask 框架和 Pandas、SQLAlchemy 等依赖库,主要提供了这几方面的功能:
1 集成数据查询功能,支持多种数据库,包括 MySQL、Oracle、SQL Server、SQLite、SparkSQL、Hive、Kylin等,并深度支持Druid

更多数据源支持见https://superset.apache.org/docs/databases/installing-database-drivers/
2 通过 NVD3/D3 预定义了多种可视化图表,满足大部分的数据展示功能。如果还有其他需求,也可以自开发更多的图表类型,或者嵌入其他的 JavaScript 图表库(如 HighCharts、ECharts)。
3 提供细粒度安全模型,可以在功能层面和数据层面进行访问控制。支持多种鉴权方式(如数据库、OpenID、LDAP、OAuth、REMOTE_USER 等)
7.2 安装Python环境
https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
conda是一个开源的包、环境管理器,可以用于在同一个机器上安装不同Python版本的软件包及其依赖,并能够在不同的Python环境之间切换,Anaconda包括Conda、Python以及一大堆安装好的工具包,比如numpy、pandas等,Miniconda包括Conda、Python。此处,我们不需要如此多的工具包,故选择MiniConda。使用root用户后续会遇到各种问题,我们使用itbaizhan用户操作。
创建新用户
[root@node4 ~]# useradd [username]
[root@node4 ~]# passwd [username]
更改用户 [username] 的密码 。
passwd:所有的身份验证令牌已经成功更新。
创建目录/opt/module,并需改所属用户组和用户
[root@node4 ~]# mkdir /opt/module
[root@node4 ~]# chown -R itbaizhan:itbaizhan /opt/module/
上传文件

执行安装脚本
[itbaizhan@node4 ~]# bash Miniconda3-
latest-Linux-x86_64.sh
In order to continue the installation
process, please review the license
agreement.
Please, press ENTER to continue
>>> #安装Enter键 然后按空格键
Do you accept the license terms? [yes|no]
[no] >>> yes #输入yes,然后按下Enter键
Miniconda3 will now be installed into this
location:
/root/miniconda3
- Press ENTER to confirm the location
- Press CTRL-C to abort the installation
- Or specify a different location below
#输入安装路径
[/home/itbaizhan/miniconda3] >>>
/opt/module/miniconda3
Do you wish the installer to initialize
Miniconda3
by running conda init? [yes|no]
[no] >>> yes #输入yes初始化然后按下Enter键
Thank you for installing Miniconda3!
加载环境变量配置文件,使之生效
[itbaizhan@node4 ~]$ source ~/.bashrc
(base) [itbaizhan@node4 ~]$
取消激活base环境
Miniconda安装完成后,每次打开终端都会激活其默认的base环境,我们可通过以下命令,禁止激活默认base环境。
(base) [itbaizhan@node4 ~]$ conda config --set auto_activate_base false
(base) [itbaizhan@node4 ~]$
配置conda镜像
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
conda config --set show_channel_urls yes
安装python环境、
[itbaizhan@node4 ~]# conda create -n
superset python=3.9.15
Proceed ([y]/n)? y
补充:conda环境管理命令
创建环境: conda create -n env_name
查看所有环境: conda info -e / --envs
激活环境: conda activate env_name
取消激活: conda deactivate 在当前激活环境中
删除环境: conda remove -n env_name --all
激活superset环境
[itbaizhan@node4 ~]# conda activate
superset
(superset) [itbaizhan@node4 ~]# conda
deactivate #取消激活
7.3 Linux 虚拟机 安装配置Superset
为itbaizhan用户添加sudo权限
[root@node4 ~]# chmod u+w /etc/sudoers
[root@node4 ~]# vim /etc/sudoers
root ALL=(ALL) ALL
#添加
itbaizhan ALL=(ALL) ALL
[root@node4 ~]# chmod u-w /etc/sudoers
安装SuperSet之前安装基础依赖
[root@node4 ~]# su itbaizhan
[itbaizhan@node4 ~]# sudo yum install -y gcc gcc-c++ libffi-devel python-devel python-pip python-wheel python-setuptools openssl-devel cyrus-sasl-devel openldap-devel
[sudo] itbaizhan 的密码:itbaizhan
[itbaizhan@node4 ~]# sudo yum install -y dnf
[itbaizhan@node4 ~]# sudo dnf install -y gcc gcc-c++ libffi-devel python3-devel python3-pip python3-wheel openssl-devel cyrus-sasl-devel openldap-devel
安装/更新setuptools和pip、
[itbaizhan@node4 ~]# conda activate superset
(superset) [itbaizhan@node4 ~]# pip install --upgrade setuptools pip -i https://pypi.tuna.tsinghua.edu.cn/simple
# 查看setuptools版本
(superset) [itbaizhan@node4 ~]$ pip list|grep setuptools
setuptools 67.6.0
#如果大于65.5.0,需要将setuptools降为65.5.0版本即可,避免:cannot import name 'Log' from'distutils.log'
(superset) [itbaizhan@node4 ~]# pip install setuptools==65.5.0 -i https://pypi.tuna.tsinghua.edu.cn/simple
(superset) [itbaizhan@node4 ~]$ pip list|grep setuptools setuptools 65.5.0
安装Superset
(superset) [root@node4 ~]# pip install apache-superset==2.0.0 -i https://pypi.tuna.tsinghua.edu.cn/simple
添加环境变量:
(superset) [itbaizhan@node4 ~]# export FLASK_APP=superset
初始化superset
(superset) [itbaizhan@node4 ~]# superset db upgrade
可能出现错误提示: ModuleNotFoundError: No module named’cryptography.hazmat.backends.openssl.x509
(superset) [itbaizhan@node4 ~]$ pip list|grep cryptography
cryptography 39.0.2
现有cryptography版本不兼容,需要安装3.3.2
(superset) [itbaizhan@node4 ~]$ pip uninstall cryptography
(superset) [itbaizhan@node4 ~]$ pip install cryptography==3.3.2 -i https://pypi.tuna.tsinghua.edu.cn/simple
(superset) [itbaizhan@node4 ~]$ pip list|grep cryptography
cryptography 3.3.2
(superset) [itbaizhan@node4 ~]# superset db upgrade
错误提示: ModuleNotFoundError: No module named ‘werkzeug.wrappers.etag’ 这个是在 superset 2.0 版本出现的bug,通过降低Werkzeug的版本解决
(superset) [itbaizhan@node4 ~]$ pip list|grep Werkzeug
Werkzeug 2.2.3
(superset) [itbaizhan@node4 ~]$ pip uninstall -y Werkzeug
(superset) [itbaizhan@node4 ~]$ pip uninstall -y Flask
(superset) [itbaizhan@node4 ~]$ pip install Flask==2.0.3 -i https://pypi.tuna.tsinghua.edu.cn/simple
(superset) [itbaizhan@node4 ~]$ pip install Werkzeug==2.0.3 -i https://pypi.tuna.tsinghua.edu.cn/simple
(superset) [itbaizhan@node4 ~]# rm -f .superset/superset.db
(superset) [itbaizhan@node4 ~]# superset db upgrade
错误提示: ModuleNotFoundError: No module named ‘wtforms.ext’ ,为WTForms3.0的版本去掉了ext,需要降低WTForms的版本到2.3.3
(superset) [itbaizhan@node4 ~]$ pip list|grep WTForms
WTForms 3.0.1
WTForms-JSON 0.3.5
(superset) [itbaizhan@node4 ~]$ pip uninstall -y WTForms
(superset) [itbaizhan@node4 ~]$ pip install WTForms==2.3.3 -i https://pypi.tuna.tsinghua.edu.cn/simple
(superset) [itbaizhan@node4 ~]# rm -f .superset/superset.db
(superset) [itbaizhan@node4 ~]# superset db upgrade
创建管理员账户
(superset) [root@node4 ~]# superset fab create-admin
Username [admin]: itbaizhan
User first name [admin]: it
User last name [user]: baizhan
Email [[email protected]]: xflovejava@126.com
Password: #itbaizhan
Repeat for confirmation:
初始化Superset
(superset) [root@node4 ~]# superset init
7.4 启动与停止superset
安装gunicorn
[root@node4 ~]# su itbaizhan # 切换用户
[itbaizhan@node4 root]$ cd
[itbaizhan@node4 ~]$ conda activate superset # linux进入虚拟环境
(superset) [itbaizhan@node4 ~]$ pip install gunicorn -i https://pypi.tuna.tsinghua.edu.cn/simple
注:gunicorn是一个Python Web Server,类似java中的 Tomcat
启动superset
(superset) [itbaizhan@node4 ~]$ gunicorn --workers 5 --timeout 120 --bind node4:8787 "superset.app:create_app()" --daemon # 设置5个工作进程 120s关闭 绑定node4的8787
(superset) [itbaizhan@node4 ~]$ jps # 查看进程
65627 Jps
参数说明
--workers:指定进程个数
--bind:绑定本机地址,即为Superset访问地址
--timeout:worker进程超时时间,超时会自动重启
--daemon:后台运行
关闭superset命令
(superset) [itbaizhan@node4 ~]$ ps -ef | awk '/superset/ && !/awk/{print $2}' |xargs kill -9 # 关闭superset命令
conda deactivate # 退出虚拟环境
exit # 退出用户
7.5 superset启停脚本
(superset) [itbaizhan@node4 ~]$ conda deactivate
[itbaizhan@node4 ~]$ vim superset.sh
[itbaizhan@node4 ~]$ vim superset.sh
[itbaizhan@node4 ~]$ cat superset.sh
#!/bin/bash
superset_status(){
result=`ps -ef | awk '/gunicorn/ && !/awk/{print $2}' | wc -l`
if [[ $result -eq 0 ]]; then
return 0
else
return 1
fi
}
superset_start(){
source ~/.bashrc
superset_status >/dev/null 2>&1
if [[ $? -eq 0 ]]; then
conda activate superset ;gunicorn --workers 5 --timeout 120 --bind node4:8787 --daemon 'superset.app:create_app()'
else
echo "superset running!!"
fi
}
superset_stop(){
superset_status >/dev/null 2>&1
if [[ $? -eq 0 ]]; then
echo "superset is stop"
else
ps -ef | awk '/gunicorn/ && !/awk/{print $2}' | xargs kill -9
fi
}
case $1 in
start )
echo "start Superset!!"
superset_start
;;
stop )
echo "stop Superset!!"
superset_stop
;;
restart )
echo "restart Superset!!"
superset_stop
superset_start
;;
status )
superset_status >/dev/null 2>&1
if [[ $? -eq 0 ]]; then
echo "superset is stop"
else
echo "superset running"
fi
esac
为脚本添加执行权限
[itbaizhan@node4 ~]$ chmod +x superset.sh
[itbaizhan@node4 ~]$ ll
-rwxrwxr-x 1 itbaizhan itbaizhan 1141 8月 29 19:50 superset.sh
脚本使用
[itbaizhan@node4 ~]$ ./superset.sh start
start Superset!!
[itbaizhan@node4 ~]$ ./superset.sh status
superset running
[itbaizhan@node4 ~]$ ./superset.sh stop
stop Superset!!
7.6 Superset整合MySQL数据库
使用superset在不利用代码的情况下完成数据的可视化




点击TEST CONNECTION,出现“Connection looks good!”提示即表示连接成功
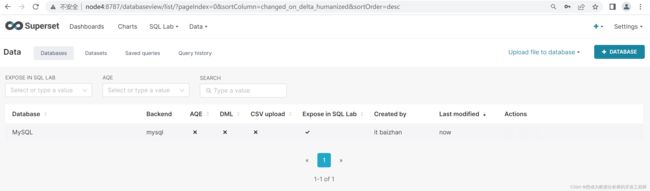
7.7 使用Supersert可视化——热卖商品Top10可视化


点击创建好的tm_hot_sale_product表后面的编辑图标,可以对列进行修改。


选择columns
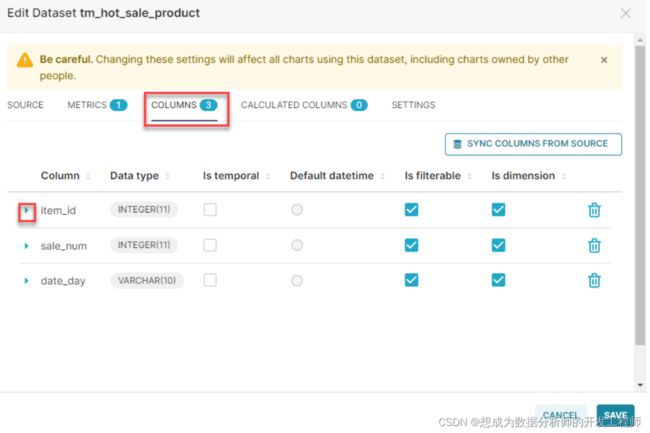
选择想要修改的列前面的小三角图标
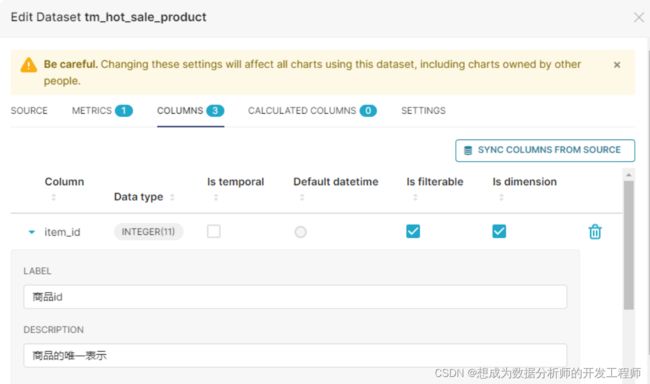
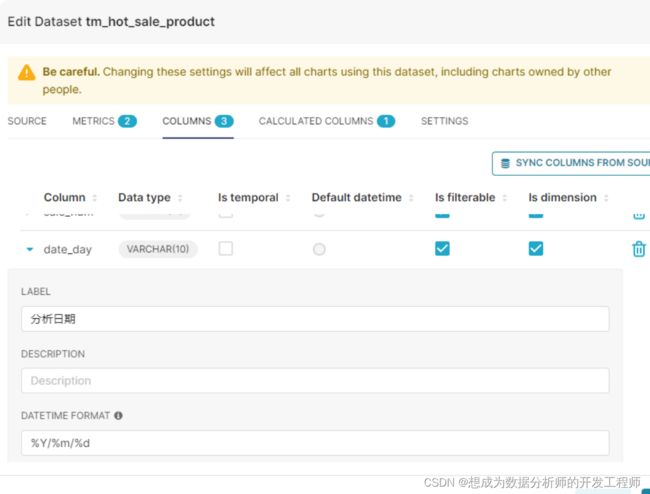
可以给列添加标签,描述,执行是否临时、过滤、维度等。
选择“METRICS(指标)”标签下的编辑,可以对统计的“指标”进行命名
点击+charts

点击bar charts

选择内容


保存数据

修改

