头指针、头节点、首元结点——《王道数据结构》
一、关于头指针、头节点、首元节点的问题
昨天考研专业课遇到了一个选择题 带头结点的单链表具有什么优点 ,因为平时都是用的带头节点的链表,只是单纯记住了结论。考后我想仔细研究研究这个问题… 来CSDN找点资料,发现越看越模糊,下面我来总结总结。
二、教材说法
1.让我们先来瞅瞅这个《王道考研》辅导书上给的结论:

下图就是一个带头结点的单链表:

上图有一个易错点:很多时候我们容易把L->next看成是头节点,其实是L指向了头节点,而L->next是首元节点。这里我们不妨再剖析下结点的含义:

2.这是《大话数据结构》上给的结论:

3.CSDN上的一些结论:
①.使用头节点,指针域都是指向第一个结点,对于空表和非空表操作都是一致的,对于第一个元素的操作(添加、删除)更加方便。
②使用头节点,则第一个位置的插入和删除都是对 head->next (head是头指针) 操作,而不是head本身,而且减少了算法分支 (if else 分支)。
4.我的理解:
头指针:
①.用来标记链表,做链表的名字。
②.指向链表的第一个结点。
头结点:
①.统一操作(第一个结点的插入、删除)。
②.统一空表和非空表。
首元节点:
①.第一个具有实际意义(存了值)的点。
三、以上只是纸上谈兵,下面我们来实操实操:
记住结论很轻松,但是真考试的时候,要你做选择的时候,往往因为缺少操作而没有底气,是谓“知其然,不知其所以然。” 回头看的时候还真发现自己没有整清楚。
我们来挨个分析,它怎么就有优势了?
定义结点:
typedef struct Node{
int data;
struct Node* next;
}Node;
优势一:统一插入入操作
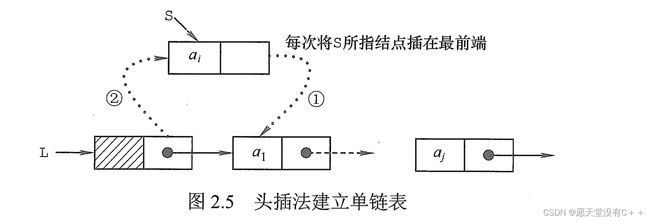
①有头节点初始化及插入(头插法)操作
//初始化一个链表,上面说到:“头指针用来标记链表,做链表的名字”操作如下:
Node* L=(Node*)malloc(sizeof(Node));
//有了链表头指针我们设置头节点:[头指针就是表示头节点],而头节点的指针域指向的是NULL
L->next=NULL;
//插入一个结点,我们省略 申请结点、输入值的操作 直接设这个结点为NewNode,并且用头插法:
NewNode->next=L->next;
L->next=NewNode;
②无头节点初始化及其头插法(简写)
//同上操作,省请一个头指针,标志一个链表:
Node* L=(Node*)malloc(sizeof(Node));//注意这步可以省略
head=NULL;
/*!!!注意!!!上面是一个“经典的错误,标准的零分”
这里出现了“内存泄露”:我们再堆区申请了一片内存,但是我们又把它置为空指针,而堆区的那片空间,没有被释放.
相当于:你去领养了一个孩子,反手抛弃了ta,ta不就成了没爹的野孩子。不慌我们看下面的操作*/
NewNode->next=L;
L=NewNode;
/*上面的操作不就是新结点NewNode指向了NULL吗,所以我们直接让L=NULL就行了!*/
好,那么问题来了?它怎么统一呢?怎么就统一操作了呢?不是各管各的吗?我靠,我们发现头插法确实是各管各的,并没有统一一说,下面我们来试试尾插法。
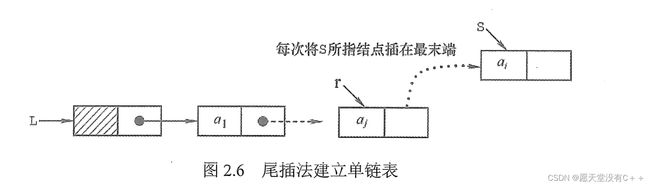
③有头节点初始化及尾插法
//初始化一个链表,上面说到:“头指针用来标记链表,做链表的名字”操作如下:
Node* L=(Node*)malloc(sizeof(Node));
//有了链表头指针我们设置头节点:[头指针就是表示头节点],而头节点的指针域指向的是NULL
L->next=NULL;
//插入一个结点,我们省略 申请结点、输入值的操作 直接设这个结点为NewNode,并且用尾插法:
/*用 r 记录head指针,然后让r一直跟随再链表尾部。狼群的狼王负责带路,他要派出一个小弟,去随时检查狼尾部有没有狼掉队,如果亲自去的话,那岂不是群狼无首,到处乱窜?*/
Node* r=L;
//假装申请了一个新节点NewNode,省略输入、赋值操作
//NewNode->next = r->next;按常理确实应该让NewNode->next指向r->next,或者直接指向NULL。亲测都行。
r->next=NewNode;
r=NewNode;
r->next=NULL;
④无头节点初始化及其尾插法
常规思路(错误示范):
//有了上面的操作,我们直接让head=NULL;
Node* L=NULL;
//派出去一个小弟监查
Node* r=L;
//插入一个结点,我们省略 申请结点、输入值的操作 直接设这个结点为NewNode,并且用尾插法:
NewNode->next=r;
r=NewNode;
乍一看没问题,但是仔细斟酌,你会发现L已经找不到r了,L始终指向空,而r又一直指向尾结点,导致了一个结果:即使这些结点连在一起,但是我们已经找不到他们了。就好比你只认识狼王和他的小弟,狼王老年痴呆,他小弟又在最后面,你也没有办法挨个遍历整个狼群。那么有头结点的尾插法,为什么L就不会丢失呢:因为L始终指向的是头结点,这“头节点”好比狼王的亲儿子,虽然狼王老年痴呆但是他肯定记得他的亲儿子,让狼王和他儿子直接对接,那么你仍然可以遍历整个狼群。所以那么我们该怎么写无头节点的尾插法呢?自然就是没有头节点,把第一个结点就设置为头节点。`
(正确示范):
//有了上面的操作,我们直接让head=NULL;
Node* L=NULL;
//派出去一个小弟监查
Node* r=L;
//如果头指针是空,我们让他指向第一个结点(让第一个结点成为狼王儿子),同样省略操作NewNode结点
if(L==NULL)
{
Newnode->next=NULL;//操作同设置头节点一样
L=NewNode;//让狼王后面更着他儿子
r=NewNode;//更新小弟
}
else
{
r->next=NewNode;//已经有头结点了,所以操作同有头节点的一样。
r=NewNode;
}
r->next=NULL;//最后一步置尾结点的next指向NULL。
优势二:统一“删除某个链表结点”操作
①有头节点“从头部”删除整个单链表
我们先理清楚几个结点:L是头指针,指向头节点,L->next是首元结点。
再次提醒!!这里一个易错点:很多时候我们容易把L->next看成是头节点,这是我刚开始学习的时候容易犯的错误。
//带头节点的结点
Node* L;//头指针指向头节点,而L->next是首元结点(第一个存数据的结点)
Node* p=L->next;//p是首元结点(第一个具有实际意义的点)
while(p!=NULL)//如果还存在实际意义的点
{
Node* q=p->next;//记录下首元结点下一个结点 (皇帝宣布传位给那个儿子)
free(p);//释放本结点 (皇帝驾崩)
p=q;//让首元结点变成q (继承皇位)
}
这里为什么要多一个q呢?直接free( p ),p=p->next 不香吗?这也是我曾犯过的错误,后头我想了个例子:皇帝驾崩之前,肯定要立遗嘱,记录下把位置传给那个儿子,不可能皇帝死了后诈尸,起来宣布把皇位传给谁。这个p除了有数据域,还有指针域,你在做free( p)时候,整个结点就没了,它指向谁也不知道了,所以要提前记录下来。
②不带头节点“从头部”删除整个单链表
这里的L直接指向了第一个首元结点:
//不带头节点的链表
Node* L;//头指针
while(L!=NULL)//同上操作
{
Node* q=L->next;//记录下一个结点
free(L);//释放首元结点
L=q;//让首元结点指向它
}
经过比较我们发现:有无头结点对删除整个单链表操作,似乎没有带来便利,那么我们需要进一步探讨:带头结点的单链表是如何统一删除操作的。 下面我们来探讨,带头结点是否对删除单链表单个元素操作,提供了便利:
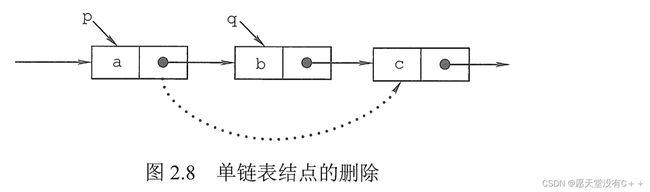
③带头节点删除单个单链表元素:
为了和删除整个单链表操作区分,我们假定删除单链表中的第二个元素。(实际操作中我们可以根据值、下标等找到需要删除的元素)
Node* L;//头指针指向头节点,而L->next是首元结点(第一个存数据的结点)
Node* aimNode=SearchNode();//假设这是目标结点
Node* p//假设这是目标结点之前的结点
//假设我们删除一个结点
p->next=aimNode->next;
free(aimNode);
④不带头节点“从尾部”删除整个单链表
这里的不带头结点,所以 L 指向首元结点,L->next是第二个结点。那么我们这样操作:
常规思路(错误示范):
//不带头节点的链表
Node* L;//头指针指向头节点,这里没有头指针所以:L直接指向首元结点
Node* aimNode=SearchNode();//假设这是目标结点
Node* p//假设这是目标结点之前的结点
p->next=aimNode->next;
free(aimNode);
这时候我们发现该代码缺少了一种情况:p为L的时候,也就是我们删除第二个点的时候,我们要让第一个结点,指向第三个结点,而这里我们只能操作第二个点。所以我们又需要动用if-else来完善这种情况:
常规思路(正确示范):
//不带头节点的链表
Node* L;//头指针指向头节点,这里没有头指针所以:L直接指向首元结点
Node* aimNode=SearchNode();//假设这是目标结点
Node* p//假设这是目标结点之前的结点
if(p==L)
{
p=aimNode->next;
}
else
{
p->next=aimNode->next;
}
free(aimNode);
经过上面一系列的折腾,我们在此发现了带头结点是如何具有统一链表操作。
我觉得我写的太啰嗦并且代码过于简陋,所以需要详细一点的代码大家可以,看看这个小哥的代码:不秃头的小黄人
优势三:统一“空表和非空表控制”操作
①那么显而易见表空和表非空,显然也是在第一个结点做文章。判断是否为空:
| 带头结点 | 不带头节点 |
|---|---|
| L->next=NULL | L=NULL |
那么那些情况比较适用呢?
②我们再来回顾下两者之间的区别:
若使用头结点,无论表是否为空,头指针都指向头结点,对于空表和非空表的操作是一致的。
若不使用头结点,当表非空时,头指针指向第1个结点的地址,但是对于空表,头指针指向的是NULL,此时空表和非空表的操作是不一致的。
③我们惊人发现,其实在上面的尾插法中,我们已经体现出了这一特点,不妨回过头来看看:
带头结点:
//初始化一个链表,上面说到:“头指针用来标记链表,做链表的名字”操作如下:
Node* L=(Node*)malloc(sizeof(Node));
//有了链表头指针我们设置头节点:[头指针就是表示头节点],而头节点的指针域指向的是NULL
L->next=NULL;
Node* r=L;
r->next=NewNode;
r=NewNode;
r->next=NULL;
不带头结点:
//有了上面的操作,我们直接让head=NULL;
Node* L=NULL;
//派出去一个小弟监查
Node* r=L;
if(L==NULL)
{
Newnode->next=NULL;//操作同设置头节点一样
L=NewNode;//让狼王后面更着他儿子
r=NewNode;//更新小弟
}
else
{
r->next=NewNode;//已经有头结点了,所以操作同有头节点的一样。
r=NewNode;
}
r->next=NULL;//最后一步置尾结点的next指向NULL。
结果显而易见,不带头结点的确实要多一步判断是否为空操作
四、总结:
话不多说,我们再来看看这个结论:
当然实际情况实际要实际分析。不能关背结论,更不能背代码。面对疑惑希望我们保持刨根问底的精神。