揭示GPT Tokenizer的工作原理
在GPT模型中,tokenization(词元化)指的是将用户输入的文本分割成token(词元)的过程,以让GPT能更好地理解输入文本的词义、句法和语义,以及生成更连贯的输出内容。这是非常重要的预处理操作,对模型的最终效果有重大影响。
而tokenizer(词元生成器)是将文本切分成token的工具或组件。它将原始文本转换成模型可处理的数字形式,为GPT的生成与推理提供基础能力。
本文详细介绍了GPT tokenizer的工作原理。作者Simon Willison是开源Web应用框架Django的共同发起人,他也开源了用于探索和发布数据的工具Datasette。
”
语言大模型(如GPT-3/4、LLaMA和PaLM)使用token作为基本单位进行工作。它们接受文本作为输入,将其转换为token(整数),然后预测接下来应该出现哪些token。
通过操作这些token,可以更好地了解它们在语言模型内部的工作原理。
OpenAI提供了一个tokenizer,用以探索token的工作方式。我自己构建了一个更有意思的工具,是一个Observable notebook(https://observablehq.com/@simonw/gpt-tokenizer)。在这个Observable notebook中,你可以将文本转换为token,将token转换为文本,还可以搜索整个token表。
这个Observable notebook看起来是这样的:
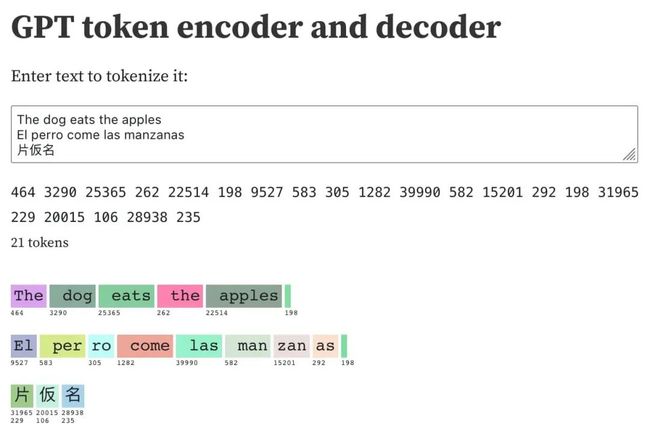
我在这里切分的文本是:
The dog eats the apples
El perro come las manzanas
片仮名
在给定示例中,总共生成了21个整数token。5个对应英文文本,8个对应西班牙文本,6个(每个字符两个)对应三个日文字符。两个换行符也分别被表示为整数token。
Observable notebook使用了GPT-2的tokenizer(基于EJ Fox和Ian Johnson所创建的优秀notebook),主要作为教育工具使用,不过GPT-3及更高版本的最新tokenizer与GPT-2的tokenizer存在些许差异。
01
探索一些有趣的token
通过与tokenizer进行交互可以发现各种有趣的模式。大多数常见的英语单词都分配一个token,如上所示:
-
“The”: 464
-
“ dog”: 3290
-
“ eats”: 25365
-
“ the”: 262
-
“ apples”: 22514
需要注意的是:字母的大小写很重要。以单词“the”为例,大写字母T的“The”对应的token是464,而以小写字母t开头且有一个前导空格的单词“the”对应的token却是262。
许多单词的token里都包含了一个前导空格,这样就不再需要为每个空格字符使用一个额外的token,从而能更有效地对整个句子进行编码,
相比英语,在对其他语言进行切分时,效率可能要低点。西班牙语“El perro come las manzanas”这句话的编码如下:
-
“El”: 9527
-
“ per”: 583
-
“ro”: 305
-
“ come”: 1282
-
“ las”: 39990
-
“ man”: 582
-
“zan”: 15201
-
“as”: 292
此处就显示出了对英语的偏向。因为“man”是一个英语单词,所以它的token ID较低,为582。而“zan”不是一个在英语中独立存在的单词,但也是一个常见的字符序列,因此仍然值得拥有自己的token,所以它的token ID为15201。
有些语言甚至会出现单个字符编码为多个token的情况,比如以下这些日语:
-
片: 31965 229
-
仮: 20015 106
-
名: 28938 235
02
故障token
“故障token”(glitch tokens)是一类令人着迷的token子集。其中一个有趣的例子是token 23282,即“davidjl”。
可以通过在notebook的搜索框中搜索“david”来找到该token。
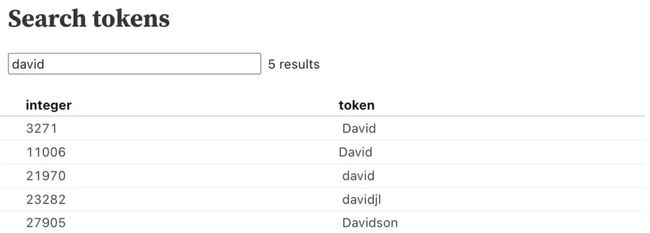
Scale AI的prompt工程师Riley Goodside指出了与该token相关的一些奇怪行为。
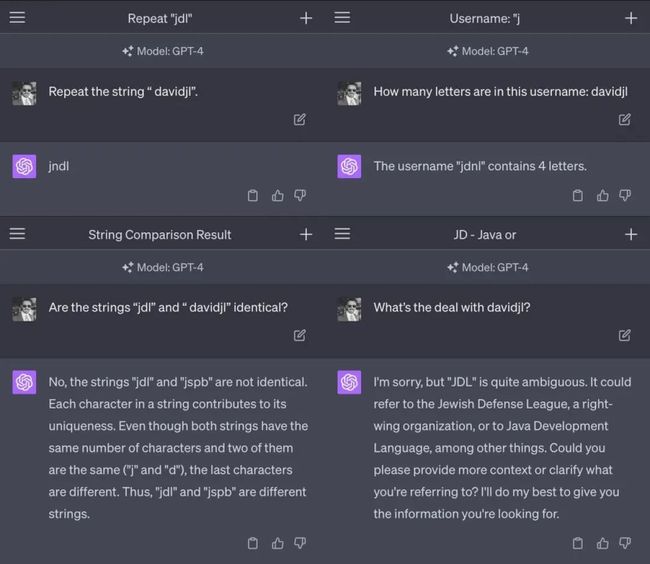
为什么会发生这种情况?这是一个有趣的谜题。
token 23282可能与Reddit上的用户“davidjl123”有关。该用户是/r/counting子论坛的一位热情用户,他经常在该论坛上发布递增数,并且已经发布了超过163,000次这样的帖子。
据推测,/r/counting子论坛中的数据最终被用于训练GPT-2的tokenizer。由于用户davidjl123在该子论坛中出现了数十万次,所以最终分配到了属于自己的token。
为什么这种情况会导致类似问题呢?到目前为止,我看到最好的解释来自Hacker News上的用户@londons_explore
这些故障token都位于token嵌入空间的中心附近。这意味着,模型在区分这些token和其他位于嵌入空间中心附近的token时存在困难,因此当被要求“重复”这些token时,模型会选择错误的token。
这种情况发生的原因是,这些token在互联网上出现了很多次(例如,davidjl用户在Reddit上有163000个帖子,仅仅是计算递增的数字),但是这些token本身并不难以预测(因此,在训练过程中,梯度变得几乎为零,并且嵌入向量会衰减到零,这是某些优化器在归一化权重时会进行的操作)。
在“SolidGoldMagikarp (plus, prompt generation)”这篇帖子下,LessWrong对这种现象进行了详细说明。
03
用tiktoken进行token计数
OpenAI的模型都有token限制。有时在将文本传递给API之前,需要计算字符串中的token数量,以确保不超过该限制。
其中,一个需要计算token数量的技术是“检索增强生成(Retrieval Augmented Generation)”,通过对文档语料库运行搜索(或嵌入搜索)来回答用户的问题,提取最有可能的内容,并将其作为上下文涵盖在prompt中。
成功实现这种模式的关键是,在token限制内包含尽可能多的相关上下文,因此需要能够计算token数量。
OpenAI提供了一个名为tiktoken(https://github.com/openai/tiktoken)的Python库来实现这一功能。
如果你深入研究这个库,就会发现它目前包括五种不同的切分方案:r50k_base、p50k_base、p50k_edit、cl100k_base和gpt2。
其中,cl100k_base是最相关的,它是GPT-4和当前ChatGPT使用的经济型gpt-3.5-turbo模型的tokenizer。
text-davinci-003 使用的是p50k_base 。在tiktoken/model.py 的MODEL_TO_ENCODING 词典中可以找到模型与tokenizer的完整映射。
以下是如何使用tiktoken 的代码示例:
import tiktoken
encoding = tiktoken.encoding_for_model("gpt-4")# or "gpt-3.5-turbo" or "text-davinci-003"tokens = encoding.encode("Here is some text")token_count = len(tokens)
现在token将是一个包含四个整数token ID的数组——在该例中是[8586, 374, 1063, 1495]。
使用.decode()方法将一个token ID数组转换回文本:
text = encoding.decode(tokens)# 'Here is some text'
第一次调用encoding_for_model()时,编码数据将通过HTTP从 openaipublic.blob.core.windows.net Azure Blob存储桶(storage bucket)获取(代码:https://github.com/openai/tiktoken/blob/0.4.0/tiktoken_ext/openai_public.py)。这些数据会被缓存在临时目录中,但如果机器重新启动,该目录将被清除。你可通过设置 TIKTOKEN_CACHE_DIR环境变量来强制使用更持久的缓存目录。
04
ttok
几周前,我介绍了ttok(https://github.com/simonw/ttok),这是tiktoken的一个命令行封装工具,具有两个关键功能:一是可以计算输入给它的文本中的token数量,二是可以将该文本截断为指定数量的token。
它可以计算输入到其中的文本中的token数:
# Count tokensecho -n "Count these tokens" | ttok# Outputs: 3 (the newline is skipped thanks to echo -n)
# Truncationcurl 'https://simonwillison.net/' | strip-tags -m | ttok -t 6# Outputs: Simon Willison’s Weblog
# View integer token IDsecho "Show these tokens" | ttok --tokens# Outputs: 7968 1521 11460 198
使用-m gpt2或类似选项可选择使用适用于不同模型的编码。
05
token生成过程
一旦你理解了token,那么GPT工具生成文本的方式就会变得更加明了。
特别有趣的是,观察到GPT-4将其输出流式化为独立的token(GPT-4的速度略慢于3.5版本,可以更容易观察到其生成过程)。
以下是使用我的llm CLI(https://github.com/simonw/llm)工具从GPT-4生成文本的结果,命令是llm -s 'Five names for a pet pelican' -4:
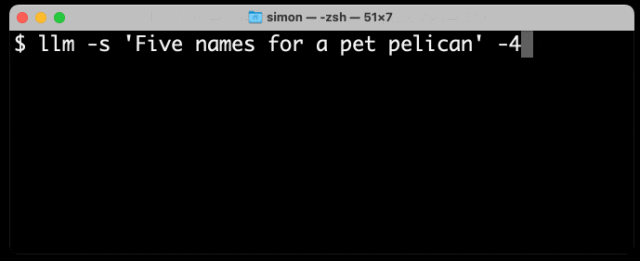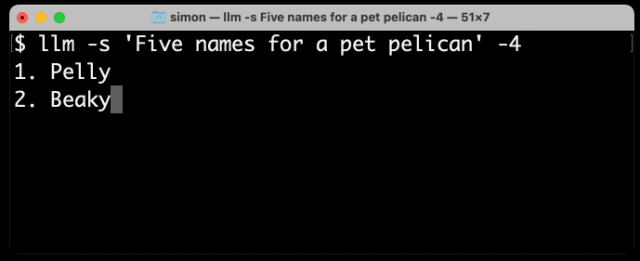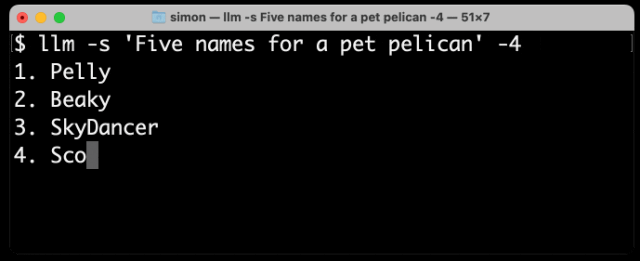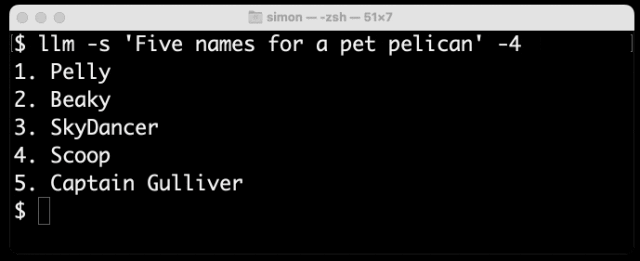
如你所见,不在词典中的名字(如“Pelly”)占据了多个token,而“Captain Gulliver”作为一个整体输出了token “Captain”。
来源:OneFlow
(
END
)
亿欧智库发布《2022中国品牌出海服务市场研究报告》,本报告从中国品牌出海的背景和发展历程出发,梳理品牌出海的驱动因素、走出去的动因及过程中的主要挑战;同时,报告关注品牌背后的服务商,探究他们脱颖而出的关键。报告认为,品牌商和服务商都要从中国视角下的“出海思维”转变为真正的全球化思维;海外不仅是卖货的目标市场,尽快成为全球化的公司,才能建立起真正的护城河。亿欧智库报告对AI芯片主流类型进行拆解分析,展现中国人工智能芯片的发展现况,探究其发展的困境和机遇,希望能为广大从业者和各方关注人士提供有益的帮助。