Kaggle竞赛——房价预测(一)
文章目录
- 任务要求
-
- 数据说明
- 最终目标
- 评价指标:RMSE
- 实施流程
- 代码实现
-
- 导包
- 读取并查看数据集
- 保存并删除原有Id列
- 数据预处理和特征工程
-
- 异常值处理
- 目标变量分析
- 缺失值处理
-
- 1、首先将训练集和测试集合并在一起
- 2、统计各个特征的缺失情况
- 3、填补缺失值
- 4、特征相关性
- 5、进一步挖掘特征
-
- 1、转换部分数值特征为分类特征
- 2、转换部分分类特征为数值特征
- 3. 利用一些重要的特征构造更多的特征
- 4、对特征进行Box-Cox变换
- 5、独热编码
任务要求
影响房价的因素有很多,在本题的数据集中,有79个解释变量几乎描述了爱荷华州艾姆斯(Ames, Iowa)住宅的方方面面,要求预测每套房屋最终的销售价格。
数据说明
train.csv - 训练集
test.csv - 测试集
data_description.txt - 每列的完整描述,最初由 Dean De Cock 准备,但经过稍微编辑以匹配此处使用的列名
sample_submission.csv - 根据销售年份和月份、地块面积和卧室数量进行线性回归的基准提交
最终目标
要求预测每栋房屋的销售价格,即对于测试集
test.csv中的每个 Id,预测对应 SalePrice 变量的值。**
评价指标:RMSE
即根据预测值的对数和观察到的房价对数之间的均方根误差对提交结果进行评估。公式如下
R M S E = ∑ i = 1 N ( y i − y ^ i ) 2 N RMSE = \sqrt{\frac {\sum_{i=1}^N{(y_i-\hat{y}_i)^2}} N}\, RMSE=N∑i=1N(yi−y^i)2
实施流程
- 1)了解、分析问题;
- 2)获取训练集和测试集,做一些数据预览工作;
- 3)进行数据预处理和特征工程;
- 4)建模、改进模型、做出预测;
- 5)提交结果。
代码实现
导包
import warnings
warnings.filterwarnings("ignore") # 忽略警告信息
from scipy.stats import norm, skew # 获取统计信息
from scipy import stats
import numpy as np
import pandas as pd # 数据处理包
import seaborn as sns # 绘图包
color = sns.color_palette()
sns.set_style('darkgrid')
import matplotlib.pyplot as plt
%matplotlib inline
pd.set_option('display.float_format', lambda x: '{:.3f}'.format(x)) # 限制浮点输出到小数点后3位
import os
print('\n'.join(os.listdir('./input'))) # 列出目录中可用的文件
读取并查看数据集
# 加载数据
train = pd.read_csv('./input/train.csv')
test = pd.read_csv('./input/test.csv')
# 检查样本和特征的数量
print("删除Id列前训练集大小: {} ".format(train.shape))
print("删除Id列前测试集大小: {} ".format(test.shape))
train.head(5)
删除Id列前训练集大小: (1460, 81)
删除Id列前测试集大小: (1459, 80)
保存并删除原有Id列
#保存Id列
train_ID = train['Id']
test_ID = test['Id']
# 删除原数据集的Id列
train.drop("Id", axis=1, inplace=True)
test.drop("Id", axis=1, inplace=True)
数据预处理和特征工程
- 异常值处理
- 目标变量分析
- 缺失值处理
- 特征相关性
- 进一步挖掘特征
- 对数值型特征进行Box-Cox变换
- 独热编码
异常值处理
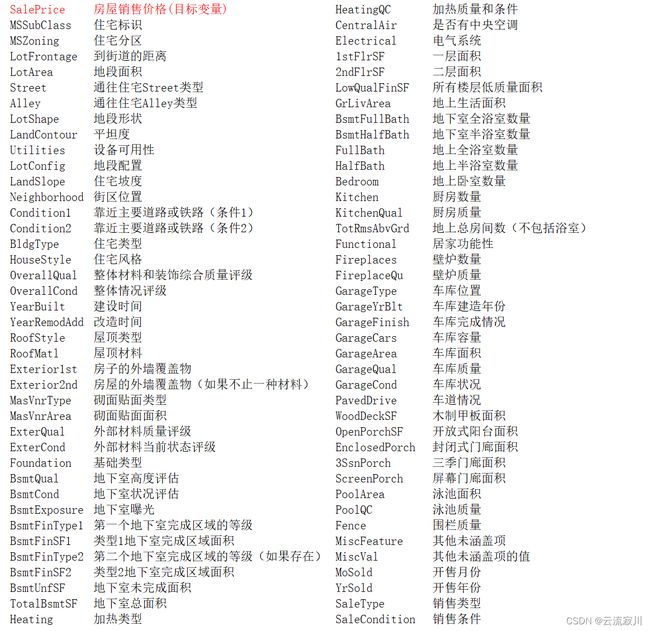
通过绘制散点图可以直观地看出训练集特征是否有离群值,这里以地上生活面积 GrLivArea 为例。
我们可以看到,图像右下角的两个点有着很大的GrLivArea,但相应的SalePrice却异常地低,我们有理由相信它们是离群值,要将其剔除。
plt.figure(figsize=(14, 4))
plt.subplot(121)
plt.scatter(x=train['GrLivArea'], y=train['SalePrice'])
plt.ylabel('SalePrice', fontsize=13)
plt.xlabel('GrLivArea', fontsize=13)
train = train.drop(train[(train['GrLivArea'] > 4000) & (train['SalePrice'] < 300000)].index)
plt.subplot(122)
plt.scatter(train['GrLivArea'], train['SalePrice'])
plt.ylabel('SalePrice', fontsize=13)
plt.xlabel('GrLivArea', fontsize=13)
注意:删除离群值并不总是安全的。我们不能也不必将所有的离群值全部剔除,因为测试集中依然会有一些离群值。用带有一定噪声的数据训练出的模型会具有更高的鲁棒性,从而在测试集中表现得更好。
目标变量分析
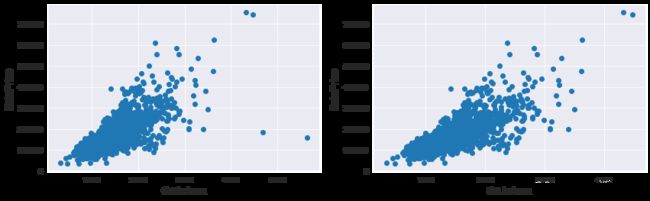
SalePrice 是我们将要预测的目标,有必要对其进行分析和处理。
我们画出SalePrice的分布图和QQ图(Quantile Quantile Plot)。QQ图是由标准正态分布的分位数为横坐标,样本值为纵坐标绘制而成的散点图。如果QQ图上的点在一条直线附近,则说明数据近似于正态分布,且该直线的斜率为标准差,截距为均值。
# 分布图
fig, ax = plt.subplots(nrows=2, figsize=(6, 10))
sns.distplot(train['SalePrice'], fit=norm, ax=ax[0])
(mu, sigma) = norm.fit(train['SalePrice'])
ax[0].legend(['Normal dist. ($\mu=$ {:.2f} and $\sigma=$ {:.2f} )'.format(mu, sigma)], loc='best')
ax[0].set_ylabel('Frequency')
ax[0].set_title('SalePrice distribution')
# QQ图
stats.probplot(train['SalePrice'], plot=ax[1])
plt.show()
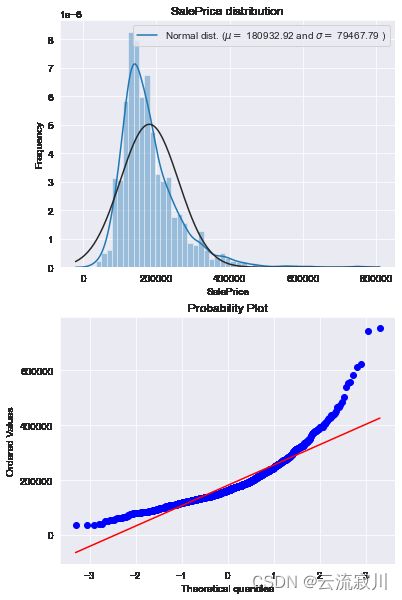
可以看到,SalePrice的分布呈正偏态,而线性回归模型要求因变量服从正态分布。我们对其做对数变换,让数据接近正态分布。
# 使用numpy中函数log1p()将log(1+x)应用于列的所有元素
train["SalePrice"] = np.log1p(train["SalePrice"])
# 查看转换后数据分布
# 分布图
fig, ax = plt.subplots(nrows=2, figsize=(6, 10))
sns.distplot(train['SalePrice'], fit=norm, ax=ax[0])
(mu, sigma) = norm.fit(train['SalePrice'])
ax[0].legend(['Normal dist. ($\mu=$ {:.2f} and $\sigma=$ {:.2f} )'.format(
mu, sigma)], loc='best')
ax[0].set_ylabel('Frequency')
ax[0].set_title('SalePrice distribution')
# QQ图
stats.probplot(train['SalePrice'], plot=ax[1])
plt.show()

缺失值处理
1、首先将训练集和测试集合并在一起
all_data = pd.concat((train, test)).reset_index(drop=True)
all_data.drop(['SalePrice'], axis=1, inplace=True)
print("all_data size is : {}".format(all_data.shape)) # print(f"all_data size is : {all_data.shape}")
all_data size is : (2917, 79)
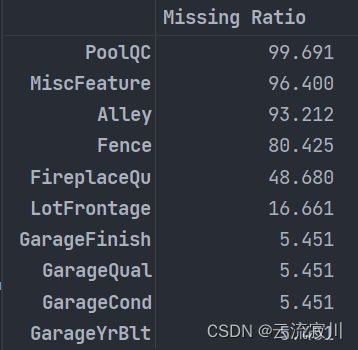
2、统计各个特征的缺失情况
all_data_na = (all_data.isnull().sum() / len(all_data)) * 100
#pd.set_option('display.max_rows', 500)
all_data_na
#pd.reset_option('display.max_rows')
过滤缺失率为0的特征并按照缺失率降序排列
all_data_na = all_data_na.drop(all_data_na[all_data_na == 0].index).sort_values(ascending=False)
missing_data = pd.DataFrame({'Missing Ratio': all_data_na})
missing_data.head(10)
为了便于直观的展示和分析,我们每个特征的缺失率的柱状图:
fig,ax = plt.subplots(figsize=(15,8))
sns.barplot(x=missing_data.index,y=all_data_na)
plt.xticks(rotation='90')#将x轴标签旋转90°,这样显示就不会挤在一起
plt.xlabel('Features',fontsize=15)
plt.ylabel('Percent of missing values',fontsize=15)
plt.title('Percent missing data by features')

3、填补缺失值
在data_description中已经说明,一部分特征值的缺失是因为这些房子根本就没有这个特征,比如游泳池面积之类,对于这种情况我们统一用None或者0来填充
Python中的None是一个特殊变量,不是0,也不是False,不是空字符串,更多的是表示一种不存在,是真正的空
- PoolQC : 数据描述说 NA 表示“没有泳池”。 这是有道理的,因为大多数房子一般都没有游泳池,因而缺失值的比例很高(+99%)。
- MiscFeature : 数据描述说 NA 表示“没有杂项”。
- Alley : 数据描述NA 表示“没有小巷通往”。
- Fence : 数据描述说 NA 表示“没有围栏”。
- FireplaceQu : 数据描述说 NA 的意思是“没有壁炉”。
…
针对特征的不同特点及含义,对缺失值我们通常采用不同的处理方式
对于缺失率非常高的特征,我们用None或0来填补
all_data["PoolQC"] = all_data["PoolQC"].fillna("None")
all_data["MiscFeature"] = all_data["MiscFeature"].fillna("None")
all_data["Alley"] = all_data["Alley"].fillna("None")
all_data["Fence"] = all_data["Fence"].fillna("None")
all_data["FireplaceQu"] = all_data["FireplaceQu"].fillna("None")
all_data["MasVnrType"] = all_data["MasVnrType"].fillna("None")
all_data["MasVnrArea"] = all_data["MasVnrArea"].fillna(0)
for col in ('GarageType', 'GarageFinish', 'GarageQual', 'GarageCond'):
all_data[col] = all_data[col].fillna('None')
for col in ('GarageYrBlt', 'GarageArea', 'GarageCars'):
all_data[col] = all_data[col].fillna(0)
for col in ('BsmtFinSF1', 'BsmtFinSF2', 'BsmtUnfSF', 'TotalBsmtSF', 'BsmtFullBath', 'BsmtHalfBath'):
all_data[col] = all_data[col].fillna(0)
for col in ('BsmtQual', 'BsmtCond', 'BsmtExposure', 'BsmtFinType1', 'BsmtFinType2'):
all_data[col] = all_data[col].fillna('None')
对于缺失值较少的离散型特征,比如Electrical,可以使用众数插补
all_data['MSZoning'] = all_data['MSZoning'].fillna(all_data['MSZoning'].mode()[0])
all_data['Electrical'] = all_data['Electrical'].fillna(all_data['Electrical'].mode()[0])
all_data['KitchenQual'] = all_data['KitchenQual'].fillna(all_data['KitchenQual'].mode()[0])
all_data['Exterior1st'] = all_data['Exterior1st'].fillna(all_data['Exterior1st'].mode()[0])
all_data['Exterior2nd'] = all_data['Exterior2nd'].fillna(all_data['Exterior2nd'].mode()[0])
all_data['SaleType'] = all_data['SaleType'].fillna(all_data['SaleType'].mode()[0])
LotFrontage:由于房屋到街道的距离,最有可能与其附近其他房屋到街道的距离相同或相似,因此我们可以通过该社区的LotFrontage的中位数来填充缺失值
all_data['LotFrontage'] = all_data.groupby("Neighborhood")["LotFrontage"].transform(lambda x:x.fillna(x.median()))
Functional:居家功能性,数据描述说NA表示类型“Typ”。因此,我们用其填充
all_data['Functional'] = all_data['Functional'].fillna("Typ")
Utillties:设备可用性,对于这个特征,所有记录除了一个“NoSeWa”和两个NA,其余值都是“AllPub",因此该项特征的方差非常小。并且带有”NoSewa“的房子在训练集中,也就是说测试集都是”AllPub“,这个特征对预测建模没有帮助。因此,我们可以安全的删除他
all_data = all_data.drop(['Utilities'],axis=1)
至此,所有的缺失值都已处理完毕
4、特征相关性
相关性矩阵热图可以表现特征与目标值之间以及两两特征之间的相关程度,对特征的处理有指导意义
#seaborn中函数heatmap()可以查看特征如何与SalePrice相关联
corrmat = train.corr()
plt.figure(figsize=(12,9))
sns.heatmap(corrmat,vmax=0.9,square=True)
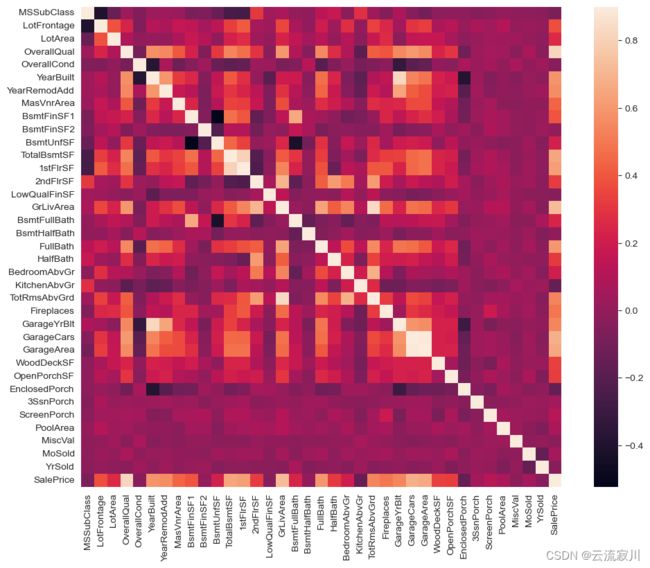
5、进一步挖掘特征
1、转换部分数值特征为分类特征
我们注意到有些特征虽然是数值型的,但其实表征的只是不同类别,其数值的大小并没有实际意义,因此我们将其转化为分类特征
MSSubClass:住宅标识
YrSold:开售年份
MoSold:开售月份
all_data['MSSubClass'] = all_data['MSSubClass'].apply(str)#apply函数默认对列进行操作
all_data['YrSold'] = all_data['YrSold'].apply(str)
all_data['MoSold'] = all_data['MoSold'].apply(str)
2、转换部分分类特征为数值特征
反过来,有些类别特征实际上有高低好坏之分,这些特征的质量越高,就可能在一定程度上导致房价越高
我们将这些特征的类别映射成有大小的数字,以此来表征这种潜在的偏序关系。(标签编码:LabelEncoder)
PoolQC:泳池质量,有Ex Excellent,Gd Good等
from sklearn.preprocessing import LabelEncoder
cols = ('FireplaceQu', 'BsmtQual', 'BsmtCond', 'GarageQual', 'GarageCond',
'ExterQual', 'ExterCond', 'HeatingQC', 'PoolQC', 'KitchenQual', 'BsmtFinType1',
'BsmtFinType2', 'Functional', 'Fence', 'BsmtExposure', 'GarageFinish', 'LandSlope','LotShape',
'PavedDrive', 'Street', 'Alley', 'CentralAir', 'MSSubClass', 'OverallCond','YrSold', 'MoSold')
#处理列,将标签编码应用于分类特征
for c in cols:
lbe = LabelEncoder()
all_data[c] = lbe.fit_transform(list(all_data[c].values))
print('Shape all_data:{}'.format(all_data.shape))
Shape all_data:(2917, 78)
3. 利用一些重要的特征构造更多的特征
- TotalBsmtSF:地下室总面积
- 1stFlrSF:一层面积
- 2ndFlrSF:二层面积
- OverallQual:整体材料和装饰综合质量
- GrLivArea:地上生活面积
- TotRmsAbvGrd:地上总房间数
- GarageArea:车库面积
- YearBuilt:建造时间
合并策略
1、将地下室总面积和一层二层面积这三个特征相加,叫房屋可用总面积
2、构建整体质量和重要特征之间的交互项,就是相乘
# 构造更多的特征
all_data['TotalSF'] = all_data['TotalBsmtSF'] + all_data['1stFlrSF'] + all_data['2ndFlrSF'] # 房屋总面积
all_data['OverallQual_TotalSF'] = all_data['OverallQual'] * all_data['TotalSF'] # 整体质量与房屋总面积交互项
all_data['OverallQual_GrLivArea'] = all_data['OverallQual'] * all_data['GrLivArea'] # 整体质量与地上总房间数交互项
all_data['OverallQual_TotRmsAbvGrd'] = all_data['OverallQual'] * all_data['TotRmsAbvGrd'] # 整体质量与地上生活面积交互项
all_data['GarageArea_YearBuilt'] = all_data['GarageArea'] * all_data['YearBuilt'] # 车库面积与建造时间交互项
4、对特征进行Box-Cox变换
Box-Cox变换简介:对于存在正负偏态的特征,我们通常有对数变换和开方变换两种方式,那么Box-Cox就是一种自动根据数据进行变换纠偏的方法。
https://blog.csdn.net/lx529068450/article/details/117419208
1、对数值型特征,我们希望他们尽量服从正态分布,也就是不希望这些特征出现正负偏态。那么我们先来计算一下各个特征的偏度
#筛选出所有数值型特征
numeric_feats = all_data.dtypes[all_data.dtypes != "object"].index
#计算特征的偏度
numeric_data = all_data[numeric_feats]
skewed_feats = numeric_data.apply(lambda x:skew(x.dropna())).sort_values(ascending=False)
skewness = pd.DataFrame({'skew':skewed_feats})
skewness

2、对高偏度的特征进行Box-Cox变换
new_skewness = skewness[skewness.abs() > 0.75]
print('有{}个特征被Box-Cox变换'.format(new_skewness.shape[0]))
有63个特征被Box-Cox变换
我们使用scipy中的boxcox1p()函数计算1+x的Box-Cox变换,当参数等于0时等效于目标变量的log1p
选出偏度绝对值大于0.75的数据,找出这些偏度对应的特征,将偏度平滑至0.15
from scipy.special import boxcox1p
skewed_features = new_skewness.index
lam = 0.15
for feat in skewed_features:
all_data[feat] = boxcox1p(all_data[feat],lam)#指定要平滑的列和需要平滑到的峰度
5、独热编码
上述我们主要在处理数值型特征,接下来我们处理类别特征
那么对于类别特征,我们将其转化为独热编码,这样既解决了模型不好处理属性数据的问题,在一定程度上也起到了扩充特征的作用
什么时候使用标签编码/独热编码呢,例如:有个特征代表颜色,有红黄蓝三种,这三种如果使用labelencoder则是012,但是在机器学习中我们这就赋予了红黄蓝一个天然的大小关系,而本质上三种颜色不存在任何的比较关系,赋予特征错误的信息将会造成模型的准确率下降,这个时候我们就应该使用独热编码
从另一个方面来说,每个特征向量的距离都是根号二,在向量空间中的距离都相等,即不会影响基于向量空间度量算法的一个效果
下面我们对数据进行独热编码
all_data = pd.get_dummies(all_data)
print(all_data.shape)
至此,我们完成了在模型训练前全部的数据准备工作。