在上一篇《Generative AI 新世界:过去、现在和未来》中,我做为一名曾经多次穿越过市场周期的从业者,对 Generative AI 的发展历程、目前的热点方向、以及对未来的畅想做了一个梳理,希望可以帮助大家理清这个新周期的一些底层逻辑,例如知识底座、应用蓝图、以及发展方向和潜在机遇等方面的内容。
| 亚马逊云科技开发者社区为开发者们提供全球的开发技术资源。这里有技术文档、开发案例、技术专栏、培训视频、活动与竞赛等。帮助中国开发者对接世界最前沿技术,观点,和项目,并将中国优秀开发者或技术推荐给全球云社区。如果你还没有关注/收藏,看到这里请一定不要匆匆划过,点这里让它成为你的技术宝库! |
就在我在准备这个专题系列的下一篇内容时,就在这个月,一个更酷炫的“学霸”型文本生成模型 GPT-4 正式发布了!根据 GPT-4 的官方技术报告,这个“学霸” 型文本生成模型已经可以以各种炫技高分通过各种标准化考试了。例如:
- GRE Verbal:接近满分
- 律师入学考试LSAT (Law School Admission Test):进入前 10% 左右
- 律师执照考试UBE (Uniform Bar Exam):进入前 10% 左右
- SAT Reading & Writing:进入前 7%
- SAT Math:进入前 10% 左右
- ……

Source:https://cdn.openai.com/papers/gpt-4.pdf?trk=cndc-detail
技术报告中还举例展现了 GPT-4 的具体解题分析过程,例如用户直接给一张考试题的照片,让 GPT-4 一步步思考作答。如下图所示:

GPT-4 模型看图之后,一板一眼地解答如下:

关于 GPT-4 更多细节,我们还会在本文的第四节中更详细地做出介绍。
文本生成
文本生成(Text Generation)领域的进步真可谓是日新月异。为了更好这个领域的这些激动人心的技术进步,让我们一起来深入探究下文本生成领域的主要几篇论文:InstructGPT,RLHF,PPO,GPT-3,以及GPT-4。
1 InstructGPT 论文概述
我们将以一个文本生成(Text Generation)的经典论文 (InstructGPT)来解读目前在该领域的 SoTA 模型结构设计和训练方法。

Paper Source: https://arxiv.org/pdf/2203.02155.pdf?trk=cndc-detail
我们先来看看 InstructGPT 论文的摘要。
这张图片显示了我通读这篇论文摘要时的一些评论和笔记。

我记录的主要纲要是:
- 论文的总体想法(Fine-tune human feedback)
- 他们是如何收集数据集的?(收集了问题和答案)
- 他们如何微调数据集?(在 GPT-3 上有监督式学习)
- 他们为什么称之为 “InstructGPT”?(在人工评估中...)
- 结果(只有 GPT-3 的 1% 模型参数但是 InstructGPT 的结果更好)
InstructGPT 的论文共有 68 页,我想重点介绍的亮点是:来自人类反馈的强化学习(简称为 RLHF)。
2020 年的论文 “Learning to summarize with human feedback”,可以认为是最早开始研究 RLHF 的论文之一,已经开始研究探讨 GPT-3 和 RLHF 的结合:

Source: https://arxiv.org/abs/2009.01325?trk=cndc-detail
1.1 RLHF 的训练过程
RLHF 的训练过程可以分解为三个核心步骤:
- 步骤一:预训练语言模型:采用有监督的策略微调
- 步骤二:收集数据并训练奖励模型
- 步骤三:通过强化学习微调 LM
首先,我们将了解这三个步骤分别需要的数据集来源、数据集大小等重要信息。为什么要先去分析这三个大步骤中的数据集来源呢?
西方有句著名的谚语:“The devil is in the details.” 翻译成中文就是:“魔鬼藏在细节里”。在人工智能领域里,优质的数据和数据来源,在同样的研究方法的作用下,结果可能相差很大,即:差一点,差很多。
因此,对于数据来源的研究,在我阅读论文中习惯里,是我最提前关注重视的部分之一。
- Paper Source: https://arxiv.org/pdf/2203.02155.pdf?trk=cndc-detail
- RLHF (Reinforcement Learning from Human Feedback):https://huggingface.co/blog/rlhf?trk=cndc-detail
1.2 训练数据的来源

1/ SFT 数据集:
- 数据集大小:13K
- 这个数据集是由 [Prompt, Text] 对组成的样本。数据一部分来自使用 API 提交的用户数据,另一部分来自专门的标注人员(Labeler)。
2/ RM 数据集:
- 数据集大小:33K
- 先让模型生成一批候选文本,然后通过标注人员(Labeler)根据生成数据的质量对这些生成内容进行排序打分作为 RM 模型的标注。
3/ PPO 数据集:
- 数据集大小:31K
- PPO 数据没有进行人工标注,它均来自用户通过 API 提交的数据。这里有不同用户提供的不同种类的任务,其中占比最高的包括生成任务(45.6%),问答(12.4%),头脑风暴(11.2%),对话(8.4%)等等。
1.3 训练阶段一:预训练语言模型上的策略微调
数据来源:
用于训练奖励模型的 Prompt 数据一般来自于一个预先的数据集,比如某个 LLM 模型的 Prompt 数据则主要来自那些调用 GPT API 的用户。这些 prompts 会被丢进初始的语言模型(步骤一的模型)里来生成文本。
训练方法:
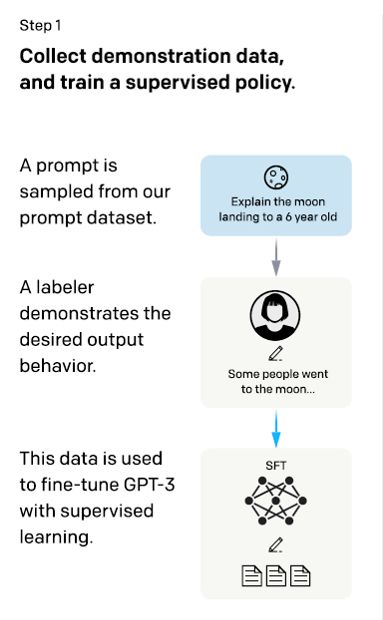
如图所示。首先,我们需要选一个经典的预训练语言模型作为初始模型。OpenAI 在其第一个RLHF 模型 InstructGPT 中用的小规模参数版本的 GPT-3。这些语言模型往往见过大量的 [Prompt, Text] 对,输入一个 prompt(提示),模型往往能输出还不错的一段文本。
Source: https://arxiv.org/pdf/2203.02155.pdf?trk=cndc-detail
预训练模型也可以在人工精心撰写的语料上进行微调,但这一步不是必要的。例如,OpenAI 在人工撰写的优质语料上对预训练模型进行了微调。不过,这种人工撰写的优质语料一般成本是非常高的。
人工微调的大致操作是:在数据集中随机抽取问题,由专门的标注人员给出高质量答案,然后用这些人工标注好的数据来微调模型。标注人员根据提示 (prompt) 编写质量可靠的输出响应 (demonstrations)。这里采用的是 Supervised Fine-Tuning(SFT)模型,即有监督的策略来进行微调。微调之后,模型在遵循指令/对话方面得到优化,但不一定符合人类偏好。

Source: https://huggingface.co/blog/rlhf?trk=cndc-detail
第一步完成之后,我们需要基于这个初始语言模型产出的数据来训练一个奖励模型(reward model,简称 RM)。接下来,就会引入人类的反馈信号了。
1.4 训练阶段二:训练奖励模型(Reward Model)
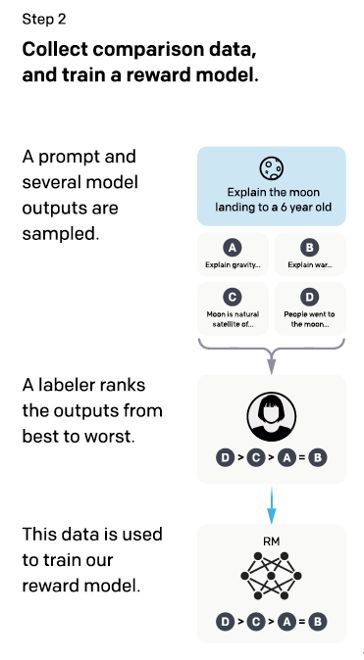
训练一个奖励模型(RM)的目标是让模型的输出在人类看来表现不错。即,输入是一个 prompt(模型生成的文本),输出是一个代表文本质量的标量数字。
Source: https://arxiv.org/pdf/2203.02155.pdf?trk=cndc-detail
数据来源:
用于训练奖励模型的 Prompt 数据一般来自于一个预先的数据集,OpenAI 的 Prompt 数据则主要来自那些调用 GPT API 的用户。这些 prompts 会被丢进初始的语言模型(步骤一的模型)里来生成文本。
训练方法:
如下图所示,标注人员的任务则是对初始语言模型生成的文本进行排序。说到这里有人可能会问:为啥不直接让标注人员对文本进行打分呢?

Source: https://huggingface.co/blog/rlhf?trk=cndc-detail
这是因为研究人员发现不同的标注员,由于其教育背景、生活阅历和家庭环境等的不同,打分的偏好会有很大的差异,而这种差异就会导致出现大量的噪声样本。若改成标注排序,则发现不同的标注员的打分一致性就大大提升了。
接下来,再使用这个排序结果来训练奖励模型。对于多个排序结果,两两组合,形成多个训练数据对。奖励模型(Reward Model)接受输入后,给出评价回答质量的分数。对于一对训练数据,通过调节参数使得高质量回答的打分比低质量的打分要高。奖励模型学会了为评分高的响应计算更高的奖励,为评分低的回答计算更低的奖励。
1.5 训练阶段三:通过强化学习微调大模型
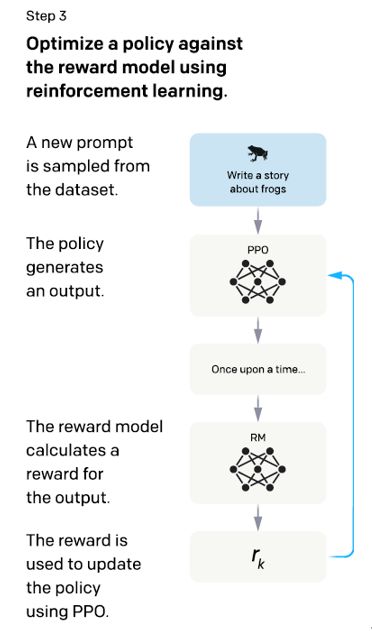
这一阶段整体采用强化学习(Reinforcement Learning)方式,使用在阶段二里训练好的奖励模型(Reward Model)做为该强化学习的奖励模型,通过 PPO 算法优化模型策略。PPO(Proximal Policy Optimization,近端策略优化)是一种用于在强化学习中训练 agent 的策略,这里被用来再次微调在阶段一中提及的有监督微调(SFT)大模型。
Source: https://arxiv.org/pdf/2203.02155.pdf?trk=cndc-detail
这一阶段利用第二阶段训练好的奖励模型,靠奖励模型打分来更新预训练模型参数。在数据集中随机抽取问题后,使用 PPO 模型生成回答,并用上一阶段训练好的 RM 模型计算奖励,给出质量分数,然后用这个奖励来继续更新 PPO 模型。奖励依次传递,由此产生策略梯度,通过强化学习的方式更新 PPO 模型参数。但这次和阶段二不同的地方是:这次不再让人类来打分排序,而是让阶段二训练好的奖励模型去给模型的预测结果进行打分排序。

Source: https://huggingface.co/blog/rlhf?trk=cndc-detail
就这样,使用一个初始的语言模型来生成文本,以及使用一个奖励模型来判断模型生成的文本是否优质(迎合人类偏好)。如此不断重复第二和第三阶段,通过迭代会训练出更高质量的 InstructGPT 模型。我们将来自于人类反馈的强化学习简称为 RLHF(reinforcement learning from human feedback),即使用人类的偏好作为奖励信号来微调模型。
就这样,使用一个初始的语言模型来生成文本,以及使用一个奖励模型来判断模型生成的文本是否优质(迎合人类偏好),然后不断生成、评估、优化,如此循环进行。简单来说,就是机器代替人类做排序的工作。这是一个非常重要的进步。
2 PPO 论文概述
Proximal Policy Optimization(PPO)是 Actor-Critic 的升级版,利用 KL 距离(经过一系列近似化简的形式描述,实际本质上是概率分布的差异)来动态衡量学习率是否过大。

PPO paper: https://arxiv.org/pdf/1707.06347.pdf?trk=cndc-detail
在前一章节中,我们提到了 InstructGPT 在 RLHF 训练的阶段三,是通过 PPO 算法进一步优化策略模型的。InstructGPT 在论文中,有更详细地描述他们是如何使用 PPO 算法的描述,如下图所示:

Source - InstructGPT paper: https://arxiv.org/pdf/2203.02155.pdf?trk=cndc-detail
一句话概括,PPO 算法提出的一种解决 Policy Gradient 不好确定动作幅度的问题。因为如果动作幅度过大,机器人会反复横跳,不易收敛;但如果动作幅度太小, 想要完成训练,那就得等到天荒地老。PPO 利用 New Policy 和 Old Policy 的 KL 距离,限制了 New Policy 的更新幅度,如果 KL 距离过小,就让 KL 正则项的权重减小,让机器放开膀子大胆干;如果 KL 距离过大,就让 KL 正则项权重增大,让机器收紧步伐悠着点。
举一个爬山的例子来类比。我们人类爬山的时候,在选择下一步时,在较安全的接近平地的区域,我们会放心大胆地步子迈大一些;而在一些比较陡峭有风险的区域时,我们会尽量悠着点。PPO 算法我个人理解就是应用了人类的这种思维。
因为 Generative AI 的这波浪潮,我们预计强化学习(Reinforcement Learning)领域也会引发一波学习浪潮。如果您想在实践中更好地认知强化学习理论,包括 PPO 算法的一些实践细节,您可以使用亚马逊云科技的 DeepRacer 服务。如下图所示:

亚马逊云科技 DeepRacer 简介:https://aws.amazon.com/cn/deepracer/?trk=cndc-detail
在亚马逊云科技的 DeepRacer 服务中,缺省的训练算法就是 PPO。如下图所示:

3 GPT-3 论文概述
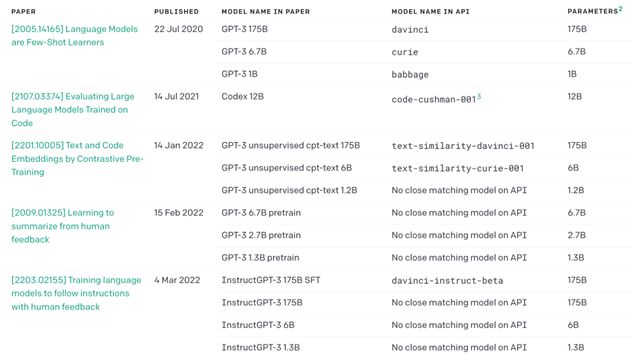
如果您对 GPT-3 非常感兴趣,您还可以参考 GPT-3 的主要论文。不过需要提醒您的是,关于 GPT-3 的模型有不少,其参数从 1B 到 175B 不等。因此其 GPT-3 相关的论文最主要的也有五篇,如图所示:
Papers of GPT-3: https://platform.openai.com/docs/model-index-for-researchers?...
另外,如果您是一位刚开始学习机器学习不久的新人,如果一开始就阅读 GPT-3 的论文的话,会非常吃力。GPT 的很多架构细节是在 GPT-1、GPT-2 中讨论的。所以我建议您的学习路线会是:Transformer -> GPT -> GPT-2 -> GPT-3。
以下对基于 GPT-3 模型的发展路线,做一个大致的梳理。总体而言分为以下两个发展路线:
- 代码/推理方向(例如:Codex)
- 理解人类偏好方向(例如:InstructGPT)
3.1 代码/推理方向:GPT-3 + 代码训练
代码/推理方向的发展时间线如下:
- 2020 年 5-6 月,GPT-3 论文 “Language Models are Few-Shot Learners”;
- GPT-3 的最大规模的版本,1750 亿参数的 API Davinci,此时的 GPT-3 还只能写一些简单的代码和做一些简单的数学题;
- 2021 年 7 月,Codex 论文 “Evaluating Large Language Models Trained on Code”,其中初始的 Codex 是根据 120亿 参数的 GPT-3 变体进行微调的,且通过对 159GB 的 Python 代码进行代码训练,它开始具备较强的代码/推理能力。
该方向的主要论文有:Codex 等。
3.2 理解人类偏好方向:GPT-3 + 指令学习 + RLHF
理解人类偏好方向的发展时间线如下:
- 2020 年论文 “Learning to summarize with human feedback”,开始研究 GPT-3 和 RLHF 的结合;
- 2022 年 3 月,遵循人类指令学习的论文 “Training language models to follow instructions with human feedback” 发布,即是前面我们介绍的 InstructGPT 论文;
该方向的主要论文有:InstructGPT 等。
4 GPT-4 论文概述
2023 年 3 月 GPT-4 也正式以 Model as a Service 的方式在对外提供服务。以下根据其提供的一些技术报告,以及其它第三方的资料,对 GPT-4 模型做概述如下。

Source:https://cdn.openai.com/papers/gpt-4.pdf?trk=cndc-detail
GPT-4 是一个大型多模态模型(输入图像和文本,输出文本输出)。其中 GPT 是生成式预训练模型的缩写。大型多模态模型可以广泛用于对话系统、文本摘要和机器翻译。
GPT-4 实际上是在 2022 年 8 月完成训练的,直到 2023 年 3 月 14 日才发布。在发布之前,一直在对该模型进行对抗性测试和改进。GPT-4 的内容窗口能支持多达 32,000 个 token(相当于 24000 单次或 48 页文本),如下图所示:
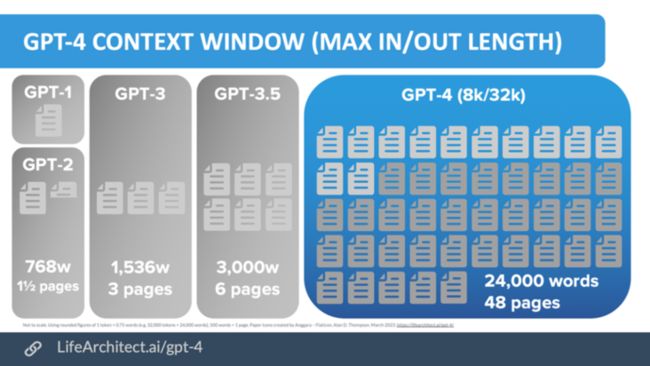
Source: https://lifearchitect.ai/gpt-4/?trk=cndc-detail
比较有趣的是 GPT-4 已经能看懂一些图梗了,不仅仅只是擅长做对话机器人。以下图为例,输入一张由三张图片拼成的图,用户问:“这张图有什么奇怪的地方?请一张图一张图地描述”。
GPT-4 会分别描述每张图中呈现的景象内容,并指出图中把一个大而过时的 VGA 接口插入一个小巧的现代智能手机充电端口是件幽默滑稽的事情。

Source:https://cdn.openai.com/papers/gpt-4.pdf?trk=cndc-detail
以及在各类考试领域已经展现出“学霸”或者“考试小王子”的潜力:

- SAT: 1410/1600 (94th percentile, top 6%).
- Uniform Bar Exam (MBE+MEE+MPT): 298/400 (90th percentile, top 10%).
- AP: Advanced Placement high school exams in biology, calculus, macroeconomics, psychology, statistics and history: 100% (5/5).
- MMLU: 86.4% (previous SOTA=75.5% for Flan-PaLM).
Source: https://lifearchitect.ai/gpt-4/?trk=cndc-detail
GPT-4 甚至可以能够读懂一些来自人类的幽默漫画深层次的内涵,这一点确实让我感到有些意外和惊喜。以下示例是让 GPT-4 解释这张漫画。GPT-4 认为它讽刺了统计学习和神经网络在提高模型性能方面的差异。
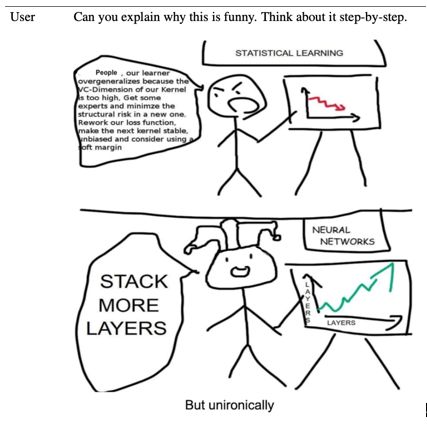

Source: https://cdn.openai.com/papers/gpt-4.pdf?trk=cndc-detail
更多关于 GPT-4,以及其它文字生成领域 State-of-the-art 的论文解读,我们也会紧密跟进这个领域的新变化和新进展,未来和大家一起探讨解读。
在下一篇内容中,我们还将通过三个关于大语言模型(LLMs)部署、编译优化、分布式训练等方面的动手实践案例,详细讨论亚马逊云科技在为支持这些大语言模型(LLMs)的编译优化、分布式训练等方面的进展和贡献,敬请期待。
请持续关注 Build On Cloud 微信公众号,了解更多面向开发者的技术分享和云开发动态!
往期推荐

作者黄浩文
亚马逊云科技资深开发者布道师,专注于 AI/ML、Data Science 等。拥有 20 多年电信、移动互联网以及云计算等行业架构设计、技术及创业管理等丰富经验,曾就职于 Microsoft、Sun Microsystems、中国电信等企业,专注为游戏、电商、媒体和广告等企业客户提供 AI/ML、数据分析和企业数字化转型等解决方案咨询服务。
文章来源:https://dev.amazoncloud.cn/column/article/641c329888a71363110...