测试老鸟整理,Selenium自动化测试POM模式分层实战(详细)
目录:导读
-
- 前言
- 一、Python编程入门到精通
- 二、接口自动化项目实战
- 三、Web自动化项目实战
- 四、App自动化项目实战
- 五、一线大厂简历
- 六、测试开发DevOps体系
- 七、常用自动化测试工具
- 八、JMeter性能测试
- 九、总结(尾部小惊喜)
前言
POM是Page Object Model的简称,它是一种设计思想,意思是,把每一个页面,当做一个对象,页面的元素和元素之间操作方法就是页面对象的属性和行为。
POM一般使用三层架构,分别为:基础封装层、页面对象层、测试用例层。
目录结构大致如下
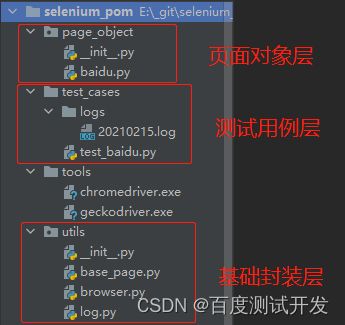
基础封装层
基础封装层主要是封装一些常用的方法,提高代码的复用。
基础封装层当前只包含了3个文件:
base_page.py:将所有界面共用的方法进行封装
browser.py:继承了selenium常用的webdriver操作,并对部分操作进行了封装
log.py:封装日志功能
class BasePage(object):
def __init__(self, driver):
self.__driver = driver
def find_element(self, by, value, times=10, wait_time=1) -> object:
return self.__driver.until_find_element(by, value, times=10, wait_time=1)
因为在页面对象层,我们会将每个界面定义成一个类对象,而每个类对象都需要传入一个webdriver的实例对象。
为了减少这样的重复操作,我们在base_page.py定义一个页面基类BasePage,在页面对象层定义的类继承该基类就可以完成webdriver实例对象的传入。
browser.py文件代码如下:
import time
import logging
from selenium.webdriver import Chrome, Firefox
from selenium.common.exceptions import NoSuchElementException
class Browser(Chrome, Firefox):
def __init__(self, browser_type="chrome", driver_path=None, *args, **kwargs):
"""
根据浏览器类型初始化浏览器
:param browser_type: 浏览器类型,只可传入chrome或firefox
:param driver_path:指定驱动存放的路径
"""
# 检查browser_type值是否合法
if browser_type not in ["chrome", "firefox"]:
# 不合法报错
logging.error("browser_type 输入值不为chrome,firefox")
raise ValueError("browser_type 输入值不为chrome,firefox")
self.__browser_type = browser_type
# 根据browser_type值选择对应的驱动
if self.__browser_type == "chrome":
if driver_path:
Chrome.__init__(self, executable_path=f"{driver_path}/chromedriver.exe", *args, **kwargs)
else:
Chrome.__init__(self, *args, **kwargs)
elif self.__browser_type == "firefox":
if driver_path:
Firefox.__init__(self, executable_path=f"{driver_path}/geckodriver.exe", *args, **kwargs)
else:
Firefox.__init__(self, *args, **kwargs)
def open_browser(self, url):
self.get(url)
self.maximize_window()
@property
def browser_name(self):
return self.capabilities["browserName"]
@property
def browser_version(self):
return self.capabilities["browserVersion"]
def until_find_element(self, by, value, times=10, wait_time=1):
"""
用于定位元素
:param by: 定位元素的方式
:param value: 定位元素的值
:param times: 定位元素的重试次数
:param wait_time: 定位元素失败的等待时间
:return: 返回定位的元素
"""
# 检查by的合法性
if by not in ["id", "xpath", "name", "class", "tag", "text", "partial_text", "css"]:
# 不合法报错
logging.error(f"无效定位方式:{by},请输入:id,xpath, name, class, tag, text, partial_text, css")
raise ValueError(f"无效定位方式:{by},请输入:id,xpath, name, class, tag, text, partial_text, css")
# 定位元素,如果定位失败,增加重试机制
for i in range(times):
# 定位元素
el = None
try:
if by == "id":
el = super().find_element_by_id(value)
elif by == "xpath":
el = super().find_element_by_xpath(value)
elif by == "name":
el = super().find_element_by_name(value)
elif by == "class":
el = super().find_element_by_class_name(value)
elif by == "tag":
el = super().find_elements_by_tag_name(value)
elif by == "text":
el = super().find_element_by_link_text(value)
elif by == "partial_text":
el = super().find_element_by_partial_link_text(value)
elif by == "css":
el = super().find_element_by_css_selector(value)
except NoSuchElementException:
# 如果报错为未找到元素,则重试
logging.error(f"通过{by}未定位到元素【{value}】,正在进行第{i+1}次重试...")
time.sleep(wait_time)
else:
# 如果成功定位元素则返回元素
logging.info(""f"通过{by}成功定位元素【{value}】!")
return el
# 如果循环完仍为定位到元素,则抛错
logging.error(f"通过{by}无法定位元素【{value}】,请检查...")
raise NoSuchElementException(f"通过{by}无法定位元素【{value}】,请检查...")
def switch_to_new_page(self):
# 获取老窗口的handle
old_handle = self.current_window_handle
handles = self.window_handles
for handle in handles:
if handle != old_handle:
self.switch_to.window(handle)
break
在browser.py文件中,我们主要定义一个 Browser类,该类继承了selenium的Chrome 和 Firefox,在实例化Browser类后,我们能使用selenium所有的方法,同时,我们在Browser类中还封装一些其它操作。
比如将查找元素的8种方法进行封装并增加元素定位失败后重试次数,比如切换新界面的handle等
log.py文件代码如下:
import os
import logging
import time
from logging.handlers import RotatingFileHandler
def log(log_level="DEBUG"):
# 创建logger,如果参数为空则返回root logger
logger = logging.getLogger()
# 设置logger日志等级
# logger.setLevel(logging.DEBUG)
logger.setLevel(log_level)
# 创建handler
log_size = 1024 * 1024 * 20
# 将日志写入到文件中
dir_name = "./logs/"
if not os.path.exists(dir_name):
os.mkdir(dir_name)
time_str = time.strftime("%Y%m%d", time.localtime())
fh = RotatingFileHandler(dir_name + f"{time_str}.log", encoding="utf-8", maxBytes=log_size, backupCount=100)
# 将日志输出到控制台
ch = logging.StreamHandler()
# 设置输出日志格式
formatter = logging.Formatter(
fmt="%(asctime)s [%(levelname)s] %(filename)s line:%(lineno)s %(message)s",
# datefmt="%Y/%m/%d %X"
)
# 注意 logging.Formatter的大小写
# 为handler指定输出格式,注意大小写
fh.setFormatter(formatter)
ch.setFormatter(formatter)
# 为logger添加的日志处理器
logger.addHandler(fh)
logger.addHandler(ch)
log.py文件主要定义了一个log函数,函数中定义了日志相关的操作,注意,定义的log函数需要在任意被执行文件中被调用。
比如,在用例层我们调用了browser.py文件中的方法,那么在架构中必定执行utils文件中__init.py文件,所以我们在__init__.py文件中调用log函数。
init.py文件代码如下:
from .log import log
log("INFO")
到此,我们完成了日志的环境配置,当需要记录日志时,只需要在文件中导入logging包,使用logging.info()这种方式记录日志即可。
页面对象层
什么是页面对象?
页面对象就是将每个界面当成一个对象,界面中的元素当成对象的属性。下面以百度首页和新闻页为例,介绍页面对象层。
在页面对象层,新增文件baidu.py,文件代码如下:
from utils.base_page import BasePage
class HomePage(BasePage):
@property
def input_box(self):
return self.find_element("id", "kw")
@property
def search_button(self):
return self.find_element("id", "su")
@property
def news_link(self):
return self.find_element("xpath", '//*[@id="s-top-left"]/a[1]')
class NewsPage(BasePage):
@property
def game_link(self):
return self.find_element("xpath", '//*[@id="channel-all"]/div/ul/li[10]/a')
类对象HomePage和NewsPage分别代表百度首页和百度新闻页,在类对象中定义了一些方法,每个方法表示页面中的一个元素,再使用装饰器@property将这些方法属性化。比如,input_box表示输入框,search_button表示搜索框。
测试用例层
下面以两个简单的用例,来演示脚本的编写。
test_baidu.py文件代码如下:
import unittest
import time
import logging
from utils.browser import Browser
from page_object.baidu import HomePage, NewsPage
class Baidu(unittest.TestCase):
def setUp(self) -> None:
self.driver = Browser("firefox")
self.driver.open_browser("http://www.baidu.com")
logging.info("打开浏览器")
logging.info(f"浏览器名称:{self.driver.browser_name},浏览器版本:{self.driver.browser_version}")
self.homepage = HomePage(self.driver)
self.newspage = NewsPage(self.driver)
def tearDown(self) -> None:
self.driver.quit()
logging.info("关闭浏览器")
def test_search(self):
""" 用例1:测试百度搜索框输入selenium能搜索出包含selenium相关的信息 """
logging.info("用例1:测试百度搜索框输入selenium能搜索出包含selenium相关的信息")
# 输入搜索信息
self.homepage.input_box.send_keys("selenium")
logging.info("输入搜索信息")
# 点击按钮
self.homepage.search_button.click()
logging.info("点击搜索按钮")
time.sleep(2)
# 校验搜索结果
els = self.driver.find_element_by_partial_link_text("selenium")
self.assertIsNotNone(els)
def test_access_game_news(self):
""" 用例2:测试通过百度首页能进入新闻界面的游戏专题 """
logging.info("用例2:测试通过百度首页能进入新闻界面的游戏专题")
# 点击新闻链接
self.homepage.news_link.click()
logging.info("点击新闻链接")
# 切换窗口
self.driver.switch_to_new_page()
logging.info("切换窗口")
# 点击游戏链接
self.newspage.game_link.click()
logging.info("点击游戏链接")
# 校验url
current_url = self.driver.current_url
self.assertEqual(current_url, "http://news.baidu.com/game")
if __name__ == '__main__':
unittest.main()
| 下面是我整理的2023年最全的软件测试工程师学习知识架构体系图 |
一、Python编程入门到精通
二、接口自动化项目实战
三、Web自动化项目实战
四、App自动化项目实战
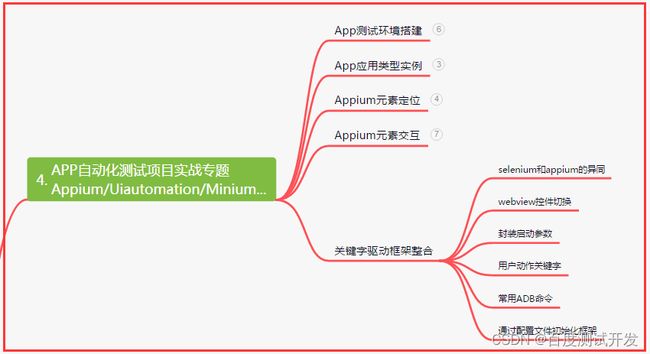
五、一线大厂简历
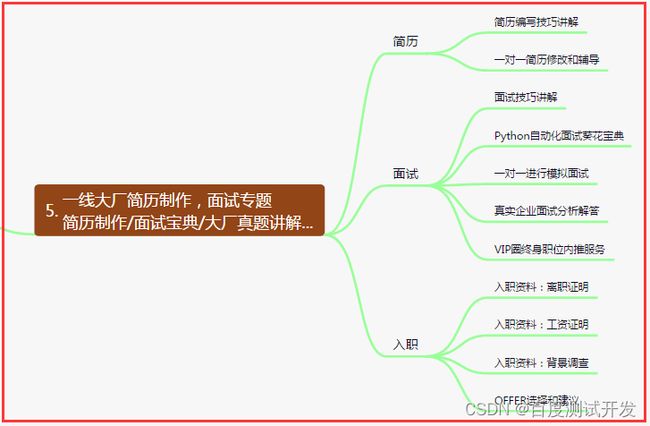
六、测试开发DevOps体系
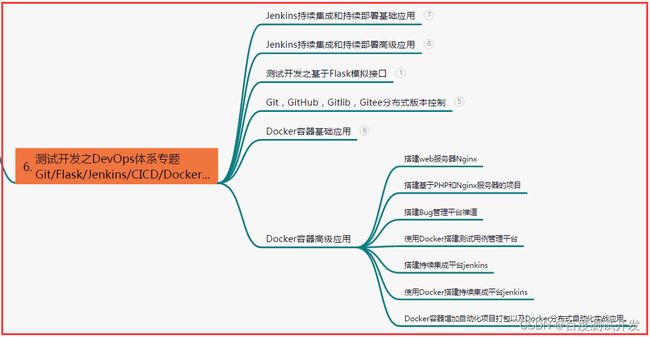
七、常用自动化测试工具
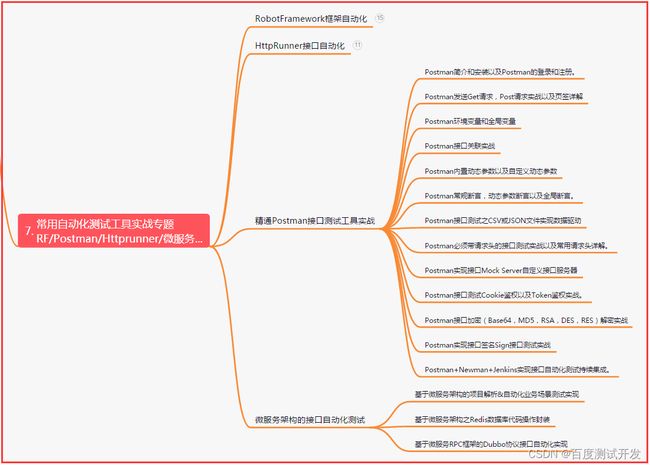
八、JMeter性能测试
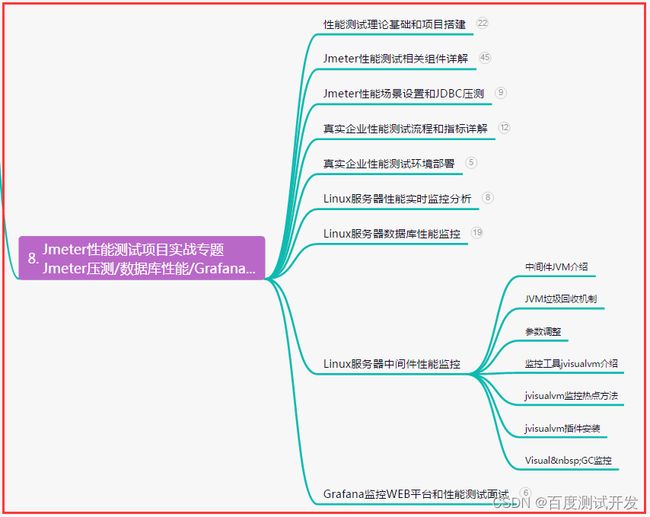
九、总结(尾部小惊喜)
每一天都是全新的起点,不要轻易放弃自己的梦想和目标。坚持努力,相信自己的实力和能力,付出总有回报,成功就在前方等待着你。无论遇到什么困难,勇于面对并克服,一步一个脚印,迈向辉煌人生!
只要你心怀梦想,坚持努力不懈,勇攀高峰,就一定能够达到自己的目标;人生的路虽然坎坷不平,但只有不断前行才能收获成功的喜悦。相信自己,勇往直前!
勇往直前,不畏困难;脚踏实地,追求卓越;不怕失败,勇于尝试;心存梦想,终将成功;坚持不懈,永不放弃;努力奋斗,创造美好未来!