李沐多模态串讲笔记
李沐多模态串讲笔记
- 0.来源
- 1.回顾
-
- 1.1 ViLT回顾
- 1.2 Clip回顾
- 1.3回顾小结
- 2.ALBEF
-
- 2.1摘要
- 2.2主体方法部分
-
- 2.2.1模型设计
- 2.2.2目标函数
- 2.2.3momentum distillation 动量蒸馏
- 2.3下游任务和实验结果
- 3.VLMo
-
- 3.1论文贡献
- 3.2研究动机
- 3.3主体方法部分
-
- 3.3.1模型设计
- 3.3.2分阶段的训练策略
- 3.4实验结果
- 3.5结语
- 3.6 BEIT系列的工作
- 4.blip
-
- 4.1贡献
- 4.2研究动机
- 4.3主体方法部分
-
- 4.3.1模型结构
- 4.3.2 Cap Filter Model
- 4.4实验部分
- 5.CoCa
-
- 5.1模型图
- 5.2可视化
- 6.BeitV3
-
- 6.1引言:Big Convergence
- 6.2模型设计
- 7.总结
0.来源
李沐多模态串讲笔记-视频链接
1.回顾
1.1 ViLT回顾
ViLT那篇论文的研究动机 其实就是为了把目标检测从视觉端给拿掉。但是ViLT也有它自己的缺点
- 它的性能不够高 ViLT在很多任务上是比不过 © 类里的这些方法
- ViLT虽然说它的推理时间很快 但其实它的训练时间非常非常的慢 我们后面也会提到 在非常标准的一个4 million的set上ViLT需要64张GPU 而且是32G的GPU训练三天 所以它在训练上的这个复杂度 和训练上的这个时间 丝毫不亚于这个 © 类的方法是有过之而无不及 所以它只是结构上简化了这个多模态学习 但没有真的让这个多模态学习 让所有人都玩得起
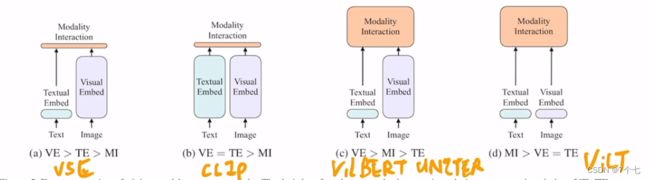
1.2 Clip回顾
CLIP模型也是非常简单的一个结构 它是一个典型的双塔模型 就是它有两个Model 一个对应文本 一个对应视觉 然后在训练的时候就是通过对比学习 让这个已有的图像文本对 在空间上拉得更近 然后让不是一个对的图片文本 就拉得尽量更远 从而最后学到了非常好的图像文本特征 然后一旦学到很好的图像文本特征之后 CLIP只需要做这种很简单的点乘 就能去做这种多模态任务 尤其是对那种图像文本匹配 或者图像文本检索的这种任务效果非常好。

1.3回顾小结
- 在多模态学习里,这个视觉特征远远要大于这个文本特征。我们知道使用这个更大更强的这个视觉模型,比如说一个更大的ViT是好的是我们需要坚持使用的。
- 模态之间的融合也是非常关键的,我们也要保证这个模态融合的模型也要尽可能的大
- 训练时 ITC Loss应该是不错的 而且训练也很高效 我们应该采纳,WPA Loss算起来是非常的慢的,所以才导致这个ViLT模型训练起来这么费劲,我们决定舍弃,然后加上mask完形填空,即对于一个好的多模态学习的模型结构来说 我们的目标函数应该也就是 ITC、ITM和MLM这三个的合体。
2.ALBEF
2.1摘要
- 作者认为预训练的目标检测器之后 你这边的这个视觉特征 和那边的文本特征其实不是align的 因为你的目标检测器是提前训练好的 然后就只用抽特征 它没有再进行这种end-to-end的训练。所以提出了ALign BEfore Fuse,融合前ITC。
- 为了了能够从这种特别noisy的网上爬下来的数据 去有效地学习这种文本图像特征 所以作者提出了一个方法 叫做Momentum Distillation 也就是这种自训练的方式去学习,即Pseudo Label 也就是用伪标签。伪标签训练的模型除了已有的模型之外 作者还采用了Moco那篇论文里提出的Momentum Encoder的形式,使用这个Momentum Model 去生成这种Pseudo Target 从而达到一个这个自训练的结果。
作者就是通过这个互信息最大化的这个角度 去做了一些理论分析 结论就是说文章里的这些训练的目标函数 包括LIM、ITM、还有就是momentum distillation 其实它们最终的作用 都是为同一个这个图像文本对 去生成不同的这个视角 其实也就是变相的在做一种data augmentation 从而让最后训练出来的模型 具备Semantic Preserving(语义保留)的功能
2.2主体方法部分
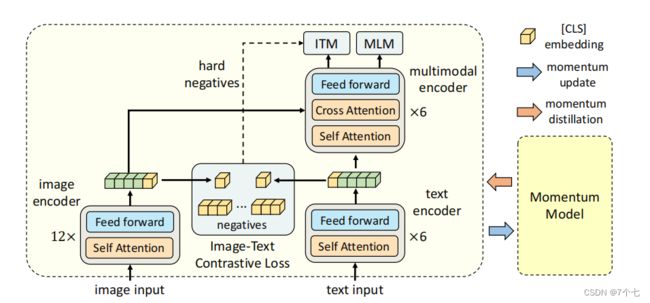
2.2.1模型设计
- 视觉端用的DEiT 也就是Data Efficient Vision Transformer 那篇论文里 在ImageNet 1K数据集上 训练出来的一个初始化参数。
- 文本模型这边其实它就是用一个BERT模型去做的这个初始化,不同的是劈成两个部分 我只用前六层去做这个文本编码 然后把剩下的那六层transformer encoder 就直接当成这个multi-model fusion的过程。
- momentum distillation是为了给这里的ITC loss提供更多这个negative。MoCo是一模一样的 这里通过把moving average的那个参数设的非常高 在论文里是0.995 从而来保证这边的这个momentum model 不会那么快的更新 所以说它产生的特征就更加的稳定。
2.2.2目标函数
- ITC loss:黄色这个CLS token 也就当做它的这个全局特征。它的负样本全都存在一个q里 这个q里有65536个这个负样本,它没有gradient 因为它是由这个momentum model产生的 所以说它并不占很多内存 那这样因为你有很多很多的这个负样本 然后你通过这种正负样本之间的这个对比 你就可以去对这个模型进行第一阶段的学习。
- ITM loss:实际操作的时候 因为判断正样本可能还有点难度 但是判断谁和谁是负样本 这个就太简单了 因为如果你不对这个负样本做什么要求 那基本上很多很多的这个图片文本 它都可以当成是 现在图像文本对的负样本 所以这个分类任务 很快它的准确度就提升得很高很高 那在预训练的时候 训练再久其实也没有任何意义了 那这个时候一个常见的做法 就是说在选这个负样本的时候 我给它一些constraint。那在ALBEF这篇论文里 它就是采取了最常用的一个方法 就是通过某种方式 去选择最难的那个负样本 也就是最接近于正样本的那个负样本 。具体的来说,如果batch size是512 那对于ITM这个loss来说 它的这个正样本对就是512个。hard negative这个时候ITM还依赖于之前的这个ITC 它就把这张图片和同一个batch里 所有的这个文本都算一遍这个cos similarity 然后它在这里选择一个除了它自己之外 相似度最高的那个文本当做这个negative。其实这个文本和这个图像 已经非常非常相似了 它基本都可以拿来当正样本用 但是我非说它是一个负样本 也就是hard negative的定义
- MLM loss:它不是像NLP那边单纯的一个MLM了,为了借助了图像这边的信息去帮助它更好的恢复,和VILT一样将文本里的整个单词被mask掉了。有一个小细节很值得关注 就是说在我们算这个ITC loss 和这个ITM loss的时候呢 其实我们的输入都是原始的i和t 原始的i和t 但是呢当我们算这个MLM loss的时候呢 它的输入是原始的i 但是是mask后的t 这意味着什么呢 这说明ALBEF这个模型 每一个训练的iteration 其实它做了两次模型的forward
2.2.3momentum distillation 动量蒸馏
从网上爬下来的这些 正的这个图像文本对 其实它们之间的关联不是那么强,有的时候甚至都不匹配。
可能会有一些影响
- 对于一张图片来说 它的这个所谓的负样本文本 其实很有可能也描述了这个图像里的很多内容这个文本可能已经很好的描述了这个图像,甚至可能比Ground Truth描述的还好 但是我们非要把它当成是一个负样本那这个时候就会对ITC的学习造成很大的影响。
- 对于这个MLM loss来说完形填空那有很多时候这个空里是可以填很多单词的 有的时候是会存在这种比Ground Truth 还要描述这个图片更好。
作者给出的解决方式是:
先构建一个momentum model,然后用这个动量模型去生成这种pseudo targets。具体这个动量模型是怎么构建的呢?其实就是在已有的模型之上去做这种exponential moving average EMA 这个技术其实是很成熟的 现在大部分的代码库里都是支持这个EMA的 包括DEiT, Swin Transformer 都是自带EMA的 它的目的就是说在这个模型训练的时候:
我们希望在训练原始的这个model的时候 我们不光是让它的这个预测跟这个ground truth的one hot label去尽可能的接近,我们还想让它这个预测跟这个动量模型出来的这个pseudo targets去尽可能的match 这样就能达到一个比较好的折中点 就是说很多的信息我们从one hot label里去学 但是当这个one hot label是错误的 或者是noisy的时候 我们希望这个稳定的momentum model 能够提供一些改进。
于是损失函数如下:
MLM loss:![]()
MLM loss:![]()
ITM loss:因为ITM这个loss 本身它就是基于ground truth 它必须要知道你是不是一个pair 它就是一个二分类任务 而且在ITM里我们又做了hard negative 这跟momentum model其实又有conflict 所以说ITM并没有动量的这个版本 。
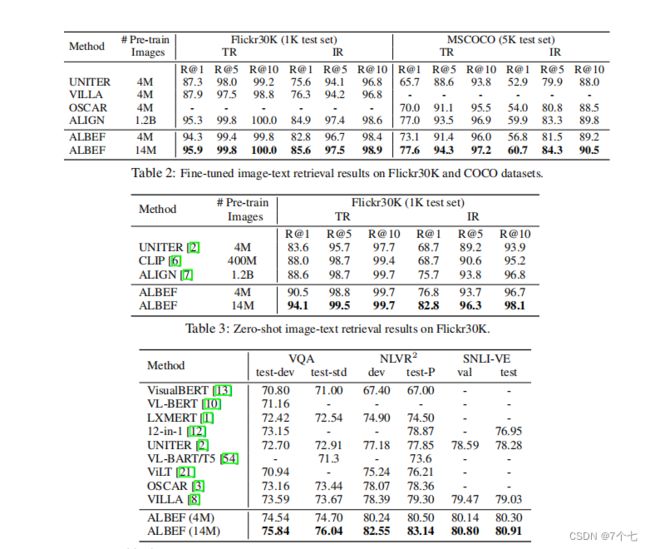
2.3下游任务和实验结果
- TR 文本到图像的检索
- IR 图像到文本的检索
- Visual Entailment 也就是视觉蕴含,就是说给定一个假设 一个前提 我能不能去推理出这个前提 如果能推理出来 我就说是一个蕴含的关系 也就是这个Entailment 如果说前后矛盾推不出来 就是这个Contradictory 如果没什么关系 你也不知道推得出来还是推不出来 那就是中立,就是Neutral 所以其实一般情况下 大部分工作都把这个Visual Entailment 变成了一个三分类的问题 因为你是分类问题 所以很自然你的衡量的指标 就是分类准确度
- VQA视觉问答
- Visual Reasoning 视觉推理 这个任务就是去预测一个文本 能不能同时描述一对图片 所以它是一个二分类任务问题 当然这个衡量指标也是准确度
- 最后一个任务是这个Visual Grounding 但其实Visual Grounding属于它自己的一个领域 很多多模态表征学习的论文里 都不会去涉及这个Visual Grounding的任务 都是专门做Grounding的论文 会去刷这些Visual Grounding的数据集 所以这里我们就不过多复述
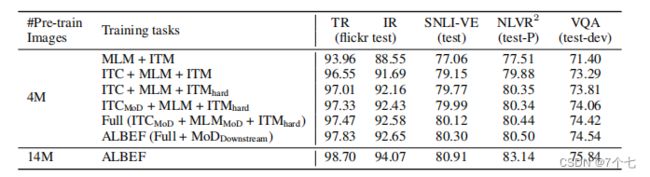
一些结论: - ITC loss真的是YYDS 也就是说CLIP、MoCo 这种对比学习的方式还是很厉害 即使是mask modeling当前非常火爆的情况下 我觉得这个对比学习还是有值得挖掘的点 或者值得有继续做下去的潜力的。
- 作者在ITM里提出的Hard Negative 这个我们可以看到 大概都有0.5左右的提升 虽然看起来不是那么显著 但是毕竟所有任务上都有提升 所以也是相当不错的一个技巧 这个也是意料之中 毕竟在对比学习出来之后 有很多很多篇论文都去研究Hard Negative 对对比学习的影响 而且Hard Negative这个概念在很早之前就有 而且应用到了各个方方面面的领域 甚至是目标检测或者物体分割 里面也都有Hard Negative的应用
- Momentum Distillation带来的提升不是那么大 但是这个研究方向还是很好的 怎么从Noise Data里去学习有效的表征也是一个非常有趣的研究方向
3.VLMo
3.1论文贡献
- 模型结构上的改进 也就是他这里说的Mixture-of-Modality-Experts
- 训练方式上的改进 他们做的这种分阶段的模型预训练
3.2研究动机
多模态学习领域大概有两个主流的模型结构
- 个就是像CLIP Align这种的 他们采取了一个dual-encoder 也就是双塔结构,模态之间的交互 就是被一个非常简单的Cosine Similarity.对于图像文本的检索非常具有商业价值,但其他下游任务不行
- 单塔就是Fusion Encoder的方式 就是我先把图像和文本分开处理一下下 但是当做模态交互的时候 我用一个Transformer Encoder 去好好的做一下模态之间的交互 这样就弥补了你之前这个双塔模式的缺陷。但是当你只有一个模型 你必须同时做这个推理 如果你这个图像文本对特别多 数据集特别大的时候 你就要把所有all possible这个图像文本对 全都要同时的去编码 然后去算这个Similarity Score 而你才能去做这个检索 所以说它的这个推理时间就会非常非常的慢 所以对于大规模数据集来说 去做检索的话基本就不太现实了。
于是作者做了以下改进:
- Mixture-of-Modality-Expert训练的时候 哪个模态的数据来了 我就训练哪个模态的Expert 然后在推理的时候 我也能根据现在输入的数据 去决定我到底该使用什么样的模型结构
- 当时多模态的训练数据集不够 比如说只有4 million的setting 或者14 million的setting 但是在单个的modality里 就是视觉或者NLP里 有大把大把的数据可以去用 即使你是想有监督的训练 视觉里也有ImageNet 22K 有14 million的数据 就已经比多模态这边最大的 14 million的setting还要大 那如果你是说我想要无监督的预训练 那可用的数据更是多的数不胜数 那文本那边也是多的数不胜数 所以说基于这个研究动机 本文VLMo的作者就提出了一个 stagewise pre-training strategy 就是分阶段去训练 先把vision expert 在视觉数据集这边训好 然后我再去把language expert 在language那边的数据集上 text-only data上训好 这个时候这个模型本身这个参数 已经是非常好的被初始化过了 这个时候你再在多模态的数据上去做一下pre-training 效果应该就会好很多。
3.3主体方法部分
3.3.1模型设计

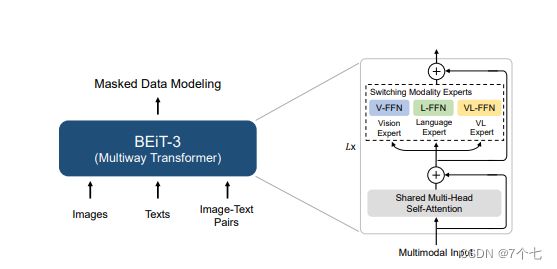
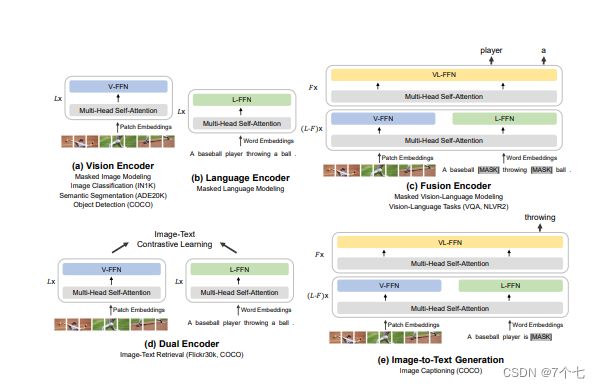
3. 这个feed-forward network这块 它不是一个feed-forward network 而是针对不同的这个输入 不同的modality 它有这个vision FFN、language FFN 和这个vision language FFN 也就是它这里说的这个switching modality expert 从而构建出了它的这个MoME transformer block
4. self-attention层 是完全share weights的 也就是说不论你是图像信号 还是这个文本信号 还是图像文本信号 你任何的这个token sequence进来 我的这个self-attention这个model weights 全都是一样的 通通都是share weights的
作者在后面说 VLMo这个base模型 在4 million的setting下训练 用64张V100的卡也要训练两天 所以说又回到ViLT那个级别的训练量了 比ALBEF要慢【注:这里的灵活性是通过增加训练强度实现的】 但总之这个模型结构 真的是很灵活 也很有趣 所以作者团队在接下来的时间中 还在继续打磨而且使用它 比如说今年最新的这个BEiT v3里 它还是使用了这个MoME Transformer结构 去做BEiT v3。
3.3.2分阶段的训练策略
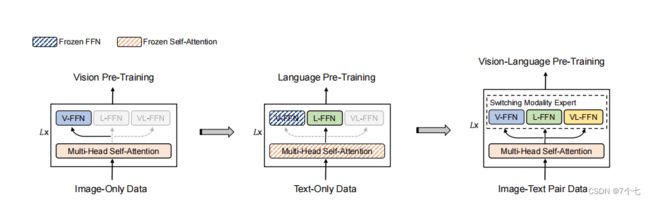
蓝色的这个虚线就代表是Frozen FFN
橘黄色的虚线 代表Frozen Self-attention
- Vision Pre-training:刚开始训练肯定没有什么需要freeze的 因为所有的东西都是随机初始化了。
- Language Pre-training:Vision Expert被冻住了因为你现在是文本数据嘛 你不需要去训练那个Vision Expert,但是非常有意思的事 是它把这个Self-Attention给冻住了。
意思就是说 我完全拿一个在视觉数据上 训练好的这么一个模型 在视觉Token Sequence上 训练好的一个自注意力模型 我可以直接拿来 对这个文本数据进行建模 我都不需要fine-tune 它这个Self-Attention就工作得很好。反而先在Language上去训练 然后再在Vision上冻住去做 好像结果不太好 - Vision Language Pre-training:该打开的就全打开了 不光是这个Self-Attention 还是后面的这三个Expert 就都打开去做fine-tune。
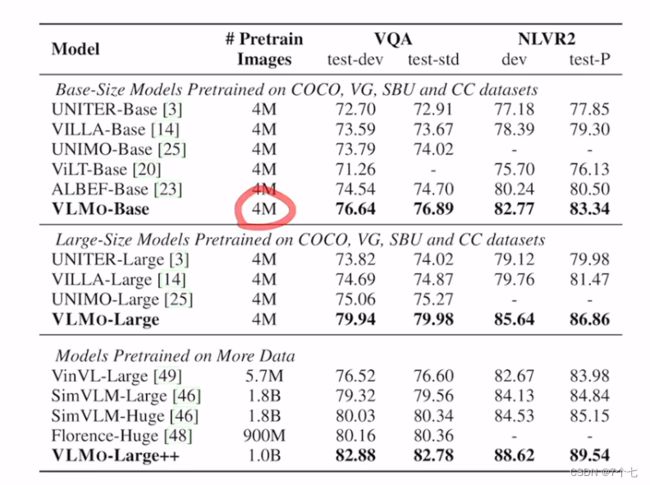
3.4实验结果
3.5结语

未来的工作
- 第一个最直白的 就是直接去scale 就是把这个模型变大 这个在作者接下来的BEIT v3里就实现了 它就用了ViT-Giant 有1.9 billion的参数
- 第二个就是做更多的下游的Vision-Language Task 比如说其中有一个更著名的 Image Captioning 就是图像字幕 做Captioning一般是需要一个Transformer Decoder 所以我们这一期讲了 这个ViLT, CLIP, ALBEF和VLMo 都不太适合能去做 接下来作者在VL-BEIT、BEIT v3里 都去做了尝试。
- 第三点作者想说的就是Unimodality 能够帮助Multimodality 同样的Multimodality也有可能能帮助Unimodality 同样的在BEIT v3的工作里 作者刷的不光是多模态的数据集 他把文本和图像的各个数据集也全刷了一遍 效果都非常好
- 最后一个更宏观的目标 就是说光是想做Vision Language 肯定有更多的模态和更多的应用场景 比如说Speech、Video或者Structured Knowledge 其实作者团队也做了很多这方面的工作 比如说在Speech这边就有WAVLM 在Structured Knowledge这边就有Layout LM v1、v2、v3 还有就是去支持这种General Purpose的多模态学习 这个最近也是比较火 就是统一用这个文本当做一个Interface 这样所有的任务都可以通过一个Prompt 然后去生成文本这种结构去实现 作者团队这边也出了一个MetaLM的工作。
3.6 BEIT系列的工作

BEIT这一系列的工作 它的发展历程 这个BEIT V1在2021年6月份就出来了 接下来在2021年11月份的时候 就出了VLMo这篇论文 因为这个时候 图像也可以用Mask Modeling去做 文本也可以用Mask Modeling去做 所以很自然的到22年6月份的时候 作者团队就推出了VL-BEIT 就是同时用Mask Modeling去做Vision Language 接下来又过了两个月 这个BEIT V2就出来了 BEIT V2其实是BEIT V1的一个升级版 它还做的是视觉这边的Dataset 而不是做的Multimodality 同样的月份 22年8月份又出了BEIT V3 BEIT V3其实就是之前 所有这些工作的一个集大成版本 就是一个多模态的网络 但是同时它也做了Unimodality 所以就是在这一步一步的积累过程之中。
4.blip
4.1贡献
- 第一个Bootstrapping其实是从数据集角度出发的 先用嘈杂的数据集去训练一个模型 接下来你再通过一些方法去得到一些更干净的数据,然后再用这些更干净的数据能不能train出更好的模型
- 第二个贡献点Unified其实就是统一两个方向 一个是Understanding也就是Image Text Retrieval VQA VRVE这些我们上次讲过的任务 还有就是Generation这种生成式任务 比如说Image Captioning就是图像生成字幕这种任务
4.2研究动机
- 模型角度:如何能提出一个Unified 一个统一的框架 用一个模型把所有的任务都解决 那该多好 那接下来我们很快就可以看到 其实BLIP这篇论文就是利用了很多VLMO里的想法 把它的模型设计成了一个很灵活的框架 从而构造了这么一个Unified Framewor
- 数据角度:用这种Noisy的数据集去预训练还是不好的 它是一个Suboptimal不是最优解 那如何能够有效地去Clean这个Noisy的Data Set 如何能够让模型更好地去利用 数据集里的这个图像文本配对信息呢 在BLIP这篇论文里 作者就提出了这个Captioner和Filter这么一个Module Captioner的作用就是我给定任意一张图片 我就用这个Captioner去生成一些这个字幕 这样我就会得到大量的这个合成数据Synthetic Data 然后同时我再去训练这么一个Filtering Model 它的作用就是把那些图像和文本不匹配的对 都从这个数据集里删掉。
4.3主体方法部分
4.3.1模型结构
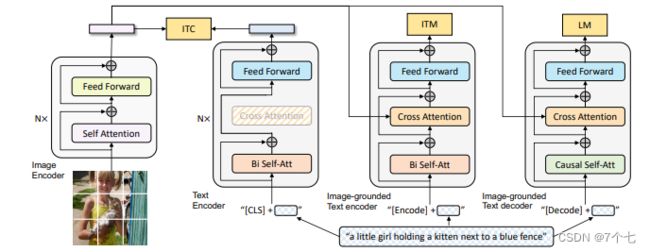
- 图像部分:一个vit模型
- 文本:Text Encoder
这里面它也是N层 而不像ALBEF里的L层了 它的目的是根据你输入的文本 去做这么一个understanding 去做这么一个分类的任务 所以说当得到了这个文本特征之后 它就去跟这个视觉特征去做ITC loss - 文本:Image-grounded Text encoder
它是一个多模态的编码器了 它这里是借助了图像的信息 然后去完成一些多模态的任务 很显然 那这个就是我们之前要做这个ITM loss。 同样的颜色代表同样的参数 就是共享参数的它不是两个模型 那这里我们可以看到 这个SA层也是共享参数的 所以相当于第一个文本编码器 和第二个文本编码器 它基本就是一样了 它的这个SA和FF全都是一致的 只不过第二个里头多了一个Cross Attention层 需要新去学习 - 文本:Image-grounded Text decoder
第一层用的是 Causal的Self-Attention 也就是因果关系的这个自注意力 就是你要去做一些这个因果推理 你要通过前面的这些文本 去推测后面的文本到底是什么 那因为这里它做的是这种Causal Self-Attention 跟前面的这个Bidirectional Self-Attention 就不一样了 所以我们可以看到 它这里颜色是不一样的 就是它俩是没办法共享参数的
因为BLIP就是ALBEF的原班人马做的 所以说里面用到了很多ALBEF的技巧 比如说在算ITC的时候 它也用了Momentum Encoder 去做更好的Knowledge Distillation 也去做更好的数据级的清理 同时在算ITM Loss的时候 也像ALBEF一样 利用ITC算的Similarity Score 去做Hard Negative Mining
4.3.2 Cap Filter Model
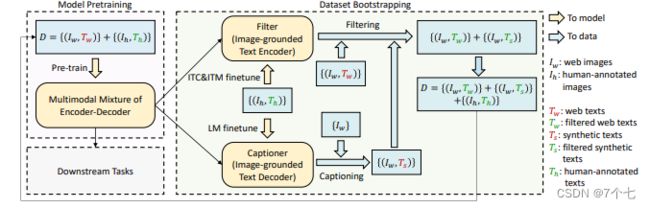
图片文本对不那么匹配数据集,也就是说这里的这个TW不好 所以作者这里用红色来表示,例如Coco
然后手工标注的,文本图片就一定匹配 所以用绿色来表示,例如Coco数据集。
filter训练过程:
- Coco和cc12m对模型进行预训练
- 把模型的itc和itm模型拿出来在Coco上再次微调得到filter
- 用这个filter模型去过滤cc12m,删去不匹配的文本图片,获得新的数据集。
作者在训练出来那个decoder之后,他发现这个BLIP模型训练好的这个decoder 真的是非常的强 他有时候生成的那个句子 比原始的那个图像文本对要好很多 就即使原来的那个图像文本对是一个match 它俩是匹配的 但是我新生成的这个文本呢 更匹配 它的质量更高 所以作者就想说那我就试试看 对吧 那我用生成的这些文本 去充当新的训练书记集 会不会得到更好的模型呢?
captioner过程:
- 在filter步骤2时,用Coco做LM finetune,得到微调后模型
- 微调后模型用cc12m Iw输入,得打新的Ts,获得新的数据集
最终将filter和captioner的新数据集和coco数据集合在一起再次对blip模型进行微调。
4.4实验部分
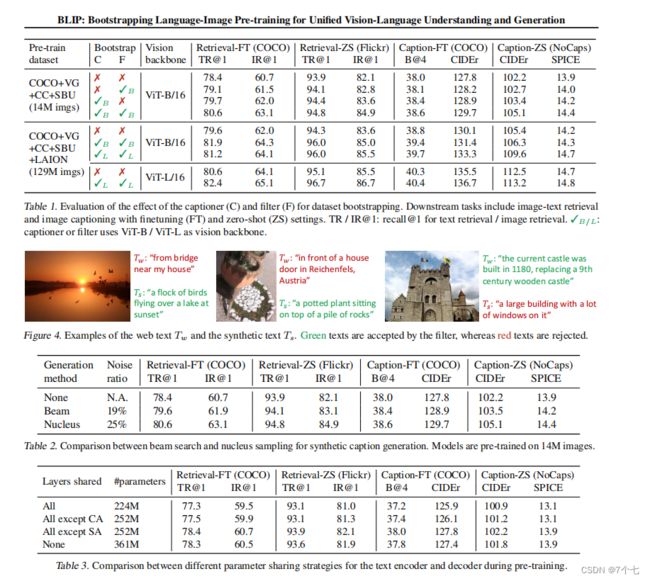
注:Caption Filtering 这个方法非常非常的有效 而且具有普适性,视频还展示了它的强大之处
5.CoCa
5.1模型图

- ImageEncoder
- TextDecoder 这里面是Decoder 不是Encoder
目标函数:
- ITC
- LanguageModelingLoss
CoCa跟ALBEF还是有区别的:
- Attentional Pooling 而这一部分呢 是可学的 作者就发现了这种可学的Pooling方式呢 能够针对不同的任务
学到更好的特征 从而呢 能在最后的这个多模态学习呢 产生更好的影响 - 不论是单模态的这个文本特征的学习 还是多模态的这个特征学习 整个文本这一端呢 全都是用的Decoder 而且因为最后的这个Loss是Captioning的Loss
作者这样设计的动机是:
不论是ALBEF还是VLMO 因为它要去算各种各样的这个目标函数,往往啊一个Training Iteration 它要forward这个模型好几次 那这无形中呢 就增加了这个模型训练的时间长度。例如明明是训练100个Epoch,可能forward三次之后呢,你相当于是训练了300个Epoch。那作者这里就想能不能只做一次forward呢 所以说为了让这个ITC Loss 和这个Captioning Loss能同时计算,把这个文本的输入啊,刚开始就必须是把后面都mask掉的 这样子呢 通过Unimodal Text Decoder出来的特征呢 能直接去做ITC Loss然后同样的输入得到的这个多模态特征呢 也直接能去做Captioning Loss 这样呢 一个Eternity Iteration就是只forward一次这个训练时间呢就会降低一些。
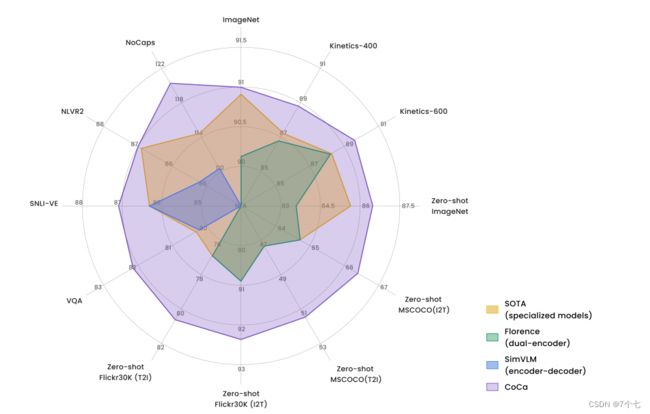
5.2可视化

6.BeitV3
6.1引言:Big Convergence
Big Convergence 是说在超级超级多的这个数据集上去做大规模的预训练,一旦这个模型训练好之后 它的这个特征就已经非常好了 可以直接Transfer到这个下游任务上去 尤其是这个模型足够大 数据足够多的时候 就有可能预训练出来一个 有通用性能的一个Foundation Model 这个Foundation Model 可能就已经能去解决 各种各样的这个模态 或者各种各样的下一个任务。
- 模型角度:因为未来肯定是多模态的 未来肯定是一个模型去做所有的Modality 去做所有的Task 肯定是一个大一统的框架 那在这个大一统的框架下 CNN就不太适合做其他的Modality 但是Transformer又适合做很多的Modality 所以就从这一点上讲 Transformer就已经胜出。
- 目标函数 :作者这里就想能不能真的就用这一个目标函数 就把一个模型训练的非常好。因为如果你用更多的这个目标函数训练速度慢,也有优化和调参的问题在里面,如果你现在有三四个Loss 那这Loss和Loss之间的Weight该怎么调 你是不是得跑好几个大模型去对比一下 该选用什么Loss Weight 同时呢有的Loss之间可能互补,有的Loss之间可能互斥。
- Scale Up:Scale Up啊 用了更多的数据 有一个Capacity很大的模型 它才有可能用一个模型啊 去解决所有的事情 所以在BEIT V3里呢 作者说也把这个模型的Size呢 扩展到Billions of Parameters里了 而且也把数据集呢 也扩展的非常大 但即使如此呢 作者团队还是坚持啊 就使用这种Public Available的这个Resource 所以学术界呢 就比较容易去这个复现 非常的难能可贵。
6.2模型设计
7.总结
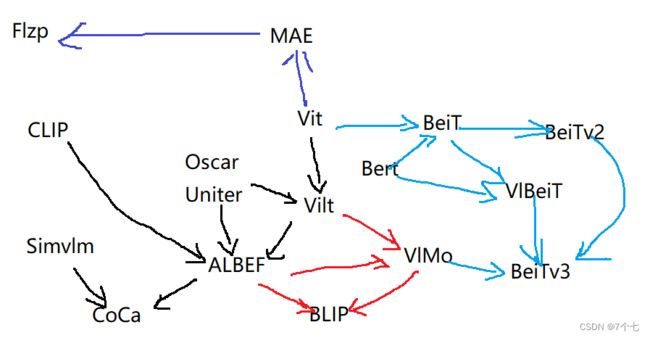
- 多模态学习之前呢,都是Oscar或者Uniter的这些工作,视觉特征的抽取太贵太慢,Vilt简化了这个模型结构。ALBEF的作者就发现了说 Clip呢比较高效啊 适合做这种Image Text Retrieval 原始的这些方法呢因为这个Modality Fusion做得很好啊 所以多模态任务非常强 然后这个ViLT呢 这个结构比较简单 所以说最后呢综合三家的长处啊就推出了ALBEF,SimVLM呢 就是用Encoder Decoder去做多模态的,SimVLM的作者呢 就在ALBEF的基础上呢 推出了这个Coca啊 很简单就用一个Contrast 和Captioning的两个Loss啊 就去训练出来了非常强大的模型。
- Vilt而且有了这个ALBEF之后呢 微软的研究者呢 就推出了这个VLMO 就用这个共享参数的方式 去推出一个统一的啊 做多模态的框架。ALBEF的作者呢又推出了这个Blip的模型,能做非常好的这个Captioning的功能 而且它的Caption Filter那个模型呢 也非常的好用 能够像一个普适的工具 一样啊用到各种各样的情形中去。
- 顺着Bert的这个思想这个微软的研究者就提出了BEIT 当时的口号呢就是说 这是计算机视觉界的这个Bert Moment 然后在BEIT的基础上呢 很快又推出了BEITv2 但是这个主要是做这个视觉Task,并不是做多模态的。因为BEIT呢,可以在视觉上做Mask Modeling 然后Bert呢可以在文本上做Mask Modeling 作者就想那视觉和文本是不是可以合在一起呢 所以说呢又推出了这个Vision Language BEIT。最后呢在他们一系列的这个实验啊 经验的这个积累之下呢 作者最后把VLMO, VLBEIT和BEITv2 三个工作合起来啊 推出了多模态的BEITv3 大幅超过了之前那个CoCa, Blip 在单模态和多模态上的各种表现。
- BEIT是去Predict那个Patch,MAE是去Mask Predict那个Pixel,当然不论是恢复Patch还是恢复Pixel 其实Vision Transformer这篇paper呢 原来他都已经做了 但是效果都不是很好。然后BEIT呢和MAE呢 都把这个效果呢 推到一个非常高的高度了 都是很有效的啊 去做Mask Data Modeling的方式。然后呢MAE呢 他有一个非常好的一个特性 就是说他在视觉那端呢 他把大量的这个Patch呢 全都给Mask掉之后 他只把那些没有Mask掉过的那些Patch呢 扔给了这个Vision Transformer去学习 这样呢就大大减少了这个计算量。
所以就引出了最近另外一篇比较有名的 Flip就是把MAE的这个有用的这个特性呢 用到Clip的这个结构里 他的模型呢就是Clip没有任何的改变 只不过是在视觉这端呢 他跟MAE一样啊 都是只用那些没有Mask的Token 把那些Mask的Token呢就扔掉了 这样无形之中呢 就把Sequence Length降低了很多 所以这个训练就快了 也就是他说的这个Fast Language Image Prediction 当然Flip这篇论文呢 做了超级多的实验 最后呢也做了Model和Data 还有这个训练Schedule上各种这个Scaling的实验。
其他论文:
Language去做Interface:Metalm,Poli
模型就是一个Encoder Decoder 然后有图像的输入啊,有文本的输入啊 但是至于这个模型 不论是在预训练的时候 还是在下游任务的时候做什么 完全是由文本那边的Prompt决定 它的输出呢永远都是文字就不论你是什么任务啊 它的输出都是文字。
Generalist Model:通用模型 ,就是不论是在预训练的时候啊还是在做下游任务的时候啊我都想用这一个模型啊 直接训练好之后做就完了,我不想再根据这个下游任务再去调整我的模型结构。