电商在线订单分析与可视化
目录
一、项目描述
二、需求分析
三、数据采集与清洗
1. 重复值处理
2.缺失值处理
3. 异常值处理
四、数据分析以及可视化
1.从商品角度
1.1 大卖商品TOP20
1.2退货最多商品TOP20
1.3商品的价位分布、各价位区间的销量
1.4该网站各个在售商品具体的价位分布情况
1.5不同价位商品的销量情况
1.6退货商品按不同价格区间进行分组
1.7 对比不同价位的退货商品数和退货商品所属种类数分布
2.从用户角度
2.1 购买金额最多、购买频率最高的TOP20顾客
2.2 按订单分组,查看各个订单中购买的商品种类数量
2.3退货商品的情况
2.4 不同国家顾客消费占比
2.5 不同国家顾客数量占比
2.6 各个国家的顾客的平均消费情况
3.RFM模型客户细分
3.1 RFM模型了解:
3.2 建模
3.3 R、F、M 值打分、客户的价值分类和汇总
3.4 分别给 R、F、M 三个值进行分级并为 RFM 打分表格
3.5 更改 R、F、M 值类型并求出各自均值,并进行打分
3.6 根据 R、F、M 评级对用户进行价值细分
3.7 用户汇总
4. 时间维度
4.1不同月份的退货、未退货商品数量和金额
4.2不同月份的销售金额、订单数、订单均额情况
4.3不同时间段的销售金额、订单数、订单均额情况
一、项目描述
随着电商的不断发展,网上购物变得越来越流行。更多电商平台崛起,对于电商卖家来说增加的不只是人们越来越高的需求,还要面对更多强大的竞争对手。面对这些挑战,就需要能够及时发现店铺经营中的问题,并且能够有效解决这些实际的问题,从而提升自身的竞争力。
根据已有数据对店铺整体运营情况进行分析,了解运营状况,对未来进行预测,已经成为电商运营必不可少的技能。
二、需求分析
为了更好地了解平台的经营状况,对销售数据进行分析,提出优化平台运营的策略,从而为平台创造更多价值。
对订单、客户、商品、地区和时间序列进行详细的分析以及可视化,从而得出这些方面对于平台销售额的影响,随之进行改善。
技术支持:利用jupyter实现
三、数据采集与清洗
导入包和数据集
import pandas as pd
import numpy as np
# 导入数据
mydata = pd.read_csv(r'Excel电商在线订单数据集.csv')
mydata.head()显示效果:
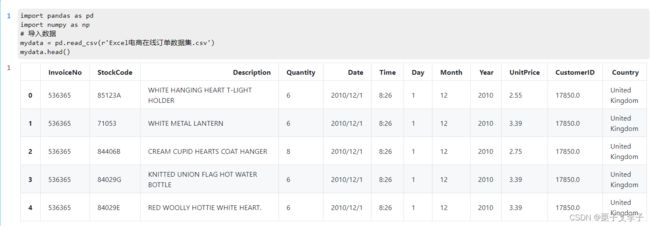
1. 重复值处理
整个数据集有541909条数据,其中完全重复的数据有5268条,剔除后剩下536641条交易数据。
# 去除重复值,只有当两行数据完全相同时才算是重复值
before_delete=mydata.shape[0]
mydata.drop_duplicates(inplace = True)
after_delete = mydata.shape[0]
print("删除前行数",before_delete,'删除后行数:',after_delete,'重复行数:',before_delete-after_delete)
实现效果:

2.缺失值处理
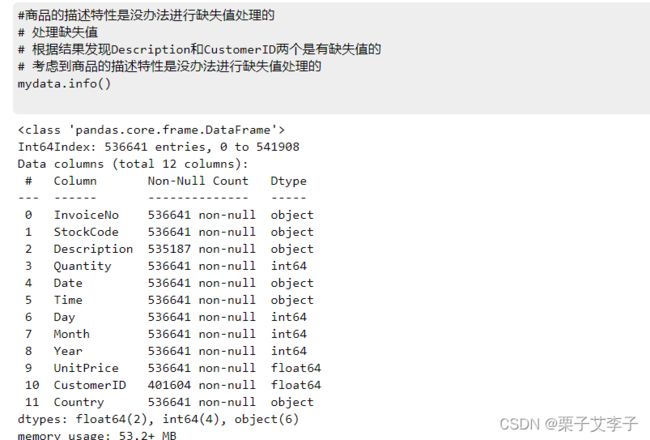
Description和CustomerID两个字段即商品描述和客户ID有缺失值,其中Descriptio缺失1454条,占总数据量的0.27%;CustomerID缺失135037行,占总数据量的25.2%。
因为商品描述是文本类型数据、对于本分析的结果不重要且缺失值占比非常小,所以不对其进行充填。
# 商品的描述特性是没办法进行缺失值处理的
# 处理缺失值
# 根据结果发现Description和CustomerID两个是有缺失值的
# 考虑到商品的描述特性是没办法进行缺失值处理的
mydata.info()实现效果:
对于CustomerID,缺失量占到了总数居的四分之一且其本身对分析结果有重要意义,必须对其填充。在已验证当前CustomerID中没有0值的前提下,充填方式选择为用0代替缺失的CustomerID值。
mydata['CustomerID'].nunique()显示效果:

# 对于缺失值的处理一般有中位数、众数、前值填充、后值填充、定值填充等方法
# 本次考虑FFill填充可能会造成较大偏差,因此采用定值填充考虑定值为0
# 首先,观察有无id==0的商品
# 注意:商品的id是数值型,不是字符串类型,结果出现的是一行字段名,说明没有商品id为0的商品
mydata[mydata['CustomerID']==0]
实现效果:

mydata['CustomerID'].fillna(0,inplace = True) #用0填充缺失值
mydata['CustomerID'].isnull().sum() #结果为0表是商品id已无缺失值
#对空值计数
mydata.isnull().sum()实现效果:
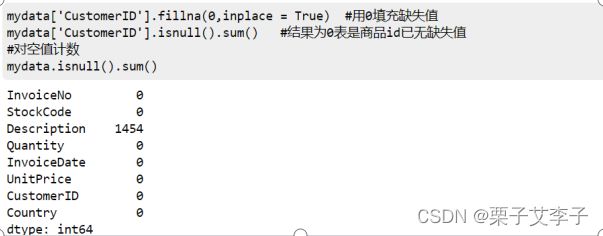
至此,缺失值处理完毕。
3. 数据转换
基于业务常识,数据形式应以合适的形式存储
mydata['Date'] = pd.to_datetime(mydata['Date'])
mydata.dtypes # 查看字段类型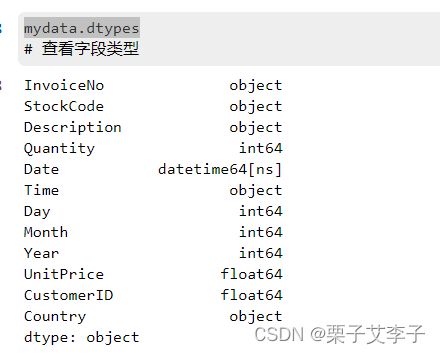
# 将商品的id转换为整型
mydata['CustomerID'] = mydata['CustomerID'].astype('int64')
# 增加一列求每次消费的消费总额
mydata['SumCost'] = mydata['Quantity'] * mydata['UnitPrice']
# 描述性统计
mydata.describe()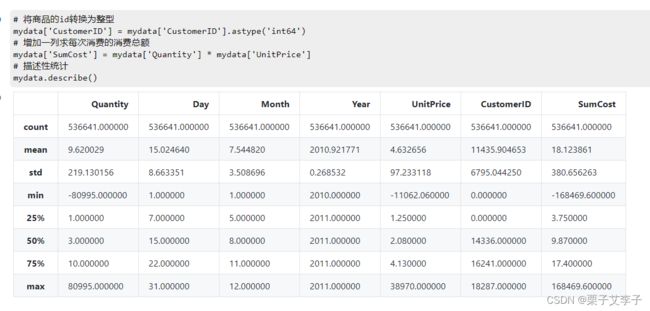
3. 异常值处理
基于业务常识,商品单价和商品数量应为正数,查看数据时发现这两种类型的异常值。
筛选出数量小于0、价格小于0的值
# 根据结果可以知道,有负值出现,这不是正常现象。所以可以想到是订单取消或者订单失败
# 筛选出数量小于0、价格小于0的值
# 根据输出结果可以发现订单的编码都是以C开头的
mydata[(mydata['Quantity'] <=0) | (mydata['UnitPrice']<=0)]实现效果:
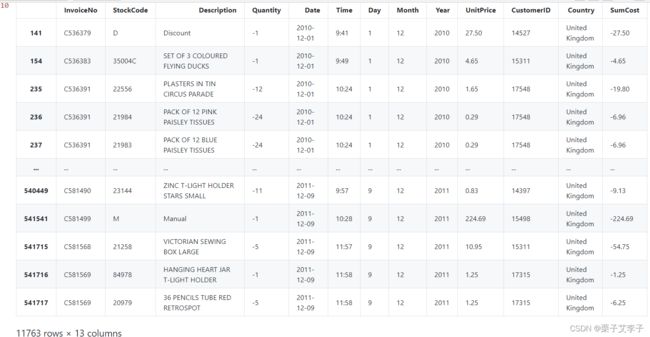
取出来查看后,发现由两种原因造成:
订单被取消即发票号以C开头的记录(共11761条);坏账数据即发票号以A开头的记录(共2条)。对于被取消的订单:由于没有发生实质交易,对平台的交易数据不存在影响故直接删除,但后续可以针对这部分数据可以尝试分析挖掘取消背后的原因;
对于坏账:数据量极小,且坏账金额也极其微小,在此也选择直接删除。
创建新表格,只包含取消订单的表格
query_c = mydata['InvoiceNo'].str.contains('C') #找订单编码包含C
# 创建新表格,只包含取消订单的表格
mydata_cannel = mydata.loc[query_c == True,:].copy()
# 创建新表格,不包含取消的订单
mydata_success = mydata.loc[-(query_c==True),:].copy()
mydata_cannel.head()取消的订单显示结果:

创建新表格,不包含取消订单的表格
mydata_success.head()
处理完取消订单后在看一下价格为0的订单
# 处理完取消订单后在看一下价格为0的订单
query_free = mydata_success['UnitPrice'] == 0
mydata_free = mydata_success.loc[query_free == True,:].copy()
mydata_not_free = mydata_success.loc[-(query_free == True),:].copy()
mydata_not_free.describe()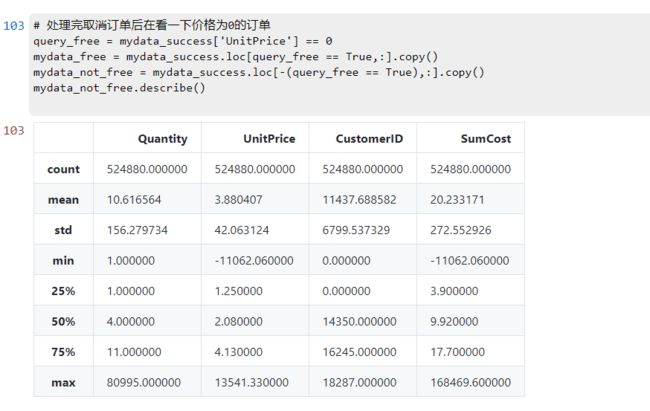
发现仍存在价格为负的订单:
发现订单编号是A开头的,表示坏账,应该删除:
# 根据结果发现仍然存在价格为负的订单:
query_mzero =mydata_not_free['UnitPrice'] <0
mydata_mzero = mydata_not_free.loc[query_mzero==True,:]
mydata_mzero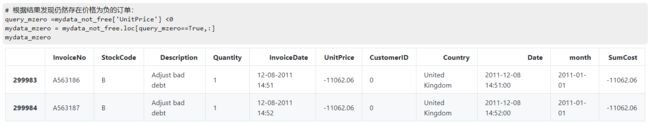
# 发现订单编号是以A开头的,表示坏账,应该删除
# 最终显示结果
mydata_finall = mydata_not_free.loc[-(query_mzero) == True,:]
mydata_finall 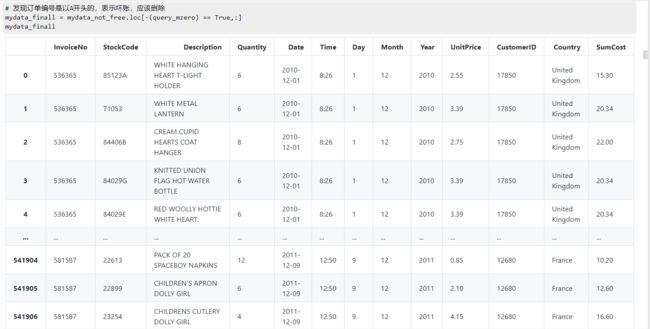
将产生的数据存储到新的csv文件:
mydata_finall.to_csv(r'new_OnlineRetail.csv')四、数据分析以及可视化
从不同角度对数据进行分析,其中包括从商品角度、从用户角度等进行分析,将数据背后的价值挖掘出来。
1.从商品角度
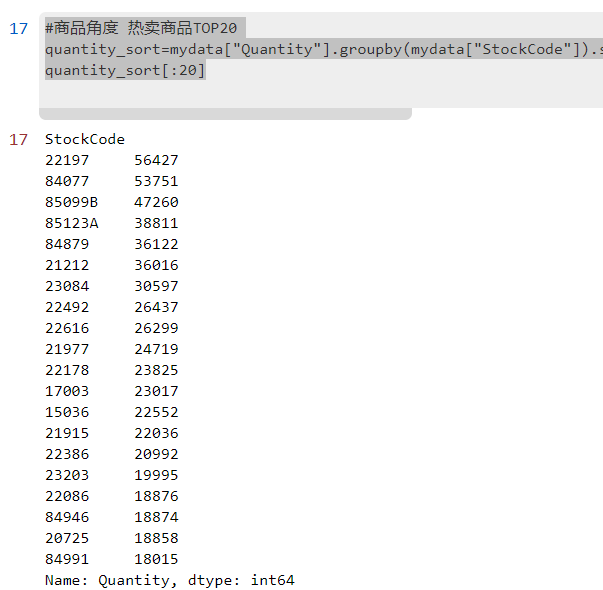
1.1 大卖商品TOP20
#商品角度 热卖商品TOP20
quantity_sort=mydata["Quantity"].groupby(mydata["StockCode"]).sum().sort_values(ascending=False)
quantity_sort[:20]实现效果:
1.2退货最多商品TOP20
#退货商品TOP20
quantity_sort[-20:] 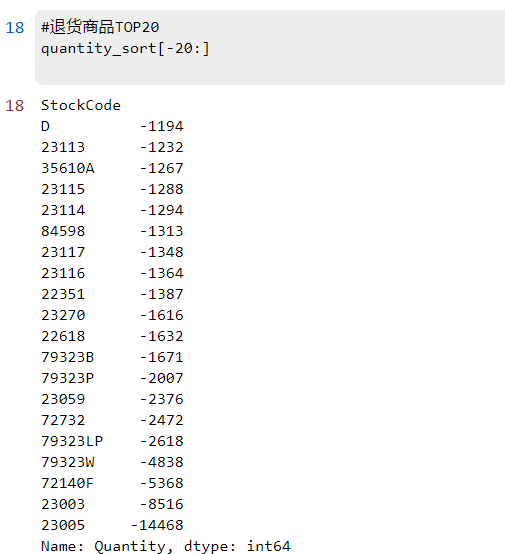
1.3商品的价位分布、各价位区间的销量
#商品的价位分布、各价位区间的销量
mydata_unique_stock=mydata.drop_duplicates(["StockCode"]) # 统计商品的种类数
mydata_unique_stock['UnitPrice'].describe() # 进行价格描述
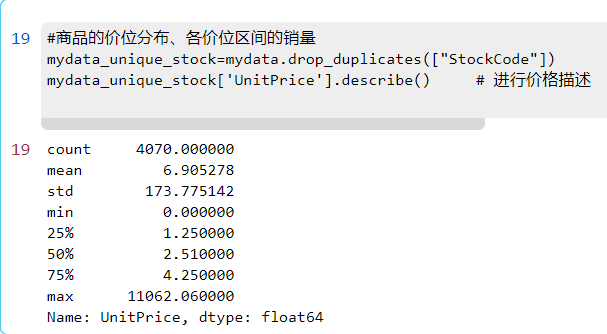
描述统计中看出,商品均价 6.9 > 商品价格的中位数 2.51,属于右偏分布,说明该网站大多售卖低价商品,少部分商品价格昂贵,少数高价商品将均值拉大,商品价格的标准差较大。
1.4该网站各个在售商品具体的价位分布情况
import matplotlib.pyplot as plt
import os该网站各个在售商品具体的价位分布情况
# 根据均值和中位数对单价UnitPrice进行分组
web_price_cut=pd.cut(mydata_unique_stock['UnitPrice'],bins=[0,1,2,3,4,5,6,7,10,15,20,25,30,50,100,10000]).value_counts().sort_index()
web_p_per=web_price_cut/web_price_cut.sum()
web_p_cumper=web_price_cut.cumsum()/web_price_cut.sum()
web_p_dis=pd.concat([web_p_per,web_p_cumper],axis=1)
web_p_dis显示效果:

画图显示:
# 画图显示
web_p_per=pd.DataFrame(web_p_per).reset_index()
%matplotlib inline
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.figure(figsize=(15,6))
x=web_p_per['index'].astype("str")
y=web_p_per['UnitPrice']
plt.bar(x,y)
web_p_cumper.plot(c='g',linewidth=2.0)
plt.xlabel('价格区间',size=15)
plt.ylabel('百分比',size=15)
plt.legend(['各价格区间累计百分比','各价格区间占比'],loc='upper left')
plt.show()
#从图表中可以看出,
# 商品类别数在价格(0,3]的区间里占比最高,合计有60%左右;
# 15元以内的商品就占了96.98%。图像显示:
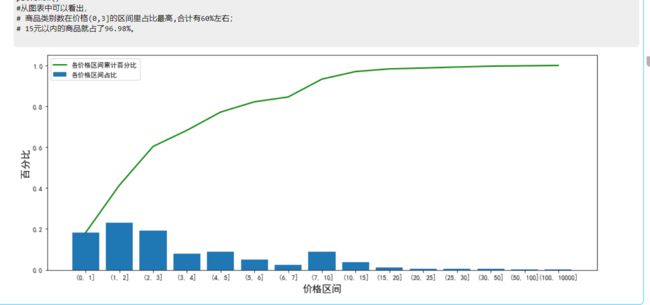
1.5不同价位商品的销量情况
#不同价位商品的销量情况
cut=pd.cut(mydata['UnitPrice'],bins=[0,1,2,3,4,5,6,7,10,15,20,25,30,50,100,10000])
quan_price=mydata['Quantity'].groupby(cut).sum()
sale_p_per=quan_price/quan_price.sum()
sale_p_cumper=quan_price.cumsum()/quan_price.sum()
sale_p_dis=pd.concat([sale_p_per,sale_p_cumper],axis=1)
sale_p_dis.columns=['销量占比','销量累计占比']
sale_p_dis现实情况:
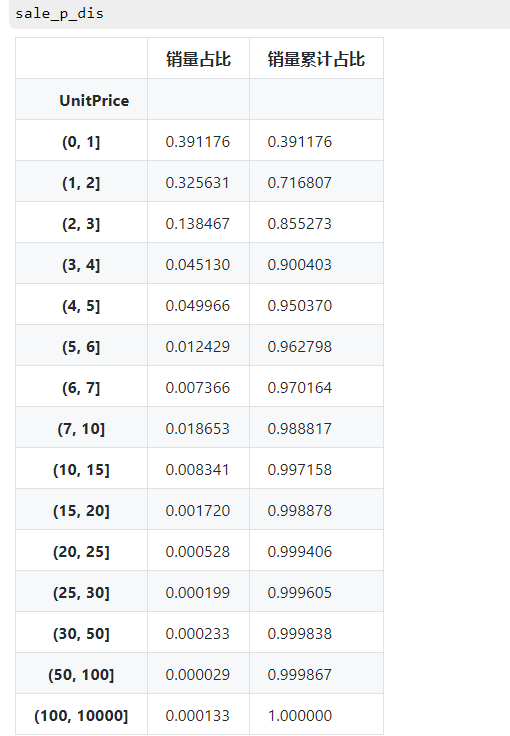
# 画图显示
sale_p_per=pd.DataFrame(sale_p_per).reset_index()
plt.figure(figsize=(15,6))
x=sale_p_per['UnitPrice'].astype("str")
y=sale_p_per['Quantity']
plt.bar(x,y)
web_p_cumper.plot(c='g',linewidth=2.0)
plt.xlabel('价格区间',size=15)
plt.ylabel('百分比',size=15)
plt.legend(['各价格区间销售量累计占比','各价格区间销售量占比'],loc='upper left')
plt.show()
# 图表显示,85.5%的销量集中在价格在3元以内的商品,
# 其中0-1区间的占比最高,为39%,区间1-2其次;
# 15元以内的商品销售比例就占据了高达99.7%。 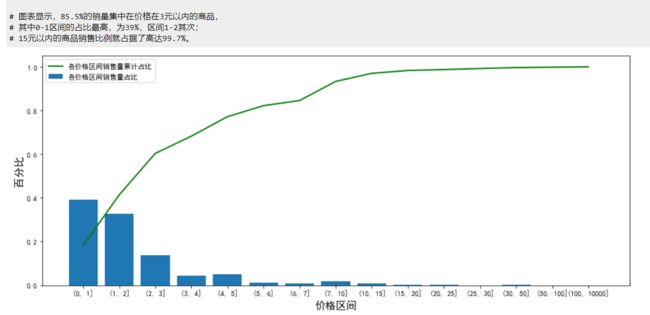
1.6退货商品按不同价格区间进行分组
# 退货商品的价格切片
cut1=pd.cut(mydata_cannel['UnitPrice'],bins=[0,1,2,3,4,5,6,7,10,15,20,25,30,50,100,10000])
return_group=mydata_cannel['Quantity'].groupby(cut1).sum() # 对退货数量进行价格分组
# 统计出退货商品各个价位区间的数量占比和累计数量占比
per_cumper=pd.concat([return_group/return_group.sum(),return_group.cumsum()/return_group.sum()],axis=1)
per_cumper.columns=['退货数占比','退货数累计占比']
per_cumper显示:
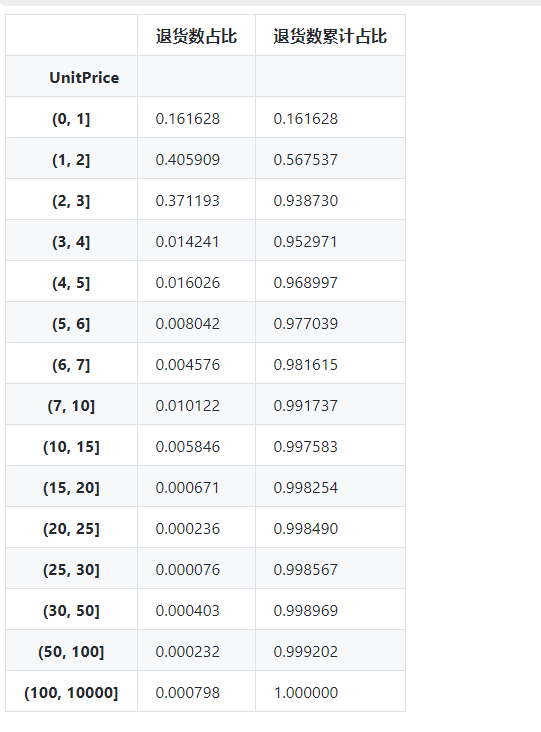
画图:
return_per=pd.DataFrame(return_group/return_group.sum()).reset_index()
return_cumper=return_group.cumsum()/return_group.sum()
plt.figure(figsize=(15,6))
x=return_per['UnitPrice'].astype("str")
y=return_per['Quantity']
plt.bar(x,y)
return_cumper.plot(c='g',linewidth=2.0)
plt.xlabel('价格区间',size=15)
plt.ylabel('百分比',size=15)
plt.legend(['退货量累计占比','退货量占比'],loc='upper left')
plt.show()
#由图可以看出退货商品最多的价格区间为 1 - 3,价格为 3以内的商品退货占比高达 93.6%
1.7 对比不同价位的退货商品数和退货商品所属种类数分布
unique_stock=mydata_cannel.drop_duplicates('StockCode') # 选出所有商品种类
# 将所有商品按照价格分组
return_uni_group=pd.cut(unique_stock['UnitPrice'],
bins=[0,1,2,3,4,5,6,7,10,15,20,25,30,50,100,10000]).value_counts().sort_index()
#画图显示不同价格区间的退货商品数和退货商品类数
plt.figure(figsize=(12,6))
(return_group/return_group.sum()).plot(c='r')
(return_uni_group/return_uni_group.sum()).plot(c='b')
plt.xlabel('价格区间',size=15)
plt.ylabel('百分比',size=15)
plt.legend(['退货商品数占比','退货商品类占比'])
plt.show()
#相较于退货商品数量最多的价格区间 1 - 3,
# 退货商品种类数最多的价格区间是 1 - 2,
# 除此以外,4-5、7-10的价格区间也是退货商品种类数较多的区间。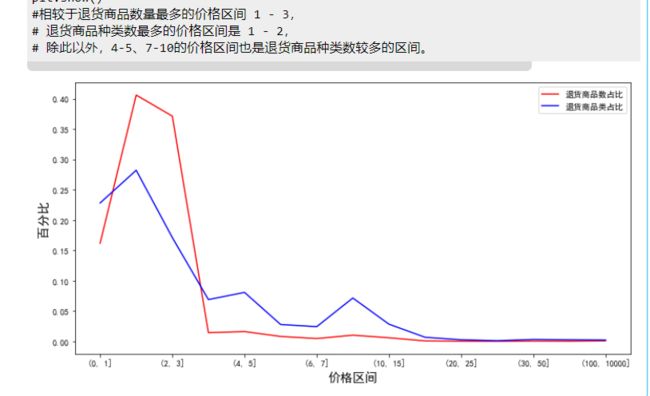
2.从用户角度
2.1 购买金额最多、购买频率最高的TOP20顾客
#计算消费金额TOP20顾客
customer_total=mydata_success["SumCost"].groupby(mydata_success["CustomerID"]).sum().sort_values(ascending=False)
customer_total[:20]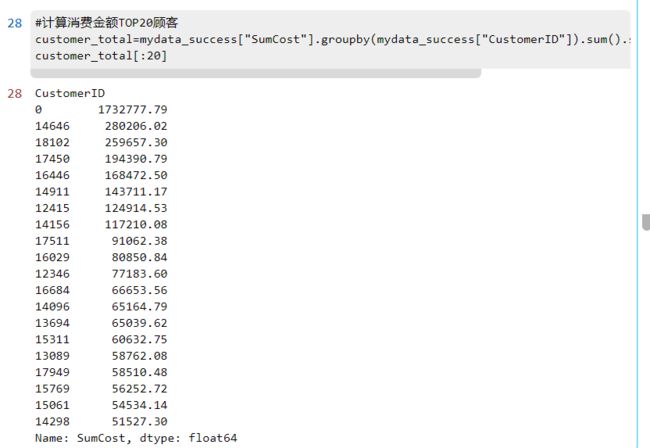
# 消费频次top20
customer_buy_freqency=mydata_success["InvoiceNo"].groupby(mydata_success["CustomerID"]).count().sort_values(ascending=False)
customer_buy_freqency[:20]
2.2 按订单分组,查看各个订单中购买的商品种类数量
按订单分组,查看各个成功订单中购买的商品种类数量描述
order_prodtype=mydata_success['StockCode'].groupby(mydata_success['InvoiceNo']).count().sort_values(ascending=False)
order_prodtype.describe()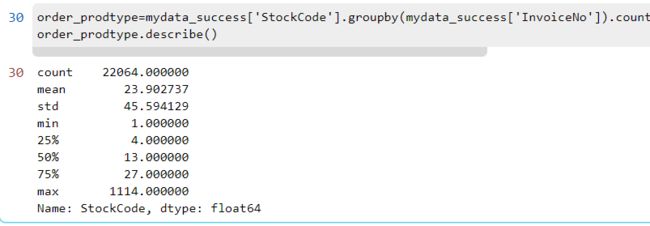
实现分段:
pd.cut(order_prodtype,bins=[0,25,50,100,200,300,500,1000,1200]).value_counts().sort_index()描述中可以看出订单中商品种数差距很大,观察平均值和中位数,发现订单的商品种数集中在 25 种左右,而一半的订单中,其种类数低于 15 种,75% 的订单中商品种数都是在 28 种以下,极少数订单的商品种数是过百的,在这些未退货的顾客中,大部分的订单商品种数在100以内。
实现效果:
2.3退货商品的情况
按订单分组,查看各个退货订单中购买的商品种类数量描述
# 按订单分组,查看各个退货订单中购买的商品种类数量描述
order_re_prodtype=mydata_cannel['StockCode'].groupby(mydata_cannel['InvoiceNo']).count().sort_values(ascending=False)
order_re_prodtype.describe()显示效果:

# 分段显示
pd.cut(order_re_prodtype,bins=[0,5,10,20,30,40,50,100,120]).value_counts().sort_index()
数据分析:相比于未退货订单,退货订单的商品种类大部分都在 10 以内。
2.4 不同国家顾客消费占比
# 不同国家顾客消费占比
country_total=mydata['SumCost'].groupby(mydata['Country']).sum().sort_values(ascending=False)
country_total_per=country_total/country_total.sum()
country_total_per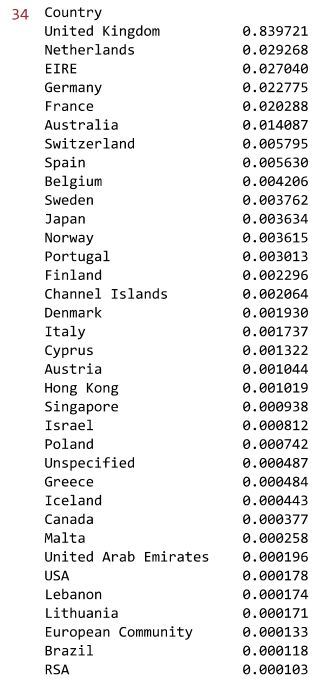

2.5 不同国家顾客数量占比
# 不同国家顾客数量占比
country_customer=mydata['CustomerID'].groupby(mydata['Country']).count().sort_values(ascending=False)
country_customer_per=country_customer/country_customer.sum()
country_customer_per
#按消费额和顾客数占比的国家分布情况
country_total_per.drop("United Kingdom",inplace=True)
country_customer_per.drop("United Kingdom",inplace=True)
plt.scatter(country_total_per.sort_index(),country_customer_per.sort_index())
plt.xlabel('消费额占比')
plt.ylabel('顾客数占比')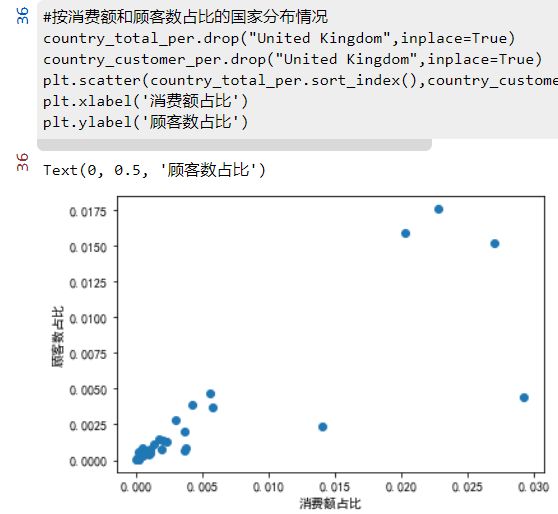
2.6 各个国家的顾客的平均消费情况
#不同国家的顾客的平均水平
mydata["SumCost"].groupby(mydata["Country"]).mean().sort_values(ascending=False)
#这家电商网站有91.36%的顾客和84%的销售额来自本国英国,然而在顾客的平均消费方面,本国只有 16.7,排名倒数第 4。
#去除本国的极端值(图中红色框位置),
销售额占比超过1%的国家有荷兰、爱尔兰、德国、法国和澳大利亚;
顾客数占比超过1%的国家有德国、法国和爱尔兰;
平均顾客消费额最高的国家是荷兰、澳大利亚、日本和瑞典,
这些国家可以作为开拓海外市场的重点对象。
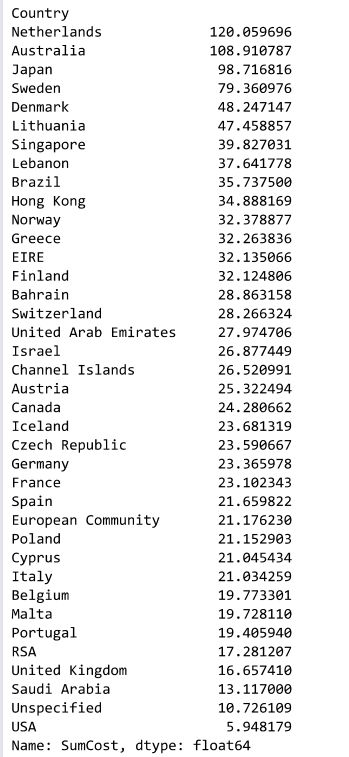
数据分析:这家电商网站有91.36%的顾客和84%的销售额来自本国英国,然而在顾客的平均消费方面,英国本国只有 16.7元,排名倒数第 4。除英国外,销售额占比超过1%的国家有荷兰、爱尔兰、德国、法国和澳大利亚;除英国外,顾客数占比超过1%的国家有德国、法国和爱尔兰;平均顾客消费额最高的国家是荷兰、澳大利亚、日本和瑞典,这些国家可以作为该电商平台开拓海外市场的重点对象。
3.RFM模型客户细分
3.1 RFM模型了解:
分析:作为商家,我们要对客户进行分组,对不同用户进行不同的营销策略,从而达到事半功倍的效果。RFM模型是衡量客户价值和客户创造利益能力的重要工具和手段,所以RFM模型适合对用户进行分析,做出精准营销。
各个指标含义:
R-最近一次消费 (Recency)
F-消费频率 (Frequency)
M-消费金额 (Monetary)

| 用户分类 |
R |
F |
M |
| 重要价值客户 |
高 |
高 |
高 |
| 重要发展客户 |
高 |
低 |
高 |
| 重要保持客户 |
低 |
高 |
高 |
| 重要挽留客户 |
低 |
低 |
高 |
| 一般价值客户 |
高 |
高 |
低 |
| 一般发展客户 |
高 |
低 |
低 |
| 一般保持客户 |
低 |
高 |
低 |
| 一般挽留客户 |
低 |
低 |
低 |
3.2 建模
计算用户最近 1 次消费时间间隔 - R值
# 先求用户最近一次消费的时间
last_trans_date = mydata_success.groupby('CustomerID')['Date'].max()
last_trans_date
#计算用户最近 1 次消费时间间隔 - R值
# 用户最近一次消费距参考时间的间隔天数
R = (mydata_success['Date'].max() - last_trans_date).dt.days
R 
计算用户的消费频率 - F值
#计算用户的消费频率 - F值
# 用户所下的订单数量---消费频率
F = mydata_success.groupby('CustomerID')['InvoiceNo'].nunique()
F 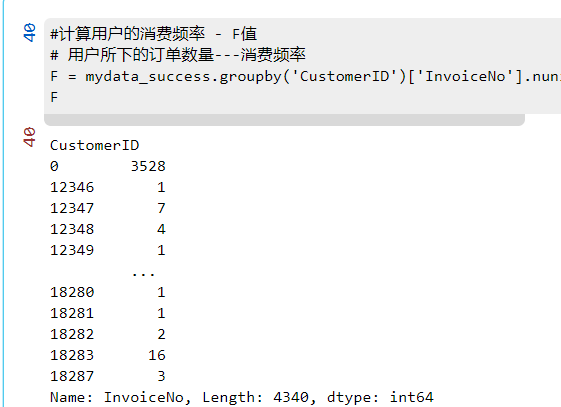
计算用户的消费金额 - M值
#计算用户的消费金额 - M值
# 用户的消费总金额
M = mydata_success.groupby('CustomerID')['SumCost'].sum()
M
3.3 R、F、M 值打分、客户的价值分类和汇总
#解决了中文字符显示为方框或乱码的形式
from pylab import mpl
# 设置显示中文字体
mpl.rcParams["font.sans-serif"] = ["SimHei"]
plt.figure(figsize=(6,18))
plt.subplot(2, 1, 2)
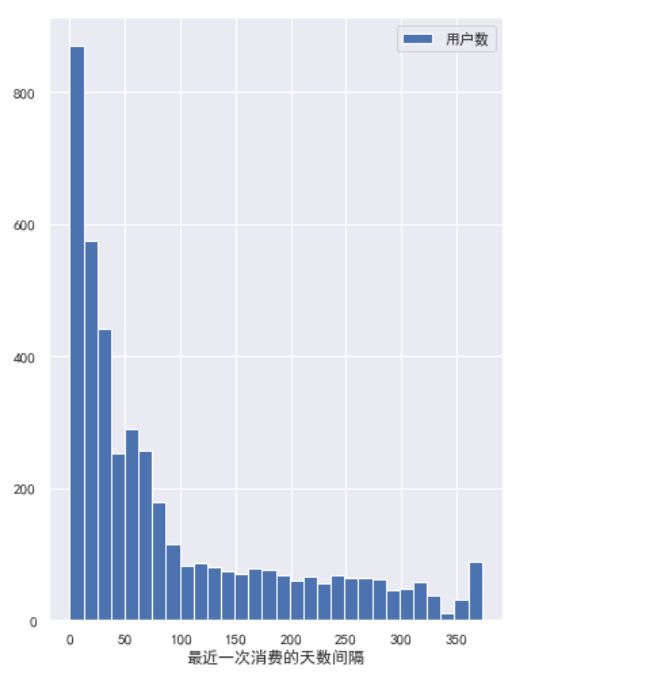
plt.hist(R,bins=30)
plt.xlabel('最近一次消费的天数间隔')
plt.legend(['用户数'],loc='upper right')
plt.subplot(2, 2, 1)
plt.hist(F,bins=30)
plt.xlabel('消费次数')
plt.legend(['用户数'],loc='upper right')
plt.subplot(2, 2, 2)
plt.hist(M,bins=30)
plt.xlabel('消费金额')
plt.legend(['用户数'],loc='upper right')
plt.show()
#%%
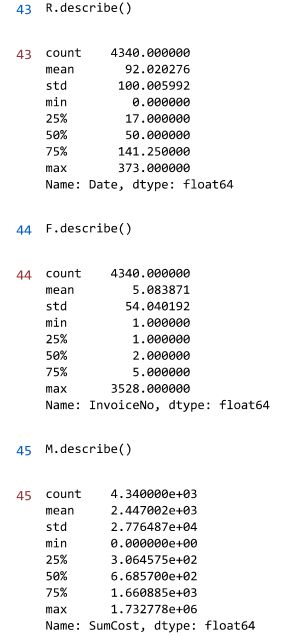
R.describe()
#%%
F.describe()
#%%
M.describe() 
实现效果:
3.4 分别给 R、F、M 三个值进行分级并为 RFM 打分表格
给 R、F、M 三个值进行分级
# 切分5级
R_bins = [0,30,70,150,270,400]
F_bins = [1,2,3,10,20,2500]
M_bins = [0,500,2000,5000,20000,2000000]
R_score = pd.cut(R,R_bins,labels=[5,4,3,2,1],right=False)
F_score = pd.cut(F,F_bins,labels=[1,2,3,4,5],right=False)
M_score = pd.cut(M,M_bins,labels=[1,2,3,4,5],right=False)
rfm = pd.concat([R_score,F_score,M_score],axis=1)
rfm.rename(columns={'Date':'R_score','InvoiceNo':'F_score','SumCost':'M_score'},inplace=True)
rfm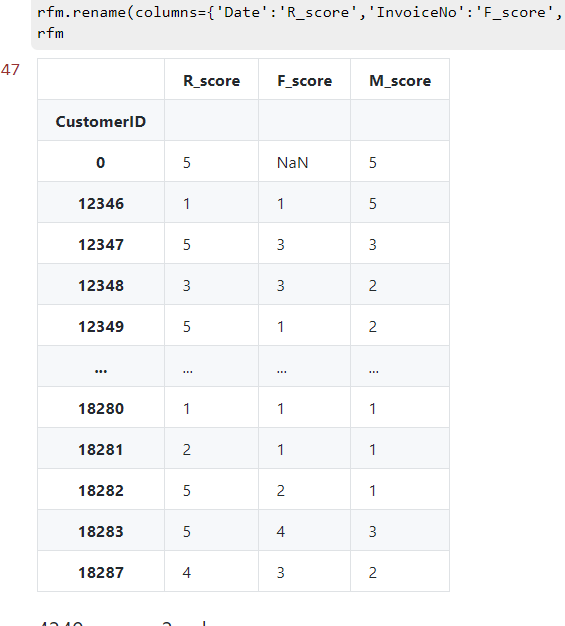
3.5 更改 R、F、M 值类型并求出各自均值,并进行打分
for i in ['R_score','F_score','M_score']:
rfm[i]=rfm[i].astype(float)
rfm.describe()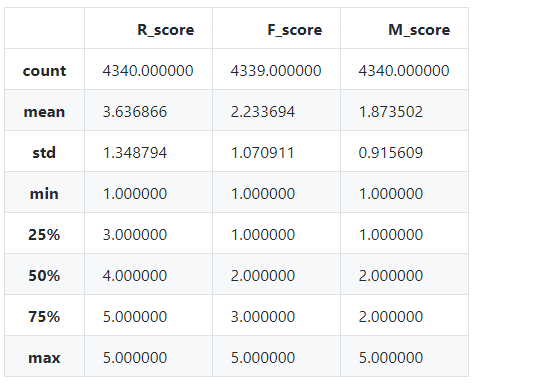
rfm['R_grade'] = np.where(rfm['R_score']>3.64,'高','低')
rfm['F_grade'] = np.where(rfm['F_score']>2.23,'高','低')
rfm['M_grade'] = np.where(rfm['M_score']>1.87,'高','低')
rfm 
3.6 根据 R、F、M 评级对用户进行价值细分
rfm['user_category']=rfm['R_grade'].str[:]+rfm['F_grade'].str[:]+rfm['M_grade'].str[:]
rfm['user_category'] =rfm['user_category'].str.strip()
def trans(x):
if x=='高高高':
return '重要价值客户'
elif x=='高低高':
return '重要发展客户'
elif x=='低高高':
return '重要保持客户'
elif x=='低低高':
return '重要挽留客户'
elif x=='高高低':
return '一般价值客户'
elif x=='高低低':
return '一般发展客户'
elif x=='低高低':
return '一般保持客户'
else:
return '一般挽留客户'
rfm['用户等级']=rfm['user_category'].apply(trans)
rfm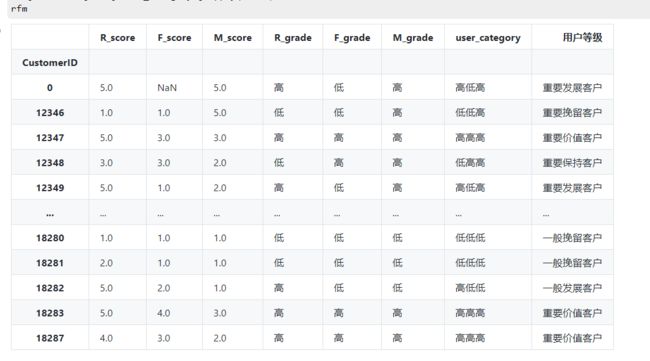
3.7 用户汇总
# 各类用户数汇总
rfm['用户等级'].value_counts()
绘图:
# 画图显示
plt.figure(figsize=(12,6))
plt.bar(rfm['用户等级'].value_counts().index,rfm['用户等级'].value_counts().values)
plt.legend(['用户数'],loc='upper right')
plt.show()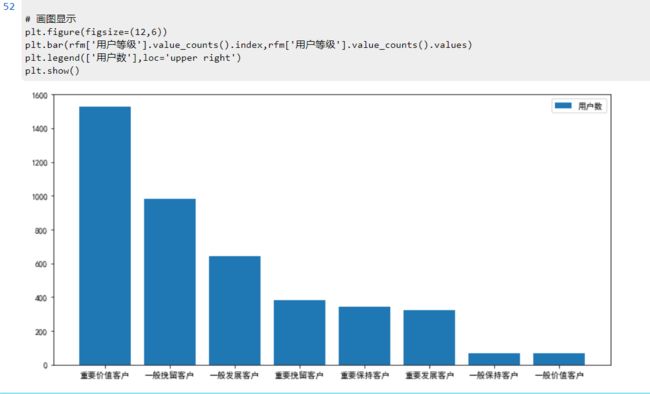
4. 时间维度
4.1不同月份的退货、未退货商品数量和金额
退货按照年月对订单和金额进行分组
退货商品数表
#不同月份的退货、未退货商品数量和金额
# 退货商品数表
df1 = mydata_cannel[mydata_cannel['Year']==2010]
df2 = mydata_cannel[mydata_cannel['Year']==2011]
temp1 = df2['Quantity'].groupby(df2['Month']).sum()
temp1 = pd.DataFrame(temp1).rename(columns={'Quantity':'2011'})
temp1['2010']=df1['Quantity'].groupby(df1['Month']).sum()
temp1 = temp1.reset_index()
temp1.head()
退货金额表
# 退货金额表
df3 = mydata_cannel[mydata_cannel['Year']==2010]
df4 = mydata_cannel[mydata_cannel['Year']==2011]
temp2 = df4['SumCost'].groupby(df4['Month']).sum()
temp2 = pd.DataFrame(temp2).rename(columns={'SumCost':'2011'})
temp2['2010']=df3['SumCost'].groupby(df3['Month']).sum()
temp2 = temp2.reset_index()
temp2.head() 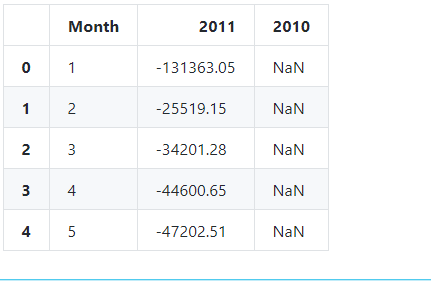
退回订单数以及订单额绘图:
plt.figure(figsize=(10,10))
plt.subplot(2, 1, 1)
x1=temp1['Month']
y1=np.abs(temp1['2011'])
y2=np.abs(temp1['2010'])
plt.scatter(x1,y2,c='g')
plt.plot(x1,y1)
plt.xlabel('月份')
plt.ylabel('退回订单数')
plt.legend(['2011年','2010年'],loc='upper center')
plt.subplot(2, 1, 2)
x2=temp2['Month']
y3=np.abs(temp2['2011'])
y4=np.abs(temp2['2010'])
plt.bar(x1,y3)
plt.plot(x1,y4,c='g',marker='o')
plt.xlabel('月份')
plt.ylabel('退回订单额')
plt.legend(['2010年','2011年'],loc='upper center')
plt.show()实现效果:

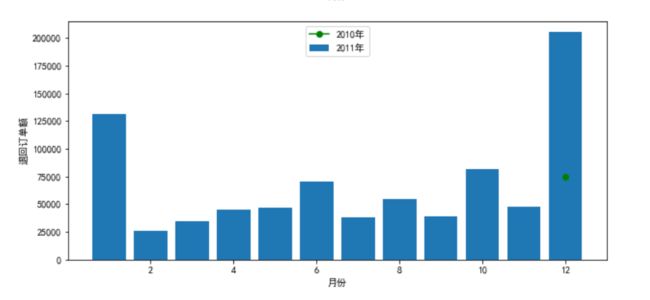
未退货按照年月对订单和金额进行分组
未退货商品数表
# 未退货商品数表
df5 = mydata_success[mydata_success['Year']==2010]
df6 = mydata_success[mydata_success['Year']==2011]
temp3 = df6['Quantity'].groupby(df6['Month']).sum()
temp3 = pd.DataFrame(temp3).rename(columns={'Quantity':'2011'})
temp3['2010']=df5['Quantity'].groupby(df5['Month']).sum()
temp3 = temp3.reset_index()
temp3.head()实现效果:

交易成功金额表:
# 货金额表
df7 = mydata_success[mydata_success['Year']==2010]
df8 = mydata_success[mydata_success['Year']==2011]
temp4 = df8['SumCost'].groupby(df8['Month']).sum()
temp4 = pd.DataFrame(temp4).rename(columns={'SumCost':'2011'})
temp4['2010']=df7['SumCost'].groupby(df7['Month']).sum()
temp4 = temp4.reset_index()
temp4.head()
成功订单:
plt.figure(figsize=(10,10))
plt.subplot(2, 1, 1)
x5=temp3['Month']
y5=np.abs(temp3['2011'])
y6=np.abs(temp3['2010'])
plt.scatter(x5,y6,c='g')
plt.plot(x5,y5)
plt.xlabel('月份')
plt.ylabel('成功订单数')
plt.legend(['2011年','2010年'],loc='upper center')
plt.subplot(2, 1, 2)
x6=temp4['Month']
y7=np.abs(temp4['2011'])
y8=np.abs(temp4['2010'])
plt.bar(x5,y7)
plt.plot(x5,y8,c='g',marker='o')
plt.xlabel('月份')
plt.ylabel('成功订单额')
plt.legend(['2010年','2011年'],loc='upper center')
plt.show()
实现效果:
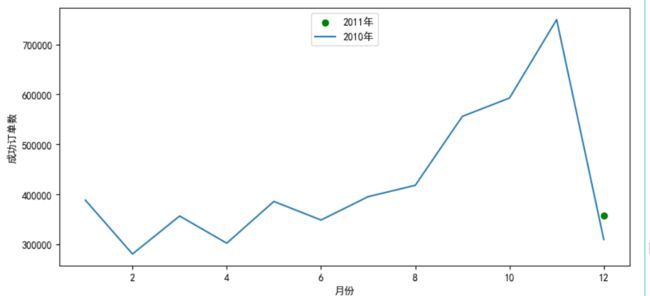

4.2不同月份的销售金额、订单数、订单均额情况
销售额:
mydata['Month']=mydata['Month'].astype('int')
mydata['SumCost'].groupby(mydata['Month']).sum().sort_index().plot()
plt.ylabel('销售额')
plt.show()
订单数:
#画图查看不同月份的订单数
mydata['InvoiceNo'].groupby(mydata['Month']).count().sort_index().plot()
plt.ylabel('订单数')
plt.show()
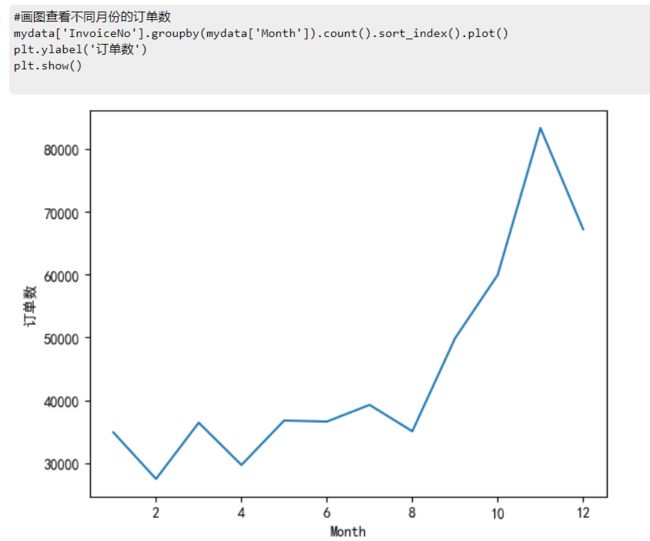
订单均额:
#画图查看不同月份的订单均销额
mydata['SumCost'].groupby(mydata['Month']).mean().sort_index().plot()
plt.ylabel('订单均销额')
plt.show()
数据分析:销售总金额与订单数量呈现相同的分布,1-12月份的销售总额整体呈上升状态,有小幅度波动,在8-11月份涨幅最大,11月份达到顶峰。一年中,平均订单金额波动较大,分别在3月、5月、9月达到了极大值,其中9月份是全年平均订单金额最大的月份。
4.3不同时间段的销售金额、订单数、订单均额情况
销售金额:
mydata["Hour"]=mydata["Time"].str.split(":",expand=True)[0].astype("int")
mydata['Hour']=mydata['Hour'].astype('int')
mydata['SumCost'].groupby(mydata['Hour']).sum().sort_index().plot()
plt.ylabel('销售额')
plt.show()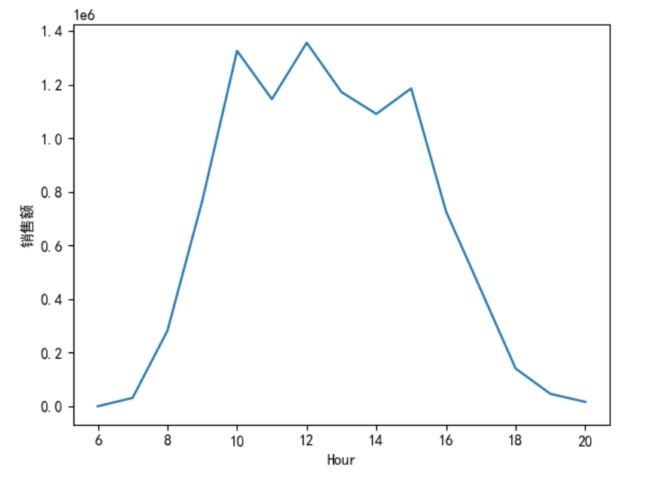
订单数:
mydata["Hour"]=mydata["Time"].str.split(":",expand=True)[0].astype("int")
mydata['Hour']=mydata['Hour'].astype('int')
mydata['Quantity'].groupby(mydata['Hour']).sum().sort_index().plot()
plt.ylabel('订单数')
plt.show()
订单均额:
mydata['SumCost'].groupby(mydata['Hour']).mean().sort_index().plot()
plt.ylabel('订单均销额')
plt.show()
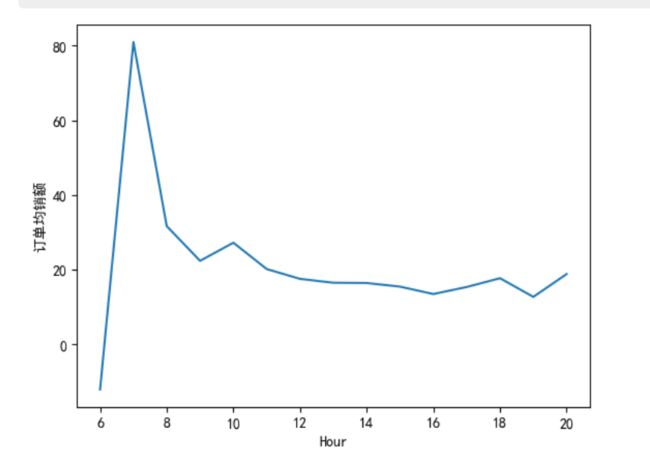
数据总结:总销售金额比较高的订单时间主要集中在 9-16 点,为上班时间,在 10 点、12 点、15 点分别达到了一天中的极大值。订单数最多的处于 11- 17 点,与销售金额的分布大致一样。平均订单金额最高的时间是早上 7 点,其他时间点相差不大。
后续利用Tableau 实现了数据可视化

报告整体效果
https://download.csdn.net/download/m0_53317797/86977193