Spark SQL数据源:JDBC
文章目录
- 一、Spark SQL读取关系数据库
- 二、Spark SQL JDBC连接属性
- 三、创建数据库与表
-
- (一)创建数据库
- (二)创建学生表
- (二)创建成绩表
- 四、读取和写入数据库表
-
- (一)利用`dbtable`属性读取数据表
- (二)利用`dbtable`属性读取数据表查询
- (三)将数据帧内容写入数据表
- (四)利用`query`属性读取数据表查询

一、Spark SQL读取关系数据库
Spark SQL还可以使用JDBC API从其他关系型数据库读取数据,返回的结果仍然是一个DataFrame,可以很容易地在Spark SQL中处理,或者与其他数据源进行连接查询。
二、Spark SQL JDBC连接属性
在使用JDBC连接数据库时可以指定相应的连接属性
| 属性 | 介绍 |
|---|---|
| url | 连接的JDBC URL |
| driver | JDBC驱动的类名 |
| user | 数据库用户名 |
| password | 数据库密码 |
| dbtable | 数据库表名或能代表一张数据库表的子查询。在读取数据时,若只使用数据库表名,则将查询整张表的数据;若希望查询部分数据或多表关联查询,则可以使用SQL查询的FROM子句中有效的任何内容,例如放入括号中的子查询。该属性的值会被当作一张表进行查询,查询格式:select * from |
| query | 指定查询的SQL语句。注意:不允许同时指定dbtable和query属性,也不允许同时指定query和partitionColumn属性。当需要指定partitionColumn属性时,可以使用dbtable属性指定子查询,并使用子查询的别名对分区列进行限定。 |
| partitionColumn lowerBound upperBound |
这几个属性,若有一个被指定,则必须全部指定,且必须指定numPartitions属性。它们描述了如何在从多个Worker中并行读取数据时对表进行分区。partitionColumn必须是表中的数字、日期或时间戳列。注意,lowerBound 和upperBound只是用来决定分区跨度的,而不是用来过滤表中的行。因此,表中的所有行都将被分区并返回。 |
| numPartitions | 对表并行读写数据时的最大分区数,这也决定了并发JDBC连接的最大数量。如果要写入数据的分区数量超过了此限制的值,那么在写入之前可以调用coalesce(numpartition)将分区数量减少到此限制的值。 |
三、创建数据库与表
(一)创建数据库
创建数据库spark_db

(二)创建学生表
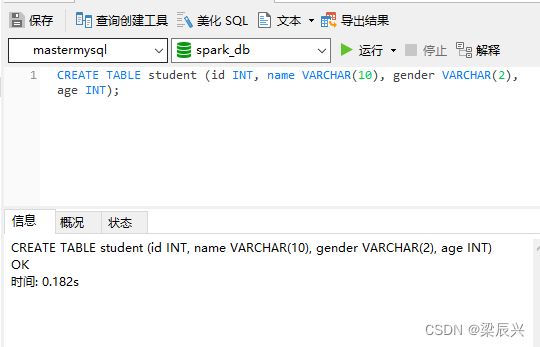
创建表student,执行命令:
CREATE TABLE student (id INT, name VARCHAR(10), gender VARCHAR(2), age INT);
给student表插入几条记录
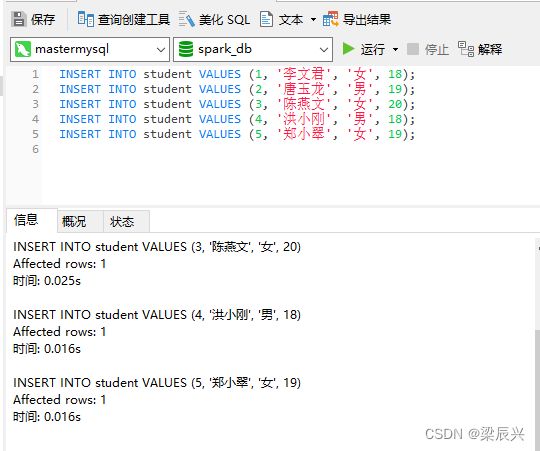
INSERT INTO student VALUES (1, '李文君', '女', 18);
INSERT INTO student VALUES (2, '唐玉龙', '男', 19);
INSERT INTO student VALUES (3, '陈燕文', '女', 20);
INSERT INTO student VALUES (4, '洪小刚', '男', 18);
INSERT INTO student VALUES (5, '郑小翠', '女', 19);
(二)创建成绩表
创建表student,执行命令:
CREATE TABLE score (id INT, name VARCHAR(10), score REAL);

给score表插入几条记录

INSERT INTO score VALUES (1, '张三', 87);
INSERT INTO score VALUES (1, '李四', 97);
INSERT INTO score VALUES (1, '王五', 92);
INSERT INTO score VALUES (1, '李宇春', 67);
INSERT INTO score VALUES (1, '张俊峰', 57);
四、读取和写入数据库表
启动Spark Shell,执行命令:spark-shell

(一)利用dbtable属性读取数据表
读取student表
val studentDF = spark.read.format("jdbc")
.option("url", "jdbc:mysql://master:3306/spark_db?useSSL=false")
.option("driver","com.mysql.jdbc.Driver")
.option("dbtable", "student")
.option("user", "root")
.option("password", "LZYp@ssw0rd")
.load()
执行上述命令

执行命令:studentDF.show()

(二)利用dbtable属性读取数据表查询
读取student与score关联查询结果
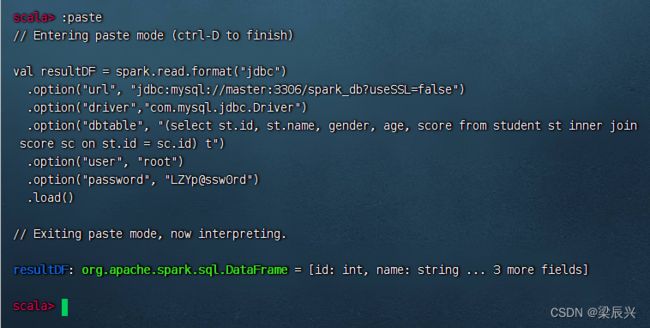
val resultDF = spark.read.format("jdbc")
.option("url", "jdbc:mysql://master:3306/spark_db?useSSL=false")
.option("driver","com.mysql.jdbc.Driver")
.option("dbtable", "(select st.id, st.name, gender, age, score from student st inner join score sc on st.id = sc.id) t")
.option("user", "root")
.option("password", "LZYp@ssw0rd")
.load()
执行上述命令(dbtable属性的值是一个子查询,相当于SQL查询中的FROM关键字后的一部分)
查看结果数据帧内容,执行命令:resultDF.show()

将数据帧内容以json格式写入HDFS的/out目录
import org.apache.spark.sql.SaveMode
resultDF.write.mode(SaveMode.Overwrite).format(“json”).save(“hdfs://master:9000/out”)

在master虚拟机上查看生成的json文件

(三)将数据帧内容写入数据表
将数据帧内容以jdbc格式写入数据库spark_db的test表
resultDF.write.mode(SaveMode.Overwrite).format("jdbc")
.option("url", "jdbc:mysql://master:3306/spark_db?useSSL=false")
.option("dbtable", "test")
.option("user", "root")
.option("password", "LZYp@ssw0rd")
.save()
执行上述命令

在Navicat里查看生成的test表
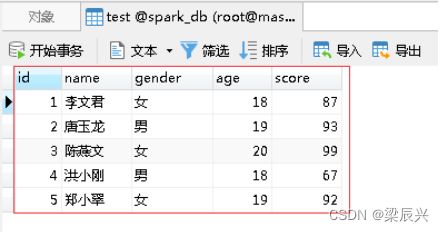
(四)利用query属性读取数据表查询
注意:Spark 2.4.0开始的Spark SQL的JDBC属性里才有query属性。
读取student与score关联查询结果
val resultDF = spark.read.format("jdbc")
.option("url", "jdbc:mysql://master:3306/spark_db?useSSL=false")
.option("driver","com.mysql.jdbc.Driver")
.option("query", "select st.name, st.gender, sc.score from student st inner join score sc on st.id = sc.id")
.option("user", "root")
.option("password", "LZYp@ssw0rd")
.load()
执行上述命令
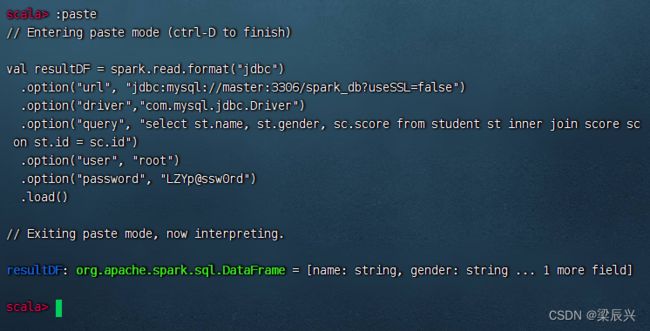
执行命令:resultDF.show()
