CENTO OS上的网络安全工具(二十一)Hadoop HA swarm容器化集群部署
如果使用swarm来构建Hadoop、Spark之类的集群,一个绕不过去的问题每个容器都需要支持SSH免密互联——因为Hadoop需要。这就需要事先准备可以一键进行集群化部署的SSH镜像。
一、SSH集群及镜像的构建
1. 准备更换镜像源的Centos7
由于Centos7已经停止维护,官方的镜像源已经不能使用,所以每次pull下来以后都需要更换镜像源,为避免麻烦,我们可以自己构造一个更换清华镜像源的镜像。
(1)编辑Dockerfile文件
新建一个空目录,在其中编辑Dockerfile文件如下。由于build的时候docker会将目录里面的东西统统打包,所以尽量空的目录是有必要的。
FROM centos:centos7
RUN sed -e 's|^mirrorlist=|#mirrorlist=|g' \
-e 's|^#baseurl=http://mirror.centos.org/centos|baseurl=https://mirrors.tuna.tsinghua.edu.cn/centos|g' \
-i.bak \
/etc/yum.repos.d/CentOS-*.repo \
&& yum makecache
CMD ["/bin/bash"]
(2) 构建国内镜像源的centos7
在Dockerfile同路径下
[root@pig1 docker]# docker build -t pig/centos7 .
[+] Building 223.0s (6/6) FINISHED
=> [internal] load build definition from Dockerfile 0.1s
=> => transferring dockerfile: 314B 0.0s
=> [internal] load .dockerignore 0.1s
=> => transferring context: 2B 0.0s
=> [internal] load metadata for docker.io/library/centos:centos7 0.0s
=> [1/2] FROM docker.io/library/centos:centos7 0.0s
=> [2/2] RUN sed -e 's|^mirrorlist=|#mirrorlist=|g' -e 's|^#baseurl=http://mirror.centos.org/centos|baseurl=https://mirrors.tuna.tsinghua.edu.cn/centos|g' 219.6s
=> exporting to image 3.2s
=> => exporting layers 3.2s
=> => writing image sha256:dd9333ee62cd83a0b0db29ac247f9282ab00bd59354074aec28e0d934ffb1677 0.0s
=> => naming to docker.io/pig/centos7 0.0s
[root@pig1 docker]# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
pig/centos7 latest dd9333ee62cd 12 seconds ago 632MB
[root@pig1 docker]#
2.构建SSH镜像
(1)镜像构建准备
在构建镜像之前,我们先梳理一下SSH免密需要安装和配置的文件:
需要安装的文件:
- openssh
- openssh-server
- openssh-clients
需要修改的文件:
- 在 /etc/hosts 尾部添加所有参与ssh免密的主机名和主机ip映射
- 在~/.ssh下设置客户端公私钥文件 ~/.ssh/id_rsa,~/.ssh/id_rsa.pub
- 在~/.ssh下设置已认证客户端密钥文件 ~/.ssh/authorizedkey
需要运行的指令:
- 运行/sbin/sshd-keygen,在/etc/ssh下生成服务端公私钥
- 运行/sbin/sshd -D & 启动ssh服务
构建镜像需要准备的文件:
- hostlist文件,记录所有参与ssh免密的主机名和主机ip映射。由于/etc/host不能在docker奖项构建时更改(此时文件系统只读),所以只能在容器启动后通过脚本方式更改;另外,由于系统启动后,会在/etc/hosts后面增加本机的hostname和ip,所以会和hostlist中的一行重复,但/etc/host中的这一行会被系统锁定,不能删除,只能考虑将hostlist中的重复行删除再向/etc/host追加的方式实现。
- init-ssh.sh文件。除上述更改/etc/host的操作外,启动ssh服务的操作也只能在容器启动后进行,所以需要一个启动脚本程序来完成。
(2)构建hostlist文件
在Dockfile同目录下新建一个hostlist文件,用来预设集群的主机名和IP地址:
[root@pig1 docker]# python3
Python 3.6.8 (default, Oct 26 2022, 09:13:21)
[GCC 8.5.0 20210514 (Red Hat 8.5.0-17)] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>>
>>> infile = open("hostlist","w")
>>> for i in range(1,16):
... infile.write("172.17.0.{:d} pignode{:d}\n".format(i+1,i))
...
>>> infile.close()
一个一个敲太麻烦,借用一下python生成一个hostlist,注意172.17.0.2是网关,不能用。
[root@pig1 docker]# cat hostlist
172.17.0.2 pignode1
172.17.0.3 pignode2
172.17.0.4 pignode3
172.17.0.5 pignode4
172.17.0.6 pignode5
172.17.0.7 pignode6
172.17.0.8 pignode7
172.17.0.9 pignode8
172.17.0.10 pignode9
172.17.0.11 pignode10
172.17.0.12 pignode11
172.17.0.13 pignode12
172.17.0.14 pignode13
172.17.0.15 pignode14
172.17.0.16 pignode15
(3)编写init-ssh.sh文件
如前所述,在docker build阶段,诸如更改hosts、启动ssh服务等操作是没有办法执行的,所以需要我们在容器启动时,通过dockfile中CMD、ENTRYPOINT等指示默认加载的启动脚本来进行。
#!/bin/bash
#1.向/etc/host文件尾部添加IP到主机名映射
#1.1 从/etc/host文件尾部提取已有主机名和IP映射
ipaddrs=`cat /etc/hosts |grep -E '[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\s\w+$'|sed 's/\s[[:alnum:]]\+$//g'`
#1.2 从hostlist文件中提取需要向/etc/hosts文件追加的IP到主机名映射表
hostlists=`cat /root/hostlist`
#1.3 从hostlist表中排除/etc/hosts中已经存在的IP到主机名映射关系
for line in $ipaddrs
do
hostlists=`echo "${hostlists}"|sed '/'"${line}"'/d'`
done
#1.4 将剩余不重复的主机名追加到hosts文件尾部
if [ -n "$hostlists" ]
then
echo 将"${hostlists}"添加到/etc/hosts中
echo $hostlists >> /etc/hosts
fi
#2. 启动SSH服务,&表示在后台启动
/sbin/sshd -D &
#3. 因为sshd在后台运行,此处前台程序执行完毕,docker会自行exit
# 所以在此处需要重新调用/bin/bash,让程序保持在前台
/bin/bash
(4)编写ssh镜像的Dockerfile
试装ssh
把上面构造的pig/centos7容器启动起来一个,执行如下操作:
主要的目的,实在计划构造ssh镜像的同样的环境下先验证一遍将要执行的操作,并获取为客户端生成的公私钥文件,以方便改造
[root@pig1 docker]# docker run -it --name pig1 --hostname pignode1 --ip 172.17.0.2 pig/centos7 bash
[root@pignode1 /]# hostname
pignode1
[root@pignode1 /]# cat /etc/hosts
127.0.0.1 localhost
::1 localhost ip6-localhost ip6-loopback
fe00::0 ip6-localnet
ff00::0 ip6-mcastprefix
ff02::1 ip6-allnodes
ff02::2 ip6-allrouters
172.17.0.2 pignode1
[root@pignode1 /]# yum install openssh openssh-server openssh-clients -y
Loaded plugins: fastestmirror, ovl
Loading mirror speeds from cached hostfile
Resolving Dependencies
--> Running transaction check
…………………………
Installed:
openssh.x86_64 0:7.4p1-22.el7_9 openssh-clients.x86_64 0:7.4p1-22.el7_9 openssh-server.x86_64 0:7.4p1-22.el7_9
Dependency Installed:
fipscheck.x86_64 0:1.4.1-6.el7 fipscheck-lib.x86_64 0:1.4.1-6.el7 libedit.x86_64 0:3.0-12.20121213cvs.el7
tcp_wrappers-libs.x86_64 0:7.6-77.el7
Complete!
[root@pignode1 /]# cd /sbin
[root@pignode1 sbin]# sshd-keygen
[root@pignode1 ssh]# /sbin/sshd -D &
[1] 78
[root@pignode1 ssh]# ps -au
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.1 0.0 11844 3080 pts/0 Ss 12:18 0:00 bash
root 78 0.0 0.1 112952 7928 pts/0 S 12:22 0:00 /sbin/sshd -D
root 79 0.0 0.0 51748 3460 pts/0 R+ 12:22 0:00 ps -au
[root@pignode1 ssh]# ssh-keygen
Generating public/private rsa key pair.
Enter file in which to save the key (/root/.ssh/id_rsa):
Created directory '/root/.ssh'.
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /root/.ssh/id_rsa.
Your public key has been saved in /root/.ssh/id_rsa.pub.
…………………………………………
+----[SHA256]-----+
[root@pignode1 ssh]# passwd
New password:
Retype new password:
passwd: all authentication tokens updated successfully.
[root@pignode1 ssh]# ssh-copy-id pignode1
/usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/root/.ssh/id_rsa.pub"
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
root@pignode1's password:
Number of key(s) added: 1
Now try logging into the machine, with: "ssh 'pignode1'"
and check to make sure that only the key(s) you wanted were added.
[root@pignode1 ssh]# cd ~/.ssh
[root@pignode1 .ssh]# ls
authorized_keys id_rsa id_rsa.pub known_hosts
伪造公钥文件
如同我们在 CENTO OS上的网络安全工具(二十)ClickHouse swarm容器化集群部署中提到过的扩充公钥的方法,对15各pignode节点都赋予访问密钥,并将.ssh文件夹中除了known_hosts文件的文件都拷贝出来备用。
在准备创建镜像的文件夹下,准备好如下所示文件:
[root@pig1 docker]# ls -a
. .. Dockerfile hostlist init-ssh.sh .ssh
编写Dockerfile
做好以上准备工作后,可以开始构建SSH的镜像了。编写SSH的Dockerfile如下。主要需要做一下几步工作:
假设(也就是要求)启动容器的时候会指定hostname为我们拷贝的hostlist中的一个,ip为对应的ip;
- 将hostlist、init-ssh.sh拷贝到/root目录下——当然随便拷贝到哪都行
- 更改init-ssh.sh的权限,添加执行权限
- 将.ssh目录整个拷贝到/root目录下
- 更改/root/.ssh/id_rsa私钥文件权限为0400,即只有root用户可读(如果使用其他用户对应修改),否则ssh会拒绝执行
- 设置root用户的密钥,否则初次ssh连接的时候过不去
- 安装openssh及服务端、客户端;
- 生成sshd密钥
- 在ssh客户端配置文件/etc/ssh/ssh_config中添加关闭指纹校验的选项,以防免密连接的时候跳出确认是否生成指纹的问题,毕竟我们不能指望hadoop有这个功夫在终端中敲个“yes”
然后在ENTRYPOINT中,设置启动init-ssh.sh。其中,将hostlist中和当前容器hostname、ip不同的行追加到/etc/hosts的后面,构建整个集群的映射关系;启动sshd服务;返回/bin/bash。之所以不用CMD,是需要避免被容器启动时指定的运行选项屏蔽掉。
FROM pig/centos7
COPY init-ssh.sh /root/init-ssh.sh
COPY hostlist /root/hostlist
COPY .ssh /root/.ssh
RUN chmod +x /root/init-ssh.sh \
&& chmod 0400 /root/.ssh/id_rsa \
&& echo 'default123' | passwd --stdin root \
&& yum install openssh openssh-server openssh-clients -y \
&& /sbin/sshd-keygen \
&& echo -e '\nHost *\nStrictHostKeyChecking no\nUserKnownHostsFile=/dev/null' >> etc/ssh/ssh_config
ENTRYPOINT ["/root/init-ssh.sh"]
编译。如果是虚拟机上测试的话,编译前一定记得看看docker0的ip地址是否正常,否则重启一下docker服务——又一次掉坑里了,检查快半小时。
[root@pig1 docker]# docker build -t pig/ssh .
[+] Building 20.5s (10/10) FINISHED
=> [internal] load build definition from Dockerfile 0.0s
=> => transferring dockerfile: 378B 0.0s
=> [internal] load .dockerignore 0.0s
=> => transferring context: 2B 0.0s
=> [internal] load metadata for docker.io/pig/centos7:latest 0.0s
=> [internal] load build context 0.0s
=> => transferring context: 382B 0.0s
=> [1/5] FROM docker.io/pig/centos7 0.0s
=> CACHED [2/5] COPY init-ssh.sh /root/init-ssh.sh 0.0s
=> CACHED [3/5] COPY hostlist /root/hostlist 0.0s
=> CACHED [4/5] COPY .ssh /root/.ssh 0.0s
=> [5/5] RUN chmod +x /root/init-ssh.sh && chmod 0400 /root/.ssh && echo 'default123' | passwd 18.3s
=> exporting to image 2.0s
=> => exporting layers 2.0s
=> => writing image sha256:3e4be2ca4730b61cc8aa7f4349ebf5b0afa582aeb1f3e3a3577ce15ffcd4eee5 0.0s
=> => naming to docker.io/pig/ssh 0.0s
[root@pig1 docker]# 3.测试SSH连接
启动两个容器测试一下:
pignode1
[root@pig1 centos]# docker run -it --name pig1 --hostname pignode1 --ip 172.17.0.2 pig/ssh bash
将172.17.0.3 pignode2
172.17.0.4 pignode3
172.17.0.5 pignode4
172.17.0.6 pignode5
172.17.0.7 pignode6
172.17.0.8 pignode7
172.17.0.9 pignode8
172.17.0.10 pignode9
172.17.0.11 pignode10
172.17.0.12 pignode11
172.17.0.13 pignode12
172.17.0.14 pignode13
172.17.0.15 pignode14
172.17.0.16 pignode15添加到/etc/hosts中
[root@pignode1 /]# ssh pignode2
Warning: Permanently added 'pignode2,172.17.0.3' (ECDSA) to the list of known hosts.
[root@pignode2 ~]# exit
logout
pignode2
[root@pig1 docker]# docker run -it --name pig2 --hostname pignode2 --ip 172.17.0.3 pig/ssh bash
将172.17.0.2 pignode1
172.17.0.4 pignode3
172.17.0.5 pignode4
172.17.0.6 pignode5
172.17.0.7 pignode6
172.17.0.8 pignode7
172.17.0.9 pignode8
172.17.0.10 pignode9
172.17.0.11 pignode10
172.17.0.12 pignode11
172.17.0.13 pignode12
172.17.0.14 pignode13
172.17.0.15 pignode14
172.17.0.16 pignode15添加到/etc/hosts中
[root@pignode2 /]# ssh pignode1
Warning: Permanently added 'pignode1,172.17.0.2' (ECDSA) to the list of known hosts.
Last login: Fri Apr 14 04:59:39 2023 from pignode1
[root@pignode1 ~]# exit
logout
可以看到已经可以做到启动容器即免密登录了。美中不足在于:因为要实现准备好hostlist,所以容器启动的时候必须按照hostlist指定ip和主机名,不过这个问题不大,因为如果要使用swarm集群,一并编写好swarm脚本就是了。
4.构建swarm下的ssh免密通信集群
有了可以装载即免密的ssh镜像,下一步,我们就可以借助swarm用它来部署ssh免密集群了。不过需要注意的是,在swarm集群中部署ssh,和在单机节点上部署ssh的docker镜像有些许不同:
(1)Swarm不支持bash作为docker前台
首先,swarm是不支持将/bin/bash作为docker前台程序的。也就是说,如果我们像前面一样,将docker镜像的ENTRYPOINT设为/bin/bash,则swarm在启动镜像后的几秒之内,就会认为容器已经没有活跃的前台程序,从而退出。然后,按照默认的swarm重启机制重启。于是我们就会看到一群不断重启的服务:
比如,我们直接使用centos的官方镜像centos/centos7启动swarm,配置文件如下:
version: "3"
services:
pigssh1:
image: centos:centos7
networks:
- pig
hostname: pignode1
pigssh2:
image: centos:centos7
networks:
networks:
- pig
hostname: pignode2
pigssh3:
image: centos:centos7
networks:
networks:
- pig
hostname: pignode3
networks:
pig:
则不断重启的过程如下:
[root@pig1 docker]# docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION
3rrx62qy2gtwcixg46xpsffas * pig1 Ready Active Leader 23.0.1
v3p0j04u0wbxfkhtkzlj0zq0d pig2 Ready Active 23.0.1
u8phg5zq1rlay99acmyca1vlo pig3 Ready Active 23.0.1
[root@pig1 docker]#
[root@pig1 docker]# docker stack deploy -c docker-compose.yml ttt
Updating service ttt_pigssh3 (id: msks8cep346rmpzujo99j91xk)
Updating service ttt_pigssh1 (id: ousc72qs2ygyzcbno2i300zh2)
Updating service ttt_pigssh2 (id: mi6nd9l1bn5st0d97zfmxj62b)
[root@pig1 docker]# docker stack ps ttt
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
6srjdbhgglae ttt_pigssh1.1 centos:centos7 pig1 Ready Ready 4 seconds ago
b95dfzw79nwa \_ ttt_pigssh1.1 centos:centos7 pig1 Shutdown Complete 4 seconds ago
rv5e1vko0asc \_ ttt_pigssh1.1 centos:centos7 pig1 Shutdown Complete 10 seconds ago
jd7650kov15k ttt_pigssh2.1 centos:centos7 pig1 Ready Ready less than a second ago
yn1t2lli0j28 \_ ttt_pigssh2.1 centos:centos7 pig1 Shutdown Complete less than a second ago
u4bwnzi4pvgi ttt_pigssh3.1 centos:centos7 pig2 Ready Ready 2 seconds ago
5vwa1d98o2bo \_ ttt_pigssh3.1 centos:centos7 pig2 Shutdown Complete 3 seconds ago
1vxrkembyuh4 \_ ttt_pigssh3.1 centos:centos7 pig2 Shutdown Complete 10 seconds ago
z815wmav05m1 \_ ttt_pigssh3.1 centos:centos7 pig2 Shutdown Complete 17 seconds ago
所以我们需要改造一下官方的镜像,Dockerfile如下:
FROM centos:centos7
ENTRYPOINT ["tail","-f","/dev/null"]
也就是更改官方镜像最后从/bin/bash入口的方式,使用CMD或ENTRYPOINT,以tail -f /dev/null命令作为前台,该命令会一直将前台进程阻塞,从而避免被swarm错误退出。
修改yml文件中的镜像:
version: "3"
services:
pigssh1:
image: pig/test
networks:
- pig
hostname: pignode1
pigssh2:
image: pig/test
networks:
networks:
networks:
- pig
hostname: pignode2
pigssh3:
image: pig/test
networks:
networks:
networks:
- pig
hostname: pignode3
networks:
pig:
重新用swarm部署:
[root@pig1 docker]# docker stack deploy -c docker-compose.yml ttt
Creating network ttt_pig
Creating service ttt_pigssh2
Creating service ttt_pigssh3
Creating service ttt_pigssh1
[root@pig1 docker]# docker stack ps ttt
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
7vqun3os7por ttt_pigssh1.1 pig/test:latest pig1 Running Running 2 seconds ago
hjnb05mcabhm ttt_pigssh2.1 pig/test:latest pig3 Running Running 15 seconds ago
y0wyocsblwrf ttt_pigssh3.1 pig/test:latest pig1 Running Running 8 seconds ago
[root@pig1 docker]# docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
6d90c934bb09 pig/test:latest "tail -f /dev/null" 16 seconds ago Up 15 seconds ttt_pigssh1.1.7vqun3os7poryxdbzbr844gxe
3d47036fd047 pig/test:latest "tail -f /dev/null" 22 seconds ago Up 21 seconds ttt_pigssh3.1.y0wyocsblwrfw49v57l6huv82
[root@pig1 docker]# docker exec -it 6d90c934bb09 bash
[root@pignode1 /]#
可以看到,这次很顺利的部署完成,并且使用容器ID可以登录某个节点上部署的容器。
PS:在前面swarm集群部署clickhouse的过程中,一直没有将clickhouse-client部署成功,与这个可能有很大关系。留待有空再试。
(2)Swarm不支持固定分配IP地址
书接上一小节。在记录本节内容之前,先利用上节部署的环境做一个小实验。
[root@pignode1 /]# ping pignode2
PING pignode2 (10.0.1.3) 56(84) bytes of data.
64 bytes from ttt_pigssh2.1.hjnb05mcabhm4vk2loeg89o3v.ttt_pig (10.0.1.3): icmp_seq=1 ttl=64 time=1.86 ms
64 bytes from ttt_pigssh2.1.hjnb05mcabhm4vk2loeg89o3v.ttt_pig (10.0.1.3): icmp_seq=2 ttl=64 time=1.04 ms
64 bytes from ttt_pigssh2.1.hjnb05mcabhm4vk2loeg89o3v.ttt_pig (10.0.1.3): icmp_seq=3 ttl=64 time=1.40 ms
^C
--- pignode2 ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2003ms
rtt min/avg/max/mdev = 1.047/1.438/1.865/0.334 ms
[root@pignode1 /]# cat /etc/hosts
127.0.0.1 localhost
::1 localhost ip6-localhost ip6-loopback
fe00::0 ip6-localnet
ff00::0 ip6-mcastprefix
ff02::1 ip6-allnodes
ff02::2 ip6-allrouters
10.0.1.9 pignode1
在我们已经启动的这些pignodes中,我们登入其中一个——比如pignode1,从pignode1里面直接ping pignode2,是能ping通的,也就是说,pignode1能够正确解析pignode2的名字;然后cat一下hosts文件,发现两件事——一是pignode2的IP映射关系并不是通过该文件记录的;二是pignode1的IP和一般容器部署时的IP不一样,是10.0.1.*。
这是swarm的特点。swarm实际上直接又建立了一套网络体系,它自己就可以负责解析加入到swarm网络的服务的IP,服务名就对应hostname,所以无需我们去建立hostname和IP的对应关系。另一方面,swarm为了负载均衡和容器重启的需要,自己建立了一套虚拟IP的网络,没有使用docker0下的网段,所以也不支持固定的IP分配。
这就是一个尴尬的事,物理机,虚拟机,docker,swarm,我现在的机器上网段套网段,套了4层。虽然确实也有办法在swarm中设置静态地址,比如先建立一个overlay网络,然后网上attach服务的方式,但既然swarm不愿意支持,最好也别强人所难,不然容易掉进不可预知的大坑……
既然解决不了问题,我们就解决提出问题的人——ssh。因为进行ssh免密部署时,需要指定ssh节点的IP和hostname映射关系——这是我们必须设置固定IP的原因。但是如果这个映射关系不需要我们提供呢?比如swarm已经提供了名字解析,我们完全可以不必再去做费力不讨好的hosts列表啊。
所以,如下更改init.sh,只负责启动sshd服务,并且使用tail -f /dev/null挂住前台就好:
#!/bin/bash
#1. 启动SSH服务,&表示在后台启动
/sbin/sshd -D &
#2. 因为sshd在后台运行,此处前台程序执行完毕,docker会自行exit
# 另swarm集群下,似乎会将bash认为是后台程序,从而自动退出
# 故而此处使用tail -f /dev/null阻塞程序,让程序保持在前台
tail -f /dev/null
再创建镜像时,也 不需要再拷贝hostlist:
FROM pig/centos7
COPY init-ssh.sh /root/init-ssh.sh
COPY .ssh /root/.ssh
RUN chmod +x /root/init-ssh.sh \
&& chmod 0400 /root/.ssh/id_rsa \
&& echo 'default123' | passwd --stdin root \
&& yum install openssh openssh-server openssh-clients -y \
&& /sbin/sshd-keygen \
&& echo -e '\nHost *\nStrictHostKeyChecking no\nUserKnownHostsFile=/dev/null' >> etc/ssh/ssh_config
ENTRYPOINT ["/root/init-ssh.sh"]
将镜像build为pig/sshs镜像,使用下面的部署文件部署:
version: "3"
services:
pigssh1:
image: pig/sshs
networks:
- pig
hostname: pignode1
pigssh2:
image: pig/sshs
networks:
- pig
hostname: pignode2
pigssh3:
image: pig/sshs
networks:
- pig
hostname: pignode3
networks:
pig:
启动部署(记得把镜像导出到各个节点上先):
[root@pig1 docker]# docker stack deploy -c docker-compose.yml ttt
Creating network ttt_pig
Creating service ttt_pigssh1
Creating service ttt_pigssh2
Creating service ttt_pigssh3
[root@pig1 docker]# docker stack ps ttt
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
wqtkk5uwb1oa ttt_pigssh1.1 pig/sshs:latest pig3 Running Running 7 seconds ago
qbczq4fx8ulb ttt_pigssh2.1 pig/sshs:latest pig2 Running Running 3 seconds ago
vfeakouuzsbu ttt_pigssh3.1 pig/sshs:latest pig1 Running Running less than a second ago
[root@pig1 docker]# docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
002fe4668083 pig/sshs:latest "/root/init-ssh.sh" 8 seconds ago Up 7 seconds ttt_pigssh3.1.vfeakouuzsbuidqubs3yoruz1
[root@pig1 docker]# docker exec -it 002fe4668083 bash
[root@pignode3 /]# ssh pignode1
Warning: Permanently added 'pignode1,10.0.2.3' (ECDSA) to the list of known hosts.
[root@pignode1 ~]#
试验成功!
二、构建Swarm下Hadoop集群
1. 构建Hadoop节点镜像
根据前面构建SSH镜像的方法,我们只需要在SSH镜像的基础上,继续安装JAVA环境,下载hadoop压缩包并释放到我们准备的目录下(比如/root/hadoop),然后设置好HADOOP_HOME、JAVA_HOME等环境变量。就可以按照CENTOS上的网络安全工具(十二)走向Hadoop(4)
中的配置方法进行配置了。
先把Dockerfile扔出来再解释:
# 1. 还是从官方的centos7镜像为起点
FROM centos:centos7
# 2. 口令参数需要从外部传入,即 docker build --build-arg password='default123' -t pig/hadoop .
ARG password
# 3. 构造更改了清华镜像源的centos7镜像,其实如果采取离线安装方式也不需要
RUN sed -e 's|^mirrorlist=|#mirrorlist=|g' \
-e 's|^#baseurl=http://mirror.centos.org/centos|baseurl=https://mirrors.tuna.tsinghua.edu.cn/centos|g' \
-i.bak \
/etc/yum.repos.d/CentOS-*.repo\
&& yum clean all\
&& yum makecache
# 4. 拷贝启动容器时的初始化脚本,用于执行启动sshd服务、初始化hadoop的系列操作
COPY init-hadoop.sh /root/init-hadoop.sh
# 5. 拷贝SSH免密登录的相关密钥文件,目前只放置了15个
COPY .ssh /root/.ssh
# 6. 拷贝所有待安装软件(主要是用于离线安装openssh和javasdk的rpm包)
COPY ./rpm /root/rpm/.
# 7. 解压Hadoop到/root目录下,一般会解压形成一个名为欸hadoop-3.3.5的文件夹
ADD hadoop-3.3.5.tar.gz /root
# 8. 构建ssh一键部署相关配置(私钥文件、公钥认证文件权限设置,root用户口令设置)
RUN chmod 0400 /root/.ssh/id_rsa \
&& chmod 0600 /root/.ssh/authorized_keys \
&& echo ${password} | passwd --stdin root
# 9. 安装openssh
# 在线安装方式: RUN yum install openssh openssh-server openssh-clients -y
# 离线安装方式:
RUN rpm -ivh /root/rpm/tcp_wrappers-libs-7.6-77.el7.x86_64.rpm\
&& rpm -ivh /root/rpm/libedit-3.0-12.20121213cvs.el7.x86_64.rpm\
&& rpm -ivh /root/rpm/fipscheck-1.4.1-6.el7.x86_64.rpm /root/rpm/fipscheck-lib-1.4.1-6.el7.x86_64.rpm\
&& rpm -ivh /root/rpm/openssh-7.4p1-22.el7_9.x86_64.rpm\
&& rpm -ivh /root/rpm/openssh-clients-7.4p1-22.el7_9.x86_64.rpm\
&& rpm -ivh /root/rpm/openssh-server-7.4p1-22.el7_9.x86_64.rpm
# 10.1 生成服务器端密钥
RUN /sbin/sshd-keygen \
# 10.2 配置SSHD免密登录(更改强制指纹验证为no,避免弹出指纹确认问题)
&& echo -e '\nHost *\nStrictHostKeyChecking no\nUserKnownHostsFile=/dev/null' >> etc/ssh/ssh_config
# 11. 安装JAVA环境
# 在线安装方式:RUN yum install java-11* -y
# 离线安装方式:
RUN rpm -ivh /root/rpm/jdk-11.0.19_linux-x64_bin.rpm
# 由于一些文章说不安装这个包会导致namenode相互不能连接,反正也不大,不管有没有用,先装一个以防万一
RUN rpm -ivh /root/rpm/psmisc-22.20-17.el7.x86_64.rpm
# 12. 设置初始化脚本可执行属性,并删除已经安装完成的rpm包,避免镜像过大
RUN chmod +x /root/init-hadoop.sh \
&& rm /root/rpm -rf\
#------------------------------------安装Hadoop环境-------------------------------------#
# 1. 设置与HADOOP相关的全局环境变量,设置hadoop安装及工作目录,并赋值给HADOOP_HOME,然后将HADOOP_HOME加入到PATH,这样执行hdfs start-dfs.sh等命令时,不用必须进入到hadoop工作目录。
# 1.1 将hadoop工作目录改个名,用起来方便
RUN mv /root/hadoop-3.3.5 /root/hadoop\
# 1.2 实际只有/.bashrc中的配置会在容器启动时被加载并发挥作用,不过无所谓,都改了也没啥
&& echo -e "export HADOOP_HOME=/root/hadoop\nexport PATH=\$PATH:\$HADOOP_HOME/bin\nexport PATH=\$PATH:\$HADOOP_HOME/sbin" >> /etc/profile\
&& echo -e "export HADOOP_HOME=/root/hadoop\nexport PATH=\$PATH:\$HADOOP_HOME/bin\nexport PATH=\$PATH:\$HADOOP_HOME/sbin" >> /root/.bashrc\
&& source /root/.bashrc
# 2. 设置$HADOOP_HOME/etc/hadoop/hadoop-env.sh中的JAVA_HOME环境变量
RUN sed -i 's|#[[:blank:]]export[[:blank:]]JAVA_HOME=$|export JAVA_HOME=/usr|g' /root/hadoop/etc/hadoop/hadoop-env.sh
# 3. 设置 HDFS的用户角色
RUN echo -e "export HDFS_NAMENODE_USER=root\nexport HDFS_DATANODE_USER=root\nexport HDFS_SECONDARYNAMENODE_USER=root\n">>/root/hadoop/etc/hadoop/hadoop-env.sh\
# 4. 设置 YARN的用户角色
&& echo -e "export YARN_RESOURCEMANAGER_USER=root\nexport YARN_NODEMANAGER_USER=root\nexport YARN_PROXYSERVER_USER=root">>/root/hadoop/etc/hadoop/yarn-env.sh
# 5. 默认启动脚本
CMD ["/root/init-hadoop.sh"]
从#1到#10的步骤,和第一部分中配置SSH的过程完全一样,其实也可以直接使用第一部分中的镜像作为起点构建。不同之处,一个是root用户的口令我们改作编译时指定,另一个是改用离线方式安装openssh:
(1)代入编译参数
因为不想将口令这种特别个性化的东西放在Dockerfile文件里面,所以使用ARG标识设置了一个名为password的参数,然后再设置口令的指令中,使用shell格式的变量调用形式${password}将这个参数传入指令中。
创建镜像的时候,使用--build-arg选项代入参数:
[root@pighost1 Dockerfile-hadoop]# docker build --build-arg password='your password' -t pig/hadoop:cluster .
[+] Building 85.1s (12/12) FINISHED
=> [internal] load build definition from Dockerfile 0.0s
=> => transferring dockerfile: 3.21kB 0.0s
=> [internal] load .dockerignore 0.0s
=> => transferring context: 2B 0.0s
=> [internal] load metadata for docker.io/library/centos:centos7 0.0s
=> [1/7] FROM docker.io/library/centos:centos7 0.0s
=> [internal] load build context 0.0s
=> => transferring context: 6.12kB 0.0s
=> CACHED [2/7] RUN sed -e 's|^mirrorlist=|#mirrorlist=|g' -e 's|^#baseurl=http://mirror.centos.org/centos|baseurl=ht 0.0s
=> [3/7] COPY init-hadoop.sh /root/init-hadoop.sh 0.0s
=> [4/7] COPY .ssh /root/.ssh 0.0s
=> [5/7] COPY ./rpm /root/rpm/. 1.1s
=> [6/7] ADD hadoop-3.3.5.tar.gz /root 14.0s
=> [7/7] RUN chmod +x /root/init-hadoop.sh && chmod 0400 /root/.ssh/id_rsa && chmod 0600 /root/.ssh/authorized_ke 56.4s
=> exporting to image 13.3s
=> => exporting layers 13.3s
=> => writing image sha256:6bb64f678a7292b9edb7d6b8d58a9b61e8cc8718ef545f9623a84e19652cb77a 0.0s
=> => naming to docker.io/pig/hadoop:cluster 0.0s 这里password使用单引号,以避免使用双引号将特殊字符转义。
(2) 离线方式
说起离线方式,貌似已经很久没有这么干了,主要是最近单位网络还比较给力,各种环境试验没出过什么岔子。这次这篇记录,本来是打算五一前发出来,结果接到一个出差任务耽误了一周。想着五一期间趁着休息花一天时间整理出来,于是在家重新搭了个环境。没想到,就这么一搭,搭出来一个接一个的连环坑,把整个五一都搭了进去。
网络环境造就了大坑之一:其实虽然现在已经从坑里爬了出来,但仍然是没有完全弄明白发生了什么事情,因为一个悲剧的发生,往往不是只有一个环节出问题,而是一连串的环节出了问题导致的。这里不完全记录一下:
Docker升级了……
因为是重新搭的环境,所以在家里的虚拟机上,Dockers是五一期间新下载安装的,然后神奇的发生了拉取镜像失败的问题。这个问题极为飘忽不定。具体症结就是,docker会报对于注册如武器registry-1.docker.io,找不到对应的主机。
[root@pighost1 ~]# ping registry-1.docker.io
PING registry-1.docker.io (52.1.184.176) 56(84) bytes of data.
^C
--- registry-1.docker.io ping statistics ---
6 packets transmitted, 0 received, 100% packet loss, time 5105ms
[root@pighost1 ~]# docker pull hello-world
Using default tag: latest
Error response from daemon: Get "https://registry-1.docker.io/v2/": dial tcp: lookup registry-1.docker.io on 192.168.21.2:53: no such host
但是同样是在虚拟机所在的windows主机上,还有一个早期安装的Docker Desktop,工作则完全正常,丝滑无比。所以一开始我以为是虚拟机网络的问题,查了好久。
直到我解决了问题(见后),打算拿出笔记本移植环境的时候,发现笔记本上的Desktop出问题了,于是进行了重装,结果发现重装后的Desktop也出现了同样的问题。这才确定这一故障应该是和Docker升级相关。
DNS的不稳定性
抓狂的是,这种故障并不稳定。比如,如果我一直pull hello-world的话,可能在数十次尝试后突然就可以了,然后又在几分钟后就又不行了……。一开始我以为是Docker升级了用户权限控制,因为中间有一段,在我登录了以后,就可以在desktop上流畅无比的pull。但是隔了两天,我没有登录的情况下,也能够在desktop(就是后面新安装的那个)流畅无比的pull……。
抓狂到最后,不可不拿出wireshar抓包分析。因为排查过程极度混乱,也没有留什么记录,还好讨论时捏了一张照片
其中框出的两部分,就是一次成功pull(上面),一次失败的pull(下面)。可以看出,失败的主要原因,就是对registry-1.dockers.io的dns查询失败了。虽然如上上面那张图所示,即使ping registry-1.docker.io确实能够看到IP的情况下,pull指令本身仍会执行失败。感觉好像就是pull命令会发出一次dns查询,失败了它就不干活一样。
这个DNS的问题,在单位的网络上就不会出现,在家里的网络上就会时不时出点问题。所以,我只好认为是电信宽带线路上某个地方的问题。也许撞墙了,也许就是指派给我这一片的DNS服务器有问题。只是我不知道这个为什么虚拟机上不行,宿主机上就没问题。
宿主机:
C:\Users\pig> nslookup registry-1.docker.io
服务器: UnKnown
Address: 2408:8000:1010:1::8
非权威应答:
名称: registry-1.docker.io
Addresses: 18.215.138.58
34.194.164.123
52.1.184.176虚拟机:
[root@pighost1 ~]# docker pull hello-world
Using default tag: latest
Error response from daemon: Get "https://registry-1.docker.io/v2/": dial tcp: lookup registry-1.docker.io on 192.168.21.2:53: no such host
[root@pighost1 ~]# nslookup registry-1.docker.io
Server: 192.168.21.2
Address: 192.168.21.2#53
Non-authoritative answer:
Name: registry-1.docker.io
Address: 52.1.184.176
Name: registry-1.docker.io
Address: 34.194.164.123
Name: registry-1.docker.io
Address: 18.215.138.58
[root@pighost1 ~]# nslookup registry-1.docker.io
Server: 192.168.21.2
Address: 192.168.21.2#53
Non-authoritative answer:
Name: registry-1.docker.io
Address: 52.1.184.176
而且在虚拟机上,使用nslookup,结果在短短几分钟之内就是不一样……
进一步,如下图,左边为虚拟机,右边为宿主机。主要的区别,就是右边在确定registry-1.docker.io的SOA服务器亚马逊route53解析服务后,宿主机查出了IP,然后进行下去了,虚拟机没有。很大的可能是虚拟机是IPv4,宿主机是IPv6……
网上对这一故障也有很多讨论,解决办法就是手工更改DNS服务,把google的DNS加到列表中去,包括8.8.8.8,8.8.4.4,另外还有著名的114.114.114.114。更改虚拟机里面的DNS后,pull大概率就可以成功了。
用魔法打败魔法…
当然因为后面我还得弄集群,并且我现在看着IPv6地址也头疼,就不尝试ipv6能不能解决这个问题了。但是改了DNS以后,docker pull是没有问题,但是在电信宽带的网上,容器内清华的镜像repo库又开始剧烈的不稳定了,甚至一些情况下压根就不通了。无奈之下,尝试使用代理穿透,在改DNS和魔法的双重加持下,pull和repo就都正常了。总之,故障似乎不在我能控制的范围内,一脸懵逼的情况下,还是尝试离线安装吧,又稳定又快。
毕竟,JAVA和Hadoop安装包的在线安装每试一次就会下载一次,速度也确实感人。
离线安装所需的rpm包可以参考我们之前的方法,使用yumdownloader下载,然后使用rpm -ivh命令去安装,就如#9步骤一样。
至于jdk11,需要登陆oracle去下载;hadoop,可以去hadoop的官方站下载。
2. 配置Hadoop
(1)Hadoop全局环境变量的设置
Dockerfile里最后的部分,就是设置与Hadoop相关的全局环境变量了。主要包括3部分:
- 设置HADOOP_HOME
在PATH中加入$HADOOP_HOME/bin 和 $HADOOP_HOME/sbin, 以下在#1中完成
HADOOP_HOME就是hadoop的安装地址,一开始我们把它解压到了/root/hadoop-3.3.5下面,然后把它改成了/root/hadoop;这个环境变量在后面大量的脚本中都会用到,所以设上为好
PATH变量中加入bin和sbin,是为了后面执行hdfs、yarn、mapred指令和start-dfs.sh、start-yarn.sh脚本的时候,不用费劲巴拉的敲完整地址。当然不设貌似也没啥问题。
最后,就是在容器里,这些变量需要在~/.bashrc中添加,也就是/root/.bashrc,容器启动时会自动载入;而不是在linux系统里设置全局变量一般,在/etc/profile中去设置,容器里似乎对这个文件不会source,设上也不会搭理。
- 设置JAVA_HOME
以下在#2中完成:
如同之前的记录中搭建hadoop集群所要做的一样,需要在$HADOOP_HOME/etc/hadoop下的hadoop-env.sh文件中,取消注释export JAVA_HOME哪一行,并且将其填为/usr,因为java在/usr/bin/java处。
-
增加HDFS和YARN的root用户
以下在#3、#4中完成:
hadoop默认使用hdfs作为用户,root并不是hadoop的用户。然而容器进去的时候基本就在root用户下,所以我们需要将root增加为hdfs和yarn的用户。否则,启动各类服务的时候,会被告知root不是对应的用户而拒绝启动。
(2) HADOOP配置文件
其实大致的配置和CENTOS上的网络安全工具(十二)走向Hadoop(4) Hadoop 集群搭建差不多,只是要根据swarm的特点做一点小小的改变——虽然这个小小的改变也是一个超级大坑。
不多说,先贴配置。
-
core-site.xml
fs.defaultFS
hdfs://pignode1:9000
hadoop.http.staticuser.user
root
hadoop.tmp.dir
/hadoopdata
-
hdfs-site.xml
dfs.replication
3
dfs.namenode.http-address
0.0.0.0:9870
dfs.namenode.secondary.http-address
pignode2:9890
-
yarn-site.xml
yarn.resourcemanager.hostname
pignode2
yarn.resourcemanager.webapp.address
0.0.0.0:8088
yarn.web-proxy.address
pignode2:8090
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.env-whitelist
JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME
- mapred-site.xml
mapreduce.framework.name
yarn
mapreduce.jobhistory.address
pignode3:10020
mapreduce.jobhistory.webapp.address
0.0.0.0:19888
mapreduce.application.classpath
$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*
对比之前的集群部署,这个唯一的区别就是,在所有需要规定WEB管理界面登录地址的地方,我们没有像之前那样填写hostname,而是填写了0.0.0.0:
这个原因就是大坑之二所在:
在我按照原来的配置启动容器后,无论如何也无法访问这几个曾经存在的管理界面,在各个节点上使用jps、netstat查看,明明进程和端口好好的存在,就是登不进去。一开始我怀疑是容器网络的问题——因为容器和宿主机并不位于一个网络上,swarm的容器内部,是要通过网桥docker_gwbridge回到宿主机的,这个完全又和docker_0不一样。而且,swarm内部网络更为复杂,内部网络地址一般在10.0.0.0/16上,并且启动一次stack变一次网段,比如上次是10.0.1.0/24,下次就是10.0.2.0/24,其网关又都在docker_gwbridge上,这货的地址是172.18.0.1……,然后宿主机又是我自己设的192.168.21.1/24,再外面才是真正的windows宿主机。
而且,由于之前的大坑之一,让我对当前的网络产生深深的不信任感,所以总以为是网络的问题——何况从宿主机也ping不同swarm容器。为了排除,我极不情愿的在宿主机上增加了去往10.0.0.0/24网段的路由:
[root@pighost1 Dockerfile-hadoop]# route add -net 10.0.0.0/16 gw 172.18.0.1 dev docker_gwbridge
[root@pighost1 Dockerfile-hadoop]#
这样,swarm容器内和宿主机就可以双向ping通了。此时,在宿主机上使用pignode1的内部ip地址,比如:
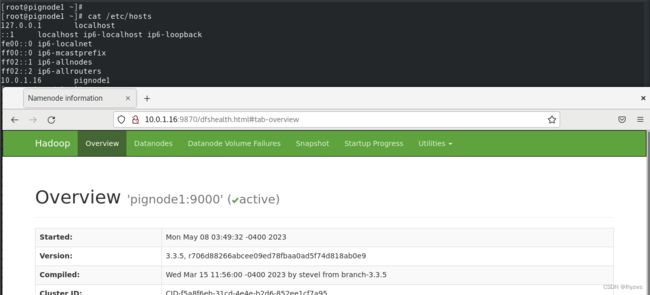
就可以看到久违的管理界面。总之,这样能证明hadoop应该是没有问题。但是使用pighost1:9870就是访问不到……
在之前配置clickhouse的时候,我也啥都没干,就照样顺畅的连上了clickhouse的服务器啊,唯一的区别,只不过是那次我用的是官方的镜像而已。 总不至于是我的Dockerfile或者docker-compse.yml又问题吧。在纠结了两天应该如何EXPOSE以及如何在宿主机的iptables下添加记录(明明防火墙都关了)以后,我突然想起来,在clickhouse的配置中,还有一样东西是在hadoop配置里没有做到的:CENTO OS上的网络安全工具(二十)ClickHouse swarm容器化集群部署
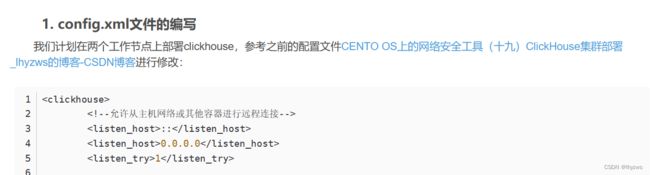
就是这个为了远程接入服务器设置的0.0.0.0地址。在hadoop中,是否需要对应设置呢?
不得不说有这样需求的人真是不多,在穷尽搜索之能事后,终于找了一两篇文章的只言片语让我突然反应过来,xml配置文件中的有些hostname其实是应该设置为0.0.0.0的……
于是就有了上面配置文件中的那些改动。改完后,pighost1:9870就可以用了:
3. 初始化启动脚本
初始化脚本如下,看注释就好。总之就是启动sshd,然后看是不是所有节点都启动成功了,启动成功了,就判断是否格式化,没有就先格了,然后依次start dfs,yarn和history server。
#! /bin/bash
# the NODE_COUNT param set by swarm config yml file, using endpoint_environment flag.
NODECOUNT=$NODE_COUNT
TRYLOOP=50
############################################################################################################
## 1. source一下环境变量,虽然docker也会在载入的时候source它,保险起见,自己也来一遍
############################################################################################################
source /etc/profile
source /root/.bashrc
############################################################################################################
## 2. 启动openssh服务
############################################################################################################
/sbin/sshd -D &
############################################################################################################
## 3. 定义后面初始化过程中要调用的函数
############################################################################################################
#FUNCTION:测试是否所有节点都已经启动的函数,避免在节点尚未全部启动时就执行format的尴尬----------------------------
#param1: 节点hostname的前缀(就是不包含尾巴后面数字的部分)
#param2: 节点数量
#param3: 在放弃前执行多少轮转圈ping节点的操作
isAllNodesConnected(){
PIGNODE_PRENAME=$1
PIGNODE_COUNT=$2
TRYLOOP_COUNT=$3
tryloop=0
ind=1
#init pignode hostname array,and pignode status array
while(( $ind <= $PIGNODE_COUNT ))
do
pignodes[$ind]="$PIGNODE_PRENAME$ind"
pignodes_stat[$ind]=0
let "ind++"
done
#check wether all the pignodes can be connected
noactivecount=$PIGNODE_COUNT
while(( $noactivecount > 0 ))
do
noactivecount=$PIGNODE_COUNT
ind=1
while(( $ind <= $PIGNODE_COUNT ))
do
if (( ${pignodes_stat[$ind]}==0 ))
then
ping -c 1 ${pignodes[$ind]} > /dev/null
if (($?==0))
then
pignodes_stat[$ind]=1
let "noactivecount-=1"
echo "Try to connect ${pignodes[$ind]}:successed." >>init.log
else
echo "Try to connect ${pignodes[$ind]}: failed." >>init.log
fi
else
let "noactivecount-=1"
fi
let "ind++"
done
if (( ${noactivecount}>0 ))
then
let "tryloop++"
if (($tryloop>$TRYLOOP_COUNT))
then
echo "ERROR Tried ${TRYLOOP_COUNT} loops. ${noactivecount} nodes failed, exit." >>init.log
break;
fi
echo "${noactivecount} left for ${PIGNODE_COUNT} nodes not connected, waiting for next try">>init.log
sleep 5
else
echo "All nodes are connected.">>init.log
fi
done
return $noactivecount
}
#----------------------------------------------------------------------------------------------------------
#FUNCTION:从core-site文件中获取所设置的hadoop dfs所在文件夹---------------------------------------------------
getDataDirectory(){
configfiledir=`echo "${HADOOP_HOME}/etc/hadoop/core-site.xml"`
datadir=`cat ${configfiledir} | grep -A 2 'hadoop.tmp.dir' | grep '' | sed 's/^[[:blank:]]*//g' | sed 's/<\/value>$//g'`
echo $datadir
}
############################################################################################################
## 4. 测试是否是主节点(hostname1),是则执行初始化操作 ##
############################################################################################################
nodehostname=`hostname`
nodehostnameprefix=`echo $nodehostname|sed -e 's|[[:digit:]]\+$||g'`
nodeindex=`hostname | sed "s/${nodehostnameprefix}//g"`
#切换到Hadoop安装目录
cd $HADOOP_HOME
#判断节点ID,主节点则执行初始化,否则等待即可
if (($nodeindex!=1));then
echo $nodehostname waiting for init...>>init.log
else
# 求yarn节点id(默认装在第2节点)和mapreduce节点id(默认装在第3节点)
if (($NODECOUNT>=2));then
yarnnodeid=2
else
yarnnodeid=1
fi
if (($NODECOUNT>=3));then
maprednodeid=3
else
maprednodeid=1
fi
# 测试是否所有节点都可以ping通
echo $nodehostname is one of the init manager nodes...>>init.log
#waiting for all the nodes connected
isAllNodesConnected $nodehostnameprefix $NODECOUNT $TRYLOOP
if (($?==0));then
#all the nodes is connected,from then to init hadoop
datadirectory=`echo $(getDataDirectory)`
#如果hadoop数据目录不为空,证明已经格式化,直接启动dfs,否则需执行格式化
if [ $datadirectory ];then
#check wether hadoop was formatted.
datadircontent=`ls -A ${datadirectory}`
if [ -z $datadircontent ];then
echo "format dfs">>init.log
bin/hdfs namenode -format >>init.log
else
echo "dfs is already formatted.">>init.log
fi
else
echo "ERROR:Can not get hadoop tmp data directory.init can not be done. ">>init.log
fi
#start-all.sh已经弃用,所以分别使用start-dfs.sh和start-yarn.sh启动
echo "Init dfs --------------------------------------------------------------------" >> init.log
sbin/start-dfs.sh
echo "Init yarn -------------------------------------------------------------------" >> init.log
ssh root@${nodehostnameprefix}${yarnnodeid} "bash ${HADOOP_HOME}/sbin/start-yarn.sh" >> init.log
# history server需要单独启动
echo "Init JobHistory server-------------------------------------------------------" >> init.log
ssh root@${nodehostnameprefix}${maprednodeid} "bash ${HADOOP_HOME}/bin/mapred --daemon start historyserver">>init.log
else
echo "ERROR:Not all the nodes is connected. init can not be done. exit...">>init.log
fi
fi
#挂住前台,防止swarn重启
tail -f /dev/null
哦,为了方便后面映射hadoop的dfs目录,以及每次测试完清空目录以免重复格式化,还需要一个小脚本来在宿主机上清空和创建目录,一并贴了:
#! /bin/bash
index=1
rm /hadoopdata/* -rf
while(($index<=12));do
file="/hadoopdata/${index}"
mkdir $file
let "index++"
done
4. swarm stack的配置文件
接下来是最大的一个坑了,先上docker-compse.yml:
version: "3.7"
services:
# 使用pignode1作为Hadoop的Nameode,开放9000端口
# 使用pignode1作为Hadoop的Namenode Http服务器,开放9870端口
pignode1:
image: pig/hadoop:cluster
deploy:
endpoint_mode: dnsrr
restart_policy:
condition: on-failure
placement:
constraints:
- node.hostname==pighost1
hostname: pignode1
environment:
- NODE_COUNT=12
networks:
- pig
ports:
- target: 22
published: 9011
protocol: tcp
mode: host
- target: 9000
published: 9000
protocol: tcp
mode: host
- target: 9870
published: 9870
protocol: tcp
mode: host
volumes:
# 映射xml配置文件
- ./config/core-site.xml:/root/hadoop/etc/hadoop/core-site.xml:r
- ./config/hdfs-site.xml:/root/hadoop/etc/hadoop/hdfs-site.xml:r
- ./config/yarn-site.xml:/root/hadoop/etc/hadoop/yarn-site.xml:r
- ./config/mapred-site.xml:/root/hadoop/etc/hadoop/mapred-site.xml:r
# 映射workers文件
- ./config/workers:/root/hadoop/etc/hadoop/workers:r
# 映射数据目录
- /hadoopdata/1:/hadoopdata:wr
pignode2:
image: pig/hadoop:cluster
deploy:
endpoint_mode: dnsrr
restart_policy:
condition: on-failure
placement:
# 将Second Namenode限制部署在第二个节点上
constraints:
- node.hostname==pighost2
networks:
- pig
hostname: pignode2
environment:
- NODE_COUNT=12
ports:
# 第二名字服务器接口
- target: 22
published: 9012
protocol: tcp
mode: host
- target: 9890
published: 9890
protocol: tcp
mode: host
- target: 8088
published: 8088
protocol: tcp
mode: host
volumes:
# 映射xml配置文件
- ./config/core-site.xml:/root/hadoop/etc/hadoop/core-site.xml:r
- ./config/hdfs-site.xml:/root/hadoop/etc/hadoop/hdfs-site.xml:r
- ./config/yarn-site.xml:/root/hadoop/etc/hadoop/yarn-site.xml:r
- ./config/mapred-site.xml:/root/hadoop/etc/hadoop/mapred-site.xml:r
# 映射workers文件
- ./config/workers:/root/hadoop/etc/hadoop/workers:r
# 映射数据目录
- /hadoopdata/2:/hadoopdata:wr
pignode3:
image: pig/hadoop:cluster
deploy:
endpoint_mode: dnsrr
restart_policy:
condition: on-failure
placement:
# 将Mapreduce限制部署在第三个节点上
constraints:
- node.hostname==pighost3
networks:
- pig
hostname: pignode3
environment:
- NODE_COUNT=12
ports:
- target: 22
published: 9013
protocol: tcp
mode: host
- target: 10020
published: 10020
protocol: tcp
mode: host
- target: 19888
published: 19888
protocol: tcp
mode: host
volumes:
# 映射xml配置文件
- ./config/core-site.xml:/root/hadoop/etc/hadoop/core-site.xml:r
- ./config/hdfs-site.xml:/root/hadoop/etc/hadoop/hdfs-site.xml:r
- ./config/yarn-site.xml:/root/hadoop/etc/hadoop/yarn-site.xml:r
- ./config/mapred-site.xml:/root/hadoop/etc/hadoop/mapred-site.xml:r
# 映射workers文件
- ./config/workers:/root/hadoop/etc/hadoop/workers:r
# 映射数据目录
- /hadoopdata/3:/hadoopdata:wr
#------------------------------------------------------------------------------------------------
#以下均为工作节点,可在除leader以外的主机上部署
pignode4:
image: pig/hadoop:cluster
deploy:
endpoint_mode: dnsrr
restart_policy:
condition: on-failure
placement:
# 将Mapreduce限制部署在第三个节点上
constraints:
# node.role==manager
# node.role==worker
- node.hostname==pighost3
networks:
- pig
environment:
- NODE_COUNT=12
ports:
- target: 22
published: 9014
protocol: tcp
mode: host
hostname: pignode4
volumes:
# 映射xml配置文件
- ./config/core-site.xml:/root/hadoop/etc/hadoop/core-site.xml:r
- ./config/hdfs-site.xml:/root/hadoop/etc/hadoop/hdfs-site.xml:r
- ./config/yarn-site.xml:/root/hadoop/etc/hadoop/yarn-site.xml:r
- ./config/mapred-site.xml:/root/hadoop/etc/hadoop/mapred-site.xml:r
# 映射workers文件
- ./config/workers:/root/hadoop/etc/hadoop/workers:r
# 映射数据目录
- /hadoopdata/4:/hadoopdata:wr
pignode5:
image: pig/hadoop:cluster
deploy:
endpoint_mode: dnsrr
restart_policy:
condition: on-failure
placement:
# 将Mapreduce限制部署在第三个节点上
constraints:
# node.role==manager
- node.hostname==pighost3
networks:
- pig
ports:
- target: 22
published: 9015
protocol: tcp
mode: host
hostname: pignode5
environment:
- NODE_COUNT=12
volumes:
# 映射xml配置文件
- ./config/core-site.xml:/root/hadoop/etc/hadoop/core-site.xml:r
- ./config/hdfs-site.xml:/root/hadoop/etc/hadoop/hdfs-site.xml:r
- ./config/yarn-site.xml:/root/hadoop/etc/hadoop/yarn-site.xml:r
- ./config/mapred-site.xml:/root/hadoop/etc/hadoop/mapred-site.xml:r
# 映射workers文件
- ./config/workers:/root/hadoop/etc/hadoop/workers:r
# 映射数据目录
- /hadoopdata/5:/hadoopdata:wr
pignode6:
image: pig/hadoop:cluster
deploy:
endpoint_mode: dnsrr
restart_policy:
condition: on-failure
placement:
# 将Mapreduce限制部署在第三个节点上
constraints:
# node.role==manager
- node.hostname==pighost3
networks:
- pig
ports:
- target: 22
published: 9016
protocol: tcp
mode: host
hostname: pignode6
environment:
- NODE_COUNT=12
volumes:
# 映射xml配置文件
- ./config/core-site.xml:/root/hadoop/etc/hadoop/core-site.xml:r
- ./config/hdfs-site.xml:/root/hadoop/etc/hadoop/hdfs-site.xml:r
- ./config/yarn-site.xml:/root/hadoop/etc/hadoop/yarn-site.xml:r
- ./config/mapred-site.xml:/root/hadoop/etc/hadoop/mapred-site.xml:r
# 映射workers文件
- ./config/workers:/root/hadoop/etc/hadoop/workers:r
# 映射数据目录
- /hadoopdata/6:/hadoopdata:wr
pignode7:
image: pig/hadoop:cluster
deploy:
endpoint_mode: dnsrr
restart_policy:
condition: on-failure
placement:
# 将Mapreduce限制部署在第三个节点上
constraints:
# node.role==manager
- node.hostname==pighost4
networks:
- pig
ports:
- target: 22
published: 9017
protocol: tcp
mode: host
hostname: pignode7
environment:
- NODE_COUNT=12
volumes:
# 映射xml配置文件
- ./config/core-site.xml:/root/hadoop/etc/hadoop/core-site.xml:r
- ./config/hdfs-site.xml:/root/hadoop/etc/hadoop/hdfs-site.xml:r
- ./config/yarn-site.xml:/root/hadoop/etc/hadoop/yarn-site.xml:r
- ./config/mapred-site.xml:/root/hadoop/etc/hadoop/mapred-site.xml:r
# 映射workers文件
- ./config/workers:/root/hadoop/etc/hadoop/workers:r
# 映射数据目录
- /hadoopdata/7:/hadoopdata:wr
pignode8:
image: pig/hadoop:cluster
deploy:
endpoint_mode: dnsrr
restart_policy:
condition: on-failure
placement:
# 将Mapreduce限制部署在第三个节点上
constraints:
# node.role==manager
- node.hostname==pighost4
networks:
- pig
ports:
- target: 22
published: 9018
protocol: tcp
mode: host
hostname: pignode8
environment:
- NODE_COUNT=12
volumes:
# 映射xml配置文件
- ./config/core-site.xml:/root/hadoop/etc/hadoop/core-site.xml:r
- ./config/hdfs-site.xml:/root/hadoop/etc/hadoop/hdfs-site.xml:r
- ./config/yarn-site.xml:/root/hadoop/etc/hadoop/yarn-site.xml:r
- ./config/mapred-site.xml:/root/hadoop/etc/hadoop/mapred-site.xml:r
# 映射workers文件
- ./config/workers:/root/hadoop/etc/hadoop/workers:r
# 映射数据目录
- /hadoopdata/8:/hadoopdata:wr
pignode9:
image: pig/hadoop:cluster
deploy:
endpoint_mode: dnsrr
restart_policy:
condition: on-failure
placement:
# 将Mapreduce限制部署在第三个节点上
constraints:
# node.role==manager
- node.hostname==pighost4
networks:
- pig
ports:
- target: 22
published: 9019
protocol: tcp
mode: host
hostname: pignode9
environment:
- NODE_COUNT=12
volumes:
# 映射xml配置文件
- ./config/core-site.xml:/root/hadoop/etc/hadoop/core-site.xml:r
- ./config/hdfs-site.xml:/root/hadoop/etc/hadoop/hdfs-site.xml:r
- ./config/yarn-site.xml:/root/hadoop/etc/hadoop/yarn-site.xml:r
- ./config/mapred-site.xml:/root/hadoop/etc/hadoop/mapred-site.xml:r
# 映射workers文件
- ./config/workers:/root/hadoop/etc/hadoop/workers:r
# 映射数据目录
- /hadoopdata/9:/hadoopdata:wr
pignode10:
image: pig/hadoop:cluster
deploy:
endpoint_mode: dnsrr
restart_policy:
condition: on-failure
placement:
# 将Mapreduce限制部署在第三个节点上
constraints:
# node.role==manager
- node.hostname==pighost5
networks:
- pig
ports:
- target: 22
published: 9020
protocol: tcp
mode: host
hostname: pignode10
environment:
- NODE_COUNT=12
volumes:
# 映射xml配置文件
- ./config/core-site.xml:/root/hadoop/etc/hadoop/core-site.xml:r
- ./config/hdfs-site.xml:/root/hadoop/etc/hadoop/hdfs-site.xml:r
- ./config/yarn-site.xml:/root/hadoop/etc/hadoop/yarn-site.xml:r
- ./config/mapred-site.xml:/root/hadoop/etc/hadoop/mapred-site.xml:r
# 映射workers文件
- ./config/workers:/root/hadoop/etc/hadoop/workers:r
# 映射数据目录
- /hadoopdata/10:/hadoopdata:wr
pignode11:
image: pig/hadoop:cluster
deploy:
endpoint_mode: dnsrr
restart_policy:
condition: on-failure
placement:
# 将Mapreduce限制部署在第三个节点上
constraints:
# node.role==manager
- node.hostname==pighost5
networks:
- pig
ports:
- target: 22
published: 9021
protocol: tcp
mode: host
hostname: pignode11
environment:
- NODE_COUNT=12
volumes:
# 映射xml配置文件
- ./config/core-site.xml:/root/hadoop/etc/hadoop/core-site.xml:r
- ./config/hdfs-site.xml:/root/hadoop/etc/hadoop/hdfs-site.xml:r
- ./config/yarn-site.xml:/root/hadoop/etc/hadoop/yarn-site.xml:r
- ./config/mapred-site.xml:/root/hadoop/etc/hadoop/mapred-site.xml:r
# 映射workers文件
- ./config/workers:/root/hadoop/etc/hadoop/workers:r
# 映射数据目录
- /hadoopdata/11:/hadoopdata:wr
pignode12:
image: pig/hadoop:cluster
deploy:
endpoint_mode: dnsrr
restart_policy:
condition: on-failure
placement:
# 将Mapreduce限制部署在第三个节点上
constraints:
# node.role==manager
- node.hostname==pighost5
networks:
- pig
ports:
- target: 22
published: 9022
protocol: tcp
mode: host
hostname: pignode12
environment:
- NODE_COUNT=12
volumes:
# 映射xml配置文件
- ./config/core-site.xml:/root/hadoop/etc/hadoop/core-site.xml:r
- ./config/hdfs-site.xml:/root/hadoop/etc/hadoop/hdfs-site.xml:r
- ./config/yarn-site.xml:/root/hadoop/etc/hadoop/yarn-site.xml:r
- ./config/mapred-site.xml:/root/hadoop/etc/hadoop/mapred-site.xml:r
# 映射workers文件
- ./config/workers:/root/hadoop/etc/hadoop/workers:r
# 映射数据目录
- /hadoopdata/12:/hadoopdata:wr
networks:
pig:
如果不说,没啥特别的地方。但是出问题的时候,在网上查,发现和我一样掉坑的兄弟也有,爬出来的不多……
按照原来的方式,直接使用9000:9000之类的端口映射,swarm默认采用vip形式来构建名字服务。所谓vip形式,就是swarm会帮助我们对每个节点/服务的hostname映射一个ip,然后启用自己的负载均衡来管理名字和ip的映射关系。
其实这段话在之前学习stack的配置方式时也看过,但是没觉着有什么需要特别注意的地方。直到这次遭遇到datanode节点随机只启动一半的问题……
排查了一个下午,才发现原因,是在某些datanode启动的时候,swarm名字服务给出了错误的namenode ip地址……犯罪现场是已经没有了,当时也百思不得其解,不过搞明白后还原现场的照片还在:
在不断的ping下,两个ip反复交替出现,所以马上让人联想到负载均衡问题。
所以最终问题才回到正轨上来——如果vip会被负载均衡的话,原来那个不太理解的dnsrr模式,应该就是需要“自行负载均衡”的简单ip轮询方式了。果不其然,在更改endpoint_mode为dnsrr模式后(当然对应导致端口映射的写法也要改),ip解析终于稳定了。datanode也能够赏心悦目地一次全部启动了。
三、 Hadoop HA集群部署
高可用有两种方式,一种是使用Quorun Journal node管理器(QJM)进行活跃名字服务器和待机名字服务器间编辑信息的同步,另一种是使用传统的NFS共享存储来帮助编辑信息同步。鉴于把NFS的高可用性建立在另一个NFS上的这种奇怪逻辑,这里毫不犹豫选择了QJM模式,希望是对的。
1. DFS部分配置
高可用模式网上配置教程很多,有些写得极为复杂,有的宣称简单到一把搞定,我都试了,感觉复杂未必,简单也不见得。所谓复杂未必,是说虽然配置项很多,但是配哪些如何配,官网说得比较清楚,一项项照配就行;所谓简单不见得,主要在于启动过程,不同的前提条件启动过程不太一样,虽然官网说得比较明白,但也有些步骤容易忽视,勤看log是个不错的爬坑习惯。
按照官网的说法,要配置QJM高可用集群,需要准备2类节点。一是Namenode服务器,2台以上,我们用了3台,所有这些名字服务器需要有相同的硬件配置;二是Journalnode服务器,其实一种轻载的进程,所以官网推荐和Namenode、JobTracker或者ResourceManager装在一起,且要求为大于3的奇数台,用以容忍(N-1)/2个节点失效。所以,我们干脆运行了3个管理节点,每节点用来承载一个namenode,一个Journalnode,一个resourcemanager及其它。
(1)core-site.xml
默认文件系统,由原先的pignode1:9000改成群组名,群族名在后面hdfs-site.xml中定义。
fs.defaultFS
hdfs://mycluster
(2)hdfs-site.xml
由于使用了名字服务器群组,所以在hdfs中需要更改的配置主要是定义名字服务器群组及其中的名字服务器。相关配置包括:
- dfs.nameservices
名字服务群组的逻辑名称(自己取个名字就行)
dfs.nameservices
mycluster
- dfs.ha.namenodes.[nameservice ID]
定义名字服务器群组中每个名字服务器的名称,比如mycluster群组中,包含nn1、nn2、nn3这3个名字服务器。注意这个nn1,nn2,nn3就是为名字服务器取的名字,不一定是名字服务器主机所在的名字。为免混淆,最好不一样。
dfs.ha.namenodes.mycluster
nn1,nn2, nn3
- dfs.namenode.rpc-address.[nameservice ID].[name node ID]
定义每个名字服务器需要监听RPC调用的地址和端口。因为定义了3个,所以要有3个property
dfs.namenode.rpc-address.mycluster.nn1
machine1.example.com:8020
dfs.namenode.rpc-address.mycluster.nn2
machine2.example.com:8020
dfs.namenode.rpc-address.mycluster.nn3
machine3.example.com:8020
- dfs.namenode.http-address.[nameservice ID].[name node ID]
定义名字服务器监听的WEB服务的地址和端口号。就是最后我们经常用的WEB管理页面的地址。也可以设置为https的,为免麻烦,直接http了。
dfs.namenode.http-address.mycluster.nn1
machine1.example.com:9870
dfs.namenode.http-address.mycluster.nn2
machine2.example.com:9870
dfs.namenode.http-address.mycluster.nn3
machine3.example.com:9870
到此,和名字服务器相关的配置基本就搞定了。上文说了,还要准备Journalnode服务器,相关配置也要配好:
- dfs.namenode.shared.edits.dir
该属性定义了所有的Journalnode服务器和监听端口,名字服务器用这个地址来同步编辑信息
dfs.namenode.shared.edits.dir
qjournal://node1.example.com:8485;node2.example.com:8485;node3.example.com:8485/mycluster
然后就是配置故障迁移相关的脚本:
- dfs.client.failover.proxy.provider.[nameservice ID]
定义HDFS客户端用来确定活跃名字服务器的Java class,也就是客户端用这个来确定应该和哪个名字服务器通信。这里只有nameserviceID需要改一下,改成我们自己取的那个名字。
dfs.client.failover.proxy.provider.mycluster
org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider
- dfs.ha.fencing.methods
一组java class或脚本的列表,用于在故障迁移期间用于锁定活跃的名字服务器。比如sshfence,使用ssh链接到活跃的名字服务器并kill进程。所以被杀节点上应该有发起节点的公钥和authkey文件,发起节点的私钥存储位置如下定义。
dfs.ha.fencing.methods
sshfence
dfs.ha.fencing.ssh.private-key-files
/home/exampleuser/.ssh/id_rsa
- dfs.journalnode.edits.dir
配置Journalnode用于存储编辑信息的本地目录,应该是一个绝对路径。在容器中最好映射到宿主机。
dfs.journalnode.edits.dir
/path/to/journal/node/local/data
2. Zookeeper部分配置
hadoop建议部署3个以上,同样最好是奇数个的zookeeper节点,并且在启动hadoop前验证zookeeper节点是否正常工作。
这个可以通过在每个zookeeper节点上运行zkServer.sh status来查看,进一步可使用zkCli.sh -ls /来查看目录,判断是否工作正常。
zookeeper相关的配置一共2个,一个涉及名字服务器的同步和故障迁移,在core-site.xml中;一个涉及reoursemanager的同步和迁移,在yarn-site.xml中,后面会涉及,此处不赘述。
3. 配置自动故障迁移
涉及自动故障迁移的主要有两个配置项,分别在两个不同的配置文件中:
(1)core-site.xml
配置用于自动切换的zookeeper节点及端口
ha.zookeeper.quorum
zk1.example.com:2181,zk2.example.com:2181,zk3.example.com:2181
(2)hdfs-site.xml
指示集群自动故障切换
dfs.ha.automatic-failover.enabled
true
4. 启动dfs
前面说过,说复杂不复杂,说简单不简单。关键在于两点,一点就是上面的配置不要敲错了——这个确实很难检查,很坑;二呢,就是下面的启动步骤,不要颠倒了。之所以如此怪异和复杂,主要还是和服务器间初始化时的同步相关,一旦格式化、初始化都搞定了,后续还是可以通过start-dfs.sh脚本一键启动的。
(1)启动所有Journalnode
在所有的3个名字服务器上,执行:hdfs --daemon start journalnode
[root@pignode1 ~]# hdfs --daemon start journalnode
WARNING: /root/hadoop/logs does not exist. Creating.
[root@pignode1 ~]# jps
75 JournalNode
123 Jps
[root@pignode1 ~]#
[root@pignode2 ~]# hdfs --daemon start journalnode
WARNING: /root/hadoop/logs does not exist. Creating.
[root@pignode2 ~]# jps
75 JournalNode
123 Jps
[root@pignode3 ~]# hdfs --daemon start journalnode
WARNING: /root/hadoop/logs does not exist. Creating.
[root@pignode3 ~]# jps
75 JournalNode
123 Jps
(2)namenode格式化
这里只介绍安装完全新鲜的HA集群的做法,升级HA或者迁移数据什么的,请参考官网描述Apache Hadoop 3.3.5 – HDFS High Availability Using the Quorum Journal Manager
在其中一个名字服务器节点上,进行格式化,比如pignode1: hdfs namenode -format
[root@pignode1 ~]# hdfs namenode -format
2023-05-11 09:39:06,842 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
……………
……………
2023-05-11 09:39:09,145 INFO namenode.FSImage: Allocated new BlockPoolId: BP-1327835470-10.0.30.18-1683797949145
2023-05-11 09:39:09,159 INFO common.Storage: Storage directory /hadoopdata/hdfs_name has been successfully formatted.
2023-05-11 09:39:09,320 INFO namenode.FSImageFormatProtobuf: Saving image file /hadoopdata/hdfs_name/current/fsimage.ckpt_0000000000000000000 using no compression
2023-05-11 09:39:09,403 INFO namenode.FSImageFormatProtobuf: Image file /hadoopdata/hdfs_name/current/fsimage.ckpt_0000000000000000000 of size 396 bytes saved in 0 seconds .
2023-05-11 09:39:09,409 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0
2023-05-11 09:39:09,456 INFO namenode.FSNamesystem: Stopping services started for active state
2023-05-11 09:39:09,457 INFO namenode.FSNamesystem: Stopping services started for standby state
2023-05-11 09:39:09,466 INFO namenode.FSImage: FSImageSaver clean checkpoint: txid=0 when meet shutdown.
2023-05-11 09:39:09,467 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at pignode1/10.0.30.18
************************************************************/
[root@pignode1 ~]#
启动该名字服务器 ,否则后面在其它服务器上同步元数据会因为连不上服务器而失败
[root@pignode1 ~]# hdfs --daemon start namenode
[root@pignode1 ~]# jps
259 NameNode
341 Jps
75 JournalNode
在其它名字服务器节点上,执行:hdfs namenode -bootstrapStandby,以确保将已格式化节点的元数据通过Journalnode同步到没有格式化的名字服务器上。这也就是为什么必须首先启动journalnode的原因。
[root@pignode2 ~]# hdfs namenode -bootstrapStandby
2023-05-11 09:43:54,097 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = pignode2/10.0.30.21
STARTUP_MSG: args = [-bootstrapStandby]
STARTUP_MSG: version = 3.3.5
…………
…………
2023-05-11 09:58:32,730 INFO common.Util: Assuming 'file' scheme for path /hadoopdata/hdfs_name in configuration.
2023-05-11 09:58:32,730 INFO common.Util: Assuming 'file' scheme for path /hadoopdata/hdfs_name in configuration.
=====================================================
About to bootstrap Standby ID pignamenode2 from:
Nameservice ID: pignamenodecluster
Other Namenode ID: pignamenode1
Other NN's HTTP address: http://pignode1:9870
Other NN's IPC address: pignode1/10.0.31.21:8020
Namespace ID: 1898329509
Block pool ID: BP-1342056252-10.0.31.21-1683799022316
Cluster ID: CID-ddaf258a-47c4-4dde-b681-2c9c70872ef1
Layout version: -66
isUpgradeFinalized: true
=====================================================
2023-05-11 09:58:33,140 INFO common.Storage: Storage directory /hadoopdata/hdfs_name has been successfully formatted.
2023-05-11 09:58:33,171 INFO common.Util: Assuming 'file' scheme for path /hadoopdata/hdfs_name in configuration.
2023-05-11 09:58:33,172 INFO common.Util: Assuming 'file' scheme for path /hadoopdata/hdfs_name in configuration.
2023-05-11 09:58:33,200 INFO namenode.FSEditLog: Edit logging is async:true
2023-05-11 09:58:33,300 INFO namenode.TransferFsImage: Opening connection to http://pignode1:9870/imagetransfer?getimage=1&txid=0&storageInfo=-66:1898329509:1683799022316:CID-ddaf258a-47c4-4dde-b681-2c9c70872ef1&bootstrapstandby=true
2023-05-11 09:58:33,436 INFO common.Util: Combined time for file download and fsync to all disks took 0.00s. The file download took 0.00s at 0.00 KB/s. Synchronous (fsync) write to disk of /hadoopdata/hdfs_name/current/fsimage.ckpt_0000000000000000000 took 0.00s.
2023-05-11 09:58:33,437 INFO namenode.TransferFsImage: Downloaded file fsimage.ckpt_0000000000000000000 size 399 bytes.
2023-05-11 09:58:33,443 INFO ha.BootstrapStandby: Skipping InMemoryAliasMap bootstrap as it was not configured
2023-05-11 09:58:33,456 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at pignode2/10.0.31.12
************************************************************/
同步完了也启动:
[root@pignode2 ~]# hdfs --daemon start namenode
[root@pignode2 ~]# jps
75 JournalNode
251 NameNode
332 Jps
第3个节点照抄:
[root@pignode3 ~]# hdfs namenode -bootstrapStandby
2023-05-11 09:46:55,393 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = pignode3/10.0.30.6
STARTUP_MSG: args = [-bootstrapStandby]
STARTUP_MSG: version = 3.3.5
…………
…………
2023-05-11 10:02:24,114 INFO common.Util: Assuming 'file' scheme for path /hadoopdata/hdfs_name in configuration.
=====================================================
About to bootstrap Standby ID pignamenode3 from:
Nameservice ID: pignamenodecluster
Other Namenode ID: pignamenode1
Other NN's HTTP address: http://pignode1:9870
Other NN's IPC address: pignode1/10.0.31.21:8020
Namespace ID: 1898329509
Block pool ID: BP-1342056252-10.0.31.21-1683799022316
Cluster ID: CID-ddaf258a-47c4-4dde-b681-2c9c70872ef1
Layout version: -66
isUpgradeFinalized: true
=====================================================
2023-05-11 10:02:24,409 INFO common.Storage: Storage directory /hadoopdata/hdfs_name has been successfully formatted.
2023-05-11 10:02:24,420 INFO common.Util: Assuming 'file' scheme for path /hadoopdata/hdfs_name in configuration.
2023-05-11 10:02:24,421 INFO common.Util: Assuming 'file' scheme for path /hadoopdata/hdfs_name in configuration.
2023-05-11 10:02:24,450 INFO namenode.FSEditLog: Edit logging is async:true
2023-05-11 10:02:24,542 INFO namenode.TransferFsImage: Opening connection to http://pignode1:9870/imagetransfer?getimage=1&txid=0&storageInfo=-66:1898329509:1683799022316:CID-ddaf258a-47c4-4dde-b681-2c9c70872ef1&bootstrapstandby=true
2023-05-11 10:02:24,567 INFO common.Util: Combined time for file download and fsync to all disks took 0.00s. The file download took 0.00s at 0.00 KB/s. Synchronous (fsync) write to disk of /hadoopdata/hdfs_name/current/fsimage.ckpt_0000000000000000000 took 0.00s.
2023-05-11 10:02:24,568 INFO namenode.TransferFsImage: Downloaded file fsimage.ckpt_0000000000000000000 size 399 bytes.
2023-05-11 10:02:24,574 INFO ha.BootstrapStandby: Skipping InMemoryAliasMap bootstrap as it was not configured
2023-05-11 10:02:24,590 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at pignode3/10.0.31.18
************************************************************/
启动:
[root@pignode3 ~]# hdfs --daemon start namenode
[root@pignode3 ~]# jps
249 NameNode
330 Jps
75 JournalNode
(3)检查名字服务器状态
在这里,就可以检查名字服务器的状态了,随便找个名字服务器查看一下,状态都是standby,这很正常,因为启动尚未完成,同志们还需努力。
[root@pignode3 ~]# hdfs haadmin -getAllServiceState
pignode1:8020 standby
pignode2:8020 standby
pignode3:8020 standby (4)初始化Zookeeper目录
从一个名字服务器节点执行:hdfs zkfc -formatZK
[root@pignode1 ~]# hdfs zkfc -formatZK
2023-05-11 10:06:06,802 INFO tools.DFSZKFailoverController: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting DFSZKFailoverController
STARTUP_MSG: host = pignode1/10.0.31.21
STARTUP_MSG: args = [-formatZK]
STARTUP_MSG: version = 3.3.5
…………
…………
2023-05-11 10:06:07,564 INFO ha.ActiveStandbyElector: Session connected.
2023-05-11 10:06:07,618 INFO ha.ActiveStandbyElector: Successfully created /hadoop-ha/pignamenodecluster in ZK.
2023-05-11 10:06:07,731 INFO zookeeper.ZooKeeper: Session: 0x300052118910000 closed
2023-05-11 10:06:07,731 WARN ha.ActiveStandbyElector: Ignoring stale result from old client with sessionId 0x300052118910000
2023-05-11 10:06:07,732 INFO zookeeper.ClientCnxn: EventThread shut down for session: 0x300052118910000
2023-05-11 10:06:07,736 INFO tools.DFSZKFailoverController: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down DFSZKFailoverController at pignode1/10.0.31.21
************************************************************/
(5)启动ZKFC(Zookeeper failover Controller)
按照官网的说法,从这里可以开始start-dfs.sh了;当然也可以手工 hdfs --daemon start zkfc
但是3个zkfc手工搞问题还不大,9个datanode就比较难受了,所以还是偷个懒:
[root@pignode1 hadoop]# sbin/start-dfs.sh
Starting namenodes on [pignode1 pignode2 pignode3]
Last login: Thu May 11 10:05:49 UTC 2023 from 192.168.21.11 on pts/0
pignode1: Warning: Permanently added 'pignode1,10.0.31.21' (ECDSA) to the list of known hosts.
pignode2: Warning: Permanently added 'pignode2,10.0.31.12' (ECDSA) to the list of known hosts.
pignode3: Warning: Permanently added 'pignode3,10.0.31.18' (ECDSA) to the list of known hosts.
pignode1: namenode is running as process 259. Stop it first and ensure /tmp/hadoop-root-namenode.pid file is empty before retry.
pignode2: namenode is running as process 251. Stop it first and ensure /tmp/hadoop-root-namenode.pid file is empty before retry.
pignode3: namenode is running as process 249. Stop it first and ensure /tmp/hadoop-root-namenode.pid file is empty before retry.
Starting datanodes
Last login: Thu May 11 10:07:40 UTC 2023 on pts/0
pignode5: Warning: Permanently added 'pignode5,10.0.31.2' (ECDSA) to the list of known hosts.
pignode4: Warning: Permanently added 'pignode4,10.0.31.14' (ECDSA) to the list of known hosts.
pignode6: Warning: Permanently added 'pignode6,10.0.31.16' (ECDSA) to the list of known hosts.
pignode9: Warning: Permanently added 'pignode9,10.0.31.8' (ECDSA) to the list of known hosts.
pignode11: Warning: Permanently added 'pignode11,10.0.31.15' (ECDSA) to the list of known hosts.
pignode7: Warning: Permanently added 'pignode7,10.0.31.20' (ECDSA) to the list of known hosts.
pignode10: Warning: Permanently added 'pignode10,10.0.31.19' (ECDSA) to the list of known hosts.
pignode8: Warning: Permanently added 'pignode8,10.0.31.6' (ECDSA) to the list of known hosts.
pignode12: Warning: Permanently added 'pignode12,10.0.31.4' (ECDSA) to the list of known hosts.
pignode4: WARNING: /root/hadoop/logs does not exist. Creating.
pignode5: WARNING: /root/hadoop/logs does not exist. Creating.
pignode6: WARNING: /root/hadoop/logs does not exist. Creating.
pignode7: WARNING: /root/hadoop/logs does not exist. Creating.
pignode9: WARNING: /root/hadoop/logs does not exist. Creating.
pignode8: WARNING: /root/hadoop/logs does not exist. Creating.
pignode10: WARNING: /root/hadoop/logs does not exist. Creating.
pignode11: WARNING: /root/hadoop/logs does not exist. Creating.
pignode12: WARNING: /root/hadoop/logs does not exist. Creating.
Starting journal nodes [pignode3 pignode2 pignode1]
Last login: Thu May 11 10:07:40 UTC 2023 on pts/0
pignode1: Warning: Permanently added 'pignode1,10.0.31.21' (ECDSA) to the list of known hosts.
pignode2: Warning: Permanently added 'pignode2,10.0.31.12' (ECDSA) to the list of known hosts.
pignode3: Warning: Permanently added 'pignode3,10.0.31.18' (ECDSA) to the list of known hosts.
pignode2: journalnode is running as process 75. Stop it first and ensure /tmp/hadoop-root-journalnode.pid file is empty before retry.
pignode1: journalnode is running as process 74. Stop it first and ensure /tmp/hadoop-root-journalnode.pid file is empty before retry.
pignode3: journalnode is running as process 75. Stop it first and ensure /tmp/hadoop-root-journalnode.pid file is empty before retry.
Starting ZK Failover Controllers on NN hosts [pignode1 pignode2 pignode3]
Last login: Thu May 11 10:07:47 UTC 2023 on pts/0
pignode1: Warning: Permanently added 'pignode1,10.0.31.21' (ECDSA) to the list of known hosts.
pignode2: Warning: Permanently added 'pignode2,10.0.31.12' (ECDSA) to the list of known hosts.
pignode3: Warning: Permanently added 'pignode3,10.0.31.18' (ECDSA) to the list of known hosts.
[root@pignode1 hadoop]#
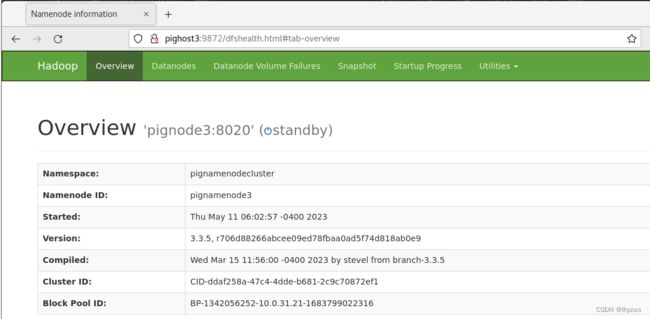
启动完了再看,一个服务器已经上线了:
[root@pignode1 hadoop]# hdfs haadmin -getAllServiceState
pignode1:8020 active
pignode2:8020 standby
pignode3:8020 standby
然后使用WEB管理器看看成果: 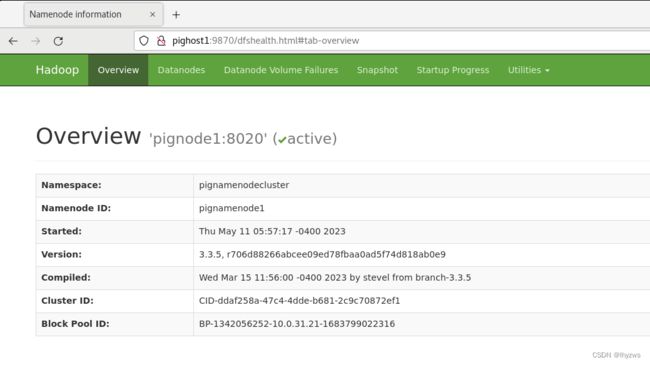
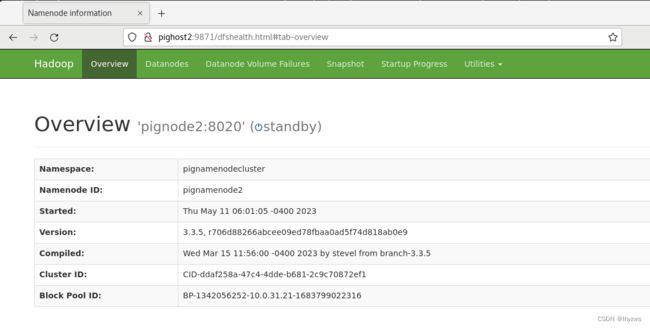
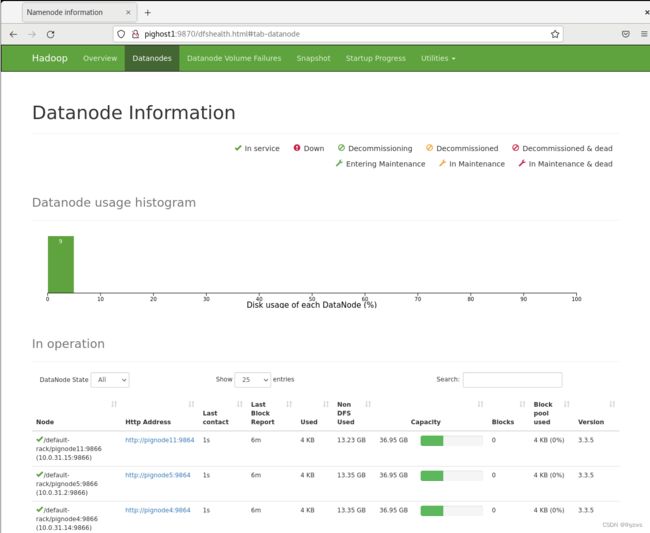
脚本的好处,是Datanode也都起来了:
5. 配置Yarn
参考Apache Hadoop 3.3.5 – ResourceManager High Availability进行Yarn的高可靠配置,涉及的主要参数包括:
(1)打开HA选项
- yarn.resourcemanager.ha.enabled
打开resourcemanager的高可靠开关
yarn.resourcemanager.ha.enabled
true
(2)定义HA resource manager集群
- yarn.resourcemanager.cluster-id
定义resourcemanager的集群id,也就是自己取一个,而且目前看再别的什么地儿也没用上
- yarn.resourcemanager.ha.rm-ids
定义resoucemanager集群的内部成员名称
yarn.resourcemanager.hostname.rm-id
定义每个resourcemanager部署的节点
yarn.resourcemanager.webapp.address.rm-id
定义每个resourcemanager的WEB管理页面的端口
yarn.resourcemanager.cluster-id
pignode-ha
yarn.resourcemanager.ha.rm-ids
pigresourcemanager1,pigresourcemanager2,pigresourcemanager3
yarn.resourcemanager.hostname.pigresourcemanager1
pignode1
……
yarn.resourcemanager.webapp.address.pigresourcemanager1
0.0.0.0:8088
……
(3)指定zookeeper
- hadoop.zk.address
官方给出的是hadoop.zk.address,但很多网上文章给出的是yarn.resourcemanaget.zk-address,估计是版本问题。whatever,能用就行。
yarn.resourcemanager.zk-address
zookeeper1:2181,zookeeper2:2181,zookeeper3:2181
6. 启动Yarn
yarn可以直接使用start-yarn.sh脚本启动。使用yarn rmadmin -getAllServiceState可以查看resourcemanager的状态。
[root@pignode1 hadoop]# sbin/start-yarn.sh
Starting resourcemanagers on [ pignode1 pignode2]
Last login: Thu May 11 10:07:50 UTC 2023 on pts/0
pignode2: Warning: Permanently added 'pignode2,10.0.31.22' (ECDSA) to the list of known hosts.
pignode1: Warning: Permanently added 'pignode1,10.0.31.21' (ECDSA) to the list of known hosts.
pignode2: WARNING: /root/hadoop/logs does not exist. Creating.
Starting nodemanagers
Last login: Thu May 11 13:32:28 UTC 2023 on pts/0
pignode6: Warning: Permanently added 'pignode6,10.0.31.27' (ECDSA) to the list of known hosts.
pignode11: Warning: Permanently added 'pignode11,10.0.31.31' (ECDSA) to the list of known hosts.
pignode4: Warning: Permanently added 'pignode4,10.0.31.25' (ECDSA) to the list of known hosts.
pignode8: Warning: Permanently added 'pignode8,10.0.31.6' (ECDSA) to the list of known hosts.
pignode7: Warning: Permanently added 'pignode7,10.0.31.20' (ECDSA) to the list of known hosts.
pignode9: Warning: Permanently added 'pignode9,10.0.31.8' (ECDSA) to the list of known hosts.
pignode12: Warning: Permanently added 'pignode12,10.0.31.30' (ECDSA) to the list of known hosts.
pignode5: Warning: Permanently added 'pignode5,10.0.31.28' (ECDSA) to the list of known hosts.
pignode10: Warning: Permanently added 'pignode10,10.0.31.29' (ECDSA) to the list of known hosts.
pignode6: WARNING: /root/hadoop/logs does not exist. Creating.
pignode11: WARNING: /root/hadoop/logs does not exist. Creating.
pignode4: WARNING: /root/hadoop/logs does not exist. Creating.
pignode12: WARNING: /root/hadoop/logs does not exist. Creating.
pignode5: WARNING: /root/hadoop/logs does not exist. Creating.
pignode10: WARNING: /root/hadoop/logs does not exist. Creating.
Last login: Thu May 11 13:32:30 UTC 2023 on pts/0
pignode3: Warning: Permanently added 'pignode3,10.0.31.24' (ECDSA) to the list of known hosts.
pignode3: WARNING: /root/hadoop/logs does not exist. Creating.
[root@pignode1 hadoop]#
启动后可以通过 yarn rmadmin命令查看resourcemanager的情况:
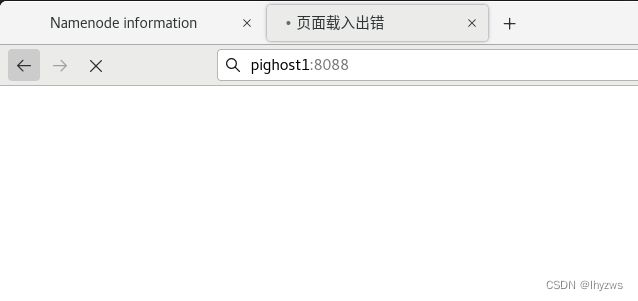
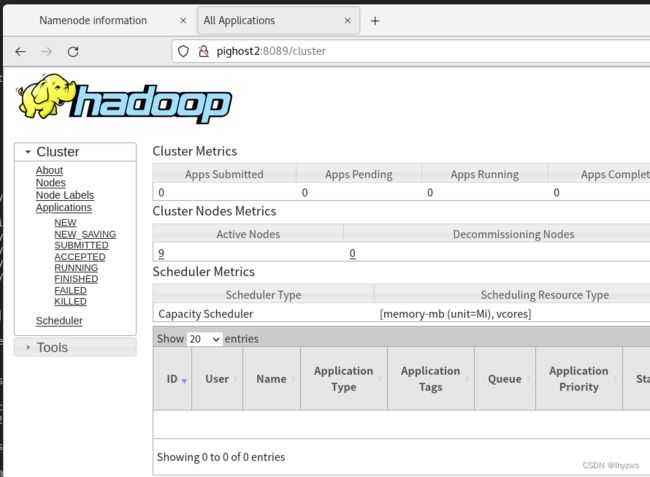
[root@pignode1 hadoop]# yarn rmadmin -getAllServiceState
pignode1:8033 standby
pignode2:8033 active
pignode3:8033 standby
和namenode不太一样的是,如果是不活跃的resourcemanager,似乎就无法访问管理页面:
但是活跃的rm,是可以访问的
7. 启动MapReduce
MapReduce和非HA模式下配置、启动方式均一样,不赘述。
四、Swarm上的Hadoop HA部署
不多说了,前文已经很罗嗦,这里直接贴。
1. 配置文件
(1)core-site.xml
fs.defaultFS
hdfs://pignamenodecluster
ha.zookeeper.quorum
zookeeper1:2181,zookeeper2:2181,zookeeper3:2181
hadoop.http.staticuser.user
root
hadoop.tmp.dir
/hadoopdata/data
~ (2)hdfs-site.xml
dfs.nameservices
pignamenodecluster
dfs.ha.namenodes.pignamenodecluster
pignamenode1,pignamenode2,pignamenode3
dfs.replication
3
dfs.namenode.name.dir
/hadoopdata/hdfs_name
dfs.datanode.data.dir
/hadoopdata/hdfs_data
dfs.webhdfs.enabled
true
dfs.namenode.rpc-address.pignamenodecluster.pignamenode1
pignode1:8020
dfs.namenode.rpc-address.pignamenodecluster.pignamenode2
pignode2:8020
dfs.namenode.rpc-address.pignamenodecluster.pignamenode3
pignode3:8020
dfs.namenode.http-address.pignamenodecluster.pignamenode1
0.0.0.0:9870
dfs.namenode.http-address.pignamenodecluster.pignamenode2
0.0.0.0:9870
dfs.namenode.http-address.pignamenodecluster.pignamenode3
0.0.0.0:9870
dfs.namenode.shared.edits.dir
qjournal://pignode1:8485;pignode2:8485;pignode3:8485/pignamenodecluster
dfs.journalnode.edits.dir
/hadoopdata/journal
dfs.ha.fencing.methods
sshfence
dfs.ha.fencing.ssh.private-key-files
/root/.ssh/id_rsa
dfs.ha.automatic-failover.enabled
true
dfs.client.failover.proxy.provider.pignamenodecluster
org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider
(3)yarn-site.xml
yarn.resourcemanager.ha.enabled
true
yarn.resourcemanager.recovery.enabled
true
yarn.resourcemanager.cluster-id
pignode-ha
yarn.resourcemanager.ha.rm-ids
pigresourcemanager1,pigresourcemanager2,pigresourcemanager3
yarn.resourcemanager.hostname.pigresourcemanager1
pignode1
yarn.resourcemanager.hostname.pigresourcemanager2
pignode2
yarn.resourcemanager.hostname.pigresourcemanager3
pignode3
yarn.resourcemanager.webapp.address.pigresourcemanager1
0.0.0.0:8088
yarn.resourcemanager.webapp.address.pigresourcemanager2
0.0.0.0:8088
yarn.resourcemanager.webapp.address.pigresourcemanager3
0.0.0.0:8088
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.env-whitelist
JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME
yarn.resourcemanager.stored.class
org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore
yarn.resourcemanager.zk-address
zookeeper1:2181,zookeeper2:2181,zookeeper3:2181
(4)mapred-site.xml
mapreduce.framework.name
yarn
mapreduce.jobhistory.address
pignode3:10020
mapreduce.jobhistory.webapp.address
0.0.0.0:19888
mapreduce.application.classpath
$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*
2. 启动初始化脚本
(1)宿主机映射文件系统清理及构建脚本
主要功能,就是清理宿主机上映射的hadoop、zookeeper目录,防止因为反复格式化等操作,在试验过程中出现莫名其妙的错误。
#! /bin/bash
index=1
rm /hadoopdata/* -rf
while(($index<=12));do
file="/hadoopdata/${index}"
mkdir $file
mkdir ${file}/data
mkdir ${file}/hdfs_name
mkdir ${file}/hdfs_data
mkdir ${file}/journal
let "index++"
done
index=1
while(($index<=3));do
file="/hadoopdata/zoo/${index}"
mkdir ${file}/data -p
mkdir ${file}/datalog -p
mkdir ${file}/logs -p
let "index++"
done
(2)容器内Hadoop初始化脚本
初始化脚本贴在这里完全是给我自己看的,因为一些参数我没有做得很灵活。而且,仅仅只考虑了没有格式化和已经格式化2种情况下,所有节点启动的情况……也就是swarm启动的情况,没有考虑单个节点失效重启情况下如何启动,仅仅是在等待5分钟后执行start-dfs.sh和start-yarn.sh脚本,由脚本帮助判断是否需要启动进程。总之应付当前需求是够了。
#! /bin/bash
# the NODE_COUNT param set by swarm config yml file, using endpoint_environment flag.
NODECOUNT=$NODE_COUNT
TRYLOOP=50
ZOOKEEPERNODECOUNT=$ZOOKEEPER_COUNT
############################################################################################################
## 1. get enviorenment param
############################################################################################################
source /etc/profile
source /root/.bashrc
############################################################################################################
## 2. for every node, init sshd service
############################################################################################################
/sbin/sshd -D &
############################################################################################################
## 3. define functions
############################################################################################################
#FUNCTION:to test all the nodes can be connected------------------------------------------------------------
#param1: node's hostname prefix
#param2: node count
#param3: how many times the manager node try connect
isAllNodesConnected(){
PIGNODE_PRENAME=$1
PIGNODE_COUNT=$2
TRYLOOP_COUNT=$3
tryloop=0
ind=1
#init pignode hostname array,and pignode status array
while(( $ind <= $PIGNODE_COUNT ))
do
pignodes[$ind]="$PIGNODE_PRENAME$ind"
pignodes_stat[$ind]=0
let "ind++"
done
#check wether all the pignodes can be connected
noactivecount=$PIGNODE_COUNT
while(( $noactivecount > 0 ))
do
noactivecount=$PIGNODE_COUNT
ind=1
while(( $ind <= $PIGNODE_COUNT ))
do
if (( ${pignodes_stat[$ind]}==0 ))
then
ping -c 1 ${pignodes[$ind]} > /dev/null
if (($?==0))
then
pignodes_stat[$ind]=1
let "noactivecount-=1"
echo "Try to connect ${pignodes[$ind]}:successed." >>init.log
else
echo "Try to connect ${pignodes[$ind]}: failed." >>init.log
fi
else
let "noactivecount-=1"
fi
let "ind++"
done
if (( ${noactivecount}>0 ))
then
let "tryloop++"
if (($tryloop>$TRYLOOP_COUNT))
then
echo "ERROR Tried ${TRYLOOP_COUNT} loops. ${noactivecount} nodes failed, exit." >>init.log
break;
fi
echo "${noactivecount} left for ${PIGNODE_COUNT} nodes not connected, waiting for next try">>init.log
sleep 5
else
echo "All nodes are connected.">>init.log
fi
done
return $noactivecount
}
#----------------------------------------------------------------------------------------------------------
#FUNCTION:get the hadoop data directory--------------------------------------------------------------------
getDataDirectory(){
#when use tmp data directory
# configfiledir=`echo "${HADOOP_HOME}/etc/hadoop/core-site.xml"`
# datadir=`cat ${configfiledir} | grep -A 2 'hadoop.tmp.dir' | grep '' | sed 's/^[[:blank:]]*//g' | sed 's/<\/value>$//g'`
# echo $datadir
#when use namenode.name.dir direcotry
datadir=`cat ${HADOOP_HOME}/etc/hadoop/hdfs-site.xml|grep -A 2 "dfs.namenode.name.dir"|grep ""|sed -e "s///g"|sed -e "s/<\/value>//g"`
echo $datadir
}
#---------------------------------------------------------------------------------------------------------
#FUNCTION:init hadoop while dfs not formatted.------------------------------------------------------------
initHadoop_format(){
#init journalnode
echo 'start all Journalnode' >> init.log
journallist=`cat $HADOOP_HOME/etc/hadoop/hdfs-site.xml |grep -A 2 'dfs.namenode.shared.edits.dir'|grep ''|sed -e "s/qjournal:\/\/\(.*\)\/.*<\/value>/\1/g"|sed "s/;/ /g"|sed -e "s/:[[:digit:]]\{2,5\}/ /g"`
for journalnode in $journallist;do
ssh root@${journalnode} "hdfs --daemon start journalnode"
done
#format and start the main namenode
echo 'format and start namenode 1'>>init.log
hdfs namenode -format
if (( $?!=0 )); then
exit $?
fi
hdfs --daemon start namenode
if (( $?!=0 )); then
exit $?
fi
#sync and start other namenodes
echo 'sync and start others.'>>init.log
dosyncid=2
while (($dosyncid<=3));do
ssh root@$nodehostnameprefix$dosyncid "hdfs namenode -bootstrapStandby"
if (( $?!=0 )); then
exit $?
fi
ssh root@$nodehostnameprefix$dosyncid "hdfs --daemon start namenode"
if (( $?!=0 )); then
exit $?
fi
let "dosyncid++"
done
#format zookeeper directory
hdfs zkfc -formatZK
}
#---------------------------------------------------------------------------------------------------------
#FUNCTION:init hadoop while dfs formatted-----------------------------------------------------------------
initHadoop_noformat(){
echo 'name node formatted. go on to start dfs related nodes and service'>>init.log
sbin/start-dfs.sh
if (( $?!=0 )); then
exit $?
fi
echo 'start yarn resourcemanager and node manager'>>init.log
sbin/start-yarn.sh
if (( $?!=0 )); then
exit $?
fi
echo 'start mapreduce history server'>>init.log
historyservernode=`cat $HADOOP_HOME/etc/hadoop/mapred-site.xml |grep -A 2 'mapreduce.jobhistory.address'|grep '' |sed -e "s/^.*//g"|sed -e "s/<\/value>//g"|sed -e "s/:[[:digit:]]*//g"`
ssh root@$historyservernode "mapred --daemon start historyserver"
if (( $?!=0 )); then
exit $?
fi
}
############################################################################################################
## 4. test wether this is the main node ##
############################################################################################################
#get the host node's name, name prefix, and name No.
nodehostname=`hostname`
nodehostnameprefix=`echo $nodehostname|sed -e 's|[[:digit:]]\+$||g'`
nodeindex=`hostname | sed "s/${nodehostnameprefix}//g"`
#get the zookeeper's name prefix from yarn-site.xml
zookeepernameprefix=`cat ${HADOOP_HOME}/etc/hadoop/yarn-site.xml |grep -A 2 'yarn.resourcemanager.zk-address '|grep ''|sed -e "s/[[:blank:]]\+\([[:alpha:]]\+\)[[:digit:]]\+:.*/\1/g"`
#1.ensure in working directory, only the first node can go on initiation.
cd $HADOOP_HOME
#check the NODECOUNT param,if it is less than 3, do notion and return err for 3 node can not support ha mode.
if (($NODECOUNT<=3));then
echo "Nodes count must more than 3.">>init.log
exit 1
fi
#check node id,if node id not equal 1, do nothing.
if (($nodeindex!=1));then
echo $nodehostname waiting for init...>>init.log
sleep 5m
cd $HADOOP_HOME
sbin/start-dfs.sh
sbin/start-yarn.sh
if (($nodeindex==3));then
mapred --daemon start historyserver
fi
tail -f /dev/null
exit 0
fi
#2.Try to connect to all host nodes and zookeeper nodes.
echo $nodehostname is the init manager nodes...>>init.log
#waiting for all the nodes connected
isAllNodesConnected $nodehostnameprefix $NODECOUNT $TRYLOOP
isHadoopOK=$?
isAllNodesConnected $zookeepernameprefix $ZOOKEEPERNODECOUNT $TRYLOOP
isZookeeperOK=$?
if ([ $isHadoopOK != 0 ] || [ $isZookeeperOK != 0 ]);then
echo "Not all the host nodes or not all the zookeeper nodes actived. exit 1">>init.log
exit 0
fi
#3. whether dfs is formatted.
datadirectory=`echo $(getDataDirectory)`
if [ $datadirectory ];then
datadircontent=`ls -A ${datadirectory}`
if [ -z $datadircontent ];then
echo "dfs is not formatted.">>init.log
isDfsFormat=0
else
echo "dfs is already formatted.">>init.log
isDfsFormat=1
fi
else
echo "ERROR:Can not get hadoop tmp data directory.init can not be done. ">>init.log
exit 1
fi
#4. if not fomatted, then do format and sync
if (( $isDfsFormat == 0 ));then
initHadoop_format
fi
if (( $? != 0 ));then
echo "ERROR:Init Hadoop interruptted...">>init.log
exit $?
fi
#5. start all dfs node, yarn node and mapreduce history server
initHadoop_noformat
if (( $? != 0 ));then
echo "ERROR:Init Hadoop interruptted...">>init.log
exit $?
fi
echo "hadoop init work has been done. hang up for swarm."
tail -f /dev/null
3. stack配置文件
version: "3.7"
services:
pignode1:
image: pig/hadoop:ha
deploy:
endpoint_mode: dnsrr
restart_policy:
condition: on-failure
placement:
constraints:
- node.hostname==pighost1
hostname: pignode1
environment:
- NODE_COUNT=12
- ZOOKEEPER_COUNT=3
networks:
- pig
ports:
- target: 22
published: 9011
protocol: tcp
mode: host
- target: 9000
published: 9000
protocol: tcp
mode: host
- target: 9870
published: 9870
protocol: tcp
mode: host
- target: 8088
published: 8088
protocol: tcp
mode: host
volumes:
# 映射xml配置文件
- ./config/core-site.xml:/root/hadoop/etc/hadoop/core-site.xml:r
- ./config/hdfs-site.xml:/root/hadoop/etc/hadoop/hdfs-site.xml:r
- ./config/yarn-site.xml:/root/hadoop/etc/hadoop/yarn-site.xml:r
- ./config/mapred-site.xml:/root/hadoop/etc/hadoop/mapred-site.xml:r
# 映射workers文件
- ./config/workers:/root/hadoop/etc/hadoop/workers:r
# 映射数据目录
- /hadoopdata/1:/hadoopdata:wr
pignode2:
image: pig/hadoop:ha
deploy:
endpoint_mode: dnsrr
restart_policy:
condition: on-failure
placement:
# 将Second Namenode限制部署在第二个节点上
constraints:
- node.hostname==pighost2
networks:
- pig
hostname: pignode2
ports:
# 第二名字服务器接口
- target: 22
published: 9012
protocol: tcp
mode: host
- target: 9890
published: 9890
protocol: tcp
mode: host
- target: 9870
published: 9871
protocol: tcp
mode: host
- target: 8088
published: 8089
protocol: tcp
mode: host
volumes:
# 映射xml配置文件
- ./config/core-site.xml:/root/hadoop/etc/hadoop/core-site.xml:r
- ./config/hdfs-site.xml:/root/hadoop/etc/hadoop/hdfs-site.xml:r
- ./config/yarn-site.xml:/root/hadoop/etc/hadoop/yarn-site.xml:r
- ./config/mapred-site.xml:/root/hadoop/etc/hadoop/mapred-site.xml:r
# 映射workers文件
- ./config/workers:/root/hadoop/etc/hadoop/workers:r
# 映射数据目录
- /hadoopdata/2:/hadoopdata:wr
pignode3:
image: pig/hadoop:ha
deploy:
endpoint_mode: dnsrr
restart_policy:
condition: on-failure
placement:
# 将Mapreduce限制部署在第三个节点上
constraints:
- node.hostname==pighost3
networks:
- pig
hostname: pignode3
ports:
- target: 22
published: 9013
protocol: tcp
mode: host
- target: 9870
published: 9872
protocol: tcp
mode: host
- target: 8088
published: 8087
protocol: tcp
mode: host
- target: 8090
published: 8090
protocol: tcp
mode: host
- target: 10020
published: 10020
protocol: tcp
mode: host
- target: 19888
published: 19888
protocol: tcp
mode: host
volumes:
# 映射xml配置文件
- ./config/core-site.xml:/root/hadoop/etc/hadoop/core-site.xml:r
- ./config/hdfs-site.xml:/root/hadoop/etc/hadoop/hdfs-site.xml:r
- ./config/yarn-site.xml:/root/hadoop/etc/hadoop/yarn-site.xml:r
- ./config/mapred-site.xml:/root/hadoop/etc/hadoop/mapred-site.xml:r
# 映射workers文件
- ./config/workers:/root/hadoop/etc/hadoop/workers:r
# 映射数据目录
- /hadoopdata/3:/hadoopdata:wr
#------------------------------------------------------------------------------------------------
#以下均为工作节点,可在除leader以外的主机上部署
pignode4:
image: pig/hadoop:ha
deploy:
endpoint_mode: dnsrr
restart_policy:
condition: on-failure
placement:
# 将Mapreduce限制部署在第三个节点上
constraints:
# node.role==manager
# node.role==worker
- node.hostname==pighost3
networks:
- pig
ports:
- target: 22
published: 9014
protocol: tcp
mode: host
hostname: pignode4
volumes:
# 映射xml配置文件
- ./config/core-site.xml:/root/hadoop/etc/hadoop/core-site.xml:r
- ./config/hdfs-site.xml:/root/hadoop/etc/hadoop/hdfs-site.xml:r
- ./config/yarn-site.xml:/root/hadoop/etc/hadoop/yarn-site.xml:r
- ./config/mapred-site.xml:/root/hadoop/etc/hadoop/mapred-site.xml:r
# 映射workers文件
- ./config/workers:/root/hadoop/etc/hadoop/workers:r
# 映射数据目录
- /hadoopdata/4:/hadoopdata:wr
pignode5:
image: pig/hadoop:ha
deploy:
endpoint_mode: dnsrr
restart_policy:
condition: on-failure
placement:
# 将Mapreduce限制部署在第三个节点上
constraints:
# node.role==manager
- node.hostname==pighost3
networks:
- pig
ports:
- target: 22
published: 9015
protocol: tcp
mode: host
hostname: pignode5
volumes:
# 映射xml配置文件
- ./config/core-site.xml:/root/hadoop/etc/hadoop/core-site.xml:r
- ./config/hdfs-site.xml:/root/hadoop/etc/hadoop/hdfs-site.xml:r
- ./config/yarn-site.xml:/root/hadoop/etc/hadoop/yarn-site.xml:r
- ./config/mapred-site.xml:/root/hadoop/etc/hadoop/mapred-site.xml:r
# 映射workers文件
- ./config/workers:/root/hadoop/etc/hadoop/workers:r
# 映射数据目录
- /hadoopdata/5:/hadoopdata:wr
pignode6:
image: pig/hadoop:ha
deploy:
endpoint_mode: dnsrr
restart_policy:
condition: on-failure
placement:
# 将Mapreduce限制部署在第三个节点上
constraints:
# node.role==manager
- node.hostname==pighost3
networks:
- pig
ports:
- target: 22
published: 9016
protocol: tcp
mode: host
hostname: pignode6
volumes:
# 映射xml配置文件
- ./config/core-site.xml:/root/hadoop/etc/hadoop/core-site.xml:r
- ./config/hdfs-site.xml:/root/hadoop/etc/hadoop/hdfs-site.xml:r
- ./config/yarn-site.xml:/root/hadoop/etc/hadoop/yarn-site.xml:r
- ./config/mapred-site.xml:/root/hadoop/etc/hadoop/mapred-site.xml:r
# 映射workers文件
- ./config/workers:/root/hadoop/etc/hadoop/workers:r
# 映射数据目录
- /hadoopdata/6:/hadoopdata:wr
pignode7:
image: pig/hadoop:ha
deploy:
endpoint_mode: dnsrr
restart_policy:
condition: on-failure
placement:
# 将Mapreduce限制部署在第三个节点上
constraints:
# node.role==manager
- node.hostname==pighost4
networks:
- pig
ports:
- target: 22
published: 9017
protocol: tcp
mode: host
hostname: pignode7
volumes:
# 映射xml配置文件
- ./config/core-site.xml:/root/hadoop/etc/hadoop/core-site.xml:r
- ./config/hdfs-site.xml:/root/hadoop/etc/hadoop/hdfs-site.xml:r
- ./config/yarn-site.xml:/root/hadoop/etc/hadoop/yarn-site.xml:r
- ./config/mapred-site.xml:/root/hadoop/etc/hadoop/mapred-site.xml:r
# 映射workers文件
- ./config/workers:/root/hadoop/etc/hadoop/workers:r
# 映射数据目录
- /hadoopdata/7:/hadoopdata:wr
pignode8:
image: pig/hadoop:ha
deploy:
endpoint_mode: dnsrr
restart_policy:
condition: on-failure
placement:
# 将Mapreduce限制部署在第三个节点上
constraints:
# node.role==manager
- node.hostname==pighost4
networks:
- pig
ports:
- target: 22
published: 9018
protocol: tcp
mode: host
hostname: pignode8
volumes:
# 映射xml配置文件
- ./config/core-site.xml:/root/hadoop/etc/hadoop/core-site.xml:r
- ./config/hdfs-site.xml:/root/hadoop/etc/hadoop/hdfs-site.xml:r
- ./config/yarn-site.xml:/root/hadoop/etc/hadoop/yarn-site.xml:r
- ./config/mapred-site.xml:/root/hadoop/etc/hadoop/mapred-site.xml:r
# 映射workers文件
- ./config/workers:/root/hadoop/etc/hadoop/workers:r
# 映射数据目录
- /hadoopdata/8:/hadoopdata:wr
pignode9:
image: pig/hadoop:ha
deploy:
endpoint_mode: dnsrr
restart_policy:
condition: on-failure
placement:
# 将Mapreduce限制部署在第三个节点上
constraints:
# node.role==manager
- node.hostname==pighost4
networks:
- pig
ports:
- target: 22
published: 9019
protocol: tcp
mode: host
hostname: pignode9
volumes:
# 映射xml配置文件
- ./config/core-site.xml:/root/hadoop/etc/hadoop/core-site.xml:r
- ./config/hdfs-site.xml:/root/hadoop/etc/hadoop/hdfs-site.xml:r
- ./config/yarn-site.xml:/root/hadoop/etc/hadoop/yarn-site.xml:r
- ./config/mapred-site.xml:/root/hadoop/etc/hadoop/mapred-site.xml:r
# 映射workers文件
- ./config/workers:/root/hadoop/etc/hadoop/workers:r
# 映射数据目录
- /hadoopdata/9:/hadoopdata:wr
pignode10:
image: pig/hadoop:ha
deploy:
endpoint_mode: dnsrr
restart_policy:
condition: on-failure
placement:
# 将Mapreduce限制部署在第三个节点上
constraints:
# node.role==manager
- node.hostname==pighost5
networks:
- pig
ports:
- target: 22
published: 9020
protocol: tcp
mode: host
hostname: pignode10
volumes:
# 映射xml配置文件
- ./config/core-site.xml:/root/hadoop/etc/hadoop/core-site.xml:r
- ./config/hdfs-site.xml:/root/hadoop/etc/hadoop/hdfs-site.xml:r
- ./config/yarn-site.xml:/root/hadoop/etc/hadoop/yarn-site.xml:r
- ./config/mapred-site.xml:/root/hadoop/etc/hadoop/mapred-site.xml:r
# 映射workers文件
- ./config/workers:/root/hadoop/etc/hadoop/workers:r
# 映射数据目录
- /hadoopdata/10:/hadoopdata:wr
pignode11:
image: pig/hadoop:ha
deploy:
endpoint_mode: dnsrr
restart_policy:
condition: on-failure
placement:
# 将Mapreduce限制部署在第三个节点上
constraints:
# node.role==manager
- node.hostname==pighost5
networks:
- pig
ports:
- target: 22
published: 9021
protocol: tcp
mode: host
hostname: pignode11
volumes:
# 映射xml配置文件
- ./config/core-site.xml:/root/hadoop/etc/hadoop/core-site.xml:r
- ./config/hdfs-site.xml:/root/hadoop/etc/hadoop/hdfs-site.xml:r
- ./config/yarn-site.xml:/root/hadoop/etc/hadoop/yarn-site.xml:r
- ./config/mapred-site.xml:/root/hadoop/etc/hadoop/mapred-site.xml:r
# 映射workers文件
- ./config/workers:/root/hadoop/etc/hadoop/workers:r
# 映射数据目录
- /hadoopdata/11:/hadoopdata:wr
pignode12:
image: pig/hadoop:ha
deploy:
endpoint_mode: dnsrr
restart_policy:
condition: on-failure
placement:
# 将Mapreduce限制部署在第三个节点上
constraints:
# node.role==manager
- node.hostname==pighost5
networks:
- pig
ports:
- target: 22
published: 9022
protocol: tcp
mode: host
hostname: pignode12
volumes:
# 映射xml配置文件
- ./config/core-site.xml:/root/hadoop/etc/hadoop/core-site.xml:r
- ./config/hdfs-site.xml:/root/hadoop/etc/hadoop/hdfs-site.xml:r
- ./config/yarn-site.xml:/root/hadoop/etc/hadoop/yarn-site.xml:r
- ./config/mapred-site.xml:/root/hadoop/etc/hadoop/mapred-site.xml:r
# 映射workers文件
- ./config/workers:/root/hadoop/etc/hadoop/workers:r
# 映射数据目录
- /hadoopdata/12:/hadoopdata:wr
zookeeper1:
image: zookeeper:latest
deploy:
endpoint_mode: dnsrr
restart_policy:
condition: on-failure
placement:
constraints:
- node.hostname==pighost1
networks:
- pig
ports:
- target: 2181
published: 2181
protocol: tcp
mode: host
hostname: zookeeper1
environment:
- ZOO_MY_ID=1
- ZOO_SERVERS=server.1=zookeeper1:2888:3888;2181 server.2=zookeeper2:2888:3888;2181 server.3=zookeeper3:2888:3888;2181
volumes:
- /hadoopdata/zoo/1/data:/data
- /hadoopdata/zoo/1/datalog:/datalog
- /hadoopdata/zoo/1/logs:/logs
zookeeper2:
image: zookeeper:latest
deploy:
endpoint_mode: dnsrr
restart_policy:
condition: on-failure
placement:
constraints:
- node.hostname==pighost2
networks:
- pig
ports:
- target: 2181
published: 2182
protocol: tcp
mode: host
hostname: zookeeper2
environment:
- ZOO_MY_ID=2
- ZOO_SERVERS=server.1=zookeeper1:2888:3888;2181 server.2=zookeeper2:2888:3888;2181 server.3=zookeeper3:2888:3888;2181
volumes:
- /hadoopdata/zoo/2/data:/data
- /hadoopdata/zoo/2/datalog:/datalog
- /hadoopdata/zoo/2/logs:/logs
zookeeper3:
image: zookeeper:latest
deploy:
endpoint_mode: dnsrr
restart_policy:
condition: on-failure
placement:
constraints:
- node.hostname==pighost3
networks:
- pig
ports:
- target: 2181
published: 2183
protocol: tcp
mode: host
hostname: zookeeper3
environment:
- ZOO_MY_ID=3
- ZOO_SERVERS=server.1=zookeeper1:2888:3888;2181 server.2=zookeeper2:2888:3888;2181 server.3=zookeeper3:2888:3888;2181
volumes:
- /hadoopdata/zoo/3/data:/data
- /hadoopdata/zoo/3/datalog:/datalog
- /hadoopdata/zoo/3/logs:/logs
networks:
pig:
到这吧,不能再写了,内容太多,网页都卡……重启一篇。