并行计算——MPI编程
目录
基础知识
进程与线程,并行与并发
奇偶排序
MPI实现 odd-even sort
思路
环境部署
编程实现(C++)
“若干”的问题
参考链接
一个偶然的机会,我接触到了国立清华大学的MPI编程作业,也就接触到了并行计算。这次作业简单描述的话,就是使用MPI的并行计算能力实现一个奇偶排序,并理解他的原理、思想,下面是作业的原题。
In this homework, you are required to write a parallel odd-even transposition sort by using MPI. A a parallel odd-even transposition sort is performed as follows:
/* Initially, numbers are distributed to processes, respectively.*/
For each process with odd rank P, send its number to the process with rank P-1.
For each process with rank P- 1, compare its number with the number sent by the process with rank P and send the larger one back to the process with rank P.
For each process with even rank Q, send its number to the process with rank Q-1.
For each process with rank Q- 1, compare its number with the number sent by the process with rank Q and send the larger one back to the process with rank Q.
本文主要介绍并行计算的概念,以及MPI编程如何实现。
基础知识
进程与线程,并行与并发
进程与线程:
① 进程:可以理解为电脑任务管理器的一个个应用,他是系统资源分配的基本单位,一个进程可以被多个CPU执行。
② 线程:可以理解为进程的一部分,一个进程可以由多个线程组成,他是CPU调度执行的基本单位,一个线程不可以被多个CPU执行。
多任务执行的两种方式:
① 并发:在一段时间内交替去执行多个任务:任务数量大于CPU核心数<切换速度很快>
② 并行:在一段时间内真正同时一起执行多个任务:任务数量小于或等于CPU核心数)
在python中,有许多模块,例如threading、multiprocessing都可以实现线程的并发、并行,一下是一段使用threading的代码示例:
import threading
import time
# 定义任务函数
def task(num):
print('Thread %d is processing...' % num)
time.sleep(1) # 模拟任务执行时间
print('Thread %d is done.' % num)
# 并行执行任务
def parallel_processing():
threads = []
start_time = time.time() # 记录开始时间
# 创建 5 个线程,并启动执行任务
for i in range(5):
t = threading.Thread(target=task, args=(i,))
threads.append(t)
t.start()
# 等待所有线程都完成
for t in threads:
t.join()
end_time = time.time() # 记录结束时间
print(f"Parallel processing time: {end_time - start_time:.2f}s") # 输出并行处理所需时间
# 并发执行任务
def concurrent_processing():
start_time = time.time() # 记录开始时间
# 创建 5 个线程,并启动执行任务
for i in range(5):
t = threading.Thread(target=task, args=(i,))
t.start()
end_time = time.time() # 记录结束时间
print(f"Concurrent processing time: {end_time - start_time:.2f}s") # 输出并发处理所需时间
if __name__ == '__main__':
parallel_processing() # 并行处理任务
concurrent_processing() # 并发处理任务一般情况下,线程并发比线程并行更快。这是因为线程并发使用的是单一CPU资源进行多个任务的切换执行,而线程并行则需要将任务分配到多个CPU核心上进行并行处理。由于存在线程切换的开销和多个CPU之间的数据交互的通信开销,线程并行可能会消耗更多的系统资源和时间,导致效率较低。但是,对于某些计算密集型或I/O密集型的任务,如果能够利用多核CPU的优势,采用线程并行方式可以取得更好的效果。
那么同样的道理,进程的并行通常比并发更快。但是,采用并发还是并行都必须结合具体情况,如程序所需的资源多少和当前的CPU个数进行具体分析。
奇偶排序
奇偶排序(odd even sort)是一个经典的排序算法,而将这个算法用于体现MPI编程的好处,则是更为经典的做法。
下面为奇偶排序示意动图以及python代码:

def odd_even_sort(arr):
"""
奇偶排序函数,输入一个列表,返回一个按升序排列的新列表
"""
n = len(arr)
sorted_flag = 0
while sorted_flag == 0:
sorted_flag = 1
for odd_even in range(2):
# 如果是奇数轮,则从下标为1的位置开始,每隔2个元素比较一次
# 如果是偶数轮,则从下标为0的位置开始,每隔2个元素比较一次
for i in range(odd_even, n - 1, 2):
if arr[i] > arr[i + 1]:
arr[i], arr[i + 1] = arr[i + 1], arr[i]
sorted_flag = 0
return arr
if __name__ == '__main__':
number = [503, 87, 512, 61, 908, 170, 897, 275, 653, 426, 154, 509, 612, 677, 765, 703]
# 输出未排序的关键字
print("Unsorted Ks:")
for i in range(len(number)):
print(i + 1, ":", number[i])
print()
# 奇偶排序
odd_even_sort(number)
# 输出已排序的关键字
print("Sorted Ks:")
for i in range(len(number)):
print(i + 1, ":", number[i])我们不难看出,奇偶排序有很强的可并行性,同一个for i in range(odd_even, n - 1, 2)中,每一次的交换都是没有前置条件的,这当然可以并行批量完成交换。
MPI实现 odd-even sort
MPI(Massage Passing Interface)是消息传递函数库的标准规范,由MPI论坛开发。可以使用他进行进程间的通信,实现进程间的并行计算。
思路
思路描述如下:
-
Step0:和前面说的一样,先根据CPU的个数将整个待排序数组分成若干个子序列(这里的“若干个”,在后面会有更详细的解释)。
-
Step1:在每个子序列中,随意的使用一个排序算法将子序列从小到大排好(真的随便用什么算法,总之排好就可以了)。
-
Step2:以子序列为单位,对整个序列进行奇偶排序,在比较后序号较小的子序列保存前半部分的小数,较大的子序列保留后半部分大数字(这个大小完全是根据排序升降序的要求)
-
Step3:重复Step1、Step2,直到序列完全有序。
你可能存在疑惑,没关系,下面有例子。
假设待排序的数组如下:
arr=[15,11,9,16,3,14,8,7,4,6,12,10,5,2,13,1],即1-16的打乱,子序列分为4个,排序过程如下:
| 排序过程\子序列 | P1 | P2 | P3 | P4 |
|---|---|---|---|---|
| 初始情况 | 15,11,9,16 | 6,3,14,8 | 7,4,6,12 | 5,2,13,1 |
| 1_组内排序 | 9,11,15,16 | 3,6,8,14 | 4,6,7,12 | 1,2,5,13 |
| 1_奇偶排序_奇 | 3,7,8,9 | 11,14,15,16 | 1,2,4,5 | 6,10,12,13 |
| 1_奇偶排序_偶 | 3,7,8,9 | 1,2,4,5 | 11,14,15,16 | 6,10,12,13 |
| 2_奇偶排序_奇 | 1,2,3,4 | 5,7,8,9 | 6,10,11,12 | 11,12,13,14 |
| 2_奇偶排序_偶 | 1,2,3,4 | 5,6,7,8 | 9,10,11,12 | 11,12,13,14 |
| 序 | 列 | 排 | 好 | 了 |
1_奇偶排序_奇:P1与P2比,P3与P4比,这里的“比”是指将两个子序列合并排好序,序号偏小的留下数值小的部分,序号偏大的留下数值大的部分。
1_奇偶排序_偶:P2与P3比,P1、P4被跳过了。“比”的含义同上。
这个过程固然是很麻烦,把原本简单的排序似乎搞复杂了,但是要明白,联合很多个人做事要比单干麻烦很多,想到这里我也就不觉得奇怪了。
环境部署
由于MPI不是一个语言,而是一种新的库描述,所以可以用很多语言实现,本文讲C++和python的环境配置方法。
C++
# 首先安装gcc和gfortan,这两步应该问题不大
sudo apt‐get install gcc
which gcc
sudo apt‐get install gfortran
whicg gfortan
# 接着安装MPI编程的环境
sudo wget http://www.mpich.org/static/downloads/3.3.2/mpich‐3.3.2.tar.gz
tar ‐zxvf mpich‐3.3.2.tar.gz
cd mpich‐3.3.2
./configure ‐‐prefix=/usr/local/mpich‐3.3.2
# The ‐‐prefix parameter is to set the installation path, just set the appropriate path according to your needs, but you need to remember the installation location
make
# 这一步需要很长时间,请耐心等待
make install
vim ~/.bashrc
# 写入环境变量
export PATH="/usr/local/mpich‐3.3.2/bin:$PATH"
source ~/.bashrc
which mpicc
which mpif90 # 查看是否安装成功
MPI编程的测试代码:
/* hellow.c */
#include
#include
int main(int argc, char * argv[])
{
int myrank, nprocs;
MPI_Init(&argc, &argv);
MPI_Comm_size(MPI_COMM_WORLD,&nprocs);
MPI_Comm_rank(MPI_COMM_WORLD, &myrank);
printf("rank%dof%d:Hello,world!\n",myrank, nprocs);
MPI_Finalize();
return 0;
} -
MPI_Init(&argc, &argv);初始化MPI编程环境 -
MPI_Comm_size(MPI_COMM_WORLD,&nprocs);MPI_Comm_rank(MPI_COMM_WORLD, &myrank);获得并行环境参数(进程总数,本地进程编号等)。 -
printf("rank%dof%d:Hello,world!\n",myrank, nprocs);执行计算、通信。 -
MPI_Finalize();结束MPI编程。
编译、执行命令:
mpicc hellow.c ‐o hellow
mpirun ‐np 4 ./hellopython
MPI在Python中的实现是通过mpi4py库来完成的,瞬间安装命令如下:
pip install mpi4py --upgrade -i http://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com当然,还需要安装MPI本身:Download Microsoft MPI v10.0 from Official Microsoft Download Center,直接一路安装到底,也不需要手动配环境变量。

编程实现(C++)
#include
#include"mpi.h"
#include
#include
#include
using namespace std;
void odd_even_sort(float *p, int num);//顺序执行的奇偶排序
void swap(float *p, int i, int j);//交换算法
void mergeSort(float *data, float *buffer, float *tmp, bool &sort, int part);//两块排好序的元素进行排序合并
void parallelMergeSort(float *data, int part);//奇偶排序式的 融合排序算法
int main(int argc, char *argv[]) {
MPI_Init(&argc, &argv);
int myid, numprocs;//进程标识,进程总数
MPI_Comm_rank(MPI_COMM_WORLD, &myid);
MPI_Comm_size(MPI_COMM_WORLD, &numprocs);
int masterNode = 0;
float *memoryPool = nullptr;
if (myid == masterNode) {
const int N = 9900;//待排元素个数
int padding = numprocs - N % numprocs;//若不能整除则需加上padding个无穷大的元素使能够整除
memoryPool = new float[N + padding] {0};
srand(time(NULL));
for (int i = 0; i < N; ++i)
memoryPool[i] = (rand() % 1000) / 10.0;
double start = MPI_Wtime();//串行开始计时
if (numprocs == 1) {
odd_even_sort(memoryPool, N);
double finish = MPI_Wtime();//串行停止计时
cout << "串行时间:" << finish - start << endl;
MPI_Finalize();
return 0;
}
for (int i = 0; i < padding; ++i)
memoryPool[N + i] = numeric_limits::infinity();//设置一个无穷大值
int part = (N + padding) / numprocs;
start = MPI_Wtime();//并行开始计时
MPI_Bcast(&part, 1, MPI_INT, masterNode, MPI_COMM_WORLD);
float *data = new float[part] {0};
//主进程向各进程播撒数据
MPI_Scatter(memoryPool, part, MPI_FLOAT, data, part, MPI_FLOAT, masterNode, MPI_COMM_WORLD);
//保证部分有序
odd_even_sort(data, part);
parallelMergeSort(data, part);
//将全局有序的数据收集到主进程
MPI_Gather(data, part, MPI_FLOAT, memoryPool, part, MPI_FLOAT, masterNode, MPI_COMM_WORLD);
double finish = MPI_Wtime();//并行停止计算
if (memoryPool)delete[]memoryPool;
if (myid == masterNode)
cout << "调用进程数:" << numprocs << " 计算时间:" << finish - start << endl;
delete[]data;
}
MPI_Finalize();
return 0;
}
void odd_even_sort(float *p, int num) {
bool sort = false;
while (!sort) { //若一次奇数排序,一次偶数排序,均未发生数据交换,则认为已排好序
sort = true;
for (int i = 1; i < num; i += 2) {
if (p[i] < p[i - 1]) { //此处不能写等号
swap(p, i, i - 1);
sort = false;
}
}
for (int i = 2; i < num; i += 2) {
if (p[i] < p[i - 1]) {
swap(p, i, i - 1);
sort = false;
}
}
}
}
inline void swap(float *p, int i, int j) {
float tmp = p[i];
p[i] = p[j];
p[j] = tmp;
}
void mergeSort(float *data, float *buffer, float *tmp, bool &sort, int part) {
int i = 0, j = 0, k = 0;
while (i != part && j != part) {
if (data[i] <= buffer[j]) {
tmp[k++] = data[i++]; //此处等号一定要加
} else {
tmp[k++] = buffer[j++];
}
}
if (j != 0)sort = false;
if (i != part) {
while (k != 2 * part)tmp[k++] = data[i++];
}
if (j != part) {
while (k != 2 * part)tmp[k++] = buffer[j++];
}
copy_n(tmp, part, data);
copy_n(tmp + part, part, buffer);
}
void parallelMergeSort(float *data, int part) {
MPI_Status status;
int myid, numprocs;
MPI_Comm_rank(MPI_COMM_WORLD, &myid);
MPI_Comm_size(MPI_COMM_WORLD, &numprocs);
int left = myid - 1, right = myid + 1;
if (left < 0)left = MPI_PROC_NULL;//虚拟进程,使所有进程都有左右,边界上无序特殊处理
if (right > numprocs - 1)right = MPI_PROC_NULL;
float *buffer = new float[part] { 0 };
float *tmp = new float[2 * part] { 0 };
bool sort = false;
bool flag = false;
while (!flag) {
sort = true;
if (myid % 2 == 0) {
MPI_Send(data, part, MPI_FLOAT, left, 0, MPI_COMM_WORLD);
MPI_Recv(data, part, MPI_FLOAT, left, 0, MPI_COMM_WORLD, &status);
} else if (right != MPI_PROC_NULL) { //如果接受的是虚拟进程的消息(空),那就不应该进行mergeSort
MPI_Recv(buffer, part, MPI_FLOAT, right, 0, MPI_COMM_WORLD, &status);
mergeSort(data, buffer, tmp, sort, part);
MPI_Send(buffer, part, MPI_FLOAT, right, 0, MPI_COMM_WORLD);
}
MPI_Barrier(MPI_COMM_WORLD);//屏障函数,显式将奇排序和偶排序分开,不加也可以
if (myid % 2 == 1) {
MPI_Send(data, part, MPI_FLOAT, left, 0, MPI_COMM_WORLD);
MPI_Recv(data, part, MPI_FLOAT, left, 0, MPI_COMM_WORLD, &status);
} else if (right != MPI_PROC_NULL) {
MPI_Recv(buffer, part, MPI_FLOAT, right, 0, MPI_COMM_WORLD, &status);
mergeSort(data, buffer, tmp, sort, part);
MPI_Send(buffer, part, MPI_FLOAT, right, 0, MPI_COMM_WORLD);
}
//全规约函数,对每个进程中的sort标识求逻辑与,结果保存在flag中,flag=1 意味着每个进程的sort都为1,排序完成
MPI_Allreduce(&sort, &flag, 1, MPI_C_BOOL, MPI_LAND, MPI_COMM_WORLD);
}
delete[]tmp;
delete[]buffer;
} “若干”的问题
从下面的实验结果可以看出,在选择分为两个子序列时,排序速度是最快的(使用CPU的核数通常都是偶数,具体原因个人感觉有技术和市场两方面)。那么为什么分的子序列更多,反而排序的速度成倍减慢呢?
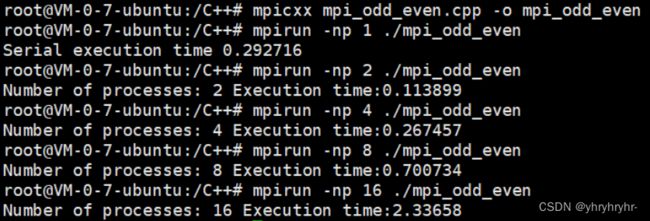
因为这个实验是在服务器上做的,代码是C++写的,我的服务器CPU只有两个,如果分的子序列超过了CPU的个数,那么进程之间的切换会耗费大量的时间,这非但不会加快排序的速度,反而会让程序严重变慢。这就有点东施效颦的感觉,明明没有那么多CPU,还非要分那么多子进程
参考链接
两小时入门MPI与并行计算(一):并行计算预备知识
并行计算:MPI总结
MPI并行计算学习笔记4——奇偶排序的优雅实现_奇偶排序并行化
odd-even-sort/odd_even_sort.cpp at main · thkkk/odd-even-sort · GitHub