python-docx 取消首行缩进
前言
python的docx库想必大家并不陌生,就是处理word文档(docx格式)的三方库。但有些格式总是遍查各个网站都没有结果,无法处理。比如,对段落格式的首行缩进2字符如何取消?本文就是对此进行介绍,以及记录探索过程。
若不想看过程,可直奔文末看结论。
探索过程
1、缘由
最初的需求是,同事编写帮助文档的Word后,需要将文档(含图片)复制到网站的富文本编辑器中,以供用户查阅。但是一顿繁琐的操作上传图片后,富文本中的图片总是很模糊,不是原图,原因是编写word时,word本身就对大图做了压缩。
后来另一个同事对富文本编辑器编写了一个插件,自动提取word中的图片,解决了繁琐的操作,但仍无法获取原图。然后我用python-docx编写了一个工具,将图片还原为原图大小,结合起来用就可以满足需求。
但问题来了,那位同事写的文档格式很不规范,前面首行缩进的段落换行后直接粘贴图片,于是图片所在行也有了首行缩进,图片的编号也是,而该同事又只对图编号居中。这样在word中还不觉得有什么,但在大显示屏的网页查看,就是图片居左、编号居中。
于是我就想在我写的工具中一并处理:将首行缩进全部取消,然后居中。
2、最初方案(不可行)
最开始的思路就是直接赋值,像这样:
from docx import Document
from docx.enum.text import WD_PARAGRAPH_ALIGNMENT
doc = Document(r'D:/test/文本缩进测试.docx')
graph = doc.paragraphs[10] # 某一段落
graph.paragraph_format.first_line_indent = 0 # 首行缩进设置为0
graph.paragraph_format.left_indent = 0 # 左侧缩进设置为0
graph.paragraph_format.alignment = WD_PARAGRAPH_ALIGNMENT.CENTER # 居中
doc.save(r'D:/test/[已处理]文本缩进测试.docx')但是发现,虽然居中了,但缩进没有取消!
3、灵感
没办法,换种方式尝试,但探索了很长时间都不行,甚至换了种方式:复制本行到新的一行,然后删除原行。但新的问题来了:字体如何获取?
word中有些字体是继承前面的,使用python-docx获取出来是空值,在网上找了方法获取,然后,最重要的一步设置字体是这段代码:
run.element.rPr.rFonts.set(qn('w:eastAsia'), ‘宋体’)完整代码:
from docx import Document
from docx.oxml.ns import qn
doc = Document(r'D:/test/文本缩进测试.docx')
graph = doc.paragraphs[10] # 某一段落
run = graph.runs[0] # 某一段落的某一段内容
run.font.name = ‘宋体’ # 1、先对字体设置
run.element.rPr.rFonts.set(qn('w:eastAsia'), ‘宋体’) # 2、再对xml的属性赋值
doc.save(r'D:/test/[已处理]文本缩进测试.docx')其中,还提到docx文档本质是xml,可以解压获得。于是我解压获得了xml。
期间,我还尝试了修改缩进属性:(都不可行)
graph.paragraph_format.element.pPr.first_line_indent = 0 # 都不可行
graph.paragraph_format.element.pPr.ind_left = 0
graph.paragraph_format.element.pPr.ind = 0 # 会报错
del graph.paragraph_format.element.pPr.ind # 会报错然后又是打印xml,又是查看解压的xml,终于发觉:既然能通过修改xml属性给字体赋值,为何不能给段落赋值?马上尝试!
4、成功解决
先对比原文档,和解压后的document.xml文件。原文档截图:
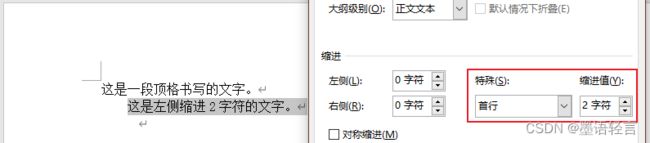
document.xml文件截图:(建议用浏览器打开xml文件,浏览器会自动解析结构)

好!真相大白!原来就这一行的区别! 既然无法删掉,那么就设置为0就行了!仿照设置字体的方式,于是:
graph.paragraph_format.element.pPr.ind.set(qn("w:firstLineChars"), '0') # 这里的0是字符串尝试可行!好,完成!
那么,举一反三,修改xml的其他属性理论上也能通过这种方式实现,妙啊!从此再也不受羁绊了!
结论
将段落的xml中对应属性赋值为0即可。封装成函数,完整代码:
from docx import Document
from docx.enum.text import WD_PARAGRAPH_ALIGNMENT
from docx.oxml.ns import qn
def clear_indent_and_center(paragraph):
paragraph.paragraph_format.left_indent = 0 # 预先对缩进赋值,防止对象为空报错
paragraph.paragraph_format.element.pPr.ind.set(qn("w:firstLineChars"), '0') # 去除缩进
paragraph.paragraph_format.element.pPr.ind.set(qn("w:firstLine"), '0')
paragraph.paragraph_format.element.pPr.ind.set(qn("w:leftChars"), '0')
paragraph.paragraph_format.element.pPr.ind.set(qn("w:left"), '0')
paragraph.paragraph_format.alignment = WD_PARAGRAPH_ALIGNMENT.CENTER # 居中
doc = Document(r'D:/test/文本缩进测试.docx')
graph = doc.paragraphs[10] # 某一段落
clear_indent_and_center(graph)
doc.save(r'D:/test/[已处理]文本缩进测试.docx')如果要修改文档其他属性,理论上都能通过此方式实现:解压docx→分析xml→直接修改属性值。但滥改很容易导致文档损坏,最好另存为,并注意检查处理后的文档!