第1章 项目需求及架构设计1.1 项目需求分析 一、数据采集平台搭建 二、Kafka、Zookeeper中间件准备 三、下游Spark Streaming对接Kafka接收数据,实现vip个数统计、栏目打标签功能、做题正确率与掌握度的实时计算功能。
1.2 项目框架1.2.1 技术选型 一、数据存储:Kafka、MySql 二、数据处理:Spark 三、其他组件:Zookeeper1.2.2 流程设计

第2章 需求2.0原始数据格式及对应topic2.0.1实时统计注册人数kafka对应 topic: register_topic数据格式:

85571 1 2019-07-16 16:01:55用户id 平台id 1:PC 2:APP 3:Ohter 创建时间2.0.2做题正确率数与知识点掌握度数据格式Kafka 对应topic: qz_log数据格式:

字段含义:1005 505 29 1 1 2019-09-12 11:17:48(用户id) (课程id) (知识点id) (题目id) (是否正确 0错误 1正确)(创建时间)2.0.3商品页面到订单页,订单页到支付页数据格式Kafka 对应topic: page_topic
数据格式

{"app_id":"1","device_id":"102","distinct_id":"5fa401c8-dd45-4425-b8c6-700f9f74c532","event_name":"-","ip":"121.76.152.135","last_event_name":"-","last_page_id":"0","next_event_name":"-","next_page_id":"2","page_id":"1","server_time":"-","uid":"245494"}
uid:用户id app_id:平台id deviceid:平台id disinct_id:唯一标识Ip:用户ip地址 last_page_id :上一页面idpage_id:当前页面id 0:首页 1:商品课程页 2:订单页面 3:支付页面next_page_id:下一页面id 2.0.4实时统计学员播放视频各时长Kafka 对应topic: course_learn数据格式:

{"biz":"bdfb58e5-d14c-45d2-91bc-1d9409800ac3","chapterid":"1","cwareid":"3","edutypeid":"3","pe":"55","ps":"41","sourceType":"APP","speed":"2","subjectid":"2","te":"1563352166417","ts":"1563352159417","uid":"235","videoid":"2"}
biz:唯一标识 chapterid:章节id cwareid:课件id edutypeid:辅导id ps:视频播放时间区间 pe:视频播放结束区间 sourceType:播放平台 speed:播放倍速 ts:视频播放开始时间(时间戳) te:视频播放结束时间(时间戳) videoid:视频id2.1环境准备在本机三台虚拟机上分别搭建好zookeeper 和kafka创建所需topic [atguigu@hadoop102 kafka]$ bin/kafka-topics.sh --zookeeper hadoop102:2181 --create --replication-factor 2 --partitions 10 --topic qz_log[atguigu@hadoop102 kafka]$ bin/kafka-topics.sh --zookeeper hadoop102:2181 --create --replication-factor 2 --partitions 10 --topic page_topic[atguigu@hadoop102 kafka]$ bin/kafka-topics.sh --zookeeper hadoop102:2181 --create --replication-factor 2 --partitions 10 --topic register_topic[atguigu@hadoop102 kafka]$ bin/kafka-topics.sh --zookeeper hadoop102:2181 --create --replication-factor 2 --partitions 10 --topic course_learn
2.2模拟数据采集模拟数据采集 将准备好的log文件使用kafka生产者代码发送信息到topic
注册日志数据 register.log日志文件 对应topic: register_topic
做题数据 qz_log 日志文件 对应topic :qz_log
商品页面数据page_log 日志文件 对应topic:page_topic
视频播放时长数据course_learn.log日志文件 对应topic: course_learn
如果windows下没有安装hadoop环境先配置环境


Ip解析工具Ip解析本地库:


2.3.实时统计注册人员信息 用户使用网站或APP进行注册,后台实时收集数据传输Kafka,Spark Streaming进行对接统计,实时统计注册人数。 需求1:实时统计注册人数,批次为3秒一批,使用updateStateBykey算子计算历史数据和当前批次的数据总数,仅此需求使用updateStateBykey,后续需求不使用updateStateBykey。 需求2:每6秒统统计一次1分钟内的注册数据,不需要历史数据 提示:reduceByKeyAndWindow算子 需求3:观察对接数据,尝试进行调优。2.4实时计算学员做题算正确率与知识点掌握度 mysql建表语句:
用户在网站或APP进行做题,做完题点击交卷按钮,程序将做题记录提交,传输到Kafka中,下游Spark Streaming对接kafka实现实时计算做题正确率和掌握度,将正确率和掌握度存入mysql中,用户点击交卷后刷新页面能立马看到自己做题的详情。需求1:要求Spark Streaming 保证数据不丢失,每秒100条处理速度,需要手动维护偏移量需求2:同一个用户做在同一门课程同一知识点下做题需要去重,需要根据历史数据进行去重并且记录去重后的做题id与个数。需求3:计算知识点正确率 正确率计算公式:做题正确总个数/做题总数 保留两位小数需求4:计算知识点掌握度 去重后的做题个数/当前知识点总题数(已知30题)*当前知识点的正确率2.5实时统计商品页到订单页,订单页到支付页转换率 mysql建表语句: 用户浏览课程首页点击下订单,跳转到订单页面,再点击支付跳转到支付页面进行支付,收集各页面跳转json数据,解析json数据计算各页面点击数和转换率,计算top3点击量按地区排名(ip字段,需要根据历史数据累计) 需求1:计算首页总浏览数、订单页总浏览数、支付页面总浏览数 需求2:计算商品课程页面到订单页的跳转转换率、订单页面到支付页面的跳转转换率 需求3:根据ip得出相应省份,展示出top3省份的点击数,需要根据历史数据累加2.6实时统计学员播放视频各时长 建表语句:
用户在线播放视频进行学习课程,后台记录视频播放开始区间和结束区间,及播放开始时间和播放结束时间,后台手机数据传输kafka需要计算用户播放视频总时长、有效时长、完成时长,及各维度总播放时长。 需求1:计算各章节下的播放总时长(按chapterid聚合统计播放总时长) 需求2:计算各课件下的播放总时长(按cwareid聚合统计播放总时长) 需求3:计算各辅导下的播放总时长(按edutypeid聚合统计播放总时长) 需求4:计算各播放平台下的播放总时长(按sourcetype聚合统计播放总时长) 需求5:计算各科目下的播放总时长(按subjectid聚合统计播放总时长) 需求6:计算用户学习视频的播放总时长、有效时长、完成时长,需求记录视频播历史区间,对于用户多次学习的播放区间不累计有效时长和完成时长。 播放总时长计算:(te-ts)/1000 向下取整 单位:秒 完成时长计算: 根据pe-ps 计算 需要对历史数据进行去重处理 有效时长计算:根据te-ts 除以pe-ts 先计算出播放每一区间需要的实际时长 * 完成时长第3章 思考(1)Spark Streaming 下每个stage的耗时由什么决定(2)Spark Streaming task发生数据倾斜如何解决(3)Spark Streaming操作mysql时,相同维度的数据如何保证线程安全问题(4)如何保证kill Spark Streaming任务的时候不丢失数据(5)如何保证Spark Streaming的第一次启动和kill后第二次启动时据不丢失数据(6)Spark Streaming下如何正确操作mysql(如何正确使用连接)(7)MySql建表时 索引注意第4章 创建maven项目在education-online父工程下创建子项目




创建相应的包

配置pom.xml文件
第5章 需求实现5.1创建MySql配置文件在resource源码包下创建comerce.peoperties
jdbc.url=jdbc:mysql://hadoop102:3306/course_learn?useUnicode=true&characterEncoding=utf8&serverTimezone=Asia/Shanghai&useSSL=falsejdbc.user=rootjdbc.password=000000
5.2创建读取配置文件的工具类在com.atguigu.qzpoint.util创建ConfigurationManager类package com.atguigu.qzpoint.util;
import java.io.InputStream;import java.util.Properties;
/** * * 读取配置文件工具类 */public class ConfigurationManager {
private static Properties prop = new Properties();
static { try { InputStream inputStream = ConfigurationManager.class.getClassLoader() .getResourceAsStream("comerce.properties"); prop.load(inputStream); } catch (Exception e) { e.printStackTrace(); } }
//获取配置项 public static String getProperty(String key) { return prop.getProperty(key); }
//获取布尔类型的配置项 public static boolean getBoolean(String key) { String value = prop.getProperty(key); try { return Boolean.valueOf(value); } catch (Exception e) { e.printStackTrace(); } return false; }
}5.3创建Json解析工具类在com.atguigu.qz.point.util创建ParseJsonData类package com.atguigu.qzpoint.util;
import com.alibaba.fastjson.JSONObject;
public class ParseJsonData {
public static JSONObject getJsonData(String data) { try { return JSONObject.parseObject(data); } catch (Exception e) { return null; } }}
5.4创建Druid连接池在com.atgugiu.qzpoint.util创建DataSourceUtil类package com.atguigu.qzpoint.util;
import com.alibaba.druid.pool.DruidDataSourceFactory;
import javax.sql.DataSource;import java.io.Serializable;import java.sql.*;import java.util.Properties;
/** * 德鲁伊连接池 */public class DataSourceUtil implements Serializable { public static DataSource dataSource = null;
static { try { Properties props = new Properties(); props.setProperty("url", ConfigurationManager.getProperty("jdbc.url")); props.setProperty("username", ConfigurationManager.getProperty("jdbc.user")); props.setProperty("password", ConfigurationManager.getProperty("jdbc.password")); props.setProperty("initialSize", "5"); //初始化大小 props.setProperty("maxActive", "10"); //最大连接 props.setProperty("minIdle", "5"); //最小连接 props.setProperty("maxWait", "60000"); //等待时长 props.setProperty("timeBetweenEvictionRunsMillis", "2000");//配置多久进行一次检测,检测需要关闭的连接 单位毫秒 props.setProperty("minEvictableIdleTimeMillis", "600000");//配置连接在连接池中最小生存时间 单位毫秒 props.setProperty("maxEvictableIdleTimeMillis", "900000"); //配置连接在连接池中最大生存时间 单位毫秒 props.setProperty("validationQuery", "select 1"); props.setProperty("testWhileIdle", "true"); props.setProperty("testOnBorrow", "false"); props.setProperty("testOnReturn", "false"); props.setProperty("keepAlive", "true"); props.setProperty("phyMaxUseCount", "100000");// props.setProperty("driverClassName", "com.mysql.jdbc.Driver"); dataSource = DruidDataSourceFactory.createDataSource(props); } catch (Exception e) { e.printStackTrace(); } }
//提供获取连接的方法 public static Connection getConnection() throws SQLException { return dataSource.getConnection(); }
// 提供关闭资源的方法【connection是归还到连接池】 // 提供关闭资源的方法 【方法重载】3 dql public static void closeResource(ResultSet resultSet, PreparedStatement preparedStatement, Connection connection) { // 关闭结果集 // ctrl+alt+m 将java语句抽取成方法 closeResultSet(resultSet); // 关闭语句执行者 closePrepareStatement(preparedStatement); // 关闭连接 closeConnection(connection); }
private static void closeConnection(Connection connection) { if (connection != null) { try { connection.close(); } catch (SQLException e) { e.printStackTrace(); } } }
private static void closePrepareStatement(PreparedStatement preparedStatement) { if (preparedStatement != null) { try { preparedStatement.close(); } catch (SQLException e) { e.printStackTrace(); } } }
private static void closeResultSet(ResultSet resultSet) { if (resultSet != null) { try { resultSet.close(); } catch (SQLException e) { e.printStackTrace(); } } }}
5.5创建操作MySql的代理类 在com.atguigu.qzpoint.util创建SqlProxy类package com.atguigu.qzpoint.util
import java.sql.{Connection, PreparedStatement, ResultSet}
trait QueryCallback { def process(rs: ResultSet)}
class SqlProxy { private var rs: ResultSet = _ private var psmt: PreparedStatement = _
/** * 执行修改语句 * * @param conn * @param sql * @param params * @return */ def executeUpdate(conn: Connection, sql: String, params: Array[Any]): Int = { var rtn = 0 try { psmt = conn.prepareStatement(sql) if (params != null && params.length > 0) { for (i <- 0 until params.length) { psmt.setObject(i + 1, params(i)) } } rtn = psmt.executeUpdate() } catch { case e: Exception => e.printStackTrace() } rtn }
/** * 执行查询语句 * 执行查询语句 * * @param conn * @param sql * @param params * @return */ def executeQuery(conn: Connection, sql: String, params: Array[Any], queryCallback: QueryCallback) = { rs = null try { psmt = conn.prepareStatement(sql) if (params != null && params.length > 0) { for (i <- 0 until params.length) { psmt.setObject(i + 1, params(i)) } } rs = psmt.executeQuery() queryCallback.process(rs) } catch { case e: Exception => e.printStackTrace() } }
def shutdown(conn: Connection): Unit = DataSourceUtil.closeResource(rs, psmt, conn)}
5.6实时统计注册人数代码实现package com.atguigu.qzpoint.streaming
import java.langimport java.sql.ResultSetimport java.util.Random
import com.atguigu.qzpoint.util.{DataSourceUtil, QueryCallback, SqlProxy}import org.apache.kafka.clients.consumer.ConsumerRecordimport org.apache.kafka.common.TopicPartitionimport org.apache.kafka.common.serialization.StringDeserializerimport org.apache.spark.SparkConfimport org.apache.spark.streaming.dstream.InputDStreamimport org.apache.spark.streaming.kafka010._import org.apache.spark.streaming.{Seconds, StreamingContext}
import scala.collection.mutable
object RegisterStreaming { private val groupid = "register_group_test"
def main(args: Array[String]): Unit = { val conf = new SparkConf().setAppName(this.getClass.getSimpleName).setMaster("local[2]") .set("spark.streaming.kafka.maxRatePerPartition", "50") .set("spark.streaming.stopGracefullyOnShutdown", "true") val ssc = new StreamingContext(conf, Seconds(3)) val topics = Array("register_topic") val kafkaMap: Map[String, Object] = Map[String, Object]( "bootstrap.servers" -> "hadoop102:9092,hadoop103:9092,hadoop104:9092", "key.deserializer" -> classOf[StringDeserializer], "value.deserializer" -> classOf[StringDeserializer], "group.id" -> groupid, "auto.offset.reset" -> "earliest", "enable.auto.commit" -> (false: lang.Boolean) ) ssc.checkpoint("hdfs://hadoop102:9000/user/atguigu/sparkstreaming/checkpoint") //查询mysql中是否有偏移量 val sqlProxy = new SqlProxy() val offsetMap = new mutable.HashMap[TopicPartition, Long]() val client = DataSourceUtil.getConnection try { sqlProxy.executeQuery(client, "select * from `offset_manager` where groupid=?", Array(groupid), new QueryCallback { override def process(rs: ResultSet): Unit = { while (rs.next()) { val model = new TopicPartition(rs.getString(2), rs.getInt(3)) val offset = rs.getLong(4) offsetMap.put(model, offset) } rs.close() //关闭游标 } }) } catch { case e: Exception => e.printStackTrace() } finally { sqlProxy.shutdown(client) } //设置kafka消费数据的参数 判断本地是否有偏移量 有则根据偏移量继续消费 无则重新消费 val stream: InputDStream[ConsumerRecord[String, String]] = if (offsetMap.isEmpty) { KafkaUtils.createDirectStream( ssc, LocationStrategies.PreferConsistent, ConsumerStrategies.Subscribe[String, String](topics, kafkaMap)) } else { KafkaUtils.createDirectStream( ssc, LocationStrategies.PreferConsistent, ConsumerStrategies.Subscribe[String, String](topics, kafkaMap, offsetMap)) } val resultDStream = stream.filter(item => item.value().split("\t").length == 3). mapPartitions(partitions => { partitions.map(item => { val line = item.value() val arr = line.split("\t") val app_name = arr(1) match { case "1" => "PC" case "2" => "APP" case _ => "Other" } (app_name, 1) }) }) resultDStream.cache() // resultDStream.reduceByKeyAndWindow((x: Int, y: Int) => x + y, Seconds(60), Seconds(6)).print() val updateFunc = (values: Seq[Int], state: Option[Int]) => { val currentCount = values.sum //本批次求和 val previousCount = state.getOrElse(0) //历史数据 Some(currentCount + previousCount) } resultDStream.updateStateByKey(updateFunc).print()
// val dsStream = stream.filter(item => item.value().split("\t").length == 3)// .mapPartitions(partitions =>// partitions.map(item => {// val rand = new Random()// val line = item.value()// val arr = line.split("\t")// val app_id = arr(1)// (rand.nextInt(3) + "_" + app_id, 1)// }))// dsStream.print()// val a = dsStream.reduceByKey(_ + _)// a.print()// a.map(item => {// val appid = item._1.split("_")(1)// (appid, item._2)// }).reduceByKey(_ + _).print()
//处理完 业务逻辑后 手动提交offset维护到本地 mysql中 stream.foreachRDD(rdd => { val sqlProxy = new SqlProxy() val client = DataSourceUtil.getConnection try { val offsetRanges: Array[OffsetRange] = rdd.asInstanceOf[HasOffsetRanges].offsetRanges for (or <- offsetRanges) { sqlProxy.executeUpdate(client, "replace into `offset_manager` (groupid,topic,`partition`,untilOffset) values(?,?,?,?)", Array(groupid, or.topic, or.partition.toString, or.untilOffset)) } } catch { case e: Exception => e.printStackTrace() } finally { sqlProxy.shutdown(client) } }) ssc.start() ssc.awaitTermination() }
}
5.7实时统计学员做题正确率与知识点掌握度package com.atguigu.qzpoint.streaming
import java.langimport java.sql.{Connection, ResultSet}import java.time.LocalDateTimeimport java.time.format.DateTimeFormatter
import com.atguigu.qzpoint.util.{DataSourceUtil, QueryCallback, SqlProxy}import org.apache.kafka.clients.consumer.ConsumerRecordimport org.apache.kafka.common.TopicPartitionimport org.apache.kafka.common.serialization.StringDeserializerimport org.apache.spark.SparkConfimport org.apache.spark.streaming.dstream.InputDStreamimport org.apache.spark.streaming.kafka010._import org.apache.spark.streaming.{Seconds, StreamingContext}
import scala.collection.mutable
/** * 知识点掌握度实时统计 */object QzPointStreaming {
private val groupid = "qz_point_group"
def main(args: Array[String]): Unit = { val conf = new SparkConf().setAppName(this.getClass.getSimpleName).setMaster("local[*]") .set("spark.streaming.kafka.maxRatePerPartition", "50") .set("spark.streaming.stopGracefullyOnShutdown", "true") val ssc = new StreamingContext(conf, Seconds(3)) val topics = Array("qz_log") val kafkaMap: Map[String, Object] = Map[String, Object]( "bootstrap.servers" -> "hadoop102:9092,hadoop103:9092,hadoop104:9092", "key.deserializer" -> classOf[StringDeserializer], "value.deserializer" -> classOf[StringDeserializer], "group.id" -> groupid, "auto.offset.reset" -> "earliest", "enable.auto.commit" -> (false: lang.Boolean) ) //查询mysql中是否存在偏移量 val sqlProxy = new SqlProxy() val offsetMap = new mutable.HashMap[TopicPartition, Long]() val client = DataSourceUtil.getConnection try { sqlProxy.executeQuery(client, "select * from `offset_manager` where groupid=?", Array(groupid), new QueryCallback { override def process(rs: ResultSet): Unit = { while (rs.next()) { val model = new TopicPartition(rs.getString(2), rs.getInt(3)) val offset = rs.getLong(4) offsetMap.put(model, offset) } rs.close() //关闭游标 } }) } catch { case e: Exception => e.printStackTrace() } finally { sqlProxy.shutdown(client) } //设置kafka消费数据的参数 判断本地是否有偏移量 有则根据偏移量继续消费 无则重新消费 val stream: InputDStream[ConsumerRecord[String, String]] = if (offsetMap.isEmpty) { KafkaUtils.createDirectStream( ssc, LocationStrategies.PreferConsistent, ConsumerStrategies.Subscribe[String, String](topics, kafkaMap)) } else { KafkaUtils.createDirectStream( ssc, LocationStrategies.PreferConsistent, ConsumerStrategies.Subscribe[String, String](topics, kafkaMap, offsetMap)) } //过滤不正常数据 获取数据 val dsStream = stream.filter(item => item.value().split("\t").length == 6). mapPartitions(partition => partition.map(item => { val line = item.value() val arr = line.split("\t") val uid = arr(0) //用户id val courseid = arr(1) //课程id val pointid = arr(2) //知识点id val questionid = arr(3) //题目id val istrue = arr(4) //是否正确 val createtime = arr(5) //创建时间 (uid, courseid, pointid, questionid, istrue, createtime) })) dsStream.foreachRDD(rdd => { //获取相同用户 同一课程 同一知识点的数据 val groupRdd = rdd.groupBy(item => item._1 + "-" + item._2 + "-" + item._3) groupRdd.foreachPartition(partition => { //在分区下获取jdbc连接 val sqlProxy = new SqlProxy() val client = DataSourceUtil.getConnection try { partition.foreach { case (key, iters) => qzQuestionUpdate(key, iters, sqlProxy, client) //对题库进行更新操作 } } catch { case e: Exception => e.printStackTrace() } finally { sqlProxy.shutdown(client) } } ) }) //处理完 业务逻辑后 手动提交offset维护到本地 mysql中 stream.foreachRDD(rdd => { val sqlProxy = new SqlProxy() val client = DataSourceUtil.getConnection try { val offsetRanges: Array[OffsetRange] = rdd.asInstanceOf[HasOffsetRanges].offsetRanges for (or <- offsetRanges) { sqlProxy.executeUpdate(client, "replace into `offset_manager` (groupid,topic,`partition`,untilOffset) values(?,?,?,?)", Array(groupid, or.topic, or.partition.toString, or.untilOffset)) } } catch { case e: Exception => e.printStackTrace() } finally { sqlProxy.shutdown(client) } }) ssc.start() ssc.awaitTermination() }
/** * 对题目表进行更新操作 * * @param key * @param iters * @param sqlProxy * @param client * @return */ def qzQuestionUpdate(key: String, iters: Iterable[(String, String, String, String, String, String)], sqlProxy: SqlProxy, client: Connection) = { val keys = key.split("-") val userid = keys(0).toInt val courseid = keys(1).toInt val pointid = keys(2).toInt val array = iters.toArray val questionids = array.map(_._4).distinct //对当前批次的数据下questionid 去重 //查询历史数据下的 questionid var questionids_history: Array[String] = Array() sqlProxy.executeQuery(client, "select questionids from qz_point_history where userid=? and courseid=? and pointid=?", Array(userid, courseid, pointid), new QueryCallback { override def process(rs: ResultSet): Unit = { while (rs.next()) { questionids_history = rs.getString(1).split(",") } rs.close() //关闭游标 } }) //获取到历史数据后再与当前数据进行拼接 去重 val resultQuestionid = questionids.union(questionids_history).distinct val countSize = resultQuestionid.length val resultQuestionid_str = resultQuestionid.mkString(",") val qz_count = questionids.length //去重后的题个数 var qz_sum = array.length //获取当前批次题总数 var qz_istrue = array.filter(_._5.equals("1")).size //获取当前批次做正确的题个数 val createtime = array.map(_._6).min //获取最早的创建时间 作为表中创建时间 //更新qz_point_set 记录表 此表用于存当前用户做过的questionid表 val updatetime = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss").format(LocalDateTime.now()) sqlProxy.executeUpdate(client, "insert into qz_point_history(userid,courseid,pointid,questionids,createtime,updatetime) values(?,?,?,?,?,?) " + " on duplicate key update questionids=?,updatetime=?", Array(userid, courseid, pointid, resultQuestionid_str, createtime, createtime, resultQuestionid_str, updatetime))
var qzSum_history = 0 var istrue_history = 0 sqlProxy.executeQuery(client, "select qz_sum,qz_istrue from qz_point_detail where userid=? and courseid=? and pointid=?", Array(userid, courseid, pointid), new QueryCallback { override def process(rs: ResultSet): Unit = { while (rs.next()) { qzSum_history += rs.getInt(1) istrue_history += rs.getInt(2) } rs.close() } }) qz_sum += qzSum_history qz_istrue += istrue_history val correct_rate = qz_istrue.toDouble / qz_sum.toDouble //计算正确率 //计算完成率 //假设每个知识点下一共有30道题 先计算题的做题情况 再计知识点掌握度 val qz_detail_rate = countSize.toDouble / 30 //算出做题情况乘以 正确率 得出完成率 假如30道题都做了那么正确率等于 知识点掌握度 val mastery_rate = qz_detail_rate * correct_rate sqlProxy.executeUpdate(client, "insert into qz_point_detail(userid,courseid,pointid,qz_sum,qz_count,qz_istrue,correct_rate,mastery_rate,createtime,updatetime)" + " values(?,?,?,?,?,?,?,?,?,?) on duplicate key update qz_sum=?,qz_count=?,qz_istrue=?,correct_rate=?,mastery_rate=?,updatetime=?", Array(userid, courseid, pointid, qz_sum, countSize, qz_istrue, correct_rate, mastery_rate, createtime, updatetime, qz_sum, countSize, qz_istrue, correct_rate, mastery_rate, updatetime))
}}
5.8实时统计商品页到订单页,订单页到支付页转换率package com.atguigu.qzpoint.streaming
import java.langimport java.sql.{Connection, ResultSet}import java.text.NumberFormat
import com.atguigu.qzpoint.util.{DataSourceUtil, ParseJsonData, QueryCallback, SqlProxy}import org.apache.kafka.clients.consumer.ConsumerRecordimport org.apache.kafka.common.TopicPartitionimport org.apache.kafka.common.serialization.StringDeserializerimport org.apache.spark.streaming.dstream.InputDStreamimport org.apache.spark.streaming.kafka010._import org.apache.spark.streaming.{Seconds, StreamingContext}import org.apache.spark.{SparkConf, SparkFiles}import org.lionsoul.ip2region.{DbConfig, DbSearcher}
import scala.collection.mutableimport scala.collection.mutable.ArrayBuffer
/** * 页面转换率实时统计 */object PageStreaming { private val groupid = "vip_count_groupid"
def main(args: Array[String]): Unit = { val conf = new SparkConf().setAppName(this.getClass.getSimpleName).setMaster("local[*]") .set("spark.streaming.kafka.maxRatePerPartition", "30") .set("spark.streaming.stopGracefullyOnShutdown", "true") val ssc = new StreamingContext(conf, Seconds(3)) val topics = Array("page_topic") val kafkaMap: Map[String, Object] = Map[String, Object]( "bootstrap.servers" -> "hadoop102:9092,hadoop103:9092,hadoop104:9092", "key.deserializer" -> classOf[StringDeserializer], "value.deserializer" -> classOf[StringDeserializer], "group.id" -> groupid, "auto.offset.reset" -> "earliest", "enable.auto.commit" -> (false: lang.Boolean) ) //查询mysql中是否存在偏移量 val sqlProxy = new SqlProxy() val offsetMap = new mutable.HashMap[TopicPartition, Long]() val client = DataSourceUtil.getConnection try { sqlProxy.executeQuery(client, "select *from `offset_manager` where groupid=?", Array(groupid), new QueryCallback { override def process(rs: ResultSet): Unit = { while (rs.next()) { val model = new TopicPartition(rs.getString(2), rs.getInt(3)) val offset = rs.getLong(4) offsetMap.put(model, offset) } rs.close() } }) } catch { case e: Exception => e.printStackTrace() } finally { sqlProxy.shutdown(client) }
//设置kafka消费数据的参数 判断本地是否有偏移量 有则根据偏移量继续消费 无则重新消费 val stream: InputDStream[ConsumerRecord[String, String]] = if (offsetMap.isEmpty) { KafkaUtils.createDirectStream( ssc, LocationStrategies.PreferConsistent, ConsumerStrategies.Subscribe[String, String](topics, kafkaMap)) } else { KafkaUtils.createDirectStream( ssc, LocationStrategies.PreferConsistent, ConsumerStrategies.Subscribe[String, String](topics, kafkaMap, offsetMap)) } //解析json数据 val dsStream = stream.map(item => item.value()).mapPartitions(partition => { partition.map(item => { val jsonObject = ParseJsonData.getJsonData(item) val uid = if (jsonObject.containsKey("uid")) jsonObject.getString("uid") else "" val app_id = if (jsonObject.containsKey("app_id")) jsonObject.getString("app_id") else "" val device_id = if (jsonObject.containsKey("device_id")) jsonObject.getString("device_id") else "" val ip = if (jsonObject.containsKey("ip")) jsonObject.getString("ip") else "" val last_page_id = if (jsonObject.containsKey("last_page_id")) jsonObject.getString("last_page_id") else "" val pageid = if (jsonObject.containsKey("page_id")) jsonObject.getString("page_id") else "" val next_page_id = if (jsonObject.containsKey("next_page_id")) jsonObject.getString("next_page_id") else "" (uid, app_id, device_id, ip, last_page_id, pageid, next_page_id) }) }).filter(item => { !item._5.equals("") && !item._6.equals("") && !item._7.equals("") }) dsStream.cache() val pageValueDStream = dsStream.map(item => (item._5 + "_" + item._6 + "_" + item._7, 1)) val resultDStream = pageValueDStream.reduceByKey(_ + _) resultDStream.foreachRDD(rdd => { rdd.foreachPartition(partition => { //在分区下获取jdbc连接 val sqlProxy = new SqlProxy() val client = DataSourceUtil.getConnection try { partition.foreach(item => { calcPageJumpCount(sqlProxy, item, client) //计算页面跳转个数 }) } catch { case e: Exception => e.printStackTrace() } finally { sqlProxy.shutdown(client) } }) })
ssc.sparkContext.addFile(this.getClass.getResource("/ip2region.db").getPath) //广播文件 val ipDStream = dsStream.mapPartitions(patitions => { val dbFile = SparkFiles.get("ip2region.db") val ipsearch = new DbSearcher(new DbConfig(), dbFile) patitions.map { item => val ip = item._4 val province = ipsearch.memorySearch(ip).getRegion().split("\\|")(2) //获取ip详情 中国|0|上海|上海市|有线通 (province, 1l) //根据省份 统计点击个数 } }).reduceByKey(_ + _)
ipDStream.foreachRDD(rdd => { //查询mysql历史数据 转成rdd val ipSqlProxy = new SqlProxy() val ipClient = DataSourceUtil.getConnection try { val history_data = new ArrayBuffer[(String, Long)]() ipSqlProxy.executeQuery(ipClient, "select province,num from tmp_city_num_detail", null, new QueryCallback { override def process(rs: ResultSet): Unit = { while (rs.next()) { val tuple = (rs.getString(1), rs.getLong(2)) history_data += tuple } } }) val history_rdd = ssc.sparkContext.makeRDD(history_data) val resultRdd = history_rdd.fullOuterJoin(rdd).map(item => { val province = item._1 val nums = item._2._1.getOrElse(0l) + item._2._2.getOrElse(0l) (province, nums) }) resultRdd.foreachPartition(partitions => { val sqlProxy = new SqlProxy() val client = DataSourceUtil.getConnection try { partitions.foreach(item => { val province = item._1 val num = item._2 //修改mysql数据 并重组返回最新结果数据 sqlProxy.executeUpdate(client, "insert into tmp_city_num_detail(province,num)values(?,?) on duplicate key update num=?", Array(province, num, num)) }) } catch { case e: Exception => e.printStackTrace() } finally { sqlProxy.shutdown(client) } }) val top3Rdd = resultRdd.sortBy[Long](_._2, false).take(3) sqlProxy.executeUpdate(ipClient, "truncate table top_city_num", null) top3Rdd.foreach(item => { sqlProxy.executeUpdate(ipClient, "insert into top_city_num (province,num) values(?,?)", Array(item._1, item._2)) }) } catch { case e: Exception => e.printStackTrace() } finally { sqlProxy.shutdown(ipClient) } })
//计算转换率 //处理完 业务逻辑后 手动提交offset维护到本地 mysql中 stream.foreachRDD(rdd => { val sqlProxy = new SqlProxy() val client = DataSourceUtil.getConnection try { calcJumRate(sqlProxy, client) //计算转换率 val offsetRanges: Array[OffsetRange] = rdd.asInstanceOf[HasOffsetRanges].offsetRanges for (or <- offsetRanges) { sqlProxy.executeUpdate(client, "replace into `offset_manager` (groupid,topic,`partition`,untilOffset) values(?,?,?,?)", Array(groupid, or.topic, or.partition.toString, or.untilOffset)) } } catch { case e: Exception => e.printStackTrace() } finally { sqlProxy.shutdown(client) } }) ssc.start() ssc.awaitTermination() }
/** * 计算页面跳转个数 * * @param sqlProxy * @param item * @param client */ def calcPageJumpCount(sqlProxy: SqlProxy, item: (String, Int), client: Connection): Unit = { val keys = item._1.split("_") var num: Long = item._2 val page_id = keys(1).toInt //获取当前page_id val last_page_id = keys(0).toInt //获取上一page_id val next_page_id = keys(2).toInt //获取下页面page_id //查询当前page_id的历史num个数 sqlProxy.executeQuery(client, "select num from page_jump_rate where page_id=?", Array(page_id), new QueryCallback { override def process(rs: ResultSet): Unit = { while (rs.next()) { num += rs.getLong(1) } rs.close() }
//对num 进行修改 并且判断当前page_id是否为首页 if (page_id == 1) { sqlProxy.executeUpdate(client, "insert into page_jump_rate(last_page_id,page_id,next_page_id,num,jump_rate)" + "values(?,?,?,?,?) on duplicate key update num=num+?", Array(last_page_id, page_id, next_page_id, num, "100%", num)) } else { sqlProxy.executeUpdate(client, "insert into page_jump_rate(last_page_id,page_id,next_page_id,num)" + "values(?,?,?,?) on duplicate key update num=num+?", Array(last_page_id, page_id, next_page_id, num, num)) } }) }
/** * 计算转换率 */ def calcJumRate(sqlProxy: SqlProxy, client: Connection): Unit = { var page1_num = 0l var page2_num = 0l var page3_num = 0l sqlProxy.executeQuery(client, "select num from page_jump_rate where page_id=?", Array(1), new QueryCallback { override def process(rs: ResultSet): Unit = { while (rs.next()) { page1_num = rs.getLong(1) } } }) sqlProxy.executeQuery(client, "select num from page_jump_rate where page_id=?", Array(2), new QueryCallback { override def process(rs: ResultSet): Unit = { while (rs.next()) { page2_num = rs.getLong(1) } } }) sqlProxy.executeQuery(client, "select num from page_jump_rate where page_id=?", Array(3), new QueryCallback { override def process(rs: ResultSet): Unit = { while (rs.next()) { page3_num = rs.getLong(1) } } }) val nf = NumberFormat.getPercentInstance val page1ToPage2Rate = if (page1_num == 0) "0%" else nf.format(page2_num.toDouble / page1_num.toDouble) val page2ToPage3Rate = if (page2_num == 0) "0%" else nf.format(page3_num.toDouble / page2_num.toDouble) sqlProxy.executeUpdate(client, "update page_jump_rate set jump_rate=? where page_id=?", Array(page1ToPage2Rate, 2)) sqlProxy.executeUpdate(client, "update page_jump_rate set jump_rate=? where page_id=?", Array(page2ToPage3Rate, 3)) }
}
5.9实时统计学员播放视频各时长package com.atguigu.qzpoint.streaming
import java.langimport java.sql.{Connection, ResultSet}
import com.atguigu.qzpoint.bean.LearnModelimport com.atguigu.qzpoint.util.{DataSourceUtil, ParseJsonData, QueryCallback, SqlProxy}import org.apache.kafka.clients.consumer.ConsumerRecordimport org.apache.kafka.common.TopicPartitionimport org.apache.kafka.common.serialization.StringDeserializerimport org.apache.spark.SparkConfimport org.apache.spark.streaming.dstream.InputDStreamimport org.apache.spark.streaming.kafka010._import org.apache.spark.streaming.{Seconds, StreamingContext}
import scala.collection.mutableimport scala.collection.mutable.ArrayBuffer
object CourseLearnStreaming { private val groupid = "course_learn_test1"
def main(args: Array[String]): Unit = { val conf = new SparkConf().setAppName(this.getClass.getSimpleName) .set("spark.streaming.kafka.maxRatePerPartition", "30") .set("spark.streaming.stopGracefullyOnShutdown", "true")
val ssc = new StreamingContext(conf, Seconds(3)) val topics = Array("course_learn") val kafkaMap: Map[String, Object] = Map[String, Object]( "bootstrap.servers" -> "hadoop102:9092,hadoop103:9092,hadoop104:9092", "key.deserializer" -> classOf[StringDeserializer], "value.deserializer" -> classOf[StringDeserializer], "group.id" -> groupid, "auto.offset.reset" -> "earliest", "enable.auto.commit" -> (false: lang.Boolean) ) //查询mysql是否存在偏移量 val sqlProxy = new SqlProxy() val offsetMap = new mutable.HashMap[TopicPartition, Long]() val client = DataSourceUtil.getConnection try { sqlProxy.executeQuery(client, "select *from `offset_manager` where groupid=?", Array(groupid), new QueryCallback { override def process(rs: ResultSet): Unit = { while (rs.next()) { val model = new TopicPartition(rs.getString(2), rs.getInt(3)) val offset = rs.getLong(4) offsetMap.put(model, offset) } rs.close() } }) } catch { case e: Exception => e.printStackTrace() } finally { sqlProxy.shutdown(client) } //设置kafka消费数据的参数 判断本地是否有偏移量 有则根据偏移量继续消费 无则重新消费 val stream: InputDStream[ConsumerRecord[String, String]] = if (offsetMap.isEmpty) { KafkaUtils.createDirectStream( ssc, LocationStrategies.PreferConsistent, ConsumerStrategies.Subscribe[String, String](topics, kafkaMap)) } else { KafkaUtils.createDirectStream( ssc, LocationStrategies.PreferConsistent, ConsumerStrategies.Subscribe[String, String](topics, kafkaMap, offsetMap)) }
//解析json数据 val dsStream = stream.mapPartitions(partitions => { partitions.map(item => { val json = item.value() val jsonObject = ParseJsonData.getJsonData(json) val userId = jsonObject.getIntValue("uid") val cwareid = jsonObject.getIntValue("cwareid") val videoId = jsonObject.getIntValue("videoid") val chapterId = jsonObject.getIntValue("chapterid") val edutypeId = jsonObject.getIntValue("edutypeid") val subjectId = jsonObject.getIntValue("subjectid") val sourceType = jsonObject.getString("sourceType") val speed = jsonObject.getIntValue("speed") val ts = jsonObject.getLong("ts") val te = jsonObject.getLong("te") val ps = jsonObject.getIntValue("ps") val pe = jsonObject.getIntValue("pe") LearnModel(userId, cwareid, videoId, chapterId, edutypeId, subjectId, sourceType, speed, ts, te, ps, pe) }) })
dsStream.foreachRDD(rdd => { rdd.cache() //统计播放视频 有效时长 完成时长 总时长 rdd.groupBy(item => item.userId + "_" + item.cwareId + "_" + item.videoId).foreachPartition(partitoins => { val sqlProxy = new SqlProxy() val client = DataSourceUtil.getConnection try { partitoins.foreach { case (key, iters) => calcVideoTime(key, iters, sqlProxy, client) //计算视频时长 } } catch { case e: Exception => e.printStackTrace() } finally { sqlProxy.shutdown(client) } }) //统计章节下视频播放总时长 rdd.mapPartitions(partitions => { partitions.map(item => { val totaltime = Math.ceil((item.te - item.ts) / 1000).toLong val key = item.chapterId (key, totaltime) }) }).reduceByKey(_ + _) .foreachPartition(partitoins => { val sqlProxy = new SqlProxy() val client = DataSourceUtil.getConnection try { partitoins.foreach(item => { sqlProxy.executeUpdate(client, "insert into chapter_learn_detail(chapterid,totaltime) values(?,?) on duplicate key" + " update totaltime=totaltime+?", Array(item._1, item._2, item._2)) }) } catch { case e: Exception => e.printStackTrace() } finally { sqlProxy.shutdown(client) } })
//统计课件下的总播放时长 rdd.mapPartitions(partitions => { partitions.map(item => { val totaltime = Math.ceil((item.te - item.ts) / 1000).toLong val key = item.cwareId (key, totaltime) }) }).reduceByKey(_ + _).foreachPartition(partitions => { val sqlProxy = new SqlProxy() val client = DataSourceUtil.getConnection try { partitions.foreach(item => { sqlProxy.executeUpdate(client, "insert into cwareid_learn_detail(cwareid,totaltime) values(?,?) on duplicate key " + "update totaltime=totaltime+?", Array(item._1, item._2, item._2)) }) } catch { case e: Exception => e.printStackTrace() } finally { sqlProxy.shutdown(client) } })
//统计辅导下的总播放时长 rdd.mapPartitions(partitions => { partitions.map(item => { val totaltime = Math.ceil((item.te - item.ts) / 1000).toLong val key = item.edutypeId (key, totaltime) }) }).reduceByKey(_ + _).foreachPartition(partitions => { val sqlProxy = new SqlProxy() val client = DataSourceUtil.getConnection try { partitions.foreach(item => { sqlProxy.executeUpdate(client, "insert into edutype_learn_detail(edutypeid,totaltime) values(?,?) on duplicate key " + "update totaltime=totaltime+?", Array(item._1, item._2, item._2)) }) } catch { case e: Exception => e.printStackTrace() } finally { sqlProxy.shutdown(client) } })
//统计同一资源平台下的总播放时长 rdd.mapPartitions(partitions => { partitions.map(item => { val totaltime = Math.ceil((item.te - item.ts) / 1000).toLong val key = item.sourceType (key, totaltime) }) }).reduceByKey(_ + _).foreachPartition(partitions => { val sqlProxy = new SqlProxy() val client = DataSourceUtil.getConnection try { partitions.foreach(item => { sqlProxy.executeUpdate(client, "insert into sourcetype_learn_detail (sourcetype_learn,totaltime) values(?,?) on duplicate key " + "update totaltime=totaltime+?", Array(item._1, item._2, item._2)) }) } catch { case e: Exception => e.printStackTrace() } finally { sqlProxy.shutdown(client) } }) // 统计同一科目下的播放总时长 rdd.mapPartitions(partitions => { partitions.map(item => { val totaltime = Math.ceil((item.te - item.ts) / 1000).toLong val key = item.subjectId (key, totaltime) }) }).reduceByKey(_ + _).foreachPartition(partitons => { val sqlProxy = new SqlProxy() val clinet = DataSourceUtil.getConnection try { partitons.foreach(item => { sqlProxy.executeUpdate(clinet, "insert into subject_learn_detail(subjectid,totaltime) values(?,?) on duplicate key " + "update totaltime=totaltime+?", Array(item._1, item._2, item._2)) }) } catch { case e: Exception => e.printStackTrace() } finally { sqlProxy.shutdown(clinet) } })
}) //计算转换率 //处理完 业务逻辑后 手动提交offset维护到本地 mysql中 stream.foreachRDD(rdd => { val sqlProxy = new SqlProxy() val client = DataSourceUtil.getConnection try { val offsetRanges: Array[OffsetRange] = rdd.asInstanceOf[HasOffsetRanges].offsetRanges for (or <- offsetRanges) { sqlProxy.executeUpdate(client, "replace into `offset_manager` (groupid,topic,`partition`,untilOffset) values(?,?,?,?)", Array(groupid, or.topic, or.partition.toString, or.untilOffset)) } } catch { case e: Exception => e.printStackTrace() } finally { sqlProxy.shutdown(client) } }) ssc.start() ssc.awaitTermination() }
/** * 计算视频 有效时长 完成时长 总时长 * * @param key * @param iters * @param sqlProxy * @param client */ def calcVideoTime(key: String, iters: Iterable[LearnModel], sqlProxy: SqlProxy, client: Connection) = { val keys = key.split("_") val userId = keys(0).toInt val cwareId = keys(1).toInt val videoId = keys(2).toInt //查询历史数据 var interval_history = "" sqlProxy.executeQuery(client, "select play_interval from video_interval where userid=? and cwareid=? and videoid=?", Array(userId, cwareId, videoId), new QueryCallback { override def process(rs: ResultSet): Unit = { while (rs.next()) { interval_history = rs.getString(1) } rs.close() } }) var effective_duration_sum = 0l //有效总时长 var complete_duration_sum = 0l //完成总时长 var cumulative_duration_sum = 0l //播放总时长 val learnList = iters.toList.sortBy(item => item.ps) //转成list 并根据开始区间升序排序 learnList.foreach(item => { if ("".equals(interval_history)) { //没有历史区间 val play_interval = item.ps + "-" + item.pe //有效区间 val effective_duration = Math.ceil((item.te - item.ts) / 1000) //有效时长 val complete_duration = item.pe - item.ps //完成时长 effective_duration_sum += effective_duration.toLong cumulative_duration_sum += effective_duration.toLong complete_duration_sum += complete_duration interval_history = play_interval } else { //有历史区间进行对比 val interval_arry = interval_history.split(",").sortBy(a => (a.split("-")(0).toInt, a.split("-")(1).toInt)) val tuple = getEffectiveInterval(interval_arry, item.ps, item.pe) val complete_duration = tuple._1 //获取实际有效完成时长 val effective_duration = Math.ceil((item.te - item.ts) / 1000) / (item.pe - item.ps) * complete_duration //计算有效时长 val cumulative_duration = Math.ceil((item.te - item.ts) / 1000) //累计时长 interval_history = tuple._2 effective_duration_sum += effective_duration.toLong complete_duration_sum += complete_duration cumulative_duration_sum += cumulative_duration.toLong } sqlProxy.executeUpdate(client, "insert into video_interval(userid,cwareid,videoid,play_interval) values(?,?,?,?) " + "on duplicate key update play_interval=?", Array(userId, cwareId, videoId, interval_history, interval_history)) sqlProxy.executeUpdate(client, "insert into video_learn_detail(userid,cwareid,videoid,totaltime,effecttime,completetime) " + "values(?,?,?,?,?,?) on duplicate key update totaltime=totaltime+?,effecttime=effecttime+?,completetime=completetime+?", Array(userId, cwareId, videoId, cumulative_duration_sum, effective_duration_sum, complete_duration_sum, cumulative_duration_sum, effective_duration_sum, complete_duration_sum)) }) }
/** * 计算有效区间 * * @param array * @param start * @param end * @return */ def getEffectiveInterval(array: Array[String], start: Int, end: Int) = { var effective_duration = end - start var bl = false //是否对有效时间进行修改 import scala.util.control.Breaks._ breakable { for (i <- 0 until array.length) { //循环各区间段 var historyStart = 0 //获取其中一段的开始播放区间 var historyEnd = 0 //获取其中一段结束播放区间 val item = array(i) try { historyStart = item.split("-")(0).toInt historyEnd = item.split("-")(1).toInt } catch { case e: Exception => throw new Exception("error array:" + array.mkString(",")) } if (start >= historyStart && historyEnd >= end) { //已有数据占用全部播放时长 此次播放无效 effective_duration = 0 bl = true break() } else if (start <= historyStart && end > historyStart && end < historyEnd) { //和已有数据左侧存在交集 扣除部分有效时间(以老数据为主进行对照) effective_duration -= end - historyStart array(i) = start + "-" + historyEnd bl = true } else if (start > historyStart && start < historyEnd && end >= historyEnd) { //和已有数据右侧存在交集 扣除部分有效时间 effective_duration -= historyEnd - start array(i) = historyStart + "-" + end bl = true } else if (start < historyStart && end > historyEnd) { //现数据 大于旧数据 扣除旧数据所有有效时间 effective_duration -= historyEnd - historyStart array(i) = start + "-" + end bl = true } } } val result = bl match { case false => { //没有修改原array 没有交集 进行新增 val distinctArray2 = ArrayBuffer[String]() distinctArray2.appendAll(array) distinctArray2.append(start + "-" + end) val distinctArray = distinctArray2.distinct.sortBy(a => (a.split("-")(0).toInt, a.split("-")(1).toInt)) val tmpArray = ArrayBuffer[String]() tmpArray.append(distinctArray(0)) for (i <- 1 until distinctArray.length) { val item = distinctArray(i).split("-") val tmpItem = tmpArray(tmpArray.length - 1).split("-") val itemStart = item(0) val itemEnd = item(1) val tmpItemStart = tmpItem(0) val tmpItemEnd = tmpItem(1) if (tmpItemStart.toInt < itemStart.toInt && tmpItemEnd.toInt < itemStart.toInt) { //没有交集 tmpArray.append(itemStart + "-" + itemEnd) } else { //有交集 val resultStart = tmpItemStart val resultEnd = if (tmpItemEnd.toInt > itemEnd.toInt) tmpItemEnd else itemEnd tmpArray(tmpArray.length - 1) = resultStart + "-" + resultEnd } } val play_interval = tmpArray.sortBy(a => (a.split("-")(0).toInt, a.split("-")(1).toInt)).mkString(",") play_interval } case true => { //修改了原array 进行区间重组 val distinctArray = array.distinct.sortBy(a => (a.split("-")(0).toInt, a.split("-")(1).toInt)) val tmpArray = ArrayBuffer[String]() tmpArray.append(distinctArray(0)) for (i <- 1 until distinctArray.length) { val item = distinctArray(i).split("-") val tmpItem = tmpArray(tmpArray.length - 1).split("-") val itemStart = item(0) val itemEnd = item(1) val tmpItemStart = tmpItem(0) val tmpItemEnd = tmpItem(1) if (tmpItemStart.toInt < itemStart.toInt && tmpItemEnd.toInt < itemStart.toInt) { //没有交集 tmpArray.append(itemStart + "-" + itemEnd) } else { //有交集 val resultStart = tmpItemStart val resultEnd = if (tmpItemEnd.toInt > itemEnd.toInt) tmpItemEnd else itemEnd tmpArray(tmpArray.length - 1) = resultStart + "-" + resultEnd } } val play_interval = tmpArray.sortBy(a => (a.split("-")(0).toInt, a.split("-")(1).toInt)).mkString(",") play_interval } } (effective_duration, result) }}
第6章 总结与调优6.1保证Spark Streaming第一次启动不丢数据在kafka的参数auto.offset.rest设定为earlist,保证Spark Streaming第一次启动从kafka最早偏移量开始拉取数据

6.2 Spark Streaming手动维护偏移量

在Spark Streaming下有三种消费模式的定义 最多一次、至少一次、恰好一次那么最好是无限接近恰好一次。要实现恰好一次偏移量必须手动维护,因为自动提交会在Spark Streaming刚运行时就立马提交offset,如果这个时候Spark Streaming消费信息失败了,那么offset也就错误提交了。所以必须保证:1.手动维护偏移量2.处理完业务数据后再提交offset手动维护偏移量 需设置kafka参数enable.auto.commit改为false

手动维护提交offset有两种选择:1.处理完业务数据后手动提交到Kafka2.处理完业务数据后手动提交到本地库 如MySql、HBase
1、先来看如何提交到kafka 官网所示:

stream.foreachRdd后根据每个rdd先转换成HashOffsetRanges对象通过.offsetRanges方法获取到偏移量对象,再通过commitAsync方法将偏移量提交。
2、维护到本地MySql 如项目所示:Driver端需先去判断Msql库中是否存在偏移量,如果存在偏移量则从MySql中获取到当前topic对应的最新offset大小,如果MySql不存在则从kafka中获取


消费到数据后,进行业务处理处理完后需将offset最新值保存到MySql

那么如果有面试官提问如何保证数据恰好一次性消费回答到这两点一般就可以了,手动维护便宜量和先处理完业务数据再提交offset。但是处理业务数据和提交offset并非同一事物,在极端情况下如提交offset时断网断电还是会导致offset没有提交并且业务数据已处理完的情况。
那么保证事物就需要将并行度调成1或者将数据collect到driver端,再进行数据业务处理和提交offset,但这样还会导致并行度变成1很可能导致处理速度跟不上,所以大数据情况下一般不考虑事物。
6.3 updateStateByKey算子与checkpoint

updateStateBykey算子根据官网描述,是返回一个新的“状态”的DStream的算子,其通过在键的先前状态和键的新值上应用给定函数更新每个键的状态。

具体写法:根据历史状态值,和当前批次的数据状态值的累加操作 得出一个最新的结果。如项目中代码:

那么使用updateStateByBykey算子,必须使用Spark Streaming的checkpoint来维护历史状态数据
Spark on Yarn模式是分布式处理数据的,那么为了让所有executor都能访问到state历史状态数据,必须将state状态数据维护在Hdfs上,如项目上所指定目录:

那么看下Hdfs上路径下的文件

存在小文件且小文件个数不可控,所以在真实企业生产环境上并不会使用checkpoint操作,也不会使用基于checkpoint的算子如updateStateBykey算子
那么如何代替updateStateBykey这种基于历史数据状态的操作的算子呢:在进行相应操作时,可以去库中查询出历史数据,再与当前数据进行操作得出最新结果集,将结果集再刷新到本地库中。
6.4计算Spark Streaming一秒钟拉取多少条数据在企业中往往会根据业务的实时性来定制一秒钟消费数据量的条数,来达到实时性,那么通过什么参数来设置Spark Streaming从kafka的拉取的条数呢。

根据官网描述,可以设置spark.streaming.kafka.maxRatePerPartition参数来设置Spark Streaming从kafka分区每秒拉取的条数
那么在项目中如 实时统计学员做题正确率与知识点掌握度需求中,需要每秒100处理速度,针对此需求topic为qz_log 分区为10,那么通过此参数设定10即可,每个分区没秒10条数据。一秒处理100条数据,当前批次为3秒一次,一批处理300条数据.


6.5 Spark Streaming背压机制
根据官网描述 Spark Streaming背压机制 使Spark Streaming能够根据当前的批处理调度延迟和处理时间来动态控制接收速率,以便系统只接收系统可以处理的速度。背压机制的上限速率由spark.streaming.kafka.maxRatePerPartition 控制,所以生产环境中往往会两个参数一起使用。


6.6一个stage的耗时由什么决定



由上图可以看出一个stage由最慢的task耗时决定。6.7 Spark Streaming优雅关闭提交Spark Streaming任务到yarn后,当需要停止程序时使用 yarn application -kill application_id 命令来关闭Spark Streaming ,那么操作此命令时需要保证数据不丢失,需要设置spark.streaming.stopGracefullOnShutdown参数为ture

当设置此参数后,Spark Streaming程序在接收到kill命令时,不会立马结束程序,Spark会在JVM关闭时正常关闭Spark Streaming,而不是是立马关闭,即保证当前数据处理完后再关闭。
6.8 Spark Streaming默认分区数Spark Streaming默认并行度与所对应kafka topic创建时的分区数所对应,比如项目中topic的分区都是10,Spark Streaming的默认分区就为10,且在真实开发环境中Spark Streaming一般不会去使用repartition增大分区操作,因为会进行shuffle耗时。第7章 打包、spark-submit命令


spark-submit --master yarn --deploy-mode client --driver-memory 1g --num-executors 2 --executor-cores 2 --executor-memory 2g --class com.atguigu.qzpoint.streaming.CourseLearnStreaming com_atguigu_sparkstreaming-1.0-SNAPSHOT-jar-with-dependencies.jar
spark-submit --master yarn --deploy-mode client --driver-memory 1g --num-executors 2 --executor-cores 2 --executor-memory 2g --class com.atguigu.qzpoint.streaming.PageStreaming com_atguigu_sparkstreaming-1.0-SNAPSHOT-jar-with-dependencies.jar
spark-submit --master yarn --deploy-mode client --driver-memory 1g --num-executors 2 --executor-cores 2 --executor-memory 2g --class com.atguigu.qzpoint.streaming.QzPointStreaming com_atguigu_sparkstreaming-1.0-SNAPSHOT-jar-with-dependencies.jar
spark-submit --master yarn --deploy-mode client --driver-memory 1g --num-executors 2 --executor-cores 2 --executor-memory 2g --class com.atguigu.qzpoint.streaming.RegisterStreaming com_atguigu_sparkstreaming-1.0-SNAPSHOT-jar-with-dependencies.jar
第8章 常见问题8.1 jar包冲突问题

根据官网描述spark-streaming-kafka-0-10_2.11jar包中包含kafka-clients客户端jar包不需要再次添加kafka客户端jar包,如果再次添加kafka客户端jar包可能会引起版本冲突8.2无法序列化问题和正确操作数据库连接

对于开发者人员刚开始接手Spark Streaming时往往会错误的使用数据库连接,如上述官网描述对于connection获取,代码写在了foreachRDD内rdd.foreach上,那么这样操作实际是在driver端创建到connection,然后rdd.foreacher操作为分布式节点操作,connection.send方法实际发生在了各个executor节点上,这个时候就涉及到了driver端对象到executor端的一个网络传输问题,这个时候spark会发生错误,会报一个org.apache.spark.SparkException:Task not serializable 这样一个任务无法序列化的错,在Spark中遇到此错误一般都是错误的将driver端对象在executor端使用造成的。 那么创建connection操作必须在executor端执行

如官网描述,在rdd.foreach里创建connection,这样虽然不会发生错误,但是这样循环的粒度是针对每条数据,每循环一条数据都会创建一个连接,这样会造成资源浪费。图1和图2都是错误展示最后,正确的使用数据库连接,循环粒度是分区,在每个分区下创建一个数据库连接,循环分区下的数据每条数据使用当前分区下的数据库连接,当使用完毕后归还的连接池中。所以在Spark Streaming开发中需养成良好习惯:dstream.foreachRdd{rdd=>{ rdd.foreachPartition{partitions=>{ //循环分区//创建connection partitions.foreach(record=>{ //业务处理 使用当前connection }} //归还连接}}循环粒度 foreachRdd => foreachPartition => foreach8.3 Spark Streaming操作数据库时线程安全问题在Spark Streaming中,采用查询本地库的历史数据和当前批次数据的计算来代替需要基于hdfs的算子updatestatebykey,那么在查询和重新刷入本地库的时候处理不当会造成线程安全问题,数据不准的问题。

那么在查询本地库时需要进行一次预聚合操作,将相同key的数据落到一个分区,保证同一个key的数据指挥操作数据库一次,预聚合操作有reducebykey、groupbykey、groupby等算子。如项目所写:

题库更新操作时需要查询MySql本地库的历史数据,在查询本地库钱先进行了groupby操作将相同符合条件的业务数据聚合到了一个分区,保证相同用户下同一课程同一知识点的数据在当前批次下只会去查询一次MySql数据库并且一次覆盖。8.4数据倾斜问题数据倾斜为在shuffle过程中,必须将各个节点上相同的key的数据拉取到某节点的一个task来进行,此时如果某个key对应的数据量特别大的话,就会发生数据倾,某个task耗时非常大,那么一个stage的耗时由最慢的task决定,从而导致整个Spark Streaming任务运行非常缓慢。以reducebykey为例:

这张图就是发生了数据倾斜,那么解决方案最有效的为两阶段聚合,先打散key聚合一次,再还原key聚合一次。

具体代码展示:
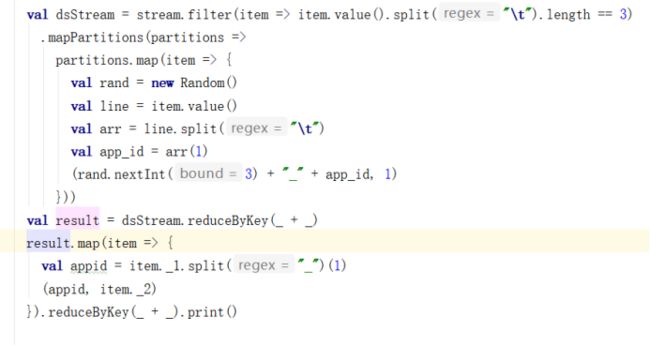
对DStream 进行map操作对原始key前加上随机值,map完后进行第一次reducebykey操作,此结果为打散key后的reducebykey结果,再次进行map操作根据分隔符,去掉随机数保留原有key,map后再进行reducebykey,保证相同key的数据准确累加。
8.5 Spark Streaming消费多topic在真实环境中往往会有许多业务场景非常类似,比如打标签、监控某指标,可能代码逻辑都一样只有某个取值不一样,这个时候一个Spark Streaming就可以监控多个topic,然后根据topic的名称来进行不同的业务处理,就不需要开发多个Spark Streaming程序了。查看kafkaUtils.createDirectStream方法

可以发现topic参数可以是个多个值,也就是createDirectStream方法支持多个topic。
通过kafkaUtils.createDirectStream方法获取到DStream,这个DStream流的类型为InputDStream[ConsumerRecord[String,String]],那么在可以通过调用map方法,ConsumerRecord的topic方法来获取对应的topic名称

获取到topic名称后value数据后,就可以在后续操作里根据判断topic名称来处理不同的业务。
8.6内存泄露内存泄露是指程序中已动态分配的堆内存由于某种原因程序未释放或无法释放,造成系统内存的浪费,导致程序运行速度减慢,甚至系统崩溃等严重后果。在Spark Streaming中往往会因为开发者代码未正确编写导致无法回收或释放对象,造成Spark Streaming内存泄露越跑越慢甚至崩溃的结果。那么排查内存泄露需要一些第三方的工具8.6.1 IBM HeapAnalyzerhttps://www.ibm.com/developerworks/community/groups/service/html/communityview?communityUuid=4544bafe-c7a2-455f-9d43-eb866ea60091官网地址

点击下载 内存泄露分析工具下载下来是一个jar包
那么需要编写bat批处理来运行创建run.bat
编辑title ibm-heap-analyzer
path=%PATH%;%C:\JAVA\jdk1.8.0_51\bin
E:
cd E:\IBM heapAnalyzer\IBM_DUMP_wjfx
java.exe -Xms1048M -Xmx4096M -jar ha456.jar
路径需要改成自己当前路径点击run.bat运行

运行成功8.6.2 模拟内存泄露场景内存泄露的原因往往是因为对象无法释放或被回收造成,那么在本项目中就模拟此场景。


如上图所示,在计算学员知识点正确率与掌握度代码中,在最后提交offset提交偏移量后,循环往map里添加LearnMode对象,使每处理一批数据就往map里添加100000个LearnMode对象,使堆内存撑满。
8.6.3 查找driver进程在集群上提交spark streaming任务ps -ef |grep com.atguigu.qzpoint.streaming.QzPointStreaming 通过此命令查找到driver进程号
![]()
进程号为6860


通过Spark Ui发现该Spark Straming task任务发生长时间卡住现象,GC出现异常。疑似发生内存泄露
8.6.4 JMAP命令 使用jmap -heap pid命令查看6860进程,内存使用情况。 jmap -heap 6860

发现新生代和老年代内存占满,有对象无法被销毁或回收。再通过jmap -histo pid 命令查看对象的内存情况。
jmap -histo 6860 >a.log

jmap -dump:live,format=b,file=dump.log 6860
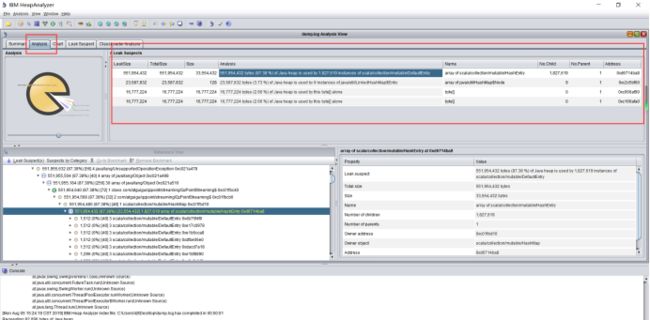
将dump从集群下载下来,打开IBM HeapAnalyzer进行分析



从饼状图可以看出,堆内存中存在大量HashEntry类点击Analysis 分析查看各个对象内存的泄露大小和总大小。
选中最大的分析对象双击,或者右键点击 Find object in a tree view查看树状图。

可以看出HashEntry的父类为HashMap,并且点击HashEntry查看内部,


链表里的next对象为LearnModel

可以定位 Spark Streaming在操作map 添加LearnModel时发生了内存泄露
