Hive_MBY_GJF
一、概述
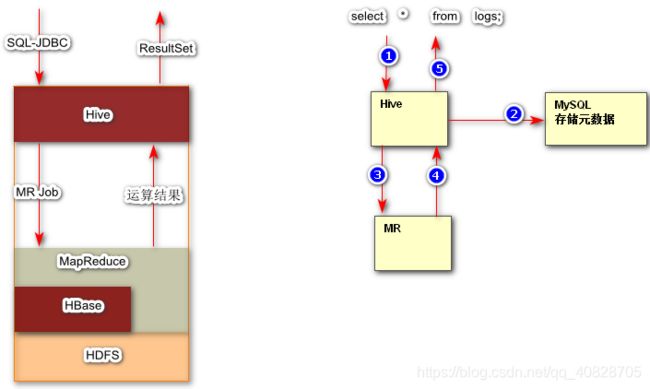
由FaceBook开源用于解决海量结构化日志的数据统计工具。
hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。 其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。
Hive是建立在 Hadoop 上的数据仓库基础构架。它提供了一系列的工具,可以用来进行数据提取转化加载(ETL),这是一种可以存储、查询和分析存储在 Hadoop 中的大规模数据的机制。Hive 定义了简单的类 SQL 查询语言,称为 HQL,它允许熟悉 SQL 的用户查询数据。同时,这个语言也允许熟悉 MapReduce 开发者的开发自定义的 mapper 和 reducer 来处理内建的 mapper 和 reducer 无法完成的复杂的分析工作。
二、Hive安装
2.1 依赖环境
- HDFS和MR就绪
- 需要安装Mysql服务
yum安装mysql:
[root@HadoopNode00 ~]# yum install -y mysql-server
开启mysql的服务:
[root@HadoopNode00 ~]# service mysqld start
Initializing MySQL database: Installing MySQL system tables...
OK
Filling help tables...
OK
To start mysqld at boot time you have to copy
support-files/mysql.server to the right place for your system
PLEASE REMEMBER TO SET A PASSWORD FOR THE MySQL root USER !
To do so, start the server, then issue the following commands:
/usr/bin/mysqladmin -u root password 'new-password'
/usr/bin/mysqladmin -u root -h HadoopNode00 password 'new-password'
Alternatively you can run:
/usr/bin/mysql_secure_installation
which will also give you the option of removing the test
databases and anonymous user created by default. This is
strongly recommended for production servers.
See the manual for more instructions.
You can start the MySQL daemon with:
cd /usr ; /usr/bin/mysqld_safe &
You can test the MySQL daemon with mysql-test-run.pl
cd /usr/mysql-test ; perl mysql-test-run.pl
Please report any problems with the /usr/bin/mysqlbug script!
[ OK ]
Starting mysqld:
#自己的笔记
[root@HadoopNode00 ~]# service mysqld start
Starting mysqld: [ OK ]
[root@HadoopNode00 ~]# mysqladmin -u root password 'root'
#自己的笔记:
[root@HadoopNode00 ~]# mysql -u root -proot #登录mysql数据库
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 13
Server version: 5.1.73 Source distribution
Copyright (c) 2000, 2013, Oracle and/or its affiliates. All rights reserved.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql>
#自己的笔记:
mysql> use mysql
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
#自己的笔记
mysql> delete from user where password = '';
Query OK, 4 rows affected (0.00 sec)
#自己的笔记
mysql> grant all privileges on *.* to 'root'@'%' identified by 'root' with grant option;
Query OK, 0 rows affected (0.00 sec)
#自己的笔记
mysql> flush privileges;
Query OK, 0 rows affected (0.00 sec)
#自己的笔记
mysql> create database hive; #创建数据库
Query OK, 1 row affected (0.00 sec)
#自己的笔记
mysql> show databases; #展示所有的数据库
+--------------------+
| Database |
+--------------------+
| information_schema |
| hive |
| mysql |
| test |
+--------------------+
4 rows in set (0.00 sec)
[root@HadoopNode00 ~]# mysql -u root -p1234 #此处全部改为root
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 3
Server version: 5.1.73 Source distribution
Copyright (c) 2000, 2013, Oracle and/or its affiliates. All rights reserved.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql> use mysql
mysql> delete from user where password = '';
mysql> grant all privileges on *.* to 'root'@'%' identified by 'root' with grant option;
Query OK, 0 rows affected (0.00 sec)
mysql> flush privileges;
Query OK, 0 rows affected (0.00 sec)
mysql> create database hive;
Query OK, 1 row affected (0.00 sec)
2.2 安装配置Hive
[root@HadoopNode00 ~]# mkdir /home/hive # 创建hive文件夹
[root@HadoopNode00 hive]# cd /home/hive/ # 进入到HIve目录
[root@HadoopNode00 hive]# tar -zxvf apache-hive-1.2.1-bin.tar.gz # 解压
[root@HadoopNode00 ~]# vi /home/hive/apache-hive-1.2.1-bin/conf/hive-site.xml
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://192.168.126.10:3306/hive</value> #注意此处
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>1234</value> #注意此处
</property>
</configuration>
2.3 拷贝相关依赖
- 将mysql 的依赖拷贝到/home/hive/apache-hive-1.2.1-bin/lib/
- 将hive目录下的lib目录下的jline-2.12.jar拷贝到/home/hadoop/hadoop-2.6.0/share/hadoop/yarn/lib/下,并且删除jline0.9.94低版本的数据
2.4 配置环境变量
[root@HadoopNode00 ~]# vi .bashrc
export HIVE_HOME=/home/hive/apache-hive-1.2.1-bin
export PATH=$PATH:$HIVE_HOME/bin
[root@HadoopNode00 ~]# source .bashrc
2.5 安装配置Hive
管理员模式
#自己的笔记
[root@HadoopNode00 ~]# start-dfs.sh
Java HotSpot(TM) 64-Bit Server VM warning: You have loaded library /home/hadoop/hadoop-2.6.0/lib/native/libhadoop.so.1.0.0 which might have disabled stack guard. The VM will try to fix the stack guard now.
It's highly recommended that you fix the library with 'execstack -c <libfile>', or link it with '-z noexecstack'.
19/11/06 21:55:46 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Starting namenodes on [HadoopNode00]
HadoopNode00: starting namenode, logging to /home/hadoop/hadoop-2.6.0/logs/hadoop-root-namenode-HadoopNode00.out
localhost: starting datanode, logging to /home/hadoop/hadoop-2.6.0/logs/hadoop-root-datanode-HadoopNode00.out
Starting secondary namenodes [0.0.0.0]
0.0.0.0: starting secondarynamenode, logging to /home/hadoop/hadoop-2.6.0/logs/hadoop-root-secondarynamenode-HadoopNode00.out
Java HotSpot(TM) 64-Bit Server VM warning: You have loaded library /home/hadoop/hadoop-2.6.0/lib/native/libhadoop.so.1.0.0 which might have disabled stack guard. The VM will try to fix the stack guard now.
It's highly recommended that you fix the library with 'execstack -c ' , or link it with '-z noexecstack'.
19/11/06 21:56:06 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
[root@HadoopNode00 ~]# jps
114418 DataNode
102389 RunJar
114300 NameNode
114623 SecondaryNameNode
101278 MapreduceDependencyClasspathTool
114798 Jps
#自己的笔记
[root@HadoopNode00 ~]# start-yarn.sh
starting yarn daemons
starting resourcemanager, logging to /home/hadoop/hadoop-2.6.0/logs/yarn-root-resourcemanager-HadoopNode00.out
localhost: starting nodemanager, logging to /home/hadoop/hadoop-2.6.0/logs/yarn-root-nodemanager-HadoopNode00.out
[root@HadoopNode00 ~]# jps
115152 NodeManager
114418 DataNode
102389 RunJar
115320 Jps
115050 ResourceManager
114300 NameNode
114623 SecondaryNameNode
101278 MapreduceDependencyClasspathTool
#自己的笔记
[root@HadoopNode00 ~]# hive
Logging initialized using configuration in jar:file:/home/hive/apache-hive-1.2.1-bin/lib/hive-common-1.2.1.jar!/hive-log4j.properties
Java HotSpot(TM) 64-Bit Server VM warning: You have loaded library /home/hadoop/hadoop-2.6.0/lib/native/libhadoop.so.1.0.0 which might have disabled stack guard. The VM will try to fix the stack guard now.
It's highly recommended that you fix the library with 'execstack -c <libfile>', or link it with '-z noexecstack'.
hive>
#自己的笔记
hive> create table t_user(id string,name string); #创建表 --- 不能时user表(它是关键词)
OK
Time taken: 1.325 seconds
#自己的笔记
hive> insert into t_user values ('1','zs'); #插入数据
Query ID = root_20191106220122_7dcc778e-349b-479c-b97f-7438344fcb26
Total jobs = 3
Launching Job 1 out of 3
Number of reduce tasks is set to 0 since there's no reduce operator
Starting Job = job_1573048606490_0001, Tracking URL = http://HadoopNode00:8088/proxy/application_1573048606490_0001/
Kill Command = /home/hadoop/hadoop-2.6.0/bin/hadoop job -kill job_1573048606490_0001
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 0
2019-11-06 22:01:41,639 Stage-1 map = 0%, reduce = 0%
2019-11-06 22:01:50,669 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.42 sec
MapReduce Total cumulative CPU time: 1 seconds 420 msec
Ended Job = job_1573048606490_0001
Stage-4 is selected by condition resolver.
Stage-3 is filtered out by condition resolver.
Stage-5 is filtered out by condition resolver.
Moving data to: hdfs://HadoopNode00:9000/user/hive/warehouse/t_user/.hive-staging_hive_2019-11-06_22-01-22_057_7044187176066837228-1/-ext-10000
Loading data to table default.t_user
Table default.t_user stats: [numFiles=1, numRows=1, totalSize=5, rawDataSize=4]
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Cumulative CPU: 1.42 sec HDFS Read: 3400 HDFS Write: 75 SUCCESS
Total MapReduce CPU Time Spent: 1 seconds 420 msec
OK
Time taken: 30.73 seconds
#总结:插入数据时启动了MR。
#自己的笔记
hive> select * from t_user; #查询数据
OK
1 zs
Time taken: 0.225 seconds, Fetched: 1 row(s)
#自己的笔记
#查看WEB UI界面的变化
#/user/hive/warehouse/t_user
#1zs --- 观察数据格式 --- hive的默认分隔符
#自己的笔记
hive> create database baizhi; #创建数据库
hive> create database baizhi; #创建baizhi数据库
OK
Time taken: 0.097 seconds
#自己的笔记
#怎样展示这个库下的表
#自己的笔记
hive> use baizhi; #用baizhi这个库
OK
Time taken: 0.048 seconds
#自己的笔记
hive> show databases; #展示所有的数据库
OK
baizhi
default
Time taken: 0.027 seconds, Fetched: 2 row(s)
#自己的笔记
#webUI界面的变化
#/user/hive/warehouse/baizhi.db
#自己的笔记
hive> create table t_user(id string,name string); #创建baizhi下的t_user这个表
OK
Time taken: 0.392 seconds
#自己的笔记
hive> show tables; #展示baizhi这个数据库的所有的表
OK
t_user
Time taken: 0.047 seconds, Fetched: 1 row(s)
hive>
#自己的笔记
hive> insert into t_user values('1','zs'); #插入数据
Query ID = root_20191106225318_e5401faf-c9d3-4729-9f07-94a56a2c2b14
Total jobs = 3
Launching Job 1 out of 3
Number of reduce tasks is set to 0 since there's no reduce operator
Starting Job = job_1573048606490_0002, Tracking URL = http://HadoopNode00:8088/proxy/application_1573048606490_0002/
Kill Command = /home/hadoop/hadoop-2.6.0/bin/hadoop job -kill job_1573048606490_0002
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 0
2019-11-06 22:53:31,034 Stage-1 map = 0%, reduce = 0%
2019-11-06 22:53:41,051 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.24 sec
MapReduce Total cumulative CPU time: 1 seconds 240 msec
Ended Job = job_1573048606490_0002
Stage-4 is selected by condition resolver.
Stage-3 is filtered out by condition resolver.
Stage-5 is filtered out by condition resolver.
Moving data to: hdfs://HadoopNode00:9000/user/hive/warehouse/baizhi.db/t_user/.hive-staging_hive_2019-11-06_22-53-18_800_3411901616279503915-1/-ext-10000
Loading data to table baizhi.t_user
Table baizhi.t_user stats: [numFiles=1, numRows=1, totalSize=5, rawDataSize=4]
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Cumulative CPU: 1.24 sec HDFS Read: 3427 HDFS Write: 74 SUCCESS
Total MapReduce CPU Time Spent: 1 seconds 240 msec
OK
Time taken: 24.169 second
#总结:插入数据是调用了MR
#自己的笔记
hive> select * from t_user; #查询数据
OK
1 zs
Time taken: 0.18 seconds, Fetched: 1 row(s)
#
#webUI
#/user/hive/warehouse/baizhi 变化
#自己的笔记
[root@HadoopNode00 ~]# hive -e 'use baizhi; select * from t_user;'#查询
Logging initialized using configuration in jar:file:/home/hive/apache-hive-1.2.1-bin/lib/hive-common-1.2.1.jar!/hive-log4j.properties
Java HotSpot(TM) 64-Bit Server VM warning: You have loaded library /home/hadoop/hadoop-2.6.0/lib/native/libhadoop.so.1.0.0 which might have disabled stack guard. The VM will try to fix the stack guard now.
It's highly recommended that you fix the library with 'execstack -c ' , or link it with '-z noexecstack'.
OK
Time taken: 1.094 seconds
OK
1 zs
Time taken: 0.916 seconds, Fetched: 1 row(s)
[root@HadoopNode00 ~]# hive
hive> create table t_user (id string,name string);
OK
Time taken: 0.291 seconds
hive> insert into t_user values ('1','zs');
[root@HadoopNode00 ~]# hive -e 'use baizhi; select * from t_user;'
Logging initialized using configuration in jar:file:/home/hive/apache-hive-1.2.1-bin/lib/hive-common-1.2.1.jar!/hive-log4j.properties
OK
Time taken: 0.722 seconds
OK
1 zs
Time taken: 0.527 seconds, Fetched: 1 row(s)
JDBC服务模式
#自己的笔记
[root@HadoopNode00 ~]# hiveserver2 #服务要处于挂起的状态
Java HotSpot(TM) 64-Bit Server VM warning: You have loaded library /home/hadoop/hadoop-2.6.0/lib/native/libhadoop.so.1.0.0 which might have disabled stack guard. The VM will try to fix the stack guard now.
It's highly recommended that you fix the library with 'execstack -c <libfile>', or link it with '-z noexecstack'.
[root@HadoopNode00 ~]# hiveserver2
Java HotSpot(TM) 64-Bit Server VM warning: You have loaded library /home/hadoop/hadoop-2.6.0/lib/native/libhadoop.so.1.0.0 which might have disabled stack guard. The VM will try to fix the stack guard now.
It's highly recommended that you fix the library with 'execstack -c ' , or link it with '-z noexecstack'.
#自己的笔记
[root@HadoopNode00 ~]# hiveserver2 & # 必须保证hiveserver2处于运行状态 后台启动模式
#自己的笔记
[root@HadoopNode00 ~]# jps
115152 NodeManager
114418 DataNode
12597 Jps
11771 RunJar #这是谁的进程
115050 ResourceManager
114300 NameNode
114623 SecondaryNameNode
101278 MapreduceDependencyClasspathTool #这是谁的进程
#自己的笔记
[root@HadoopNode00 ~]# beeline -u jdbc:hive2://HadoopNode00:10000 -n root
Connecting to jdbc:hive2://HadoopNode00:10000
Connected to: Apache Hive (version 1.2.1)
Driver: Hive JDBC (version 1.2.1)
Transaction isolation: TRANSACTION_REPEATABLE_READ
Beeline version 1.2.1 by Apache Hive
0: jdbc:hive2://HadoopNode00:10000>
#自己的笔记
0: jdbc:hive2://HadoopNode00:10000> show databases; #展示所有的数据库
+----------------+--+
| database_name |
+----------------+--+
| baizhi |
| default |
+----------------+--+
2 rows selected (1.434 seconds)
0: jdbc:hive2://HadoopNode00:10000>
[root@HadoopNode00 ~]# hiveserver2 # 必须保证hiveserver2处于运行状态 前台启动模式
[root@HadoopNode00 ~]# hiveserver2 & # 必须保证hiveserver2处于运行状态 后台启动模式
[root@HadoopNode00 ~]# beeline -u jdbc:hive2://HadoopNode00:10000 -n root
[root@HadoopNode00 ~]# beeline -u jdbc:hive2://$HOSTNAME:10000 -n root # 获取主机名 $HOSTNAME
脚本运行Hive
root下:创建hiveconn.sh的文件
#文件的内容开始:
#!/usr/bin/env bash
echo "连接hive"
echo " ————————————————————"
echo "| author:GuoJiafeng |"
echo "| company:Baizhi |"
echo " ————————————————————"
echo "beeline -u jdbc:hive2://$HOSTNAME:10000 -n root"
beeline -u jdbc:hive2://$HOSTNAME:10000 -n root
sleep 1
#文件的内容结束。
#自己的笔记
[root@HadoopNode00 ~]# sh hiveconn.sh
▒▒▒hive
▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒
| author▒▒GuoJiafeng |
| company▒▒Baizhi |
▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒
beeline -u jdbc:hive2://HadoopNode00:10000 -n root
Connecting to jdbc:hive2://HadoopNode00:10000
Connected to: Apache Hive (version 1.2.1)
Driver: Hive JDBC (version 1.2.1)
Transaction isolation: TRANSACTION_REPEATABLE_READ
Beeline version 1.2.1 by Apache Hive
#自己的笔记
0: jdbc:hive2://HadoopNode00:10000> show databases;
+----------------+--+
| database_name |
+----------------+--+
| baizhi |
| default |
+----------------+--+
2 rows selected (0.194 seconds)
三、Hive表操作
3.1 Hive 数据类型
数据类型(primitive ,array,map,struct)
primitive (原始类型)
整数:TINYINT SMALLINT INT BIGINT
布尔:BOOLEAN
小数:FLOAT DOUBLE
字符:STRING CHAR VARCHAR
二进制:BINARY
时间类型:TIMESTAMP DATE
array(数组):ARRAY
map(key-value类型):MAP
struct(结构体类型):STRUCT
3.2 创建表
#自己的笔记
[root@HadoopNode00 ~]# sh hiveconn.sh #脚本连接 ????????????有问题哈
▒▒▒hive
▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒
| author▒▒GuoJiafeng |
| company▒▒Baizhi |
▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒
beeline -u jdbc:hive2://HadoopNode00:10000 -n root
Connecting to jdbc:hive2://HadoopNode00:10000
Connected to: Apache Hive (version 1.2.1)
Driver: Hive JDBC (version 1.2.1)
Transaction isolation: TRANSACTION_REPEATABLE_READ
Beeline version 1.2.1 by Apache Hive
#自己的笔记
0: jdbc:hive2://HadoopNode00:10000> show databases; #展示所有的数据库
+----------------+--+
| database_name |
+----------------+--+
| baizhi |
| default |
+----------------+--+
2 rows selected (0.194 seconds)
#自己的笔记
0: jdbc:hive2://HadoopNode00:10000> use baizhi; #使用baizhi这个数据库
No rows affected (0.114 seconds)
0: jdbc:hive2://HadoopNode00:10000> desc baizhi;
Error: Error while compiling statement: FAILED: SemanticException [Error 10001]: Table not found baizhi (state=42S02,code=10001)
#自己的笔记
0: jdbc:hive2://HadoopNode00:10000> desc t_user; #描述表
+-----------+------------+----------+--+
| col_name | data_type | comment |
+-----------+------------+----------+--+
| id | string | |
| name | string | |
+-----------+------------+----------+--+
2 rows selected (0.33 seconds)
#自己的笔记
0: jdbc:hive2://HadoopNode00:10000> drop table t_user; #删除表 --- 有数据也是直接给删除了
No rows affected (0.789 seconds)
#自己的笔记
0: jdbc:hive2://HadoopNode00:10000> desc t_user; # 再次描述表 --- 用来证明t_user已将被删除了
Error: Error while compiling statement: FAILED: SemanticException [Error 10001]: Table not found t_user (state=42S02,code=10001)
#自己的笔记
0: jdbc:hive2://HadoopNode00:10000> create table t_user(
0: jdbc:hive2://HadoopNode00:10000> id int,
0: jdbc:hive2://HadoopNode00:10000> name string ,
0: jdbc:hive2://HadoopNode00:10000> birthday date,
0: jdbc:hive2://HadoopNode00:10000> salary double,
0: jdbc:hive2://HadoopNode00:10000> hobbbies array<string>,
0: jdbc:hive2://HadoopNode00:10000> card map<string,string>,
0: jdbc:hive2://HadoopNode00:10000> address struct<country:string,city:string>
0: jdbc:hive2://HadoopNode00:10000> ); #创建表
No rows affected (0.38 seconds)
#自己的笔记
0: jdbc:hive2://HadoopNode00:10000> desc t_user; #描述表 ---- 用于测试表是否创建成功
+-----------+-------------------------------------+----------+--+
| col_name | data_type | comment |
+-----------+-------------------------------------+----------+--+
| id | int | |
| name | string | |
| birthday | date | |
| salary | double | |
| hobbbies | array<string> | |
| card | map<string,string> | |
| address | struct<country:string,city:string> | |
+-----------+-------------------------------------+----------+--+
7 rows selected (0.247 seconds)
#自己的笔记
0: jdbc:hive2://HadoopNode00:10000> desc formatted t_user; #表的描述信息
+-------------------------------+-------------------------------------------------------------+-----------------------+--+
| col_name | data_type | comment |
+-------------------------------+-------------------------------------------------------------+-----------------------+--+
| # col_name | data_type | comment |
| | NULL | NULL |
| id | int | |
| name | string | |
| birthday | date | |
| salary | double | |
| hobbbies | array<string> | |
| card | map<string,string> | |
| address | struct<country:string,city:string> | |
| | NULL | NULL |
| # Detailed Table Information | NULL | NULL |
| Database: | default | NULL |
| Owner: | root | NULL |
| CreateTime: | Wed Nov 06 23:43:45 CST 2019 | NULL |
| LastAccessTime: | UNKNOWN | NULL |
| Protect Mode: | None | NULL |
| Retention: | 0 | NULL |
| Location: | hdfs://HadoopNode00:9000/user/hive/warehouse/t_user | NULL |
| Table Type: | MANAGED_TABLE | NULL |
| Table Parameters: | NULL | NULL |
| | transient_lastDdlTime | 1573055025 |
| | NULL | NULL |
| # Storage Information | NULL | NULL |
| SerDe Library: | org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe | NULL |
| InputFormat: | org.apache.hadoop.mapred.TextInputFormat | NULL |
| OutputFormat: | org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat | NULL |
| Compressed: | No | NULL |
| Num Buckets: | -1 | NULL |
| Bucket Columns: | [] | NULL |
| Sort Columns: | [] | NULL |
| Storage Desc Params: | NULL | NULL |
| | serialization.format | 1 |
+-------------------------------+-------------------------------------------------------------+-----------------------+--+
32 rows selected (0.2 seconds)
#自己的笔记
#插入数据(耗时) ---- 分隔符
create table t_user(
id int,
name string ,
birthday date,
salary double,
hobbbies array<string>,
card map<string,string>,
address struct<country:string,city:string>
);
0: jdbc:hive2://HadoopNode00:10000> desc formatted t_user; #表的描述信息
3.3 默认分隔符
| 分隔符 | 描述 |
|---|---|
| \n | 分割行,每一行就是一行记录 |
| ^A | 用于分割字段 \001 |
| ^B | 用于分割array 或者是struct中的元素 或者用于map结构中的k-v对分隔符 \002 |
| ^C | 用于map中的k-v的分隔符 \003 |
- 准备数据

vi 的编辑模式下:
#自己的笔记
[root@HadoopNode00 ~]# vi t_user;
#自己的笔记 --- 编辑以下的内容
1^Azs^A2012-11-12^A20000.0^ATV^BGAME^AJIANSHE^C001^BJIANSHE^C002^ACHINA^BBEIJING
#自己的笔记
[root@HadoopNode00 ~]# cat t_user #查看
1zs2012-11-1220000.0TVGAMEJIANSHE001JIANSHE002CHINABEIJING
## 3.4 将数据导入到Hive表中 ### #自己的笔记 --- 外部导入方式测试 [root@HadoopNode00 ~]# hadoop fs -rm -f /user/hive/warehouse/baizhi.db/t_user/* #删除表下的数据 #自己的笔记 [root@HadoopNode00 ~]# hadoop fs -put t_user /user/hive/warehouse/baizhi.db/t_user #上传文件 Java HotSpot(TM) 64-Bit Server VM warning: You have loaded library /home/hadoop/ hadoop-2.6.0/lib/native/libhadoop.so.1.0.0 which might have disabled stack guard . The VM will try to fix the stack guard now. It's highly recommended that you fix the library with 'execstack -c <libfile>', or link it with '-z noexecstack'. 19/11/07 06:00:16 WARN util.NativeCodeLoader: Unable to load native-hadoop libra ry for your platform... using bu #自己的笔记 #c查看WEBUI界面的变化 #/user/hive/warehouse/baizhi.db/t_user ??? 表的名字也是t_user了 #1zs2012-11-1220000.0TVGAMEJIANSHE001JIANSHE002CHINABEIJING #自己的笔记 hive> select * from t_user; #外部导入的方式测试成功 OK 1 zs 2012-11-12 20000.0 ["TV","GAME"] {"JIANSHE":"001"} {"country":"CHINA","city":"BEIJING"} Time taken: 0.219 seconds, Fetched: 1 row(s) #自己的总结(也有可能是错的): #(1)如果不使用use baizhi 其创建的表可能在默认的库下。 #(2) #自己的笔记 ---- 测试内部命令行导入(从本地的文件系统导入) #自己的笔记 --- 删除原来的文件 [root@HadoopNode00 ~]# hadoop fs -rm -f /user/hive/warehouse/baizhi.db/t_user/t_user Java HotSpot(TM) 64-Bit Server VM warning: You have loaded library /home/hadoop/hadoop-2.6.0/lib/native/libhadoop.so.1.0.0 which might have disabled stack guard. The VM will try to fix the stack guard now. It's highly recommended that you fix the library with 'execstack -c' , or link it with '-z noexecstack'. 19/11/07 06:21:10 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable 19/11/07 06:21:11 INFO fs.TrashPolicyDefault: Namenode trash configuration: Deletion interval = 1 minutes, Emptier interval = 0 minutes. Moved: 'hdfs://HadoopNode00:9000/user/hive/warehouse/baizhi.db/t_user/t_user' to trash at: hdfs://HadoopNode00:9000/user/root/.Trash/Current #自己的笔记 #查看WEBUI界面 #/user/hive/warehouse/baizhi.db/t_user 发现t_user表已经被删除了 #自己的笔记 hive> load data local inpath '/root/t_user' overwrite into table t_user; #导入测试 Loading data to table baizhi.t_user Table baizhi.t_user stats: [numFiles=1, numRows=0, totalSize=70, rawDataSize=0] OK Time taken: 0.778 seconds #自己的笔记 hive> select * from t_user; #查询测试 OK 1 zs 2012-11-12 20000.0 ["TV","GAME"] {"JIANSHE":"001"} {"country":"CHINA","city":"BEIJING"} Time taken: 0.093 seconds, Fetched: 1 row(s) #自己的笔记 #WEBUI界面测试 #1zs2012-11-1220000.0TVGAMEJIANSHE001JIANSHE002CHINABEIJING --- 查看数据 #自己的总结: #(1)本地文件还在 #自己的笔记 #内部命令行导入(从HDFS导入) #自己的笔记 ---- 测试前的准备工作 [root@HadoopNode00 ~]# hadoop fs -put t_user / #上传文件到HDFS中 Java HotSpot(TM) 64-Bit Server VM warning: You have loaded library /home/hadoop/hadoop-2.6.0/lib/native/libhadoop.so.1.0.0 which might have disabled stack guard. The VM will try to fix the stack guard now. It's highly recommended that you fix the library with 'execstack -c <libfile>', or link it with '-z noexecstack'. 19/11/07 06:32:59 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable #自己的笔记 --- 测试前的准备工作 [root@HadoopNode00 ~]# hadoop fs -rm -f /user/hive/warehouse/baizhi.db/t_user/t_user #删除原来的t_user Java HotSpot(TM) 64-Bit Server VM warning: You have loaded library /home/hadoop/hadoop-2.6.0/lib/native/libhadoop.so.1.0.0 which might have disabled stack guard. The VM will try to fix the stack guard now. It's highly recommended that you fix the library with 'execstack -c' , or link it with '-z noexecstack'. 19/11/07 06:35:23 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable 19/11/07 06:35:24 INFO fs.TrashPolicyDefault: Namenode trash configuration: Deletion interval = 1 minutes, Emptier interval = 0 minutes. Moved: 'hdfs://HadoopNode00:9000/user/hive/warehouse/baizhi.db/t_user/t_user' to trash at: hdfs://HadoopNode00:9000/user/root/.Trash/Current #自己的笔记 #WEBUI 界面测试是否删除 #/user/hive/warehouse/baizhi.db/t_user #测试删除成功 #自己的笔记 hive> select * from t_user; #shell界面测试 OK #自己的总结 #(1).t_user还在。 #自己的笔记 hive> load data inpath '/t_user' overwrite into table t_user; #内部命令行导入(从HDFS导入) Loading data to table baizhi.t_user Table baizhi.t_user stats: [numFiles=1, numRows=0, totalSize=70, rawDataSize=0] OK Time taken: 1.366 seconds #自己的笔记 hive> select * from t_user;#shell测试成功 OK 1 zs 2012-11-12 20000.0 ["TV","GAME"] {"JIANSHE":"001"} {"country":"CHINA","city":"BEIJING"} Time taken: 0.448 seconds, Fetched: 1 row(s) #自己的笔记 #WEBUI测试成功 #/user/hive/warehouse/baizhi.db/t_user #1zs2012-11-1220000.0TVGAMEJIANSHE001JIANSHE002CHINABEIJING #自己的总结: #(1)t_user直接被挪走了。 #自己的总结: (1)这三种导入数据的方式没有通过MR,通过映射的关系,直接存放在Hive存储文件的对应的文件夹中。 (2)user/hive/warehouse/下创建库。 (3)user/hive/warehouse/下存放default数据库下面的表。 (4)user/hive/warehouse/下存放着第三方默认的库。 #自己的注意: hive> use default; OK Time taken: 0.033 seconds #其创建的表在user/hive/warehouse/下。 #default库测试 hive> use default; # 使用默认的库 OK Time taken: 0.033 seconds hive> drop table baizhi; # Moved: 'hdfs://HadoopNode00:9000/user/hive/warehouse/baizhi' to trash at: hdfs://HadoopNode00:9000/user/root/.Trash/Current OK Time taken: 0.661 seconds hive> drop table t_user;# Moved: 'hdfs://HadoopNode00:9000/user/hive/warehouse/t_user' to trash at: hdfs://HadoopNode00:9000/user/root/.Trash/Current OK Time taken: 0.197 seconds #WEBBUI测试 #观察/user/hive/warehouse下 # 外部导入 [root@HadoopNode00 ~]# hadoop fs -put t_user /user/hive/warehouse/baizhi.db/t_user # 内部命令行导入(从本地文件系统导入) 0: jdbc:hive2://HadoopNode00:10000> load data local inpath '/root/t_user' overwrite into table t_user; # 内部命令行导入(从HDFS导入) 0: jdbc:hive2://HadoopNode00:10000> load data inpath '/t_user' overwrite into table t_user; > local 代表本地 文件 overwrite覆盖
3.5 JDBC 访问 Hive 实现数据查询
#自己的笔记
#1.开启mysqld ---- service mysqld start
#2.开启dfs ---- start-dfs.sh
#3.开启yarn ---- start-yarn.sh
#4.连接hive
#要实现JDBC访问Hive实现数据的查询
#要使用JDBC服务的模式开启Hive
#自己的笔记
[root@HadoopNode00 ~]# service mysqld start #开启mysqld的服务
Starting mysqld: [ OK ]
#自己的笔记
[root@HadoopNode00 ~]# hiveserver2 #此进程已开启会处于挂起的状态
Java HotSpot(TM) 64-Bit Server VM warning: You have loaded library /home/hadoop/hadoop-2.6.0/lib/native/libhadoop.so.1.0.0 which might have disabled stack guard. The VM will try to fix the stack guard now.
It's highly recommended that you fix the library with 'execstack -c <libfile>', or link it with '-z noexecstack'.
OK
OK
#自己的笔记
[root@HadoopNode00 ~]# jps
66640 Jps
115152 NodeManager
114418 DataNode
63139 RunJar
65928 RunJar #注意此进程
115050 ResourceManager
114300 NameNode
114623 SecondaryNameNode
#自己的笔记
[root@HadoopNode00 ~]# beeline -u jdbc:hive2://HadoopNode00:10000 -n root --- 连接HIve
Connecting to jdbc:hive2://HadoopNode00:10000
Connected to: Apache Hive (version 1.2.1)
Driver: Hive JDBC (version 1.2.1)
Transaction isolation: TRANSACTION_REPEATABLE_READ
Beeline version 1.2.1 by Apache Hive
#自己的笔记
0: jdbc:hive2://HadoopNode00:10000> use baizhi;
No rows affected (1.031 seconds)
#自己的笔记
0: jdbc:hive2://HadoopNode00:10000> select * from T_user;
+------------+--------------+------------------+----------------+------------------+--------------------+---------------------------------------+--+
| t_user.id | t_user.name | t_user.birthday | t_user.salary | t_user.hobbbies | t_user.card | t_user.address |
+------------+--------------+------------------+----------------+------------------+--------------------+---------------------------------------+--+
| 1 | zs | 2012-11-12 | 20000.0 | ["TV","GAME"] | {"JIANSHE":"001"} | {"country":"CHINA","city":"BEIJING"} |
+------------+--------------+------------------+----------------+------------------+--------------------+---------------------------------------+--+
1 row selected (1.027 seconds)
0: jdbc:hive2://HadoopNode00:10000>
#没有测试成功
package com.baizhi;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
public class App {
public static void main(String[] args) throws Exception {
/*
*加载驱动
* */
Class.forName("org.apache.hive.jdbc.HiveDriver");
Connection connection = DriverManager.getConnection("jdbc:hive2://HadoopNode00:10000/baizhi", "root", null);
/*
* 创建stm
* */
Statement statement = connection.createStatement();
ResultSet resultSet = statement.executeQuery("select name,salary from t_user");
while (resultSet.next()) {
String name = resultSet.getString("name");
double salary = resultSet.getDouble("salary");
System.out.println(name + "的工资 是:" + salary);
}
resultSet.close();
statement.close();
connection.close();
}
}
3.6 自定义分隔符
#自己的笔记
[root@HadoopNode00 ~]# hive #连接
Logging initialized using configuration in jar:file:/home/hive/apache-hive-1.2.1-bin/lib/hive-common-1.2.1.jar!/hive-log4j.properties
Java HotSpot(TM) 64-Bit Server VM warning: You have loaded library /home/hadoop/hadoop-2.6.0/lib/native/libhadoop.so.1.0.0 which might have disabled stack guard. The VM will try to fix the stack guard now.
It's highly recommended that you fix the library with 'execstack -c <libfile>', or link it with '-z noexecstack'.
#自己的笔记
hive> use baizhi; #用baizhi这个库
OK
Time taken: 1.05 seconds
#自己的笔记
hive> create table t_user_c( #创建表
> id int,
> name string ,
> birthday date,
> salary double,
> hobbbies array,
> card map,
> address struct
> )
> row format delimited
> fields terminated by ' ,'
> collection items terminated by '|'
> map keys terminated by '>'
> lines terminated by '\n'
> ;
OK
Time taken: 1.05 seconds
#自己的笔记
hive> desc t_user_c; #描述表
OK
id int
name string
birthday date
salary double
hobbbies array
card map
address struct
Time taken: 0.484 seconds, Fetched: 7 row(s)
#自己的笔记
[root@HadoopNode00 ~]# vi t_user_v; --- 添加数据
#自己的笔记
[root@HadoopNode00 ~]# more t_user_v;
1,zhangsan,2019-11-07,20100,TV|GAME,JIANSHE>001|ZHAOSHAN>002,CHAINA|BJ
2,lisi,2019-11-07,20100,TV|GAME,JIANSHE>002|ZHAOSHAN>006,CHAINA|BJ
3,wangwu,2019-11-07,20100,TV|GAME,JIANSHE>003|ZHAOSHAN>007,CHAINA|BJ
4,ermazi,2019-11-07,20070,TV|GAME,JIANSHE>004|ZHAOSHAN>008,CHAINA|BJ
5,ergouzi,2019-11-07,21000,TV|GAME,JIANSHE>005|ZHAOSHAN>009,CHAINA|BJ
#自己的笔记 --- 外部导入
[root@HadoopNode00 ~]# hadoop fs -put t_user_v /user/hive/warehouse/baizhi.db/t_user_c Java HotSpot(TM) 64-Bit Server VM warning: You have loaded library /home/hadoop/hadoop-2.6.0/lib/native/libhadoop.so.1.0.0 which might have disabled stack guard. The VM will try to fix the stack guard now.
It' s highly recommended that you fix the library with 'execstack -c ' , or link it with '-z noexecstack'.
19/11/07 07:42:37 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
create table t_user_c(
id int,
name string ,
birthday date,
salary double,
hobbbies array<string>,
card map<string,string>,
address struct<country:string,city:string>
)
row format delimited
fields terminated by ','
collection items terminated by '|'
map keys terminated by '>'
lines terminated by '\n'
;
1,zhangsan,2019-11-07,20100,TV|GAME,JIANSHE>001|ZHAOSHAN>002,CHAINA|BJ
2,lisi,2019-11-07,20100,TV|GAME,JIANSHE>002|ZHAOSHAN>006,CHAINA|BJ
3,wangwu,2019-11-07,20100,TV|GAME,JIANSHE>003|ZHAOSHAN>007,CHAINA|BJ
4,ermazi,2019-11-07,20070,TV|GAME,JIANSHE>004|ZHAOSHAN>008,CHAINA|BJ
5,ergouzi,2019-11-07,21000,TV|GAME,JIANSHE>005|ZHAOSHAN>009,CHAINA|BJ
load data local inpath '/root/t_user_c' into table t_user_c;
3.7 导入CSV文件
#自己的笔记
#CSV文件介紹
#逗号分隔值(Comma-Separated Values,CSV,有时也称为字符分隔值,因为分隔字符也可以不是逗号),其文件以纯文本形式存储表格数据(数字和文本)。---- 一般用通讯录·用于海量的数据结构的存储。
#自己的笔记
#准备.csv文件
1,zhangsan,true,20
2,lisi,false,21
3,wangwu,true,21
#自己的笔记
[root@HadoopNode00 ~]# more t_csv ---- 查看T_csv文件
ngsan,true,20
2,lisi,false,21
3,wangwu,true,21
#自己的笔记
#WEB-UI界面查看
#/user/hive/warehouse/baizhi.db
#自己的笔记
0: jdbc:hive2://HadoopNode00:10000> show tables; #查看表
+-----------+--+
| tab_name |
+-----------+--+
| t_csv | #
| t_user |
| t_user_c |
+-----------+--+
#自己的笔记
create table t_csv(
id int ,
name string,
sex boolean,
age int
)
row format serde 'org.apache.hadoop.hive.serde2.OpenCSVSerde'
with serdeproperties(
"separatorChar" = ",",
"escapeChar" = "\\"
) ;
#自己的笔记
0: jdbc:hive2://HadoopNode00:10000> create table t_csv( #创建表格
0: jdbc:hive2://HadoopNode00:10000> id int ,
0: jdbc:hive2://HadoopNode00:10000> name string,
0: jdbc:hive2://HadoopNode00:10000> sex boolean,
0: jdbc:hive2://HadoopNode00:10000> age int
0: jdbc:hive2://HadoopNode00:10000> )
0: jdbc:hive2://HadoopNode00:10000> row format serde 'org.apache.hadoop.hive.serde2.OpenCSVSerde'
0: jdbc:hive2://HadoopNode00:10000> with serdeproperties(
0: jdbc:hive2://HadoopNode00:10000> "separatorChar" = ",",
0: jdbc:hive2://HadoopNode00:10000> "escapeChar" = "\\"
0: jdbc:hive2://HadoopNode00:10000> ) ;
No rows affected (0.683 seconds)
#自己的笔记
0: jdbc:hive2://HadoopNode00:10000> show tables; #展示表格
+-----------+--+
| tab_name |
+-----------+--+
| t_csv |
| t_user |
| t_user_c |
+-----------+--+
3 rows selected (0.255 seconds)
#自己的笔记
0: jdbc:hive2://HadoopNode00:10000> load data local inpath '/root/t_csv' into table t_csv; #内部导入(从本地的文件系统导入)
INFO : Loading data to table baizhi.t_csv from fi le:/root/t_csv
INFO : Table baizhi.t_csv stats: [numFiles=1, totalSize=47]
No rows affected (24.693 seconds)
#自己的笔记
#WEBUUI界面测试
#/user/hive/warehouse/baizhi.db/t_csv
1,ngsan,true,20
2,lisi,false,21
3,wangwu,true,21
#自己的笔记
#shell命令测试
0: jdbc:hive2://HadoopNode00:10000> select * from t_csv; #查表
+-----------+-------------+------------+------------+--+
| t_csv.id | t_csv.name | t_csv.sex | t_csv.age |
+-----------+-------------+------------+------------+--+
| ngsan | true | 20 | NULL |
| 2 | lisi | false | 21 |
| 3 | wangwu | true | 21 |
+-----------+-------------+------------+------------+--+
1,zhangsan,true,20
2,lisi,false,21
3,wangwu,true,21
--------------------------------
create table t_csv(
id int ,
name string,
sex boolean,
age int
)
row format serde 'org.apache.hadoop.hive.serde2.OpenCSVSerde' #开源
with serdeproperties(
"separatorChar" = ",", #序列化
"escapeChar" = "\\" #反序列化
) ;
load data local inpath '/root/t_csv' into table t_csv;
3.8 JSON数据格式
#自己的笔记
#准备数据
[root@HadoopNode00 ~]# vi t_json;
[root@HadoopNode00 ~]# more t_json;
{"id":1,"name":"zs","sex":true,"age":18}
#自己的笔记
#添加jar包
# 添加环境 ---- 创建表之前要添加外部的jar包
add jar /home/hive/apache-hive-1.2.1-bin/hcatalog/share/hcatalog/hive-hcatalog-core-1.2.1.jar
#自己的笔记
0: jdbc:hive2://HadoopNode00:10000> add jar /home/hive/apache-hive-1.2.1-bin/hcatalog/share/hcatalog/hive-hcatalog-core-1.2.1.jar; #添加jar包
INFO : Added [/home/hive/apache-hive-1.2.1-bin/hcatalog/share/hcatalog/hive-hcatalog-core-1.2.1.jar] to class path
INFO : Added resources: [/home/hive/apache-hive-1.2.1-bin/hcatalog/share/hcatalog/hive-hcatalog-core-1.2.1.jar]
No rows affected (0.355 seconds)
#自己的笔记
0: jdbc:hive2://HadoopNode00:10000> create table t_json( # 创建表
0: jdbc:hive2://HadoopNode00:10000> id int ,
0: jdbc:hive2://HadoopNode00:10000> name string,
0: jdbc:hive2://HadoopNode00:10000> sex boolean,
0: jdbc:hive2://HadoopNode00:10000> age int
0: jdbc:hive2://HadoopNode00:10000> )
0: jdbc:hive2://HadoopNode00:10000> row format serde 'org.apache.hive.hcatalog.data.JsonSerDe';
No rows affected (0.42 seconds)
#自己的笔记
0: jdbc:hive2://HadoopNode00:10000> show tables; #查看所有的表
+-----------+--+
| tab_name |
+-----------+--+
| t_csv |
| t_json | #此处
| t_user |
| t_user_c |
+-----------+--+
#自己的笔记
0: jdbc:hive2://HadoopNode00:10000> load data local inpath '/root/t_json' into table t_json; #外部导入 --- (从HDFS导入)
INFO : Loading data to table baizhi.t_json from file:/root/t_json
INFO : Table baizhi.t_json stats: [numFiles=1, totalSize=41]
No rows affected (0.782 seconds
#自己的笔记
#WEBUI ---- 测试
#/user/hive/warehouse/baizhi.db/t_json
#自己的笔记
#shell命令测试
0: jdbc:hive2://HadoopNode00:10000> select * from t_json; #查表
+------------+--------------+-------------+-------------+--+
| t_json.id | t_json.name | t_json.sex | t_json.age |
+------------+--------------+-------------+-------------+--+
| 1 | zs | true | 18 |
+------------+--------------+-------------+-------------+--+
# 准备数据
{"id":1,"name":"zs","sex":true,"age":18}
---------------------------------
# 添加环境
add jar /home/hive/apache-hive-1.2.1-bin/hcatalog/share/hcatalog/hive-hcatalog-core-1.2.1.jar
------------------------------------
# 创建
create table t_json(
id int ,
name string,
sex boolean,
age int
)
row format serde 'org.apache.hive.hcatalog.data.JsonSerDe';
————————————————————————————————————————————————————————
load data local inpath '/root/t_json' into table t_json;
3.9 正则提取
快速查询手册
| 元字符 | 描述 |
|---|---|
| \ | 将下一个字符标记符、或一个向后引用、或一个八进制转义符。例如,“\n”匹配\n。“\n”匹配换行符。序列“\”匹配“\”而“(”则匹配“(”。即相当于多种编程语言中都有的“转义字符”的概念。 |
| ^ | 匹配输入字行首。如果设置了RegExp对象的Multiline属性,^也匹配“\n”或“\r”之后的位置。 |
| $ | 匹配输入行尾。如果设置了RegExp对象的Multiline属性,$也匹配“\n”或“\r”之前的位置。 |
| * | 匹配前面的子表达式任意次。例如,zo*能匹配“z”,也能匹配“zo”以及“zoo”。*等价于{0,}。 |
| + | 匹配前面的子表达式一次或多次(大于等于1次)。例如,“zo+”能匹配“zo”以及“zoo”,但不能匹配“z”。+等价于{1,}。 |
| ? | 匹配前面的子表达式零次或一次。例如,“do(es)?”可以匹配“do”或“does”。?等价于{0,1}。 |
| {n} | n是一个非负整数。匹配确定的n次。例如,“o{2}”不能匹配“Bob”中的“o”,但是能匹配“food”中的两个o。 |
| {n,} | n是一个非负整数。至少匹配n次。例如,“o{2,}”不能匹配“Bob”中的“o”,但能匹配“foooood”中的所有o。“o{1,}”等价于“o+”。“o{0,}”则等价于“o*”。 |
| {n,m} | m和n均为非负整数,其中n<=m。最少匹配n次且最多匹配m次。例如,“o{1,3}”将匹配“fooooood”中的前三个o为一组,后三个o为一组。“o{0,1}”等价于“o?”。请注意在逗号和两个数之间不能有空格。 |
| ? | 当该字符紧跟在任何一个其他限制符(*,+,?,{n},{n,},{n,m})后面时,匹配模式是非贪婪的。非贪婪模式尽可能少地匹配所搜索的字符串,而默认的贪婪模式则尽可能多地匹配所搜索的字符串。例如,对于字符串“oooo”,“o+”将尽可能多地匹配“o”,得到结果[“oooo”],而“o+?”将尽可能少地匹配“o”,得到结果 [‘o’, ‘o’, ‘o’, ‘o’] |
| . | 匹配除“\n”和"\r"之外的任何单个字符。要匹配包括“\n”和"\r"在内的任何字符,请使用像“[\s\S]”的模式。 |
| (pattern) | 匹配pattern并获取这一匹配。所获取的匹配可以从产生的Matches集合得到,在VBScript中使用SubMatches集合,在JScript中则使用$0…$9属性。要匹配圆括号字符,请使用“(”或“)”。 |
| (?:pattern) | 非获取匹配,匹配pattern但不获取匹配结果,不进行存储供以后使用。这在使用或字符“(|)”来组合一个模式的各个部分时很有用。例如“industr(?:y|ies)”就是一个比“industry|industries”更简略的表达式。 |
| (?=pattern) | 非获取匹配,正向肯定预查,在任何匹配pattern的字符串开始处匹配查找字符串,该匹配不需要获取供以后使用。例如,“Windows(?=95|98|NT|2000)”能匹配“Windows2000”中的“Windows”,但不能匹配“Windows3.1”中的“Windows”。预查不消耗字符,也就是说,在一个匹配发生后,在最后一次匹配之后立即开始下一次匹配的搜索,而不是从包含预查的字符之后开始。 |
| (?!pattern) | 非获取匹配,正向否定预查,在任何不匹配pattern的字符串开始处匹配查找字符串,该匹配不需要获取供以后使用。例如“Windows(?!95|98|NT|2000)”能匹配“Windows3.1”中的“Windows”,但不能匹配“Windows2000”中的“Windows”。 |
| (?<=pattern) | 非获取匹配,反向肯定预查,与正向肯定预查类似,只是方向相反。例如,“(?<=95|98|NT|2000)Windows”能匹配“2000Windows”中的“Windows”,但不能匹配“3.1Windows”中的“Windows”。*python的正则表达式没有完全按照正则表达式规范实现,所以一些高级特性建议使用其他语言如java、scala等 |
| (? | 非获取匹配,反向否定预查,与正向否定预查类似,只是方向相反。例如“(? |
| x|y | 匹配x或y。例如,“z|food”能匹配“z”或“food”(此处请谨慎)。“[zf]ood”则匹配“zood”或“food”。 |
| [xyz] | 字符集合。匹配所包含的任意一个字符。例如,“[abc]”可以匹配“plain”中的“a”。 |
| [^xyz] | 负值字符集合。匹配未包含的任意字符。例如,“[^abc]”可以匹配“plain”中的“plin”任一字符。 |
| [a-z] | 字符范围。匹配指定范围内的任意字符。例如,“[a-z]”可以匹配“a”到“z”范围内的任意小写字母字符。注意:只有连字符在字符组内部时,并且出现在两个字符之间时,才能表示字符的范围; 如果出字符组的开头,则只能表示连字符本身. |
| [^a-z] | 负值字符范围。匹配任何不在指定范围内的任意字符。例如,“[^a-z]”可以匹配任何不在“a”到“z”范围内的任意字符。 |
| \b | 匹配一个单词的边界,也就是指单词和空格间的位置(即正则表达式的“匹配”有两种概念,一种是匹配字符,一种是匹配位置,这里的\b就是匹配位置的)。例如,“er\b”可以匹配“never”中的“er”,但不能匹配“verb”中的“er”;“\b1_”可以匹配“1_23”中的“1_”,但不能匹配“21_3”中的“1_”。 |
| \B | 匹配非单词边界。“er\B”能匹配“verb”中的“er”,但不能匹配“never”中的“er”。 |
| \cx | 匹配由x指明的控制字符。例如,\cM匹配一个Control-M或回车符。x的值必须为A-Z或a-z之一。否则,将c视为一个原义的“c”字符。 |
| \d | 匹配一个数字字符。等价于[0-9]。grep 要加上-P,perl正则支持 |
| \D | 匹配一个非数字字符。等价于[^0-9]。grep要加上-P,perl正则支持 |
| \f | 匹配一个换页符。等价于\x0c和\cL。 |
| \n | 匹配一个换行符。等价于\x0a和\cJ。 |
| \r | 匹配一个回车符。等价于\x0d和\cM。 |
| \s | 匹配任何不可见字符,包括空格、制表符、换页符等等。等价于[ \f\n\r\t\v]。 |
| \S | 匹配任何可见字符。等价于[^ \f\n\r\t\v]。 |
| \t | 匹配一个制表符。等价于\x09和\cI。 |
| \v | 匹配一个垂直制表符。等价于\x0b和\cK。 |
| \w | 匹配包括下划线的任何单词字符。类似但不等价于“[A-Za-z0-9_]”,这里的"单词"字符使用Unicode字符集。 |
| \W | 匹配任何非单词字符。等价于“[^A-Za-z0-9_]”。 |
| \xn | 匹配n,其中n为十六进制转义值。十六进制转义值必须为确定的两个数字长。例如,“\x41”匹配“A”。“\x041”则等价于“\x04&1”。正则表达式中可以使用ASCII编码。 |
| *num* | 匹配num,其中num是一个正整数。对所获取的匹配的引用。例如,“(.)\1”匹配两个连续的相同字符。 |
| *n* | 标识一个八进制转义值或一个向后引用。如果*n之前至少n个获取的子表达式,则n为向后引用。否则,如果n为八进制数字(0-7),则n*为一个八进制转义值。 |
| *nm* | 标识一个八进制转义值或一个向后引用。如果*nm之前至少有nm个获得子表达式,则nm为向后引用。如果*nm之前至少有n个获取,则n为一个后跟文字m的向后引用。如果前面的条件都不满足,若n和m均为八进制数字(0-7),则*nm将匹配八进制转义值nm*。 |
| *nml* | 如果n为八进制数字(0-7),且m和l均为八进制数字(0-7),则匹配八进制转义值nml。 |
| \un | 匹配n,其中n是一个用四个十六进制数字表示的Unicode字符。例如,\u00A9匹配版权符号(©)。 |
| \p{P} | 小写 p 是 property 的意思,表示 Unicode 属性,用于 Unicode 正表达式的前缀。中括号内的“P”表示Unicode 字符集七个字符属性之一:标点字符。其他六个属性:L:字母;M:标记符号(一般不会单独出现);Z:分隔符(比如空格、换行等);S:符号(比如数学符号、货币符号等);N:数字(比如阿拉伯数字、罗马数字等);C:其他字符。*注:此语法部分语言不支持,例:javascript。 |
| <> | 匹配词(word)的开始(<)和结束(>)。例如正则表达式 |
| ( ) | 将( 和 ) 之间的表达式定义为“组”(group),并且将匹配这个表达式的字符保存到一个临时区域(一个正则表达式中最多可以保存9个),它们可以用 \1 到\9 的符号来引用。 |
| | | 将两个匹配条件进行逻辑“或”(Or)运算。例如正则表达式(him|her) 匹配"it belongs to him"和"it belongs to her",但是不能匹配"it belongs to them."。注意:这个元字符不是所有的软件都支持的。 |
正则匹配
#自己的笔记
#正则表达式理论上是可以分割任意数据的。
#自己的笔记
[root@HadoopNode00 ~]# vi t_access;
[root@HadoopNode00 ~]# more t_access;
192.168.0.1 qq com.xx.xx.XxxService#xx 2018-10-10 10:10:00
192.168.2.1 qq com.xx.xx.XxxService#xx 2018-10-10 10:10:00
192.168.0.1 xx com.xx.xx.XxxService#xx 2018-10-10 10:10:00
192.168.202.1 qq com.xx.xx.XxxService#xx 2018-10-10 10:10:00
192.168.2.1 qq com.xx.xx.XxxService#xx 2018-10-10 10:10:00
192.168.0.2 xx com.xx.xx.XxxService#xx 2018-10-10 10:10:00
192.168.0.2 qq com.xx.xx.XxxService#xx 2018-10-10 10:10:00
192.168.2.4 qq com.xx.xx.XxxService#xx 2018-10-10 10:10:00
192.168.0.4 xx com.xx.xx.XxxService#xx 2018-10-10 10:10:00
#自己的笔记
0: jdbc:hive2://HadoopNode00:10000> create table t_access( #创建表
0: jdbc:hive2://HadoopNode00:10000> ip string,
0: jdbc:hive2://HadoopNode00:10000> app varchar(32),
0: jdbc:hive2://HadoopNode00:10000> service string,
0: jdbc:hive2://HadoopNode00:10000> last_time string
0: jdbc:hive2://HadoopNode00:10000> )
0: jdbc:hive2://HadoopNode00:10000> ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.RegexSerDe'
0: jdbc:hive2://HadoopNode00:10000> WITH SERDEPROPERTIES (
0: jdbc:hive2://HadoopNode00:10000> "input.regex"="^(.*)\\s(.*)\\s(.*)\\s(.*\\s.*)"
0: jdbc:hive2://HadoopNode00:10000> );
No rows affected (0.374 seconds)
#自己的笔记
0: jdbc:hive2://HadoopNode00:10000> select * from t_access; #查询表
+--------------+---------------+-------------------+---------------------+--+
| t_access.ip | t_access.app | t_access.service | t_access.last_time |
+--------------+---------------+-------------------+---------------------+--+
+--------------+---------------+-------------------+---------------------+--+
No rows selected (0.465 seconds)
#自己的笔记
#/user/hive/warehouse/baizhi.db/t_access
#自己的笔记
0: jdbc:hive2://HadoopNode00:10000> load data local inpath '/root/t_access' into table t_access; #外部导入 ---- (从本地的文件系统导入)
INFO : Loading data to table baizhi.t_access from file:/root/t_access
INFO : Table baizhi.t_access stats: [numFiles=1, totalSize=533]
No rows affected (0.456 seconds)
#自己的笔记
#shell命令测试
0: jdbc:hive2://HadoopNode00:10000> select * from t_access; #查表
+----------------+---------------+--------------------------+----------------------+--+
| t_access.ip | t_access.app | t_access.service | t_access.last_time |
+----------------+---------------+--------------------------+----------------------+--+
| 192.168.0.1 | qq | com.xx.xx.XxxService#xx | 2018-10-10 10:10:00 |
| 192.168.2.1 | qq | com.xx.xx.XxxService#xx | 2018-10-10 10:10:00 |
| 192.168.0.1 | xx | com.xx.xx.XxxService#xx | 2018-10-10 10:10:00 |
| 192.168.202.1 | qq | com.xx.xx.XxxService#xx | 2018-10-10 10:10:00 |
| 192.168.2.1 | qq | com.xx.xx.XxxService#xx | 2018-10-10 10:10:00 |
| 192.168.0.2 | xx | com.xx.xx.XxxService#xx | 2018-10-10 10:10:00 |
| 192.168.0.2 | qq | com.xx.xx.XxxService#xx | 2018-10-10 10:10:00 |
| 192.168.2.4 | qq | com.xx.xx.XxxService#xx | 2018-10-10 10:10:00 |
| 192.168.0.4 | xx | com.xx.xx.XxxService#xx | 2018-10-10 10:10:00 |
+----------------+---------------+--------------------------+----------------------+--+
9 rows selected (1.024 seconds
#自己的笔记
#WEBUI --- 界面测试
192.168.0.1 qq com.xx.xx.XxxService#xx 2018-10-10 10:10:00
192.168.2.1 qq com.xx.xx.XxxService#xx 2018-10-10 10:10:00
192.168.0.1 xx com.xx.xx.XxxService#xx 2018-10-10 10:10:00
192.168.202.1 qq com.xx.xx.XxxService#xx 2018-10-10 10:10:00
192.168.2.1 qq com.xx.xx.XxxService#xx 2018-10-10 10:10:00
192.168.0.2 xx com.xx.xx.XxxService#xx 2018-10-10 10:10:00
192.168.0.2 qq com.xx.xx.XxxService#xx 2018-10-10 10:10:00
192.168.2.4 qq com.xx.xx.XxxService#xx 2018-10-10 10:10:00
192.168.0.4 xx com.xx.xx.XxxService#xx 2018-10-10 10:10:00
#自己的笔记
#其它的数据导入方式统统可以归类为正则提取的子集。
192.168.0.1 qq com.xx.xx.XxxService#xx 2018-10-10 10:10:00
192.168.2.1 qq com.xx.xx.XxxService#xx 2018-10-10 10:10:00
192.168.0.1 xx com.xx.xx.XxxService#xx 2018-10-10 10:10:00
192.168.202.1 qq com.xx.xx.XxxService#xx 2018-10-10 10:10:00
192.168.2.1 qq com.xx.xx.XxxService#xx 2018-10-10 10:10:00
192.168.0.2 xx com.xx.xx.XxxService#xx 2018-10-10 10:10:00
192.168.0.2 qq com.xx.xx.XxxService#xx 2018-10-10 10:10:00
192.168.2.4 qq com.xx.xx.XxxService#xx 2018-10-10 10:10:00
192.168.0.4 xx com.xx.xx.XxxService#xx 2018-10-10 10:10:00
---------------------------
create table t_access(
ip string,
app varchar(32),
service string,
last_time string
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.RegexSerDe'
WITH SERDEPROPERTIES (
"input.regex"="^(.*)\\s(.*)\\s(.*)\\s(.*\\s.*)"
);
load data local inpath '/root/t_access' into table t_access;
3.10 其它的数据导入方式
#自己的笔记
0: jdbc:hive2://HadoopNode00:10000> create table t(id string,name string) ;#创建表。
No rows affected (0.225 seconds)
#自己的笔记
0: jdbc:hive2://HadoopNode00:10000> show tables; #展示表
+-----------+--+
| tab_name |
+-----------+--+
| t |
| t_access |
| t_csv |
| t_json |
| t_user |
| t_user_c |
+-----------+--+
#自己的笔记
0: jdbc:hive2://HadoopNode00:10000> insert into t values ('1','zs');# RDBMS插入数据的方式 不太适用与HIVE 大数据处理 ---- MR计算
INFO : Number of reduce tasks is set to 0 since there's no reduce operator
WARN : Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this.
INFO : number of splits:1
INFO : Submitting tokens for job: job_1573048606490_0003
INFO : The url to track the job: http://HadoopNode00:8088/proxy/application_1573048606490_0003/
INFO : Starting Job = job_1573048606490_0003, Tracking URL = http://HadoopNode00:8088/proxy/application_1573048606490_0003/
INFO : Kill Command = /home/hadoop/hadoop-2.6.0/bin/hadoop job -kill job_1573048606490_0003
INFO : Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 0
INFO : 2019-11-07 13:08:12,666 Stage-1 map = 0%, reduce = 0%
INFO : 2019-11-07 13:08:39,471 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 2.27 sec
INFO : MapReduce Total cumulative CPU time: 2 seconds 270 msec
INFO : Ended Job = job_1573048606490_0003
INFO : Stage-4 is selected by condition resolver.
INFO : Stage-3 is filtered out by condition resolver.
INFO : Stage-5 is filtered out by condition resolver.
INFO : Moving data to: hdfs://HadoopNode00:9000/user/hive/warehouse/baizhi.db/t/.hive-staging_hive_2019-11-07_13-05-22_779_1893609346644049533-1/-ext-10000 from hdfs://HadoopNode00:9000/user/hive/warehouse/baizhi.db/t/.hive-staging_hive_2019-11-07_13-05-22_779_1893609346644049533-1/-ext-10002
INFO : Loading data to table baizhi.t from hdfs://HadoopNode00:9000/user/hive/warehouse/baizhi.db/t/.hive-staging_hive_2019-11-07_13-05-22_779_1893609346644049533-1/-ext-10000
INFO : Table baizhi.t stats: [numFiles=1, numRows=1, totalSize=5, rawDataSize=4]
No rows affected (209.96 seconds)
#自己的笔记
0: jdbc:hive2://HadoopNode00:10000> select * from t; #查
+-------+---------+--+
| t.id | t.name |
+-------+---------+--+
| 1 | zs |
+-------+---------+--+
1 row selected (0.446 seconds)
#自己的笔记
0: jdbc:hive2://HadoopNode00:10000> insert into table t select ip, app from t_access; #从别的表中来拷贝数据
INFO : Number of reduce tasks is set to 0 since there's no reduce operator
WARN : Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this.
INFO : number of splits:1
INFO : Submitting tokens for job: job_1573048606490_0004
INFO : The url to track the job: http://HadoopNode00:8088/proxy/application_1573048606490_0004/
INFO : Starting Job = job_1573048606490_0004, Tracking URL = http://HadoopNode00:8088/proxy/application_1573048606490_0004/
INFO : Kill Command = /home/hadoop/hadoop-2.6.0/bin/hadoop job -kill job_1573048606490_0004
INFO : Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 0
INFO : 2019-11-07 13:10:57,135 Stage-1 map = 0%, reduce = 0%
INFO : 2019-11-07 13:11:12,643 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 2.12 sec
INFO : MapReduce Total cumulative CPU time: 2 seconds 120 msec
INFO : Ended Job = job_1573048606490_0004
INFO : Stage-4 is selected by condition resolver.
INFO : Stage-3 is filtered out by condition resolver.
INFO : Stage-5 is filtered out by condition resolver.
INFO : Moving data to: hdfs://HadoopNode00:9000/user/hive/warehouse/baizhi.db/t/.hive-staging_hive_2019-11-07_13-10-41_313_6970858864523349098-1/-ext-10000 from hdfs://HadoopNode00:9000/user/hive/warehouse/baizhi.db/t/.hive-staging_hive_2019-11-07_13-10-41_313_6970858864523349098-1/-ext-10002
INFO : Loading data to table baizhi.t from hdfs://HadoopNode00:9000/user/hive/warehouse/baizhi.db/t/.hive-staging_hive_2019-11-07_13-10-41_313_6970858864523349098-1/-ext-10000
INFO : Table baizhi.t stats: [numFiles=2, numRows=10, totalSize=142, rawDataSize=132]
No rows affected (36.124 seconds)
#自己的笔记
0: jdbc:hive2://HadoopNode00:10000> select * from t; #查表
+----------------+---------+--+
| t.id | t.name |
+----------------+---------+--+
| 1 | zs |
| 192.168.0.1 | qq |
| 192.168.2.1 | qq |
| 192.168.0.1 | xx |
| 192.168.202.1 | qq |
| 192.168.2.1 | qq |
| 192.168.0.2 | xx |
| 192.168.0.2 | qq |
| 192.168.2.4 | qq |
| 192.168.0.4 | xx |
+----------------+---------+--+
10 rows selected (0.203 seconds)
#自己的笔记
0: jdbc:hive2://HadoopNode00:10000> insert into table t select * from t_access; #插入数据
Error: Error while compiling statement: FAILED: SemanticException [Error 10044]: Line 1:18 Cannot insert into target table because column number/types are different 't': Table insclause-0 has 2 columns, but query has 4 columns. (state=42000,code=10044)
#总结:需要注意的是 插入的时候 需要字段类型和数量一一对应,否则无法插入数据
#自己的笔记
0: jdbc:hive2://HadoopNode00:10000> create table temp1 as select * from t_access; #创建表的时候直接全盘把数据拿过来 (表结构也拿过来了)
INFO : Number of reduce tasks is set to 0 since there's no reduce operator
WARN : Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this.
INFO : number of splits:1
INFO : Submitting tokens for job: job_1573048606490_0005
INFO : The url to track the job: http://HadoopNode00:8088/proxy/application_1573048606490_0005/
INFO : Starting Job = job_1573048606490_0005, Tracking URL = http://HadoopNode00:8088/proxy/application_1573048606490_0005/
INFO : Kill Command = /home/hadoop/hadoop-2.6.0/bin/hadoop job -kill job_1573048606490_0005
INFO : Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 0
INFO : 2019-11-07 13:15:09,391 Stage-1 map = 0%, reduce = 0%
INFO : 2019-11-07 13:15:23,030 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.87 sec
INFO : MapReduce Total cumulative CPU time: 1 seconds 870 msec
INFO : Ended Job = job_1573048606490_0005
INFO : Stage-4 is selected by condition resolver.
INFO : Stage-3 is filtered out by condition resolver.
INFO : Stage-5 is filtered out by condition resolver.
INFO : Moving data to: hdfs://HadoopNode00:9000/user/hive/warehouse/baizhi.db/.hive-staging_hive_2019-11-07_13-14-44_282_9075728133663741551-1/-ext-10001 from hdfs://HadoopNode00:9000/user/hive/warehouse/baizhi.db/.hive-staging_hive_2019-11-07_13-14-44_282_9075728133663741551-1/-ext-10003
INFO : Moving data to: hdfs://HadoopNode00:9000/user/hive/warehouse/baizhi.db/temp1 from hdfs://HadoopNode00:9000/user/hive/warehouse/baizhi.db/.hive-staging_hive_2019-11-07_13-14-44_282_9075728133663741551-1/-ext-10001
INFO : Table baizhi.temp1 stats: [numFiles=1, numRows=9, totalSize=533, rawDataSize=524]
No rows affected (41.943 seconds)
#自己的笔记
0: jdbc:hive2://HadoopNode00:10000> select * from temp1; #查表
+----------------+------------+--------------------------+----------------------+--+
| temp1.ip | temp1.app | temp1.service | temp1.last_time |
+----------------+------------+--------------------------+----------------------+--+
| 192.168.0.1 | qq | com.xx.xx.XxxService#xx | 2018-10-10 10:10:00 |
| 192.168.2.1 | qq | com.xx.xx.XxxService#xx | 2018-10-10 10:10:00 |
| 192.168.0.1 | xx | com.xx.xx.XxxService#xx | 2018-10-10 10:10:00 |
| 192.168.202.1 | qq | com.xx.xx.XxxService#xx | 2018-10-10 10:10:00 |
| 192.168.2.1 | qq | com.xx.xx.XxxService#xx | 2018-10-10 10:10:00 |
| 192.168.0.2 | xx | com.xx.xx.XxxService#xx | 2018-10-10 10:10:00 |
| 192.168.0.2 | qq | com.xx.xx.XxxService#xx | 2018-10-10 10:10:00 |
| 192.168.2.4 | qq | com.xx.xx.XxxService#xx | 2018-10-10 10:10:00 |
| 192.168.0.4 | xx | com.xx.xx.XxxService#xx | 2018-10-10 10:10:00 |
+----------------+------------+--------------------------+----------------------+--+
9 rows selected (0.301 seconds)
#自己的笔记
0: jdbc:hive2://HadoopNode00:10000> create table t2 like t; # 复制表结构
No rows affected (0.234 seconds)
0: jdbc:hive2://HadoopNode00:10000> desc t2;
+-----------+------------+----------+--+
| col_name | data_type | comment |
+-----------+------------+----------+--+
| id | string | |
| name | string | |
+-----------+------------+----------+--+
2 rows selected (0.147 seconds)
#自己的笔记
0: jdbc:hive2://HadoopNode00:10000> select * from t2; #查表
+--------+----------+--+
| t2.id | t2.name |
+--------+----------+--+
+--------+----------+--+
#自己的总结
#注意:
#(1)as和like的区别。
# 创建表的最简单形式
0: jdbc:hive2://HadoopNode00:10000> create table t(id string,name string) ;
# RDBMS插入数据的方式 不太适用与HIVE 大数据处理
0: jdbc:hive2://HadoopNode00:10000> insert into t values ('1','zs');
# 在t_access 中查询app和ip 插入到表t中
0: jdbc:hive2://HadoopNode00:10000> insert into table t select ip, app from t_access;
# 需要注意的是 插入的时候 需要字段类型和数量一一对应,否则无法插入数据
0: jdbc:hive2://HadoopNode00:10000> insert into table t select * from t_access;
Error: Error while compiling statement: FAILED: SemanticException [Error 10044]: Line 1:18 Cannot insert into target table because column number/types are different 't': Table insclause-0 has 2 columns, but query has 4 columns. (state=42000,code=10044)
# 创建表的时候直接全盘把数据拿过来 (表结构也拿过来了)
0: jdbc:hive2://HadoopNode00:10000> create table temp1 as select * from t_access;
# 复制表结构
0: jdbc:hive2://HadoopNode00:10000> create table t2 like t;
四、表分类
4.1 管理表(内部表)
内部表与数据库中的Table在概念上是类似的,每一个内部Table在Hive中都有一个相应目录存储数据,所有的Table数据(不包括External Table)都保存在这个目录中。删除表时,元数据与数据都会被删除。
#自己的笔记
#内部表与数据库中的Table在概念上是类似的,每一个内部Table在Hive中都有一个相应目录存储数据,所有的Table数据(不包括External Table)都保存在这个目录中。
#怎样理解:
#WEBUI界面:
#/user/hive/warehouse/baizhi.db/ 此处可以查看自己创建了那哪表表
#自己的笔记
0: jdbc:hive2://HadoopNode00:10000> drop table t; #删除表时,元数据与数据都会被删除。
No rows affected (0.373 seconds)
#自己的笔记
0: jdbc:hive2://HadoopNode00:10000> desc t; #
Error: Error while compiling statement: FAILED: SemanticException [Error 10001]: Table not found t (state=42S02,code=10001)
#自己的笔记
0: jdbc:hive2://HadoopNode00:10000> select * from t; #
Error: Error while compiling statement: FAILED: SemanticException [Error 10001]: Line 1:14 Table not found 't' (state=42S02,code=10001)
#自己的笔记:
#总结:
#(1):与之对立的表是外部表。
4.2 外部表
在创建表的时候可以指定external关键字创建外部表,外部表对应的文件存储在location指定的目录下,向该目录添加新文件的同时,该表也会读取到该文件(当然文件格式必须跟表定义的一致),删除外部表的同时并不会删除location指定目录下的文件。在删除内部表的时候,内部表的元数据和数据会被一起删除(此句话同上)。
删除表,保留表中的数据- 推荐 external
#自己的笔记
0: jdbc:hive2://HadoopNode00:10000> drop table t_user_c; #删除表
No rows affected (0.219 seconds)
#自己的笔记
0: jdbc:hive2://HadoopNode00:10000> show tables; #展示表
+------------------------+--+
| tab_name |
+------------------------+--+
| t2 |
| t_access |
| t_csv |
| t_json |
| t_user |
| temp1 |
| values__tmp__table__1 |
+------------------------+--+
7 rows selected (0.067 seconds)
#自己的笔记
0: jdbc:hive2://HadoopNode00:10000> create external table t_user_c( #创建表
0: jdbc:hive2://HadoopNode00:10000> id int,
0: jdbc:hive2://HadoopNode00:10000> name string,
0: jdbc:hive2://HadoopNode00:10000> birthday date,
0: jdbc:hive2://HadoopNode00:10000> salary double,
0: jdbc:hive2://HadoopNode00:10000> hobbies array<string>,
0: jdbc:hive2://HadoopNode00:10000> card map<string,string>,
0: jdbc:hive2://HadoopNode00:10000> address struct<country:string,city:string>
0: jdbc:hive2://HadoopNode00:10000> )
0: jdbc:hive2://HadoopNode00:10000> row format delimited
0: jdbc:hive2://HadoopNode00:10000> fields terminated by ','
0: jdbc:hive2://HadoopNode00:10000> collection items terminated by '|'
0: jdbc:hive2://HadoopNode00:10000> map keys terminated by '>'
0: jdbc:hive2://HadoopNode00:10000> lines terminated by '\n';
No rows affected (0.249 seconds)
#自己的笔记
0: jdbc:hive2://HadoopNode00:10000> show tables; #展示表
+------------------------+--+
| tab_name |
+------------------------+--+
| t2 |
| t_access |
| t_csv |
| t_json |
| t_user |
| t_user_c |
| temp1 |
| values__tmp__table__1 |
+------------------------+--+
#自己的笔记
0: jdbc:hive2://HadoopNode00:10000> desc t_user_c; #描述表
+-----------+-------------------------------------+----------+--+
| col_name | data_type | comment |
+-----------+-------------------------------------+----------+--+
| id | int | |
| name | string | |
| birthday | date | |
| salary | double | |
| hobbies | array<string> | |
| card | map<string,string> | |
| address | struct<country:string,city:string> | |
+-----------+-------------------------------------+----------+--+
#自己的笔记
0: jdbc:hive2://HadoopNode00:10000> load data local inpath '/root/t_user_v' into table t_user_c;#外部导入 ---- (从本地文件系统导入)
INFO : Loading data to table baizhi.t_user_c from file:/root/t_user_v
INFO : Table baizhi.t_user_c stats: [numFiles=1, totalSize=346]
No rows affected (0.342 seconds)
#自己的笔记
0: jdbc:hive2://HadoopNode00:10000> select * from t_user_c; #查看表
+--------------+----------------+--------------------+------------------+-------------------+-------------------------------------+-----------------------------------+--+
| t_user_c.id | t_user_c.name | t_user_c.birthday | t_user_c.salary | t_user_c.hobbies | t_user_c.card | t_user_c.address |
+--------------+----------------+--------------------+------------------+-------------------+-------------------------------------+-----------------------------------+--+
| 1 | zhangsan | 2019-11-07 | 20100.0 | ["TV","GAME"] | {"JIANSHE":"001","ZHAOSHAN":"002"} | {"country":"CHAINA","city":"BJ"} |
| 2 | lisi | 2019-11-07 | 20100.0 | ["TV","GAME"] | {"JIANSHE":"002","ZHAOSHAN":"006"} | {"country":"CHAINA","city":"BJ"} |
| 3 | wangwu | 2019-11-07 | 20100.0 | ["TV","GAME"] | {"JIANSHE":"003","ZHAOSHAN":"007"} | {"country":"CHAINA","city":"BJ"} |
| 4 | ermazi | 2019-11-07 | 20070.0 | ["TV","GAME"] | {"JIANSHE":"004","ZHAOSHAN":"008"} | {"country":"CHAINA","city":"BJ"} |
| 5 | ergouzi | 2019-11-07 | 21000.0 | ["TV","GAME"] | {"JIANSHE":"005","ZHAOSHAN":"009"} | {"country":"CHAINA","city":"BJ"} |
+--------------+----------------+--------------------+------------------+-------------------+-------------------------------------+-----------------------------------+--+
5 rows selected (0.174 seconds)
#自己的笔记
#WEBui界面测死
#/user/hive/warehouse/baizhi.db/t_user_c
#自己的笔记
0: jdbc:hive2://HadoopNode00:10000> desc formatted t_user_c; #描述表
+-------------------------------+------------------------------------------------------------------+-----------------------+--+
| col_name | data_type | comment |
+-------------------------------+------------------------------------------------------------------+-----------------------+--+
| # col_name | data_type | comment |
| | NULL | NULL |
| id | int | |
| name | string | |
| birthday | date | |
| salary | double | |
| hobbies | array<string> | |
| card | map<string,string> | |
| address | struct<country:string,city:string> | |
| | NULL | NULL |
| # Detailed Table Information | NULL | NULL |
| Database: | baizhi | NULL |
| Owner: | root | NULL |
| CreateTime: | Thu Nov 07 13:36:42 CST 2019 | NULL |
| LastAccessTime: | UNKNOWN | NULL |
| Protect Mode: | None | NULL |
| Retention: | 0 | NULL |
| Location: | hdfs://HadoopNode00:9000/user/hive/warehouse/baizhi.db/t_user_c | NULL |
| Table Type: | EXTERNAL_TABLE #注意此处 | NULL |
| Table Parameters: | NULL | NULL |
| | COLUMN_STATS_ACCURATE | true |
| | EXTERNAL | TRUE |
| | numFiles | 1 |
| | totalSize | 346 |
| | transient_lastDdlTime | 1573105260 |
| | NULL | NULL |
| # Storage Information | NULL | NULL |
| SerDe Library: | org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe | NULL |
| InputFormat: | org.apache.hadoop.mapred.TextInputFormat | NULL |
| OutputFormat: | org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat | NULL |
| Compressed: | No | NULL |
| Num Buckets: | -1 | NULL |
| Bucket Columns: | [] | NULL |
| Sort Columns: | [] | NULL |
| Storage Desc Params: | NULL | NULL |
| | colelction.delim | | |
| | field.delim | , |
| | line.delim | \n |
| | mapkey.delim | > |
| | serialization.format | , |
+-------------------------------+------------------------------------------------------------------+-----------------------+--+
40 rows selected (0.165 seconds)
#自己的笔记
#WEBUI界面下:/user/hive/warehouse/baizhi.db/t_user_c下:
#t_user_v;
#自己的笔记
0: jdbc:hive2://HadoopNode00:10000> drop table t_user_c; #删除表
No rows affected (0.22 seconds)
#自己的笔记
#WEBUI界面下:/user/hive/warehouse/baizhi.db/t_user_c下:
#t_user_v;
#自己的笔记
0: jdbc:hive2://HadoopNode00:10000> drop table t_user_v; #删除表
No rows affected (0.023 seconds)
#自己的笔记
#WEBUI界面下:/user/hive/warehouse/baizhi.db/t_user_c下:
#t_user_v;
#自己的笔记
0: jdbc:hive2://HadoopNode00:10000> show tables; #展示表s
+------------------------+--+
| tab_name |
+------------------------+--+
| t2 |
| t_access |
| t_csv |
| t_json |
| t_user |
| temp1 |
| values__tmp__table__1 |
+------------------------+--+
7 rows selected (0.055 seconds)
#自己的笔记
7 rows selected (0.055 seconds)
0: jdbc:hive2://HadoopNode00:10000> create external table t_user_a( #创建表
0: jdbc:hive2://HadoopNode00:10000> id int,
0: jdbc:hive2://HadoopNode00:10000> name string,
0: jdbc:hive2://HadoopNode00:10000> birthday date,
0: jdbc:hive2://HadoopNode00:10000> salary double,
0: jdbc:hive2://HadoopNode00:10000> hobbies array<string>,
0: jdbc:hive2://HadoopNode00:10000> card map<string,string>,
0: jdbc:hive2://HadoopNode00:10000> address struct<country:string,city:string>
0: jdbc:hive2://HadoopNode00:10000> )
0: jdbc:hive2://HadoopNode00:10000> row format delimited
0: jdbc:hive2://HadoopNode00:10000> fields terminated by ','
0: jdbc:hive2://HadoopNode00:10000> collection items terminated by '|'
0: jdbc:hive2://HadoopNode00:10000> map keys terminated by '>'
0: jdbc:hive2://HadoopNode00:10000> lines terminated by '\n'
0: jdbc:hive2://HadoopNode00:10000> location '/user/hive/warehouse/baizhi.db/t_user_c';
No rows affected (0.147 seconds)
#location 指定当前这个去读取那个目录下的数据。
#自己的笔记
0: jdbc:hive2://HadoopNode00:10000> show tables; #展示表
+------------------------+--+
| tab_name |
+------------------------+--+
| t2 |
| t_access |
| t_csv |
| t_json |
| t_user |
| t_user_a |
| temp1 |
| values__tmp__table__1 |
+------------------------+--+
8 rows selected (0.053 seconds)
0: jdbc:hive2://HadoopNode00:10000> desc table t_user_a;
Error: Error while compiling statement: FAILED: ParseException line 1:5 Failed to recognize predicate 'table'. Failed rule: 'identifier' in specifying table types (state=42000,code=40000)
#自己的笔记
0: jdbc:hive2://HadoopNode00:10000> desc t_user_a; #描述表
+-----------+-------------------------------------+----------+--+
| col_name | data_type | comment |
+-----------+-------------------------------------+----------+--+
| id | int | |
| name | string | |
| birthday | date | |
| salary | double | |
| hobbies | array<string> | |
| card | map<string,string> | |
| address | struct<country:string,city:string> | |
+-----------+-------------------------------------+----------+--+
7 rows selected (0.188 seconds)
#自己的笔记
0: jdbc:hive2://HadoopNode00:10000> select * from t_user_a; #查询表
+--------------+----------------+--------------------+------------------+-------------------+-------------------------------------+-----------------------------------+--+
| t_user_a.id | t_user_a.name | t_user_a.birthday | t_user_a.salary | t_user_a.hobbies | t_user_a.card | t_user_a.address |
+--------------+----------------+--------------------+------------------+-------------------+-------------------------------------+-----------------------------------+--+
| 1 | zhangsan | 2019-11-07 | 20100.0 | ["TV","GAME"] | {"JIANSHE":"001","ZHAOSHAN":"002"} | {"country":"CHAINA","city":"BJ"} |
| 2 | lisi | 2019-11-07 | 20100.0 | ["TV","GAME"] | {"JIANSHE":"002","ZHAOSHAN":"006"} | {"country":"CHAINA","city":"BJ"} |
| 3 | wangwu | 2019-11-07 | 20100.0 | ["TV","GAME"] | {"JIANSHE":"003","ZHAOSHAN":"007"} | {"country":"CHAINA","city":"BJ"} |
| 4 | ermazi | 2019-11-07 | 20070.0 | ["TV","GAME"] | {"JIANSHE":"004","ZHAOSHAN":"008"} | {"country":"CHAINA","city":"BJ"} |
| 5 | ergouzi | 2019-11-07 | 21000.0 | ["TV","GAME"] | {"JIANSHE":"005","ZHAOSHAN":"009"} | {"country":"CHAINA","city":"BJ"} |
+--------------+----------------+--------------------+------------------+-------------------+-------------------------------------+-----------------------------------+--+
5 rows selected (0.24 seconds)
1,zhangsan,2019-11-07,20100,TV|GAME,JIANSHE>001|ZHAOSHAN>002,CHAINA|BJ
2,lisi,2019-11-07,20100,TV|GAME,JIANSHE>002|ZHAOSHAN>006,CHAINA|BJ
3,wangwu,2019-11-07,20100,TV|GAME,JIANSHE>003|ZHAOSHAN>007,CHAINA|BJ
4,ermazi,2019-11-07,20070,TV|GAME,JIANSHE>004|ZHAOSHAN>008,CHAINA|BJ
5,ergouzi,2019-11-07,21000,TV|GAME,JIANSHE>005|ZHAOSHAN>009,CHAINA|BJ
------
create external table t_user_c(
id int,
name string,
birthday date,
salary double,
hobbies array<string>,
card map<string,string>,
address struct<country:string,city:string>
)
row format delimited
fields terminated by ','
collection items terminated by '|'
map keys terminated by '>'
lines terminated by '\n';
-- 指定路径信息 --- 指定这个表是由谁来创建的。
create external table t_user_a(
id int,
name string,
birthday date,
salary double,
hobbies array<string>,
card map<string,string>,
address struct<country:string,city:string>
)
row format delimited
fields terminated by ','
collection items terminated by '|'
map keys terminated by '>'
lines terminated by '\n'
location '/user/hive/warehouse/baizhi.db/t_user_c';
4.3 分区表
庞大的数据集可能需要耗费大量的时间去处理。在许多场景下,可以通过分区或切片的方法减少每一次扫描总数据量,这种做法可以显著地改善性能。数据会依照单个或多个列进行分区,通常按照时间、地域或者是商业维度进行分区。比如电影表,分区的依据可以是电影的种类和评级,另外,按照拍摄时间划分可能会得到更一致的结果。为了达到性能表现的一致性,对不同列的划分应该让数据尽可能均匀分布。最好的情况下,分区的划分条件总是能够对应where语句的部分查询条件。
为了对表进行合理的管理以及提高查询效率,Hive可以将表组织成“分区”。分区是表的部分列的集合,可以为频繁使用的数据建立分区,这样查找分区中的数据时就不需要扫描全表,这对于提高查找效率很有帮助。分区表是一种根据“分区列”(partition column)的值对表进行粗略划分的机制。Hive中的每个分区表对应数据库中相应分区列的一个索引,每个分区表对应着表下的一个目录,在HDFS上的表现形式与表在HDFS上的表现形式相同,都是以子目录的形式存在。但是由于HDFS并不支持大量的子目录,这也给分区的使用带来了限制。我们有必要对表中的分区数量进行预估,从而避免因为分区数量过大带来一系列问题。Hive查询通常使用分区的列作为查询条件。这样的做法可以指定MapReduce任务在HDFS中指定的子目录下完成扫描的工作。HDFS的文件目录结构可以像索引一样高效利用。
#自己的笔记
1,zhangsan,2019-11-07,20100,TV|GAME,JIANSHE>001|ZHAOSHAN>002
2,lisi,2019-11-07,20100,TV|GAME,JIANSHE>002|ZHAOSHAN>006
3,wangwu,2019-11-07,20100,TV|GAME,JIANSHE>003|ZHAOSHAN>007
4,ermazi,2019-11-07,20070,TV|GAME,JIANSHE>004|ZHAOSHAN>008
5,ergouzi,2019-11-07,21000,TV|GAME,JIANSHE>005|ZHAOSHAN>009
#自己的笔记
#准备数据
[root@HadoopNode00 ~]# vi t_user_bj;
[root@HadoopNode00 ~]# more t_user_bj;
1,zhangsan,2019-11-07,20100,TV|GAME,JIANSHE>001|ZHAOSHAN>002
2,lisi,2019-11-07,20100,TV|GAME,JIANSHE>002|ZHAOSHAN>006
3,wangwu,2019-11-07,20100,TV|GAME,JIANSHE>003|ZHAOSHAN>007
4,ermazi,2019-11-07,20070,TV|GAME,JIANSHE>004|ZHAOSHAN>008
5,ergouzi,2019-11-07,21000,TV|GAME,JIANSHE>005|ZHAOSHAN>009
#自己的笔记
hive> create external table t_user_p( #创建分区表
> id int,
> name string,
> birthday date,
> salary double
> )
> partitioned by(country string,city string)
> row format delimited
> fields terminated by ','
> collection items terminated by '|'
> map keys terminated by '>'
> lines terminated by '\n';
OK
Time taken: 0.384 seconds
#自己的笔记
Time taken: 0.384 seconds
hive> show tables; #展示表
OK
t2
t_access
t_csv
t_json
t_user
t_user_a
t_user_p
temp1
Time taken: 0.044 seconds, Fetched: 8 row(s
#自己的笔记
hive> load data local inpath '/root/t_user_bj' overwrite into table t_user_p partition(country='CHAINA',city='BJ'); #导入数据并且指定分区
Loading data to table baizhi.t_user_p partition (country=CHAINA, city=BJ)
Partition baizhi.t_user_p{country=CHAINA, city=BJ} stats: [numFiles=1, numRows=0, totalSize=296, rawDataSize=0]
OK
Time taken: 1.289 seconds
#自己的笔记
hive> select * from t_user_p; #查表
OK
1 zhangsan 2019-11-07 20100.0 CHAINA BJ
2 lisi 2019-11-07 20100.0 CHAINA BJ
3 wangwu 2019-11-07 20100.0 CHAINA BJ
4 ermazi 2019-11-07 20070.0 CHAINA BJ
5 ergouzi 2019-11-07 21000.0 CHAINA BJ
Time taken: 0.18 seconds, Fetched: 5 row(s)
#自己的笔记
#WEBUI界面测试:
#/user/hive/warehouse/baizhi.db/t_user_p/country=CHAINA/city=BJ下:
#t_user_bj
1,zhangsan,2019-11-07,20100,TV|GAME,JIANSHE>001|ZHAOSHAN>002
2,lisi,2019-11-07,20100,TV|GAME,JIANSHE>002|ZHAOSHAN>006
3,wangwu,2019-11-07,20100,TV|GAME,JIANSHE>003|ZHAOSHAN>007
4,ermazi,2019-11-07,20070,TV|GAME,JIANSHE>004|ZHAOSHAN>008
5,ergouzi,2019-11-07,21000,TV|GAME,JIANSHE>005|ZHAOSHAN>009
#自己的笔记
#总结:
#(1)观察文件夹的区别。
#自己的笔记
hive> show partitions t_user_p; #展示分区
OK
country=CHAINA/city=BJ
Time taken: 0.218 seconds, Fetched: 1 row(s)
#自己的笔记
hive> alter table t_user_p drop partition(country='CHAINA',city='SH'); #删除分区
OK
Time taken: 0.155 seconds
#自己的笔记
hive> show partitions t_user_p; #展示分区
OK
country=CHAINA/city=BJ
Time taken: 0.114 seconds, Fetched: 1 row(s)
hive> show partitions t_user_p;
OK
country=CHAINA/city=BJ
Time taken: 0.119 seconds, Fetched: 1 row(s)
#自己的笔记
hive> select * from t_user_p; #查表
OK
1 zhangsan 2019-11-07 20100.0 CHAINA BJ
2 lisi 2019-11-07 20100.0 CHAINA BJ
3 wangwu 2019-11-07 20100.0 CHAINA BJ
4 ermazi 2019-11-07 20070.0 CHAINA BJ
5 ergouzi 2019-11-07 21000.0 CHAINA BJ
Time taken: 0.097 seconds, Fetched: 5 row(s)
hive> alter table t_user_p drop partition(country='CHAINA',city='SH');
OK
Time taken: 0.138 seconds
#自己的笔记
hive> select * from t_user_p; #查表
OK
1 zhangsan 2019-11-07 20100.0 CHAINA BJ
2 lisi 2019-11-07 20100.0 CHAINA BJ
3 wangwu 2019-11-07 20100.0 CHAINA BJ
4 ermazi 2019-11-07 20070.0 CHAINA BJ
5 ergouzi 2019-11-07 21000.0 CHAINA BJ
Time taken: 0.096 seconds, Fetched: 5 row(s)
#自己的笔记
hive> alter table t_user_p drop partition(country='CHAINA',city='BJ'); #删除分区
Dropped the partition country=CHAINA/city=BJ
OK
Time taken: 0.881 seconds
#自己的笔记
hive> show partitions t_user_p; #展示分区
OK
Time taken: 0.103 seconds
#自己的笔记
hive> alter table t_user_p add partition(country='china',city='bj'); #添加分区
OK
Time taken: 0.131 seconds
#自己的笔记
hive> show partitions t_user_p; #展示分区
OK
country=china/city=bj
Time taken: 0.119 seconds, Fetched: 1 row(s)
#自己的笔记
#准备文件
[root@HadoopNode00 ~]# hadoop fs -put t_user_bj / #上传到hdfs的根目录下
Java HotSpot(TM) 64-Bit Server VM warning: You have loaded library /home/hadoop/hadoop-2.6.0/lib/native/libhadoop.so.1.0.0 which might have disabled stack guard. The VM will try to fix the stack guard now.
It's highly recommended that you fix the library with 'execstack -c <libfile>', or link it with '-z noexecstack'.
19/11/07 16:21:20 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
#自己的笔记
hive> alter table t_user_p add partition(country='CHINA1',city='SH1') location 't_user_bj';#指定文件的位置(文件的位置为hdfs文件系统的位置)
OK
Time taken: 0.109 seconds
#自己的笔记
#shell命令测试
hive> show partitions t_user_p; #展示分区
OK
country=CHINA/city=SH
country=CHINA1/city=SH1
country=china/city=bj
#自己的笔记
#WEBUI界面测试
#hdfs文件系统中:
#t_user_bj下:
1,zhangsan,2019-11-07,20100,TV|GAME,JIANSHE>001|ZHAOSHAN>002
2,lisi,2019-11-07,20100,TV|GAME,JIANSHE>002|ZHAOSHAN>006
3,wangwu,2019-11-07,20100,TV|GAME,JIANSHE>003|ZHAOSHAN>007
4,ermazi,2019-11-07,20070,TV|GAME,JIANSHE>004|ZHAOSHAN>008
5,ergouzi,2019-11-07,21000,TV|GAME,JIANSHE>005|ZHAOSHAN>009
#自己的笔记
#文件夹的准备
[root@HadoopNode00 ~]# hadoop fs -mkdir /sh #创建文件夹
Java HotSpot(TM) 64-Bit Server VM warning: You have loaded library /home/hadoop/hadoop-2.6.0/lib/native/libhadoop.so.1.0.0 which might have disabled stack guard. The VM will try to fix the stack guard now.
It's highly recommended that you fix the library with 'execstack -c ' , or link it with '-z noexecstack'.
19/11/07 16:31:36 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
mkdir: `/sh': File exists
#自己的笔记
[root@HadoopNode00 ~]# hadoop fs -cp /t_user_bj /sh/t_user_sh; #移动到sh这个文件夹下面
Java HotSpot(TM) 64-Bit Server VM warning: You have loaded library /home/hadoop/hadoop-2.6.0/lib/native/libhadoop.so.1.0.0 which might have disabled stack guard. The VM will try to fix the stack guard now.
It's highly recommended that you fix the library with 'execstack -c ' , or link it with '-z noexecstack'.
19/11/07 16:33:21 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
#自己的笔记
hive> alter table t_user_p add partition(country='CHINA2',city='SH2') location 'sh';
OK
Time taken: 0.157 seconds
#自己的笔记
hive> show partitions t_user_p; #展示所有的分区
OK
country=CHINA/city=SH
country=CHINA1/city=SH1
country=CHINA2/city=SH2
country=china/city=bj
Time taken: 0.093 seconds, Fetched: 4 row(s)
#WEBUI 界面测试、
#WENUI ---界面测试
1,zhangsan,2019-11-07,20100,TV|GAME,JIANSHE>001|ZHAOSHAN>002
2,lisi,2019-11-07,20100,TV|GAME,JIANSHE>002|ZHAOSHAN>006
3,wangwu,2019-11-07,20100,TV|GAME,JIANSHE>003|ZHAOSHAN>007
4,ermazi,2019-11-07,20070,TV|GAME,JIANSHE>004|ZHAOSHAN>008
5,ergouzi,2019-11-07,21000,TV|GAME,JIANSHE>005|ZHAOSHAN>009
#自己的笔记
#shell命令测试
hive> select * from t_user_p where city = 'SH'; #查询city是SH的数据
OK
1 zhangsan 2019-11-07 20100.0 CHINA SH
2 lisi 2019-11-07 20100.0 CHINA SH
3 wangwu 2019-11-07 20100.0 CHINA SH
4 ermazi 2019-11-07 20070.0 CHINA SH
5 ergouzi 2019-11-07 21000.0 CHINA SH
create external table t_user(
id int,
name string,
birthday date,
salary double
country string,
city string
)
row format delimited
fields terminated by ','
collection items terminated by '|'
map keys terminated by '>'
lines terminated by '\n'
--------------------
create external table t_user_p(
id int,
name string,
birthday date,
salary double
)
partitioned by(country string,city string)
row format delimited
fields terminated by ','
collection items terminated by '|'
map keys terminated by '>'
lines terminated by '\n'
# 导入数据 并且指定分区
0: jdbc:hive2://CentOS:10000> load data local inpath '/root/t_user_bj' overwrite into table t_user_p partition(country='CHAINA',city='BJ');
0: jdbc:hive2://CentOS:10000> show partitions t_user_p;
+------------------------+--+
| partition |
+------------------------+--+
| country=china/city=bj |
| country=china/city=sh |
+------------------------+--+
# 删除分区
0: jdbc:hive2://CentOS:10000> alter table t_user_p drop partition(country='CHINA',city='BJ');
INFO : Dropped the partition country=china/city=bj
No rows affected (0.496 seconds)
# 添加分区
0: jdbc:hive2://CentOS:10000> alter table t_user_p add partition(country='china',city='bj');
# 添加分区并且指定分区数据
0: jdbc:hive2://CentOS:10000> alter table t_user_p add partition(country='CHINA',city='SH') location 't_user_bj';
#自己的笔记
#复习:
#什么是Hive
#(1)工具(将SQL语句翻译成MRJOB)
#(2)符合SQL标准
#(3)数据存储---存在HDFS上
#(4)元数据:存在mysql
#(5)数据本身:与表结构相关 ---- 这样子才能映射。
#创建表,默认不指定分隔符
#指定的情况下,存在表结构中
#再进行数据的导入使,数据本身之间的分隔符服必须符合创建表示所指定的分隔符数据和结构之间必须完美契合。
#自己的笔记
#分区表
#查找个人信息
#中国|河南省|郑州市|金水区|文化路街道
#总结:再导入数据的时候,分区的数据是无需存在于数据中,是在导入的时候直接指定。
五、Hive QL 操作
5.1 Select 语句
使用正则表达式指定列
#自己的笔记
#准备数据
#创建数据文件
#(1)log.txt 将数据上传到linux文件下面 ---- 对log.txt 进行数据清洗(添加UUID)
#(2)access.log 将文件上传至linux服务器
#自己的笔记
[root@HadoopNode00 ~]# sh hiveconn.sh #用脚本连接hive
▒▒▒hive
▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒
| author▒▒GuoJiafeng |
| company▒▒Baizhi |
▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒
beeline -u jdbc:hive2://HadoopNode00:10000 -n root
Connecting to jdbc:hive2://HadoopNode00:10000
Connected to: Apache Hive (version 1.2.1)
Driver: Hive JDBC (version 1.2.1)
Transaction isolation: TRANSACTION_REPEATABLE_READ
Beeline version 1.2.1 by Apache Hive
#自己的笔记
0: jdbc:hive2://HadoopNode00:10000> show databases; #展示库
+----------------+--+
| database_name |
+----------------+--+
| baizhi |
| default |
+----------------+--+
2 rows selected (3.364 seconds)
#自己的笔记
0: jdbc:hive2://HadoopNode00:10000> use baizhi; #用baizhi
No rows affected (0.755 seconds)
#自己的笔记
0: jdbc:hive2://HadoopNode00:10000> show tables; #展示表
+-----------+--+
| tab_name |
+-----------+--+
| t2 |
| t_access |
| t_csv |
| t_json |
| t_user |
| t_user_a |
| t_user_p |
| temp1 |
+-----------+--+
8 rows selected (0.973 seconds)
0: jdbc:hive2://HadoopNode00:10000>
#自己的笔记
0: jdbc:hive2://HadoopNode00:10000> create table #创建表
0: jdbc:hive2://HadoopNode00:10000> logs
0: jdbc:hive2://HadoopNode00:10000> (
0: jdbc:hive2://HadoopNode00:10000> uuid string,
0: jdbc:hive2://HadoopNode00:10000> userid string ,
0: jdbc:hive2://HadoopNode00:10000> fromUrl string ,
0: jdbc:hive2://HadoopNode00:10000> dateString string,
0: jdbc:hive2://HadoopNode00:10000> timeString string,
0: jdbc:hive2://HadoopNode00:10000> ipAddress string,
0: jdbc:hive2://HadoopNode00:10000> browserName string,
0: jdbc:hive2://HadoopNode00:10000> pcSystemNameOrmobileBrandName string ,
0: jdbc:hive2://HadoopNode00:10000> systemVersion string,
0: jdbc:hive2://HadoopNode00:10000> language string,
0: jdbc:hive2://HadoopNode00:10000> cityName string
0: jdbc:hive2://HadoopNode00:10000> )
0: jdbc:hive2://HadoopNode00:10000> partitioned BY (day string)
0: jdbc:hive2://HadoopNode00:10000> row format delimited fields terminated
0: jdbc:hive2://HadoopNode00:10000> by ' ';
No rows affected (3.384 seconds)
#自己的笔记
0: jdbc:hive2://HadoopNode00:10000> show tables; #展示表
+-----------+--+
| tab_name |
+-----------+--+
| logs | #注意此处
| t2 |
| t_access |
| t_csv |
| t_json |
| t_user |
| t_user_a |
| t_user_p |
| temp1 |
+-----------+--+
9 rows selected (0.207 seconds)
#自己的笔记
#WEBUI界面测试
#/user/hive/warehouse/baizhi.db下:
#logs
#自己的笔记
#
#
#load data local inpath '/clean01' into table logs partition(day='2019-05-09');
#数据有缺陷 ---- 分区的数据还是在文件中(分区的数据不应该数据文件中)。
#自己的笔记
0: jdbc:hive2://HadoopNode00:10000> load data local inpath '/root/access.log' into table logs partition(day='2019-05-09'); #从外部导入(从HDFS导入)
INFO : Loading data to table baizhi.logs partition (day=2019-05-09) from file:/root/access.log
INFO : Partition baizhi.logs{day=2019-05-09} stats: [numFiles=1, numRows=0, totalSize=63580, rawDataSize=0]
No rows affected (3.331 seconds)
#自己的笔记
0: jdbc:hive2://HadoopNode00:10000> select * from logs; #查
。。。。(289行的数据)
289 rows selected (2.149 seconds)
#数据的乱码问题怎样解决?????? 是文件的格式不正确码
#自己的笔记
0: jdbc:hive2://HadoopNode00:10000> select uuid from logs; #查询uuid
。。。。(289行的数据)
289 rows selected (0.467 seconds)
create table
logs
(
uuid string,
userid string ,
fromUrl string ,
dateString string,
timeString string,
ipAddress string,
browserName string,
pcSystemNameOrmobileBrandName string ,
systemVersion string,
language string,
cityName string
)
partitioned BY (day string)
row format delimited fields terminated
by ' ';
load data local inpath '/clean01' into table logs partition(day='2019-05-09');
#自己的笔记
0: jdbc:hive2://HadoopNode00:10000> select userid ,`.*string` from logs; #
Error: Error while compiling statement: FAILED: SemanticException [Error 10004]: Line 1:17 Invalid table alias or column reference '.*string': (possible column names are: uuid, userid, fromurl, datestring, timestring, ipaddress, browsername, pcsystemnameormobilebrandname, systemversion, language, cityname, day) (state=42000,code=10004)
#自己的笔记
0: jdbc:hive2://HadoopNode00:10000> set hive.support.quoted.identifiers=none;# 设置此属性 开启正则匹配
No rows affected (0.04 seconds)
#自己的笔记
0: jdbc:hive2://HadoopNode00:10000> select userid
,`.*string` from logs; #查询userid,dataString,timeString的三行值 --- 此处还是反引号
。。。。(289行的数据)
289 rows selected (0.357 seconds)
# 设置此属性 开启正则匹配
set hive.support.quoted.identifiers=none;
# 使用正则表达式查找string相关字段的信息 注意 引号为反引号 (esc下面那个)
select userid ,`.*string` from logs;

5.2 Where 语句
Where 作为SQL中的条件查询
#自己的笔记
0: jdbc:hive2://HadoopNode00:10000> select * from logs where userid ='707a2a9c-c89f-4041-a276-df12611a9363';
0: jdbc:hive2://HadoopNode00:10000> select * from logs where userid ='707a2a9c-c89f-4041-a276-df12611a9363';
5.3 Group By
聚合函数
#自己的笔记
#准备数据文件
#自己的笔记
0: jdbc:hive2://HadoopNode00:10000> show tables; #展示所有表
+-----------+--+
| tab_name |
+-----------+--+
| logs |
| t2 |
| t_access |
| t_csv |
| t_json |
| t_user |
| t_user_a |
| t_user_p |
| temp1 |
+-----------+--+
9 rows selected (0.172 seconds)
0: jdbc:hive2://HadoopNode00:10000> desc t_user;#描述表
+-----------+-------------------------------------+----------+--+
| col_name | data_type | comment |
+-----------+-------------------------------------+----------+--+
| id | int | |
| name | string | |
| birthday | date | |
| salary | double | |
| hobbbies | array<string> | |
| card | map<string,string> | |
| address | struct<country:string,city:string> | |
+-----------+-------------------------------------+----------+--+
7 rows selected (0.171 seconds)
0: jdbc:hive2://HadoopNode00:10000>
#自己的笔记
0: jdbc:hive2://HadoopNode00:10000> select * from t_user; #查表
+------------+--------------+------------------+----------------+------------------+--------------------+---------------------------------------+--+
| t_user.id | t_user.name | t_user.birthday | t_user.salary | t_user.hobbbies | t_user.card | t_user.address |
+------------+--------------+------------------+----------------+------------------+--------------------+---------------------------------------+--+
| 1 | zs | 2012-11-12 | 20000.0 | ["TV","GAME"] | {"JIANSHE":"001"} | {"country":"CHINA","city":"BEIJING"} |
+------------+--------------+------------------+----------------+------------------+--------------------+---------------------------------------+--+
1 row selected (0.589 seconds)
#自己的笔记
0: jdbc:hive2://HadoopNode00:10000> select address.city as city ,avg(salary) as avgSalary from t_user group by address.city; #按照城市分组并且查询平均工资 ---- 还启动了MR
INFO : Number of reduce tasks not specified. Estimated from input data size: 1
INFO : In order to change the average load for a reducer (in bytes):
INFO : set hive.exec.reducers.bytes.per.reducer=<number>
INFO : In order to limit the maximum number of reducers:
INFO : set hive.exec.reducers.max=<number>
INFO : In order to set a constant number of reducers:
INFO : set mapreduce.job.reduces=<number>
WARN : Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this.
INFO : number of splits:1
INFO : Submitting tokens for job: job_1573048606490_0008
INFO : The url to track the job: http://HadoopNode00:8088/proxy/application_1573048606490_0008/
INFO : Starting Job = job_1573048606490_0008, Tracking URL = http://HadoopNode00:8088/proxy/application_1573048606490_0008/
INFO : Kill Command = /home/hadoop/hadoop-2.6.0/bin/hadoop job -kill job_1573048606490_0008
INFO : Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
INFO : 2019-11-07 18:46:23,304 Stage-1 map = 0%, reduce = 0%
INFO : 2019-11-07 18:46:38,222 Stage-1 map = 100%, reduce = 0%, Cumulat ive CPU 1.32 sec
INFO : 2019-11-07 18:47:07,373 Stage-1 map = 100%, reduce = 100%, Cumul ative CPU 3.63 sec
INFO : MapReduce Total cumulative CPU time: 3 seconds 630 msec
INFO : Ended Job = job_1573048606490_0008
+----------+------------+--+
| city | avgsalary |
+----------+------------+--+
| BEIJING | 20000.0 |
+----------+------------+--+
1 row selected (99.603 seconds)
0: jdbc:hive2://HadoopNode00:10000> select address.city as city ,avg(salary) as avgSalary from t_user group by address.city;

5.4 Join 语句
内连接
#自己的笔记
#准备数据
0: jdbc:hive2://HadoopNode00:10000> create table testuser( #创建表
0: jdbc:hive2://HadoopNode00:10000> id int,
0: jdbc:hive2://HadoopNode00:10000> name string,
0: jdbc:hive2://HadoopNode00:10000> sex boolean,
0: jdbc:hive2://HadoopNode00:10000> age int,
0: jdbc:hive2://HadoopNode00:10000> salary double,
0: jdbc:hive2://HadoopNode00:10000> hobbies array<string>,
0: jdbc:hive2://HadoopNode00:10000> card map<string,string>,
0: jdbc:hive2://HadoopNode00:10000> address struct<country:string,city:string>
0: jdbc:hive2://HadoopNode00:10000> )
0: jdbc:hive2://HadoopNode00:10000> row format delimited
0: jdbc:hive2://HadoopNode00:10000> fields terminated by ','
0: jdbc:hive2://HadoopNode00:10000> collection items terminated by '|'
0: jdbc:hive2://HadoopNode00:10000> map keys terminated by '>'
0: jdbc:hive2://HadoopNode00:10000> lines terminated by '\n';
No rows affected (0.907 seconds)
#自己的笔记
0: jdbc:hive2://HadoopNode00:10000> show tables; #展示所有的表
+-----------+--+
| tab_name |
+-----------+--+
| logs |
| t2 |
| t_access |
| t_csv |
| t_json |
| t_user |
| t_user_a |
| t_user_p |
| temp1 |
| testuser |
+-----------+--+
10 rows selected (0.16 seconds)
#自己的笔记
0: jdbc:hive2://HadoopNode00:10000> desc formatted testuser; #描述表
+-------------------------------+------------------------------------------------------------------+-----------------------+--+
| col_name | data_type | comment |
+-------------------------------+------------------------------------------------------------------+-----------------------+--+
| # col_name | data_type | comment |
| | NULL | NULL |
| id | int | |
| name | string | |
| sex | boolean | |
| age | int | |
| salary | double | |
| hobbies | array<string> | |
| card | map<string,string> | |
| address | struct<country:string,city:string> | |
| | NULL | NULL |
| # Detailed Table Information | NULL | NULL |
| Database: | baizhi | NULL |
| Owner: | root | NULL |
| CreateTime: | Thu Nov 07 18:55:21 CST 2019 | NULL |
| LastAccessTime: | UNKNOWN | NULL |
| Protect Mode: | None | NULL |
| Retention: | 0 | NULL |
| Location: | hdfs://HadoopNode00:9000/user/hive/warehouse/baizhi.db/testuser | NULL |
| Table Type: | MANAGED_TABLE | NULL |
| Table Parameters: | NULL | NULL |
| | transient_lastDdlTime | 1573124121 |
| | NULL | NULL |
| # Storage Information | NULL | NULL |
| SerDe Library: | org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe | NULL |
| InputFormat: | org.apache.hadoop.mapred.TextInputFormat | NULL |
| OutputFormat: | org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat | NULL |
| Compressed: | No | NULL |
| Num Buckets: | -1 | NULL |
| Bucket Columns: | [] | NULL |
| Sort Columns: | [] | NULL |
| Storage Desc Params: | NULL | NULL |
| | colelction.delim | | |
| | field.delim | , |
| | line.delim | \n |
| | mapkey.delim | > |
| | serialization.format | , |
+-------------------------------+------------------------------------------------------------------+-----------------------+--+
37 rows selected (0.686 seconds)
0: jdbc:hive2://HadoopNode00:10000>
#自己的笔记
#准备数据
# vi testuser
[root@HadoopNode00 ~]# vi testuser;
[root@HadoopNode00 ~]# more testuser;
1,zhangsan,true,10,20100,TV|GAME,JIANSHE>001|ZHAOSHAN>002,CHAINA|BJ
2,lisi,false,20,20100,TV|GAME,JIANSHE>002|ZHAOSHAN>006,CHAINA|BJ
3,wangwu,true,30,20100,TV|GAME,JIANSHE>003|ZHAOSHAN>007,CHAINA|HN
4,ermazi,false,49,20070,TV|GAME,JIANSHE>004|ZHAOSHAN>008,CHAINA|SH
5,ergouzi,false,50,21000,TV|GAME,JIANSHE>005|ZHAOSHAN>009,CHAINA|BJ
#自己的笔记
0: jdbc:hive2://HadoopNode00:10000> load data local inpath '/root/testuser' into table testuser;#从外部导入(从HDFS导入)
INFO : Loading data to table baizhi.testuser from file:/root/testuser
INFO : Table baizhi.testuser stats: [numFiles=1, totalSize=334]
No rows affected (0.698 seconds)
#自己的笔记
0: jdbc:hive2://HadoopNode00:10000> select * from testuser; #查表
+--------------+----------------+---------------+---------------+------------------+-------------------+-------------------------------------+-----------------------------------+--+
| testuser.id | testuser.name | testuser.sex | testuser.age | testuser.salary | testuser.hobbies | testuser.card | testuser.address |
+--------------+----------------+---------------+---------------+------------------+-------------------+-------------------------------------+-----------------------------------+--+
| 1 | zhangsan | true | 10 | 20100.0 | ["TV","GAME"] | {"JIANSHE":"001","ZHAOSHAN":"002"} | {"country":"CHAINA","city":"BJ"} |
| 2 | lisi | false | 20 | 20100.0 | ["TV","GAME"] | {"JIANSHE":"002","ZHAOSHAN":"006"} | {"country":"CHAINA","city":"BJ"} |
| 3 | wangwu | true | 30 | 20100.0 | ["TV","GAME"] | {"JIANSHE":"003","ZHAOSHAN":"007"} | {"country":"CHAINA","city":"HN"} |
| 4 | ermazi | false | 49 | 20070.0 | ["TV","GAME"] | {"JIANSHE":"004","ZHAOSHAN":"008"} | {"country":"CHAINA","city":"SH"} |
| 5 | ergouzi | false | 50 | 21000.0 | ["TV","GAME"] | {"JIANSHE":"005","ZHAOSHAN":"009"} | {"country":"CHAINA","city":"BJ"} |
+--------------+----------------+---------------+---------------+------------------+-------------------+-------------------------------------+-----------------------------------+--+
5 rows selected (0.647 seconds)
#自己的笔记
0: jdbc:hive2://HadoopNode00:10000> select a.sex,a.name,a.salary,b.sex,b.name,b.salary from testuser a join testuser b on a.salary = b.salary where a.sex != b.sex;#使用内连接 查询性别不同但是工资相同的人 还启动了MR。
INFO : Execution completed successfully
INFO : MapredLocal task succeeded
INFO : Number of reduce tasks is set to 0 since there's no reduce operator
WARN : Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this.
INFO : number of splits:1
INFO : Submitting tokens for job: job_1573048606490_0009
INFO : The url to track the job: http://HadoopNode00:8088/proxy/application_1573048606490_0009/
INFO : Starting Job = job_1573048606490_0009, Tracking URL = http://HadoopNode00:8088/proxy/application_1573048606490_0009/
INFO : Kill Command = /home/hadoop/hadoop-2.6.0/bin/hadoop job -kill job_1573048606490_0009
INFO : Hadoop job information for Stage-3: number of mappers: 1; number of reducers: 0
INFO : 2019-11-07 19:14:49,624 Stage-3 map = 0%, reduce = 0%
INFO : 2019-11-07 19:15:01,723 Stage-3 map = 100%, reduce = 0%, Cumulative CPU 2.24 sec
INFO : MapReduce Total cumulative CPU time: 2 seconds 240 msec
INFO : Ended Job = job_1573048606490_0009
+--------+-----------+-----------+--------+-----------+-----------+--+
| a.sex | a.name | a.salary | b.sex | b.name | b.salary |
+--------+-----------+-----------+--------+-----------+-----------+--+
| false | lisi | 20100.0 | true | zhangsan | 20100.0 |
| true | zhangsan | 20100.0 | false | lisi | 20100.0 |
| true | wangwu | 20100.0 | false | lisi | 20100.0 |
| false | lisi | 20100.0 | true | wangwu | 20100.0 |
+--------+-----------+-----------+--------+-----------+-----------+--+
4 rows selected (53.723 seconds)
#自己的笔记
0: jdbc:hive2://HadoopNode00:10000> select a.sex,a.name,a.salary,b.sex,b.name,b.salary from testuser a join testuser b on a.salary = b.salary where a.sex = true and b.sex = false; #内连接查询
INFO : Execution completed successfully
INFO : MapredLocal task succeeded
INFO : Number of reduce tasks is set to 0 since there's no reduce operator
WARN : Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this.
INFO : number of splits:1
INFO : Submitting tokens for job: job_1573048606490_0010
INFO : The url to track the job: http://HadoopNode00:8088/proxy/application_1573048606490_0010/
INFO : Starting Job = job_1573048606490_0010, Tracking URL = http://HadoopNode00:8088/proxy/application_1573048606490_0010/
INFO : Kill Command = /home/hadoop/hadoop-2.6.0/bin/hadoop job -kill job_1573048606490_0010
INFO : Hadoop job information for Stage-3: number of mappers: 1; number of reducers: 0
INFO : 2019-11-07 19:17:20,701 Stage-3 map = 0%, reduce = 0%
INFO : 2019-11-07 19:17:46,352 Stage-3 map = 100%, reduce = 0%, Cumulative CPU 2.72 sec
INFO : MapReduce Total cumulative CPU time: 2 seconds 720 msec
INFO : Ended Job = job_1573048606490_0010
+--------+-----------+-----------+--------+---------+-----------+--+
| a.sex | a.name | a.salary | b.sex | b.name | b.salary |
+--------+-----------+-----------+--------+---------+-----------+--+
| true | zhangsan | 20100.0 | false | lisi | 20100.0 |
| true | wangwu | 20100.0 | false | lisi | 20100.0 |
+--------+-----------+-----------+--------+---------+-----------+--+
2 rows selected (53.912 seconds)
create table testuser(
id int,
name string,
sex boolean,
age int,
salary double,
hobbies array<string>,
card map<string,string>,
address struct<country:string,city:string>
)
row format delimited
fields terminated by ','
collection items terminated by '|'
map keys terminated by '>'
lines terminated by '\n';
1,zhangsan,true,10,20100,TV|GAME,JIANSHE>001|ZHAOSHAN>002,CHAINA|BJ
2,lisi,false,20,20100,TV|GAME,JIANSHE>002|ZHAOSHAN>006,CHAINA|BJ
3,wangwu,true,30,20100,TV|GAME,JIANSHE>003|ZHAOSHAN>007,CHAINA|HN
4,ermazi,false,49,20070,TV|GAME,JIANSHE>004|ZHAOSHAN>008,CHAINA|SH
5,ergouzi,false,50,21000,TV|GAME,JIANSHE>005|ZHAOSHAN>009,CHAINA|BJ
# 使用内连接 查询性别不同但是工资相同的人
select a.sex,a.name,a.salary,b.sex,b.name,b.salary from testuser a join testuser b on a.salary = b.salary where a.sex != b.sex;
select a.sex,a.name,a.salary,b.sex,b.name,b.salary from testuser a join testuser b on a.salary = b.salary where a.sex = true and b.sex = false;
#自己的笔记 --- 查询 来自三个不同城市的人且具有第二个爱好相同的人
0: jdbc:hive2://HadoopNode00:10000> select
0: jdbc:hive2://HadoopNode00:10000> a.address.city ,a.name as name ,a.hobbies[1] as hobby,
0: jdbc:hive2://HadoopNode00:10000> b.address.city ,b.name as name, b.hobbies[1] as hobby,
0: jdbc:hive2://HadoopNode00:10000> c.address.city ,c.name as name ,c.hobbies[1] as hobby
0: jdbc:hive2://HadoopNode00:10000> from testuser a
0: jdbc:hive2://HadoopNode00:10000> join testuser b on a.hobbies[1] = b.hobbies[1]
0: jdbc:hive2://HadoopNode00:10000> join testuser c on b.hobbies[1] = c.hobbies[1]
0: jdbc:hive2://HadoopNode00:10000> where a.address.city = 'SH' and b.address.city = 'HN' and c.address.city = 'BJ';
INFO : Execution completed successfully
INFO : MapredLocal task succeeded
INFO : Number of reduce tasks is set to 0 since there's no reduce operator
WARN : Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this.
INFO : number of splits:1
INFO : Submitting tokens for job: job_1573048606490_0011
INFO : The url to track the job: http://HadoopNode00:8088/proxy/application_1573048606490_0011/
INFO : Starting Job = job_1573048606490_0011, Tracking URL = http://HadoopNode00:8088/proxy/application_1573048606490_0011/
INFO : Kill Command = /home/hadoop/hadoop-2.6.0/bin/hadoop job -kill job_1573048606490_0011
INFO : Hadoop job information for Stage-4: number of mappers: 1; number of reducers: 0
INFO : 2019-11-07 19:21:44,043 Stage-4 map = 0%, reduce = 0%
INFO : 2019-11-07 19:21:56,009 Stage-4 map = 100%, reduce = 0%, Cumulative CPU 2.47 sec
INFO : MapReduce Total cumulative CPU time: 2 seconds 470 msec
INFO : Ended Job = job_1573048606490_0011
+-------+---------+--------+-------+---------+--------+-------+-----------+--------+--+
| city | name | hobby | city | name | hobby | city | name | hobby |
+-------+---------+--------+-------+---------+--------+-------+-----------+--------+--+
| SH | ermazi | GAME | HN | wangwu | GAME | BJ | zhangsan | GAME |
| SH | ermazi | GAME | HN | wangwu | GAME | BJ | lisi | GAME |
| SH | ermazi | GAME | HN | wangwu | GAME | BJ | ergouzi | GAME |
+-------+---------+--------+-------+---------+--------+-------+-----------+--------+--+
3 rows selected (34.493 seconds)
查询 来自三个不同城市的人且具有第二个爱好相同的人
select
a.address.city ,a.name as name ,a.hobbies[1] as hobby,
b.address.city ,b.name as name, b.hobbies[1] as hobby,
c.address.city ,c.name as name ,c.hobbies[1] as hobby
from testuser a
join testuser b on a.hobbies[1] = b.hobbies[1]
join testuser c on b.hobbies[1] = c.hobbies[1]
where a.address.city = 'SH' and b.address.city = 'HN' and c.address.city = 'BJ';
JOIN优化
这种优化其实是指手动指定那些数据最大,从而最后查询(和之前查过的,已经缓存上的数据进行对比),这样可以减少服务器的压力
在上述三表连接的操作中,其实就是一种“失误”的写法,为什么呢 ?因为通过比较我们可以发现,来自北京的人最多,也就是说当前a表最大。Hive同时假定查询中最后一个表是最大的那个表。在对每行记录进行连接操作时,它会尝试将其他表缓存起来,然后扫描最后那个表进行计算。因此,用户需要保证连续查询中的表的大小从左到右是依次增加的。
但是咱们将最大的表放在第一个,显然就违反这个逻辑,因为测试数据较小我们根本不会发现有任何差异,但是真正的在生产环境中,我们就需要将表依次从小到大进行排列,来达到效率的最大化。
但是假如我们在书写SQL语句的时候不能将最大的表放在最后,或者忘记放在最后,有什么办法去解决这个问题呢?
幸运的是,用户并非总是要将最大的表放置在查询语句的最后面的。这是因为Hive还提供了一个“标记”机制来显式地告之查询优化器哪张表是大表,来看具体的SQL语句:
#自己的笔记
#增氧把最大表放在最后面??? ---- 采用标记机制
#使用STREAMTABLE关键字
#自己的笔记
hive> select
> /*+STREAMTABLE(a)*/ #对join的优化
> a.address.city as name, a.name, a.hobbies[1] as hobby ,
> b.address.city as name, b.name,b.hobbies[1] as hobby ,
> c.address.city as name, c.name,c.hobbies[1] as hobby
> from testuser a
> join testuser b on a.hobbies[1] = b.hobbies[1]
> join testuser c on a.hobbies[1] = c.hobbies[1]
> where a.address.city = 'BJ' and b.address.city = 'SH' and c.addres s.city = 'HN';
Query ID = root_20191107194554_6de0ca72-de65-4ff7-b2fe-b13f94d5a03a
Total jobs = 1
Java HotSpot(TM) 64-Bit Server VM warning: You have loaded library /home/ hadoop/hadoop-2.6.0/lib/native/libhadoop.so.1.0.0 which might have disabl ed stack guard. The VM will try to fix the stack guard now.
It's highly recommended that you fix the library with 'execstack -c <libf ile>', or link it with '-z noexecstack'.
19/11/07 19:46:09 WARN util.NativeCodeLoader: Unable to load native-hadoo p library for your platform... using builtin-java classes where applicabl e
Execution log at: /tmp/root/root_20191107194554_6de0ca72-de65-4ff7-b2fe-b 13f94d5a03a.log
2019-11-07 19:46:11 Starting to launch local task to process map join ; maximum memory = 518979584
2019-11-07 19:46:16 Dump the side-table for tag: 0 with group count: 1 into file: file:/tmp/root/6093c46b-a3b4-45ef-9c21-e06c9f3cd0bd/hive_201 9-11-07_19-45-54_243_3045373106380911585-1/-local-10004/HashTable-Stage-4 /MapJoin-mapfile00--.hashtable
2019-11-07 19:46:16 Uploaded 1 File to: file:/tmp/root/6093c46b-a3b4- 45ef-9c21-e06c9f3cd0bd/hive_2019-11-07_19-45-54_243_3045373106380911585-1 /-local-10004/HashTable-Stage-4/MapJoin-mapfile00--.hashtable (402 bytes)
2019-11-07 19:46:16 Dump the side-table for tag: 1 with group count: 1 into file: file:/tmp/root/6093c46b-a3b4-45ef-9c21-e06c9f3cd0bd/hive_201 9-11-07_19-45-54_243_3045373106380911585-1/-local-10004/HashTable-Stage-4 /MapJoin-mapfile01--.hashtable
2019-11-07 19:46:16 Uploaded 1 File to: file:/tmp/root/6093c46b-a3b4- 45ef-9c21-e06c9f3cd0bd/hive_2019-11-07_19-45-54_243_3045373106380911585-1 /-local-10004/HashTable-Stage-4/MapJoin-mapfile01--.hashtable (319 bytes)
2019-11-07 19:46:16 End of local task; Time Taken: 4.185 sec.
Execution completed successfully
MapredLocal task succeeded
Launching Job 1 out of 1
Number of reduce tasks is set to 0 since there's no reduce operator
Starting Job = job_1573048606490_0012, Tracking URL = http://HadoopNode00 :8088/proxy/application_1573048606490_0012/
Kill Command = /home/hadoop/hadoop-2.6.0/bin/hadoop job -kill job_157304 8606490_0012
Hadoop job information for Stage-4: number of mappers: 1; number of reduc ers: 0
2019-11-07 19:47:10,052 Stage-4 map = 0%, reduce = 0%
2019-11-07 19:47:35,440 Stage-4 map = 100%, reduce = 0%, Cumulative CPU 2.62 sec
MapReduce Total cumulative CPU time: 2 seconds 620 msec
Ended Job = job_1573048606490_0012
MapReduce Jobs Launched:
Stage-Stage-4: Map: 1 Cumulative CPU: 2.94 sec HDFS Read: 8842 HDFS W rite: 136 SUCCESS
Total MapReduce CPU Time Spent: 2 seconds 940 msec
OK
BJ zhangsan GAME SH ermazi GAME HN wangwu G AME
BJ lisi GAME SH ermazi GAME HN wangwu GAME
BJ ergouzi GAME SH ermazi GAME HN wangwu GAME
Time taken: 134.488 seconds, Fetched: 3 row(s)
select
/*+STREAMTABLE(a)*/
a.address.city as name, a.name, a.hobbies[1] as hobby ,
b.address.city as name, b.name,b.hobbies[1] as hobby ,
c.address.city as name, c.name,c.hobbies[1] as hobby
from testuser a
join testuser b on a.hobbies[1] = b.hobbies[1]
join testuser c on a.hobbies[1] = c.hobbies[1]
where a.address.city = 'BJ' and b.address.city = 'SH' and c.address.city = 'HN';
/+STREAMTABLE(a)/ 使用此关键字,括号写表的 |别名|
6.5 排序
Order By
order by 在此处叫做全局排序
#全局排序
#类似于reduce和consumer的区别
#自己的笔记
hive> select * from testuser order by salary; #默认是升序的
Query ID = root_20191107195130_e8c56a04-dd3c-4270-ab28-70a7c52c6308
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks determined at compile time: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Starting Job = job_1573048606490_0013, Tracking URL = http://HadoopNode00 :8088/proxy/application_1573048606490_0013/
Kill Command = /home/hadoop/hadoop-2.6.0/bin/hadoop job -kill job_157304 8606490_0013
Hadoop job information for Stage-1: number of mappers: 1; number of reduc ers: 1
2019-11-07 19:51:52,438 Stage-1 map = 0%, reduce = 0%
2019-11-07 19:52:10,368 Stage-1 map = 67%, reduce = 0%
2019-11-07 19:52:12,309 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 2.8 sec
2019-11-07 19:52:27,542 Stage-1 map = 100%, reduce = 100%, Cumulative CP U 5.26 sec
MapReduce Total cumulative CPU time: 5 seconds 260 msec
Ended Job = job_1573048606490_0013
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 5.26 sec HDFS Read: 9778 HDFS Write: 344 SUCCESS
Total MapReduce CPU Time Spent: 5 seconds 260 msec
OK
4 ermazi false 49 20070.0 ["TV","GAME"] {"JIANSHE":"004", "ZHAOSHAN":"008"} {"country":"CHAINA","city":"SH"}
3 wangwu true 30 20100.0 ["TV","GAME"] {"JIANSHE":"003", "ZHAOSHAN":"007"} {"country":"CHAINA","city":"HN"}
2 lisi false 20 20100.0 ["TV","GAME"] {"JIANSHE":"002", "ZHAOSHAN":"006"} {"country":"CHAINA","city":"BJ"}
1 zhangsan true 10 20100.0 ["TV","GAME"] {"JIANSHE ":"001","ZHAOSHAN":"002"} {"country":"CHAINA","city":"BJ"}
5 ergouzi false 50 21000.0 ["TV","GAME"] {"JIANSHE":"005", "ZHAOSHAN":"009"} {"country":"CHAINA","city":"BJ"}
Time taken: 61.067 seconds, Fetched: 5 row(s)
select * from testuser order by salary;

#自己的笔记
hive> select * from testuser order by salary desc; #降序排列
Query ID = root_20191107195404_2c9128d9-beed-407a-bbaa-381a3bc5e9a7
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks determined at compile time: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Starting Job = job_1573048606490_0014, Tracking URL = http://HadoopNode00:8088/proxy/application_1573048606490_0014/
Kill Command = /home/hadoop/hadoop-2.6.0/bin/hadoop job -kill job_1573048606490_0014
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
2019-11-07 19:54:16,013 Stage-1 map = 0%, reduce = 0%
2019-11-07 19:54:45,791 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 2.36 sec
2019-11-07 19:55:21,424 Stage-1 map = 100%, reduce = 100%, Cumulative CP U 5.22 sec
MapReduce Total cumulative CPU time: 5 seconds 220 msec
Ended Job = job_1573048606490_0014
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 5.22 sec HDFS Read: 9778 HDFS Write: 344 SUCCESS
Total MapReduce CPU Time Spent: 5 seconds 220 msec
OK
5 ergouzi false 50 21000.0 ["TV","GAME"] {"JIANSHE":"005", "ZHAOSHAN":"009"} {"country":"CHAINA","city":"BJ"}
3 wangwu true 30 20100.0 ["TV","GAME"] {"JIANSHE":"003", "ZHAOSHAN":"007"} {"country":"CHAINA","city":"HN"}
2 lisi false 20 20100.0 ["TV","GAME"] {"JIANSHE":"002", "ZHAOSHAN":"006"} {"country":"CHAINA","city":"BJ"}
1 zhangsan true 10 20100.0 ["TV","GAME"] {"JIANSHE ":"001","ZHAOSHAN":"002"} {"country":"CHAINA","city":"BJ"}
4 ermazi false 49 20070.0 ["TV","GAME"] {"JIANSHE":"004", "ZHAOSHAN":"008"} {"country":"CHAINA","city":"SH"}
Time taken: 79.364 seconds, Fetched: 5 row(s)
select * from testuser order by salary desc;

Sort By
#自己的笔记、
hive> select * from testuser sort by salary; #排序
Query ID = root_20191107195704_85d79f3b-b07c-4874-b4ae-c8249ef3e4c4
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks not specified. Estimated from input data size: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Starting Job = job_1573048606490_0015, Tracking URL = http://HadoopNode00:8088/proxy/application_1573048606490_0015/
Kill Command = /home/hadoop/hadoop-2.6.0/bin/hadoop job -kill job_1573048606490_0015
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
2019-11-07 19:57:19,247 Stage-1 map = 0%, reduce = 0%
2019-11-07 19:57:29,282 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.58 sec
2019-11-07 19:57:43,818 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 3.53 sec
MapReduce Total cumulative CPU time: 3 seconds 530 msec
Ended Job = job_1573048606490_0015
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 3.53 sec HDFS Read: 9778 HDFS Write: 344 SUCCESS
Total MapReduce CPU Time Spent: 3 seconds 530 msec
OK
4 ermazi false 49 20070.0 ["TV","GAME"] {"JIANSHE":"004","ZHAOSHAN":"008"} {"country":"CHAINA","city":"SH"}
3 wangwu true 30 20100.0 ["TV","GAME"] {"JIANSHE":"003","ZHAOSHAN":"007"} {"country":"CHAINA","city":"HN"}
2 lisi false 20 20100.0 ["TV","GAME"] {"JIANSHE":"002","ZHAOSHAN":"006"} {"country":"CHAINA","city":"BJ"}
1 zhangsan true 10 20100.0 ["TV","GAME"] {"JIANSHE":"001","ZHAOSHAN":"002"} {"country":"CHAINA","city":"BJ"}
5 ergouzi false 50 21000.0 ["TV","GAME"] {"JIANSHE":"005","ZHAOSHAN":"009"} {"country":"CHAINA","city":"BJ"}
Time taken: 41.822 seconds, Fetched: 5 row(s)
select * from testuser sort by salary;
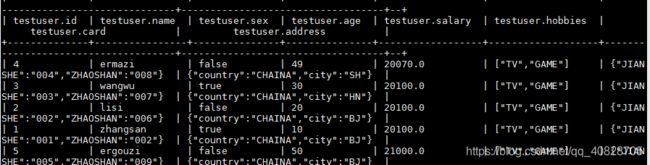
现在看来 sort by 和order by 没有任何区别
原因在于默认情况下 reduceTask的个数为为1
所以不管是全局还是局部都不会有任何区别
设置ReduceTask个数
#自己的笔记
hive> set mapreduce.job.reduces; #获取个数
mapreduce.job.reduces=-1 #默认为负一
#自己的笔记
hive> set mapreduce.job.reduces = 2; #设置 ReduceTask个数
#自己的个数
hive> set mapreduce.job.reduces;#查看设置的个数
mapreduce.job.reduces=2
#自己的笔记
hive> select * from testuser order by salary;#查询
Query ID = root_20191107200541_5d5d6994-01fe-40e3-8e7c-75f9d39d4f01
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks determined at compile time: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Starting Job = job_1573048606490_0016, Tracking URL = http://HadoopNode00:8088/proxy/application_1573048606490_0016/
Kill Command = /home/hadoop/hadoop-2.6.0/bin/hadoop job -kill job_1573048606490_0016
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
2019-11-07 20:05:55,494 Stage-1 map = 0%, reduce = 0%
2019-11-07 20:06:15,385 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 2.15 sec
2019-11-07 20:06:28,137 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 4.14 sec
MapReduce Total cumulative CPU time: 4 seconds 140 msec
Ended Job = job_1573048606490_0016
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 4.14 sec HDFS Read: 9778 HDFS Write: 344 SUCCESS
Total MapReduce CPU Time Spent: 4 seconds 140 msec
OK
4 ermazi false 49 20070.0 ["TV","GAME"] {"JIANSHE":"004","ZHAOSHAN":"008"} {"country":"CHAINA","city":"SH"}
3 wangwu true 30 20100.0 ["TV","GAME"] {"JIANSHE":"003","ZHAOSHAN":"007"} {"country":"CHAINA","city":"HN"}
2 lisi false 20 20100.0 ["TV","GAME"] {"JIANSHE":"002","ZHAOSHAN":"006"} {"country":"CHAINA","city":"BJ"}
1 zhangsan true 10 20100.0 ["TV","GAME"] {"JIANSHE":"001","ZHAOSHAN":"002"} {"country":"CHAINA","city":"BJ"}
5 ergouzi false 50 21000.0 ["TV","GAME"] {"JIANSHE":"005","ZHAOSHAN":"009"} {"country":"CHAINA","city":"BJ"}
Time taken: 48.688 seconds, Fetched: 5 row(s)
#自己的笔记
hive> select * from testuser sort by salary; #排序
Query ID = root_20191107200902_3315dcd6-6ebb-4e4b-ab0b-4daa667ee3e7
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks not specified. Defaulting to jobconf value of: 2
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Starting Job = job_1573048606490_0017, Tracking URL = http://HadoopNode00 :8088/proxy/application_1573048606490_0017/
Kill Command = /home/hadoop/hadoop-2.6.0/bin/hadoop job -kill job_157304 8606490_0017
Hadoop job information for Stage-1: number of mappers: 1; number of reduc ers: 2
2019-11-07 20:09:13,877 Stage-1 map = 0%, reduce = 0%
2019-11-07 20:09:27,365 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 2.25 sec
2019-11-07 20:09:49,353 Stage-1 map = 100%, reduce = 100%, Cumulative CP U 6.94 sec
MapReduce Total cumulative CPU time: 6 seconds 940 msec
Ended Job = job_1573048606490_0017
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Reduce: 2 Cumulative CPU: 7.09 sec HDFS Read: 14251 HDFS Write: 344 SUCCESS
Total MapReduce CPU Time Spent: 7 seconds 90 msec
OK
4 ermazi false 49 20070.0 ["TV","GAME"] {"JIANSHE":"004", "ZHAOSHAN":"008"} {"country":"CHAINA","city":"SH"}
3 wangwu true 30 20100.0 ["TV","GAME"] {"JIANSHE":"003", "ZHAOSHAN":"007"} {"country":"CHAINA","city":"HN"}
1 zhangsan true 10 20100.0 ["TV","GAME"] {"JIANSHE ":"001","ZHAOSHAN":"002"} {"country":"CHAINA","city":"BJ"}
5 ergouzi false 50 21000.0 ["TV","GAME"] {"JIANSHE":"005", "ZHAOSHAN":"009"} {"country":"CHAINA","city":"BJ"}#注意此处
2 lisi false 20 20100.0 ["TV","GAME"] {"JIANSHE":"002", "ZHAOSHAN":"006"} {"country":"CHAINA","city":"BJ"}#注意此处
Time taken: 49.747 seconds, Fetched: 5 row(s)
#自己的笔记
#设置block的大小
hive> set dfs.block.size; #设置dfs.block.size的大小
dfs.block.size=134217728
# 获取ReduceTask个数
set mapreduce.job.reduces;
# 设置 ReduceTask个数
set mapreduce.job.reduces = 2;
select * from testuser order by salary;
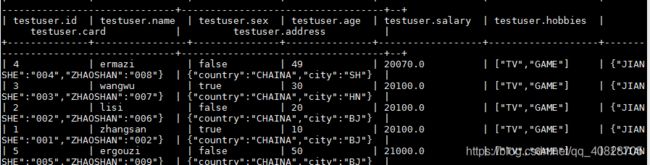
select * from testuser sory by salary;

将ReduceTask个数设置成2以后,此时就会启动两个RecueTask进行数据的处理,此时就能体现出来SortBy和Order By的区别
Orderby 的运行结果还是原来的,到那时SortBy的数据被分为两个区 ,此时数据就按照局部进行排序
六、Hive 自定义函数
在Hive当中又系统自带的函数,可以通过
show functions;语句查询系统现在已经存在函数。desc function upper;显示自带函数用法,desc function extended upper;详细显示自带函数用法。其系统中已经存在很多函数,但是这些往往不能满足生产需求,所以Hive保留了相关接口,以便用户日后去自定义函数去拓展相关的功能。#自定义函数 hive> show functions; #展示Hive的内置函数 OK ! != % & * + - / < <= <=> <> = == > >= ^ abs acos add_months and array array_contains ascii asin assert_true atan avg base64 between bin case cbrt ceil ceiling coalesce collect_list collect_set compute_stats concat concat_ws context_ngrams conv corr cos count covar_pop covar_samp create_union cume_dist current_database current_date current_timestamp current_user date_add date_format date_sub datediff day dayofmonth decode degrees dense_rank div e elt encode ewah_bitmap ewah_bitmap_and ewah_bitmap_empty ewah_bitmap_or exp explode factorial field find_in_set first_value floor format_number from_unixtime from_utc_timestamp get_json_object greatest hash hex histogram_numeric hour if in in_file index initcap inline instr isnotnull isnull java_method json_tuple lag last_day last_value lcase lead least length levenshtein like ln locate log log10 log2 lower lpad ltrim map map_keys map_values matchpath max min minute month months_between named_struct negative next_day ngrams noop noopstreaming noopwithmap noopwithmapstreaming not ntile nvl or parse_url parse_url_tuple percent_rank percentile percentile_approx pi pmod posexplode positive pow power printf radians rand rank reflect reflect2 regexp regexp_extract regexp_replace repeat reverse rlike round row_number rpad rtrim second sentences shiftleft shiftright shiftrightunsigned sign sin size sort_array soundex space split sqrt stack std stddev stddev_pop stddev_samp str_to_map struct substr substring sum tan to_date to_unix_timestamp to_utc_timestamp translate trim trunc ucase unbase64 unhex unix_timestamp upper var_pop var_samp variance weekofyear when windowingtablefunction xpath xpath_boolean xpath_double xpath_float xpath_int xpath_long xpath_number xpath_short xpath_string year | ~ Time taken: 3.42 seconds, Fetched: 216 row(s) #自己的笔记 hive> desc function upper; #查看具体的函数怎么用 OK upper(str) - Returns str with all characters changed to uppercase Time taken: 1.953 seconds, Fetched: 1 row(s) #自己的笔记 hive> desc function max; # OK max(expr) - Returns the maximum value of expr Time taken: 0.05 seconds, Fetched: 1 row(s) hive> #自己的笔记 hive> desc function year;# OK year(param) - Returns the year component of the date/timestamp/interval Time taken: 0.537 seconds, Fetched: 1 row(s) # #UDF编程接口 #自己的笔记 hive> desc function extended upper; #详细的描述函数 --- 对应Description OK upper(str) - Returns str with all characters changed to uppercase Synonyms: ucase Example: > SELECT upper('Facebook') FROM src LIMIT 1; 'FACEBOOK' Time taken: 0.121 seconds, Fetched: 5 row(s) #自己的笔记 #类似于以下的东西 @Description( name = "hello", value = "_FUNC_(str1,str2) - from the input string" + "returns the value that is \"你好 $str1 ,$str2 好玩吗? \" ", extended = "Example:\n" + " > SELECT _FUNC_(str1,str2) FROM src;" )
在Hive中,用户可以自定义一些函数,用于扩展HiveQL的功能,而这类函数叫做UDF(用户自定义函数)。UDF分为两大类:UDAF(用户自定义聚合函数)和UDTF(用户自定义表生成函数)。在介绍UDAF和UDTF实现之前,我们先在本章介绍简单点的UDF实现:UDF和GenericUDF,然后以此为基础介绍UDAF和UDTF的实现。
7.1 UDF
Hive有两个不同的接口编写UDF程序。一个是基础的UDF接口,一个是复杂的GenericUDF接口。
org.apache.hadoop.hive.ql. exec.UDF 基础UDF的函数读取和返回基本类型,即Hadoop和Hive的基本类型。如Text、IntWritable、LongWritable、DoubleWritable等。
org.apache.hadoop.hive.ql.udf.generic.GenericUDF 复杂的GenericUDF可以处理Map、List、Set类型。
@Describtion注解是可选的,用于对函数进行说明,其中的_FUNC_字符串表示函数名,当使用DESCRIBE FUNCTION命令时,替换成函数名。@Describtion包含三个属性:
name:用于指定Hive中的函数名。
value:用于描述函数的参数。
extended:额外的说明,例如当使用DESCRIBE FUNCTION EXTENDED name的时候打印。
7.1.1 准备数据
表结构
drop table logs;
create table
logs
(
userid string ,
fromUrl string ,
dateString string,
timeString string,
ipAddress string,
browserName string,
pcSystemNameOrmobileBrandName string ,
systemVersion string,
language string,
cityName string
)
partitioned BY (day string)
row format delimited fields terminated
by ' ';
导入数据
load data inpath '/clean.log' into table logs partition(day='19-06-19');
部分数据展示
a1b21e96-01d8-47ca-b343-2fb7a7172701 http://192.168.123.129:1211/Test/index.jsp 2019-06-19 23:19:26 223.71.30.3 Chrome MI-8) Android-9 zh-CN CHINA 19-06-19
7.1.2 编写Java类
这里是真正的写自定义函数的逻辑,首先需要设计一下自定义函数的逻辑。
想要实现的效果(当然这个可以自行定义):比如说查询userid(名字) 和城市,
输出 你好 userid ,pcSystemNameOrmobileBrandName 好玩吗?
环境
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-commonartifactId>
<version>2.6.0version>
dependency>
<dependency>
<groupId>org.apache.hivegroupId>
<artifactId>hive-execartifactId>
<version>1.2.2version>
dependency>
<dependency>
<groupId>junitgroupId>
<artifactId>junitartifactId>
<version>4.12version>
dependency>
出现的问题

看上图,阿里云代理的中心仓库无法下载这个依赖,这也就意味着最经常使用的几大Maven仓库也无法下载,所有在几经周折后,找到了发布这个依赖的私服(私服中也有其他依赖,可以直接使用)
解决办法
pentaho私服WEB地址 :https://public.nexus.pentaho.org/
#下载相关的依赖地址如上。
办法1
通过所有就可以下载到当前这个缺失依赖

缺点:麻烦
优点:无需再去校验或者下载其他的Jar包
#自己的笔记
#MAVEN 私服 ---- 多用于公司内部
#自己的笔记
#D:\资料(全部拷贝)\大数据_课堂\大数据训练营课程\Note\Day12-Hive\相关Jar包下:cmd
#自己的笔记
D:\资料(全部拷贝)\大数据_课堂\大数据训练营课程\Note\Day12-Hive\相关Jar包>D:\apache-maven-3.6.1\bin\mvn install:install-file -DgroupId=org.pentaho -DartifactId=pentaho-aggdesigner-algorithm -Dversion=5.1.5-jhyde -Dpackaging=jar -Dfile=pentaho-aggdesigner-algorithm-5.1.5-jhyde-javadoc.jar #使用绝对路径 ---- 如果没有配置maven的环境变量
#自己的笔记
#安装之后的信息
[INFO] Scanning for projects...
[INFO]
[INFO] ------------------< org.apache.maven:standalone-pom >-------------------
[INFO] Building Maven Stub Project (No POM) 1
[INFO] --------------------------------[ pom ]---------------------------------
[INFO]
[INFO] --- maven-install-plugin:2.4:install-file (default-cli) @ standalone-pom ---
[INFO] Installing D:\资料(全部拷贝)\大数据_课堂\大数据训练营课程\Note\Day12-Hive\相关Jar包\pentaho-aggdesigner-algorithm-5.1.5-jhyde-javadoc.jar to D:\.m2\org\pentaho\pentaho-aggdesigner-algorithm\5.1.5-jhyde\pentaho-aggdesigner-algorithm-5.1.5-jhyde.jar
[INFO] Installing C:\Users\lenovo\AppData\Local\Temp\mvninstall3796712711994324496.pom to D:\.m2\org\pentaho\pentaho-aggdesigner-algorithm\5.1.5-jhyde\pentaho-aggdesigner-algorithm-5.1.5-jhyde.pom
[INFO] ------------------------------------------------------------------------
[INFO] BUILD SUCCESS #安装成功
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 2.202 s
[INFO] Finished at: 2019-11-10T10:07:30+08:00
[INFO] ------------------------------------------------------------------------
#自己的笔记
#查看此路径下是否由此jar包 ---- pentaho-aggdesigner-algorithm-5.1.5-jhyde.jar
#D:\.m2\org\pentaho\pentaho-aggdesigner-algorithm\5.1.5-jhyde
mvn install:install-file -DgroupId=org.pentaho -DartifactId=pentaho-aggdesigner-algorithm -Dversion=5.1.5-jhyde -Dpackaging=jar -Dfile=pentaho-aggdesigner-algorithm-5.1.5-jhyde-javadoc.jar
mvn 需要配置环境变量
-Dfile 需要指定正确的路径
办法2
将阿里云的镜像替代为pentaho镜像,打开xml文件
但是地址怎么写?

https://public.nexus.pentaho.org/repository/proxied-pentaho-public-repos-group/org/pentaho/pentaho-aggdesigner-algorithm/5.1.5-jhyde/pentaho-aggdesigner-algorithm-5.1.5-jhyde-javadoc.jar

上述连接中是下载缺失依赖的jar,可以看到从org之前都是其公共仓库的连接了,所在在你的xml文件中去除阿里云的依赖,添加下方镜像即可
<mirror>
<id>nexus-pentahoid>
<mirrorOf>*mirrorOf>
<name>Nexus pentahoname>
<url>https://public.nexus.pentaho.org/repository/proxied-pentaho-public-repos-group/url>
mirror>
但是,此种方法需要重新将你的其他依赖再进行一次校验或者下载 ,也有其局限性
#自己的笔记 #缺点: #(1)时间相当的长
真正的代码
package io.gjf.udf;
import org.apache.hadoop.hive.ql.exec.Description;
import org.apache.hadoop.hive.ql.exec.UDF;
/**
* Create by GuoJF on 2019/6/19
*/
@Description(
name = "hello",
value = "_FUNC_(str1,str2) - from the input string"
+ "returns the value that is \"你好 $str1 ,$str2 好玩吗? \" ",
extended = "Example:\n"
+ " > SELECT _FUNC_(str1,str2) FROM src;"
)
public class HelloUDF extends UDF {
public String evaluate(String str1,String str2){
try {
return "Hello " + str1+", "+str2 +" 好玩吗?";
} catch (Exception e) {
// TODO: handle exception
e.printStackTrace();
return "ERROR";
}
}
}
7.1.3添加功能
本地生成Jar包,并且上传至Linux服务器,进入Hive命令行
#自己的笔记
#本地生成Jar包
#拖至root目录下面
#自己的笔记
hive> add jar /root/Hive_Test-1.0-SNAPSHOT.jar; #添加jar包
Added [/root/Hive_Test-1.0-SNAPSHOT.jar] to class path
Added resources: [/root/Hive_Test-1.0-SNAPSHOT.jar]
#自己的笔记
hive> CREATE TEMPORARY FUNCTION hello AS "com.baizhi.udf.HelloUDF";
OK
Time taken: 0.851 seconds
#自己的笔记
hive> select hello(userid,pcSystemNameOrmobileBrandName) from logs; #查询
OK
Hello 707a2a9c-c89f-4041-a276-df12611a9363, Windows 好玩吗?
Hello 707a2a9c-c89f-4041-a276-df12611a9363, Windows 好玩吗?
Hello 707a2a9c-c89f-4041-a276-df12611a9363, Windows 好玩吗?
Hello 707a2a9c-c89f-4041-a276-df12611a9363, Windows 好玩吗?
。。。。。(很多行)。
Time taken: 7.313 seconds, Fetched: 289 row(s)
#自己的笔记
#总结
#UDF入门即可
hive> add jar /root/Hive_Test-1.0-SNAPSHOT.jar;
hive> CREATE TEMPORARY FUNCTION hello AS "com.baizhi.udf.HelloUDF";
7.1.4展示效果
select hello(userid,pcSystemNameOrmobileBrandName) from logs;
部分效果如下:
Hello f8b13cf1-f601-4891-ab3b-ca06069a9f41, CHINA 好玩吗?
Hello f8b13cf1-f601-4891-ab3b-ca06069a9f41, CHINA 好玩吗?
7.2 GenericUDF(了解)
org.apache.hadoop.hive.ql.udf.generic.GenericUDF 复杂的GenericUDF可以处理Map、List、Set类型。
Serde是什么:Serde实现数据序列化和反序列化以及提供一个辅助类ObjectInspector帮助使用者访问需要序列化或者反序列化的对象。
7.3 UDTF(了解)
用户自定义表生成函数(UDTF)。用户自定义表生成函数(UDTF)接受零个或多个输入,然后产生多列或多行的输出,如explode()。要实现UDTF,需要继org.apache.hadoop.hive.ql.udf.generic.GenericUDTF,同时实现三个方法:
//该方法指定输入输出参数:输入的Object Inspectors和输出的Struct。
1. abstract StructObjectInspector initialize(ObjectInspector[] args) throws UDFArgumentException;
//该方法处理输入记录,然后通过forward()方法返回输出结果。
2. abstract void process(Object[] record) throws HiveException;
//该方法用于通知UDTF没有行可以处理,可以在该方法中清理代码或者附加其他处理输出。
3. abstract void close() throws HiveException;
7.4 UDAF (了解)
用户自定义聚合函数(UDAF)接收从零行到多行的零个到多个列,然后返回单一值,如sum()、count()。要实现UDAF,我们需要实现下面的类:
org.apache.0.hive.ql.udf.generic.AbstractGenericUDAFResolver
org.apache.hadoop.hive.ql.udf.generic.GenericUDAFEvaluator
AbstractGenericUDAFResolver检查输入参数,并且指定使用哪个resolver。在AbstractGenericUDAFResolver里,只需要实现一个方法:
Public GenericUDAFEvaluator getEvaluator(TypeInfo[] parameters) throws SemanticException;
但是,主要的逻辑处理还是在evaluator中。我们需要继承GenericUDAFEvaluator,并且实现下面几个方法:
//输入输出都是Object inspectors
public ObjectInspector init(Mode m, ObjectInspector[] parameters) throws HiveException;
//AggregationBuffer保存数据处理的临时结果
abstract AggregationBuffer getNewAggregationBuffer() throws HiveException;
//重新设置AggregationBuffer
public void reset(AggregationBuffer agg) throws HiveException;
//处理输入记录
public void iterate(AggregationBuffer agg, Object[] parameters) throws HiveException;
//处理全部输出数据中的部分数据
public Object terminatePartial(AggregationBuffer agg) throws HiveException;
//把两个部分数据聚合起来
public void merge(AggregationBuffer agg, Object partial) throws HiveException;
//输出最终结果
public Object terminate(AggregationBuffer agg) throws HiveException;
在给出示例之前,先看下UADF的Enum GenericUDAFEvaluator.Mode。Mode有4中情况:
1. PARTIAL1:Mapper阶段。从原始数据到部分聚合,会调用iterate()和terminatePartial()。
2. PARTIAL2:Combiner阶段,在Mapper端合并Mapper的结果数据。从部分聚合到部分聚合,会调用merge()和terminatePartial()。
3. FINAL:Reducer阶段。从部分聚合数据到完全聚合,会调用merge()和terminate()。
4. COMPLETE:出现这个阶段,表示MapReduce中只用Mapper没有Reducer,所以Mapper端直接输出结果了。从原始数据到完全聚合,会调用iterate()和terminate()。
7.5 Hive函数综合案例
7.5.1 实现列自增长
Java代码
package io.gjf.udf;
/**
* Create by GuoJF on 2019/6/20
*/
import org.apache.hadoop.hive.ql.exec.Description;
import org.apache.hadoop.hive.ql.exec.UDF;
import org.apache.hadoop.hive.ql.udf.UDFType;
import org.apache.hadoop.io.LongWritable;
/**
* UDFRowSequence.
*/
@Description(name = "row_sequence",
value = "_FUNC_() - Returns a generated row sequence number starting from 1")
@UDFType(deterministic = false)
public class RowSequence extends UDF {
private LongWritable result = new LongWritable();
public RowSequence() {
result.set(0);
}
public LongWritable evaluate() {
result.set(result.get() + 1);
return result;
}
}
导入函数
打Jar包上传至Linux服务器,并在Hive命令行中输出如下指令
hive> add jar /root/Hive-1.0-SNAPSHOT.jar
hive> create temporary function row_sequence as 'com.baizhi.udf.RowSequence';
查询数据
#自己的笔记
hive> create temporary function row_sequence as 'com.baizhi.udf.RowSequen
OK
Time taken: 0.008 seconds
#自己的笔记
hive> SELECT row_sequence(), userid FROM logs;
OK
1 707a2a9c-c89f-4041-a276-df12611a9363
。。。。(289行数据)
288 707a2a9c-c89f-4041-a276-df12611a9363
289 707a2a9c-c89f-4041-a276-df12611a9363
Time taken: 4.338 seconds, Fetched: 289 row(s)
SELECT row_sequence(), userid FROM logs;
效果展示

7.5.2 数据合并
需求描述
假设我们在Hive中有两张表,其中一张表是存用户基本信息,另一张表是存用户的地址信息等
user_basic_info 表信息
| id | name |
|---|---|
| 1 | a |
| 2 | b |
| 3 | c |
| 4 | d |
user_address_info 表信息
| name | address |
|---|---|
| a | add1 |
| a | add2 |
| b | add3 |
| c | add4 |
| d | add5 |
我们希望得到这样的结果:
| id | name | address |
|---|---|---|
| 1 | a | add1,add2 |
| 2 | b | add3 |
| 3 | c | add4 |
| 4 | d | add5 |
建表
创建user_basic_info
user_basic_info
create table user_basic_info(id string,name string)
row format delimited fields terminated
by ' ';
1 a
2 b
3 c
4 d
load data local inpath '/root/user_basic_info' overwrite into table user_basic_info;
创建user_address_info
user_address_info
create table user_address_info(name string,address string)
row format delimited fields terminated
by ' ';
a add1
a add2
b add3
c add4
d add5
load data local inpath '/root/user_address_info' overwrite into table user_address_info;
#自己的笔记
#concat(String s1,String s2,String s3)
#解释:能够把字符串类型的数据连接起来,连接的某个元素可以是列值。
#自己的笔记
#cast(value as type)
#解释:将某个列的值显示的转化为某个类型。
#eg:cast(age as strting) 将int类型的数据转化为String类型的数据。
#自己的笔记
#concat_ws(seperator,string s1,string s2...)
#解释:制定分隔符将多个字符串连接起来,实现"列转行".
#自己的笔记
#collect_set
#解释:去除重复元素
#自己的笔记
#先建表
hive> create table user_basic_info(id string,name string)
> row format delimited fields terminated
> by ' '; #建表
OK
Time taken: 3.698 seconds
#自己的笔记
hive> show tables; #展示表
OK
logs
t2
t_access
t_csv
t_json
t_user
t_user_a
t_user_p
temp1
testuser
user_basic_info #注意
Time taken: 0.162 seconds, Fetched: 11 row(s)
#自己的笔记
[root@HadoopNode00 ~]# vi user_basic_info
[root@HadoopNode00 ~]# more user_basic_info
1 a
2 b
3 c
4 d
#自己的笔记
hive> load data local inpath '/root/user_basic_info' overwrite into table user_basic_info;#从外部导入(HDFS)
Loading data to table baizhi.user_basic_info
Table baizhi.user_basic_info stats: [numFiles=1, numRows=0, totalSize=16, rawDataSize=0]
OK
Time taken: 2.598 seconds
#自己的笔记
#准备数据
#建表
hive> create table user_address_info(name string,address string) #建表
> row format delimited fields terminated
> by ' ';
OK
Time taken: 0.256 seconds
#自己的笔记
hive> show tables; #展示表
OK
logs
t2
t_access
t_csv
t_json
t_user
t_user_a
t_user_p
temp1
testuser
user_address_info
user_basic_info
Time taken: 0.127 seconds, Fetched: 12 row(s)
#自己的笔记
[root@HadoopNode00 ~]# vi user_address_info
[root@HadoopNode00 ~]# more user_address_info
a add1
a add2
b add3
c add4
d add5
#自己的笔记
hive> load data local inpath '/root/user_address_info' overwrite into table user_address_info; #外部倒入(从HDFS上导入)
Loading data to table baizhi.user_address_info
Table baizhi.user_address_info stats: [numFiles=1, numRows=0, totalSize=35, rawDataSize=0]
OK
Time taken: 0.54 seconds
#自己的笔记
hive> select * from user_address_info; #查表
OK
a add1
a add2
b add3
c add4
d add5
Time taken: 0.102 seconds, Fetched: 5 row(s)
#自己的笔记
hive> select max(a.id), a.name, concat_ws('|', collect_set(b.address)) as address from user_basic_info a join user_address_info b on a.name=b.name group by a.name; #查表
Query ID = root_20191107213509_7a349df4-e5b8-4e2e-a02e-1b1c27663c9c
Total jobs = 1
Java HotSpot(TM) 64-Bit Server VM warning: You have loaded library /home/hadoop/hadoop-2.6.0/lib/native/libhadoop.so.1.0.0 which might have disabled stack guard. The VM will try to fix the stack guard now.
It's highly recommended that you fix the library with 'execstack -c <libfile>', or link it with '-z noexecstack'.
19/11/07 21:35:38 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Execution log at: /tmp/root/root_20191107213509_7a349df4-e5b8-4e2e-a02e-1b1c27663c9c.log
2019-11-07 21:35:41 Starting to launch local task to process map join; maximum memory = 518979584
2019-11-07 21:35:46 Dump the side-table for tag: 0 with group count: 4 into file: file:/tmp/root/6093c46b-a3b4-45ef-9c21-e06c9f3cd0bd/hive_2019-11-07_21-35-09_786_2708769696811345747-1/-local-10004/HashTable-Stage-2/MapJoin-mapfile10--.hashtable
2019-11-07 21:35:46 Uploaded 1 File to: file:/tmp/root/6093c46b-a3b4-45ef-9c21-e06c9f3cd0bd/hive_2019-11-07_21-35-09_786_2708769696811345747-1/-local-10004/HashTable-Stage-2/MapJoin-mapfile10--.hashtable (348 bytes)
2019-11-07 21:35:46 End of local task; Time Taken: 4.477 sec.
Execution completed successfully
MapredLocal task succeeded
Launching Job 1 out of 1
Number of reduce tasks not specified. Defaulting to jobconf value of: 2
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=
In order to set a constant number of reducers:
set mapreduce.job.reduces=
Starting Job = job_1573048606490_0018, Tracking URL = http://HadoopNode00:8088/proxy/application_1573048606490_0018/
Kill Command = /home/hadoop/hadoop-2.6.0/bin/hadoop job -kill job_1573048606490_0018
Hadoop job information for Stage-2: number of mappers: 1; number of reducers: 2
2019-11-07 21:36:22,296 Stage-2 map = 0%, reduce = 0%
2019-11-07 21:36:44,638 Stage-2 map = 100%, reduce = 0%, Cumulative CPU 3.57 sec
2019-11-07 21:37:12,844 Stage-2 map = 100%, reduce = 67%, Cumulative CPU 8.23 sec
2019-11-07 21:37:15,179 Stage-2 map = 100%, reduce = 100%, Cumulative CPU 9.83 sec
MapReduce Total cumulative CPU time: 9 seconds 830 msec
Ended Job = job_1573048606490_0018
MapReduce Jobs Launched:
Stage-Stage-2: Map: 1 Reduce: 2 Cumulative CPU: 9.83 sec HDFS Read: 19510 HDFS Write: 41 SUCCESS
Total MapReduce CPU Time Spent: 9 seconds 830 msec
OK
2 b add3
4 d add5
1 a add1|add2
3 c add4
Time taken: 136.744 seconds, Fetched: 4 row(s)
#自己的笔记
hive> select min(a.id), a.name from user_basic_info a join user_address_info b on a.name=b.name group by a.name;
Query ID = root_20191107214804_dac0f778-9026-457f-88b2-c946868ccd70
Total jobs = 1
Java HotSpot(TM) 64-Bit Server VM warning: You have loaded library /home/hadoop/hadoop-2.6.0/lib/native/libhadoop.so.1.0.0 which might have disabled stack guard. The VM will try to fix the stack guard now.
It' s highly recommended that you fix the library with 'execstack -c ' , or link it with '-z noexecstack'.
19/11/07 21:48:10 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Execution log at: /tmp/root/root_20191107214804_dac0f778-9026-457f-88b2-c946868ccd70.log
2019-11-07 21:48:11 Starting to launch local task to process map join; maximum memory = 518979584
2019-11-07 21:48:13 Dump the side-table for tag: 0 with group count: 4 into file: file:/tmp/root/6093c46b-a3b4-45ef-9c21-e06c9f3cd0bd/hive_2019-11-07_21-48-04_138_2231366155720845111-1/-local-10004/HashTable-Stage-2/MapJoin-mapfile20--.hashtable
2019-11-07 21:48:13 Uploaded 1 File to: file:/tmp/root/6093c46b-a3b4-45ef-9c21-e06c9f3cd0bd/hive_2019-11-07_21-48-04_138_2231366155720845111-1/-local-10004/HashTable-Stage-2/MapJoin-mapfile20--.hashtable (348 bytes)
2019-11-07 21:48:13 End of local task; Time Taken: 2.029 sec.
Execution completed successfully
MapredLocal task succeeded
Launching Job 1 out of 1
Number of reduce tasks not specified. Defaulting to jobconf value of: 2
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Starting Job = job_1573048606490_0019, Tracking URL = http://HadoopNode00:8088/proxy/application_1573048606490_0019/
Kill Command = /home/hadoop/hadoop-2.6.0/bin/hadoop job -kill job_1573048606490_0019
Hadoop job information for Stage-2: number of mappers: 1; number of reducers: 2
2019-11-07 21:48:54,352 Stage-2 map = 0%, reduce = 0%
2019-11-07 21:49:07,106 Stage-2 map = 100%, reduce = 0%, Cumulative CPU 2.84 sec
2019-11-07 21:49:27,522 Stage-2 map = 100%, reduce = 100%, Cumulative CPU 7.29 sec
MapReduce Total cumulative CPU time: 7 seconds 290 msec
Ended Job = job_1573048606490_0019
MapReduce Jobs Launched:
Stage-Stage-2: Map: 1 Reduce: 2 Cumulative CPU: 7.29 sec HDFS Read: 17495 HDFS Write: 16 SUCCESS
Total MapReduce CPU Time Spent: 7 seconds 290 msec
OK
2 b
4 d
1 a
3 c
Time taken: 85.769 seconds, Fetched: 4 row(s)
select a.id, a.name from user_basic_info a join user_address_info b on a.name=b.name group by a.name;
select max(a.id), a.name, concat_ws('|', collect_set(b.address)) as address from user_basic_info a join user_address_info b on a.name=b.name group by a.name;
max的作用取当前组中其中的一个值 当然min等这样的函数也行
结果

数据合并
#自己的笔记
hive> create table user_all_info(id string,name string,address string)
> row format delimited fields terminated
> by ' '; #创建表
OK
Time taken: 1.395 seconds
#自己的笔记
hive> show tables; #展示表
OK
logs
t2
t_access
t_csv
t_json
t_user
t_user_a
t_user_p
temp1
testuser
user_address_info
user_all_info
user_basic_info
Time taken: 0.171 seconds, Fetched: 13 row(s)
#自己的笔记
hive> insert into table user_all_info select max(a.id), a.name, concat_ws('|', collect_set(b.address)) as address from user_basic_info a join user_address_info b
> on a.name=b.name group by a.name; #数据合并
Query ID = root_20191107215516_7dffea39-6e34-4e2b-87cb-c1a87c88866d
Total jobs = 1
Java HotSpot(TM) 64-Bit Server VM warning: You have loaded library /home/hadoop/hadoop-2.6.0/lib/native/libhadoop.so.1.0.0 which might have disabled stack guard. The VM will try to fix the stack guard now.
It's highly recommended that you fix the library with 'execstack -c <libfile>', or link it with '-z noexecstack'.
19/11/07 21:55:21 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Execution log at: /tmp/root/root_20191107215516_7dffea39-6e34-4e2b-87cb-c1a87c88866d.log
2019-11-07 21:55:23 Starting to launch local task to process map join; maximum memory = 518979584
2019-11-07 21:55:24 Dump the side-table for tag: 0 with group count: 4 into file: file:/tmp/root/6093c46b-a3b4-45ef-9c21-e06c9f3cd0bd/hive_2019-11-07_21-55-16_865_1655290510522151497-1/-local-10003/HashTable-Stage-2/MapJoin-mapfile30--.hashtable
2019-11-07 21:55:25 Uploaded 1 File to: file:/tmp/root/6093c46b-a3b4-45ef-9c21-e06c9f3cd0bd/hive_2019-11-07_21-55-16_865_1655290510522151497-1/-local-10003/HashTable-Stage-2/MapJoin-mapfile30--.hashtable (348 bytes)
2019-11-07 21:55:25 End of local task; Time Taken: 1.983 sec.
Execution completed successfully
MapredLocal task succeeded
Launching Job 1 out of 1
Number of reduce tasks not specified. Defaulting to jobconf value of: 2
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=
In order to set a constant number of reducers:
set mapreduce.job.reduces=
Starting Job = job_1573048606490_0020, Tracking URL = http://HadoopNode00:8088/proxy/application_1573048606490_0020/
Kill Command = /home/hadoop/hadoop-2.6.0/bin/hadoop job -kill job_1573048606490_0020
Hadoop job information for Stage-2: number of mappers: 1; number of reducers: 2
2019-11-07 21:55:41,474 Stage-2 map = 0%, reduce = 0%
2019-11-07 21:55:57,632 Stage-2 map = 100%, reduce = 0%, Cumulative CPU 2.71 sec
2019-11-07 21:56:26,573 Stage-2 map = 100%, reduce = 67%, Cumulative CPU 7.45 sec
2019-11-07 21:56:30,138 Stage-2 map = 100%, reduce = 83%, Cumulative CPU 8.23 sec
2019-11-07 21:56:31,268 Stage-2 map = 100%, reduce = 100%, Cumulative CPU 9.07 sec
MapReduce Total cumulative CPU time: 9 seconds 70 msec
Ended Job = job_1573048606490_0020
Loading data to table baizhi.user_all_info
Table baizhi.user_all_info stats: [numFiles=2, numRows=4, totalSize=41, rawDataSize=37]
MapReduce Jobs Launched:
Stage-Stage-2: Map: 1 Reduce: 2 Cumulative CPU: 9.07 sec HDFS Read: 20449 HDFS Write: 193 SUCCESS
Total MapReduce CPU Time Spent: 9 seconds 70 msec
OK
Time taken: 88.871 seconds
#自己的笔记
hive> select * from user_all_info; #查表
OK
2 b add3
4 d add5
1 a add1|add2
3 c add4
Time taken: 0.523 seconds, Fetched: 4 row(s)
创建新表 user_all_info
create table user_all_info(id string,name string,address string)
row format delimited fields terminated
by ' ';
执行插入语句
insert into table user_all_info select max(a.id), a.name, concat_ws('|', collect_set(b.address)) as address from user_basic_info a join user_address_info b
on a.name=b.name group by a.name;
最终结果

八、Hive On Hbase
#(1)启动zk
#(2)启动dfs
#(3)启动yarn
#(4)启动hbase
#(5)启动hiveserver2 ---- 启动Hive (要启动mysql)
@Test
public void testPut04() throws Exception {
TableName tname = TableName.valueOf("baizhi:t_user");
BufferedMutator mb = conn.getBufferedMutator(tname);
String[] company = {"baidu", "ali", "sina"};
List<Put> list = new ArrayList<>();
for (int i = 1; i < 1000; i++) {
String rowkeyP = company[new Random().nextInt(3)];
String empid = "";
if (i < 10) {
empid = "00" + i;
} else if (i < 100) {
empid = "0" + i;
} else {
empid = "" + i;
}
String rowkey = rowkeyP + ":" + empid;
Put put = new Put(rowkey.getBytes());
put.addColumn("cf1".getBytes(), "name".getBytes(), "lisi1".getBytes());
put.addColumn("cf1".getBytes(), "age".getBytes(), Bytes.toBytes(i + ""));
put.addColumn("cf1".getBytes(), "salary".getBytes(), Bytes.toBytes(100.0 * i + ""));
put.addColumn("cf1".getBytes(), "company".getBytes(), rowkeyP.getBytes());
list.add(put);
}
mb.mutate(list);
mb.close();
}
#自己的笔记
#自己创建表的时候已经将数据映射到HBase上了
#创建表的地方是精华
#在HBAse中去准备数据 ---- 在Hive中去查找(方便)
#自己的笔记
hive> CREATE EXTERNAL table t_user_hbase(
> id string,
> name string,
> age int,
> salary double,
> company string
> )
> STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
> WITH SERDEPROPERTIES('hbase.columns.mapping' = ':key,cf1:name,cf1: age,cf1:salary,cf1:company')
> TBLPROPERTIES('hbase.table.name' = 'baizhi:t_user33');
OK
Time taken: 207.945 seconds
#自己的笔记
hive> show tables; #展示表
OK
logs
t2
t_access
t_csv
t_json
t_user
t_user_a
t_user_hbase #注意此处
t_user_p
temp1
testuser
user_address_info
user_all_info
user_basic_info
Time taken: 2.961 seconds, Fetched: 14 row(s)
#自己的笔记
#只需要自己书写SQL语句
#自己的笔记
hive> select avg(salary),max(salary),min(salary),sum(salary) ,company from t_user_hbase group by company; #查询
Query ID = root_20191107223953_8c83da96-a467-4949-87b1-a5ff81b18f1b
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks not specified. Defaulting to jobconf value of: 2
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Starting Job = job_1573048606490_0021, Tracking URL = http://HadoopNode00 :8088/proxy/application_1573048606490_0021/
Kill Command = /home/hadoop/hadoop-2.6.0/bin/hadoop job -kill job_157304 8606490_0021
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 2
2019-11-07 22:44:57,782 Stage-1 map = 0%, reduce = 0%
2019-11-07 22:46:44,861 Stage-1 map = 0%, reduce = 0%
2019-11-07 22:47:58,269 Stage-1 map = 0%, reduce = 0%
2019-11-07 22:48:18,771 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 5.54 sec
2019-11-07 22:49:22,431 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 5.71 sec
2019-11-07 22:50:44,745 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 5.71 sec
2019-11-07 22:51:47,958 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 5.71 sec
2019-11-07 22:52:50,521 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 5.71 sec
2019-11-07 22:54:26,050 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 5.71 sec
2019-11-07 22:55:17,557 Stage-1 map = 100%, reduce = 33%, Cumulative CPU 14.59 sec
2019-11-07 22:55:19,624 Stage-1 map = 100%, reduce = 67%, Cumulative CPU 15.14 sec
2019-11-07 22:55:27,543 Stage-1 map = 100%, reduce = 83%, Cumulative CPU 17.53 sec
2019-11-07 22:55:28,709 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 19.29 sec
MapReduce Total cumulative CPU time: 19 seconds 290 msec
Ended Job = job_1573048606490_0021
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Reduce: 2 Cumulative CPU: 19.29 sec HDFS Read: 22236 HDFS Write: 140 SUCCESS
Total MapReduce CPU Time Spent: 19 seconds 290 msec
OK
50809.72222222222 99900.0 200.0 1.82915E7 ali
50773.1778425656 99700.0 100.0 1.74152E7 baidu
48119.25675675676 99500.0 700.0 1.42433E7 sina
Time taken: 952.739 seconds, Fetched: 3 row(s) #952秒啊
#自己的笔记
hive> select avg(salary) as avgSalary ,max(salary) as maxSalary,min(salary) as minSalary,sum(salary) as totalSalary ,company as companyName from t_user_hbase group by company;#其别名查询
Query ID = root_20191107232034_4e0fa768-f704-4f13-bbd2-ff9a356f4925
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks not specified. Defaulting to jobconf value of: 2
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Starting Job = job_1573048606490_0027, Tracking URL = http://HadoopNode00:8088/proxy/application_1573048606490_0027/
Kill Command = /home/hadoop/hadoop-2.6.0/bin/hadoop job -kill job_1573048606490_0027
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 2
2019-11-07 23:21:28,383 Stage-1 map = 0%, reduce = 0%
2019-11-07 23:22:29,148 Stage-1 map = 0%, reduce = 0%
2019-11-07 23:23:24,012 Stage-1 map = 67%, reduce = 0%, Cumulative CPU 4.54 sec
2019-11-07 23:23:37,008 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 5.09 sec
2019-11-07 23:24:08,937 Stage-1 map = 100%, reduce = 67%, Cumulative CPU 6.86 sec
2019-11-07 23:24:27,313 Stage-1 map = 100%, reduce = 99%, Cumulative CPU 9.75 sec
2019-11-07 23:24:39,043 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 10.05 sec
MapReduce Total cumulative CPU time: 10 seconds 50 msec
Ended Job = job_1573048606490_0027
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Reduce: 2 Cumulative CPU: 11.18 sec HDFS Read: 15793 HDFS Write: 140 SUCCESS
Total MapReduce CPU Time Spent: 11 seconds 180 msec
OK
50809.72222222222 99900.0 200.0 1.82915E7 ali
50773.1778425656 99700.0 100.0 1.74152E7 baidu
48119.25675675676 99500.0 700.0 1.42433E7 sina
Time taken: 269.331 seconds, Fetched: 3 row(s)
#自己的笔记
#需要的进程
[root@HadoopNode00 ~]# jps
41873 Main
115152 NodeManager
61491 HRegionServer
114418 DataNode
109895 RunJar
62090 Jps
115050 ResourceManager
39724 QuorumPeerMain
114300 NameNode
61341 HMaster
43230 Main
114623 SecondaryNameNode
CREATE EXTERNAL table t_user_hbase(
id string,
name string,
age int,
salary double,
company string
)
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES('hbase.columns.mapping' = ':key,cf1:name,cf1:age,cf1:salary,cf1:company')
TBLPROPERTIES('hbase.table.name' = 'baizhi:t_user33');
0: jdbc:hive2://CentOS:10000> select avg(salary),max(salary),min(salary),sum(salary) ,company from t_user_hbase group by company;
#自己的笔记
#与上面的相同 --- 起了别名而已
select avg(salary) as avgSalary ,max(salary) as maxSalary,min(salary) as minSalary,sum(salary) as totalSalary ,company as companyName from t_user_hbase group by company;
有关Hive查询相关函数,可以参考:https://cwiki.apache.org/confluence/display/Hive/LanguageManual+UDF或者是hive编程指南.
1 、根据性别进行分组查询相同性别的平均工资 2、使用内连接,查询来自两个不同城市的人且具有相同的第一种爱好的人 3、按照年龄进行升序排序 4、按照年龄进行降序排序
1 .创建一个普通格式的表 user_info 要求字段: id name age hobby 字段分割为空格
2 . 导入相关格式数据 要求至少10行数据
3 .通过HIVE QL查询爱好为 Game的有多少人?
4 .通过HIVE QL查询年龄的最大的人
5.通过HIVE QL 查询年龄排名前三的三个人
6.创建一个普通格式的user_address 要求和之前的id相对 要求 id userid address 字段分割为空格
7.导入相关格式数据 要求至少10行数据
8.使用相关内置函数将user_info和user_address合并在一起并插入到一张新表当中
要求:每一题都需要都代码(或者SQL|导入语句|数据)和 运行成功截图 ,运行完成导出至PDF交给组长 发送给班长
,958 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 5.71 sec
2019-11-07 22:52:50,521 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 5.71 sec
2019-11-07 22:54:26,050 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 5.71 sec
2019-11-07 22:55:17,557 Stage-1 map = 100%, reduce = 33%, Cumulative CPU 14.59 sec
2019-11-07 22:55:19,624 Stage-1 map = 100%, reduce = 67%, Cumulative CPU 15.14 sec
2019-11-07 22:55:27,543 Stage-1 map = 100%, reduce = 83%, Cumulative CPU 17.53 sec
2019-11-07 22:55:28,709 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 19.29 sec
MapReduce Total cumulative CPU time: 19 seconds 290 msec
Ended Job = job_1573048606490_0021
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Reduce: 2 Cumulative CPU: 19.29 sec HDFS Read: 22236 HDFS Write: 140 SUCCESS
Total MapReduce CPU Time Spent: 19 seconds 290 msec
OK
50809.72222222222 99900.0 200.0 1.82915E7 ali
50773.1778425656 99700.0 100.0 1.74152E7 baidu
48119.25675675676 99500.0 700.0 1.42433E7 sina
Time taken: 952.739 seconds, Fetched: 3 row(s) #952秒啊
#自己的笔记
hive> select avg(salary) as avgSalary ,max(salary) as maxSalary,min(salary) as minSalary,sum(salary) as totalSalary ,company as companyName from t_user_hbase group by company;#其别名查询
Query ID = root_20191107232034_4e0fa768-f704-4f13-bbd2-ff9a356f4925
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks not specified. Defaulting to jobconf value of: 2
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=
In order to set a constant number of reducers:
set mapreduce.job.reduces=
Starting Job = job_1573048606490_0027, Tracking URL = http://HadoopNode00:8088/proxy/application_1573048606490_0027/
Kill Command = /home/hadoop/hadoop-2.6.0/bin/hadoop job -kill job_1573048606490_0027
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 2
2019-11-07 23:21:28,383 Stage-1 map = 0%, reduce = 0%
2019-11-07 23:22:29,148 Stage-1 map = 0%, reduce = 0%
2019-11-07 23:23:24,012 Stage-1 map = 67%, reduce = 0%, Cumulative CPU 4.54 sec
2019-11-07 23:23:37,008 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 5.09 sec
2019-11-07 23:24:08,937 Stage-1 map = 100%, reduce = 67%, Cumulative CPU 6.86 sec
2019-11-07 23:24:27,313 Stage-1 map = 100%, reduce = 99%, Cumulative CPU 9.75 sec
2019-11-07 23:24:39,043 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 10.05 sec
MapReduce Total cumulative CPU time: 10 seconds 50 msec
Ended Job = job_1573048606490_0027
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Reduce: 2 Cumulative CPU: 11.18 sec HDFS Read: 15793 HDFS Write: 140 SUCCESS
Total MapReduce CPU Time Spent: 11 seconds 180 msec
OK
50809.72222222222 99900.0 200.0 1.82915E7 ali
50773.1778425656 99700.0 100.0 1.74152E7 baidu
48119.25675675676 99500.0 700.0 1.42433E7 sina
Time taken: 269.331 seconds, Fetched: 3 row(s)
#自己的笔记
#需要的进程
[root@HadoopNode00 ~]# jps
41873 Main
115152 NodeManager
61491 HRegionServer
114418 DataNode
109895 RunJar
62090 Jps
115050 ResourceManager
39724 QuorumPeerMain
114300 NameNode
61341 HMaster
43230 Main
114623 SecondaryNameNode
CREATE EXTERNAL table t_user_hbase(
id string,
name string,
age int,
salary double,
company string
)
STORED BY ‘org.apache.hadoop.hive.hbase.HBaseStorageHandler’
WITH SERDEPROPERTIES(‘hbase.columns.mapping’ = ‘:key,cf1:name,cf1:age,cf1:salary,cf1:company’)
TBLPROPERTIES(‘hbase.table.name’ = ‘baizhi:t_user33’);
0: jdbc:hive2://CentOS:10000> select avg(salary),max(salary),min(salary),sum(salary) ,company from t_user_hbase group by company;
#自己的笔记
#与上面的相同 --- 起了别名而已
select avg(salary) as avgSalary ,max(salary) as maxSalary,min(salary) as minSalary,sum(salary) as totalSalary ,company as companyName from t_user_hbase group by company;
> 有关Hive查询相关函数,可以参考:https://cwiki.apache.org/confluence/display/Hive/LanguageManual+UDF或者是hive编程指南.
>
> ```shell
> 1 、根据性别进行分组查询相同性别的平均工资
>
> 2、使用内连接,查询来自两个不同城市的人且具有相同的第一种爱好的人
>
> 3、按照年龄进行升序排序
>
> 4、按照年龄进行降序排序
> ```
>
>
```shell
1 .创建一个普通格式的表 user_info 要求字段: id name age hobby 字段分割为空格
2 . 导入相关格式数据 要求至少10行数据
3 .通过HIVE QL查询爱好为 Game的有多少人?
4 .通过HIVE QL查询年龄的最大的人
5.通过HIVE QL 查询年龄排名前三的三个人
6.创建一个普通格式的user_address 要求和之前的id相对 要求 id userid address 字段分割为空格
7.导入相关格式数据 要求至少10行数据
8.使用相关内置函数将user_info和user_address合并在一起并插入到一张新表当中
要求:每一题都需要都代码(或者SQL|导入语句|数据)和 运行成功截图 ,运行完成导出至PDF交给组长 发送给班长