LabVIEW中使用unet快速实现图像分割
博客主页: virobotics的CSDN博客:LabVIEW深度学习、人工智能博主
所属专栏:『LabVIEW深度学习实战』
上期文章: 使用 LabVIEW调用LeNet快速搭建手写数字识别系统(内含源码)
如觉得博主文章写的不错或对你有所帮助的话,还望大家多多支持呀! 欢迎大家✌关注、点赞、✌收藏、订阅专栏
文章目录
- 前言
- 一、Unet简介
- 二、环境搭建
-
- 2.1 部署本项目时所用环境
- 2.2 LabVIEW工具包下载及安装网址
- 三、LabVIEW调用Unet实现图像分割
-
- 3.1 pytorch unet模型的获取
- 3.2 查看模型输出输出
- 3.3 实现图像分割(unet.vi)
- 四、项目源码
- 总结
前言
今天我们一起来学习一下在LabVIEW中部署Unet模型,实现图像分割。
一、Unet简介
Unet是一种用于图像分割的深度学习模型,其名称源自其U形的网络结构。最初由Olaf Ronneberger、Philipp Fischer和Thomas Brox在2015年的论文《U-Net: Convolutional Networks for Biomedical Image Segmentation》中提出,旨在解决生物医学图像分割的问题。
U-Net 起源于医疗图像分割,整个网络是标准的encoder-decoder网络,特点是参数少,计算快,应用性强,对于一般场景适应度很高。原始U-Net的结构如下图所示,由于网络整体结构类似于大写的英文字母U,故得名U-net。左侧可视为一个编码器,右侧可视为一个解码器。编码器有四个子模块,每个子模块包含两个卷积层,每个子模块之后通过max pool进行下采样。由于卷积使用的是valid模式,故实际输出比输入图像小一些。具体来说,后一个子模块的分辨率=(前一个子模块的分辨率-4)/2。U-Net使用了Overlap-tile 策略用于补全输入图像的上下信息,使得任意大小的输入图像都可获得无缝分割。同样解码器也包含四个子模块,分辨率通过上采样操作依次上升,直到与输入图像的分辨率基本一致。该网络还使用了跳跃连接,以拼接的方式将解码器和编码器中相同分辨率的feature map进行特征融合,帮助解码器更好地恢复目标的细节。
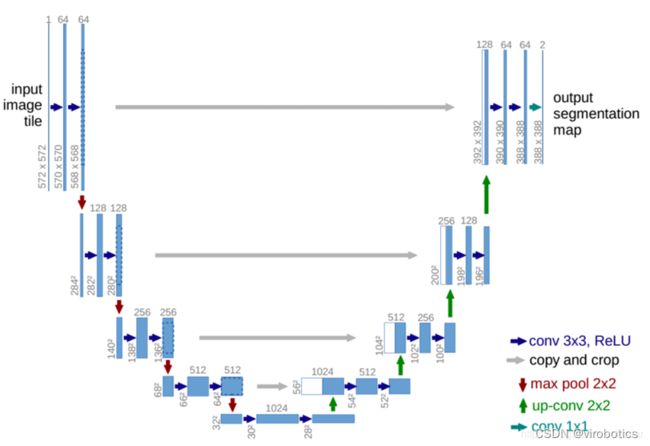
与传统的基于机器学习的图像分割方法相比,Unet具有更好的性能和更高的鲁棒性。在医学影像分割方面,Unet已被用于分割肝脏、肺部、乳腺、心脏和脑部等器官。
医疗影像分割的案例部署可查看博文:https://blog.csdn.net/virobotics/article/details/125260923
unet优缺点
- 优点:模型较为简单,对于某一特定类型分割比较清楚
- 缺点:网络无法提取太多特征,导致对输入图片的要求比较高(如周围环境、背景等。例如本案例中仅对数据集中的车辆能够较好地分割)
二、环境搭建
2.1 部署本项目时所用环境
- 操作系统:Windows10
- python:3.6及以上
- LabVIEW:2018及以上 64位版本
- AI视觉工具包:techforce_lib_opencv_cpu-1.0.0.98.vip
- onnx工具包:virobotics_lib_onnx_cuda_tensorrt-1.0.0.16.vip【1.0.0.16及以上版本】或virobotics_lib_onnx_cpu-1.13.1.2.vip
2.2 LabVIEW工具包下载及安装网址
- AI视觉工具包下载与安装参考:
https://blog.csdn.net/virobotics/article/details/123656523 - AI视觉工具包介绍:
https://blog.csdn.net/virobotics/article/details/123522165 - onnx工具包下载与安装参考:
https://blog.csdn.net/virobotics/article/details/124998746
三、LabVIEW调用Unet实现图像分割
3.1 pytorch unet模型的获取
我们已经给大家准备了Unet模型,可以直接使用~

当然,如果读者想要自己下载模型并转换为onnx模型,那可以按照如下方式下载
- 方式一(新版本模型文件pth格式): https://github.com/milesial/Pytorch-UNet/releases
- 方式二(老版本模型文件pth格式): https://github.com/milesial/Pytorch-UNet/releases/tag/v1.0
将下载好的pth转为onnx(toonnx.py)
#!/usr/bin/python3
import torch
from unet import UNet
def parseToOnnx():
net = UNet(n_channels=3, n_classes=2, bilinear=False)
net.load_state_dict(
torch.load('unet_carvana_scale0.5_epoch2.pth',
map_location=torch.device('cpu')))
print(net.eval())
batch_size, channels, height, width = 1, 3, 480, 640
inputs = torch.randn((batch_size, channels, height, width))
outputs = net(inputs)
assert outputs.shape[0] == batch_size
assert not torch.isnan(outputs).any(), 'Output included NaNs'
torch.onnx.export(
net, # model being run
inputs, # model input (or a tuple for multiple inputs)
"unet.onnx", # where to save the model (can be a file or file-like object)
export_params=
True, # store the trained parameter weights inside the model file
opset_version=11, # the ONNX version to export the model to
do_constant_folding=
False, # whether to execute constant folding for optimization
input_names=['inputs'], # the model's input names
output_names=['outputs'], # the model's output names
#dynamic_axes={
# 'inputs': {
# 0: 'batch_size'
# }, # variable lenght axes
#'outputs': {
# 0: 'batch_size'
#}
#}
)
print("ONNX model conversion is complete.")
return
parseToOnnx()
如果你想要自己训练模型,则可在官方网站下载数据集(温馨提示:数据集有点大哦)
官方数据集:https://www.kaggle.com/c/carvana-image-masking-challenge

3.2 查看模型输出输出
打开http://netron.app,载入本地onnx模型,我们可以看到模型的输入输出

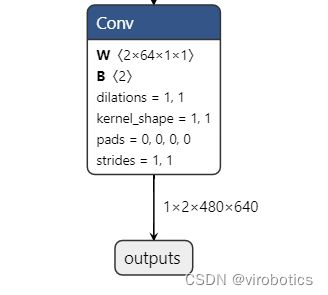
我们查看模型的输入shape,是因为推理过程Run_one_input.vi需要输入shape,不过我们也可以使用GetInputInfo.vi来直接获取模型输入的shape
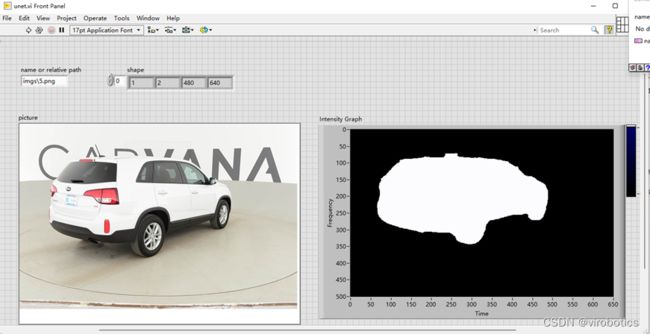
3.3 实现图像分割(unet.vi)
实现源码:
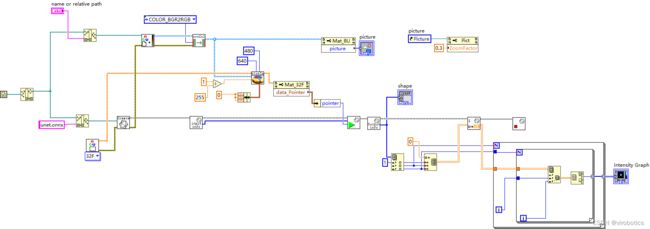
运行结果:
四、项目源码
码字不易,如需LabVIEW源码,请一键三连并订阅本专栏后评论区留下邮箱
总结
以上就是今天要给大家分享的内容,希望对大家有用。我们下篇文章见~
创作不易,如果文章对你有帮助,欢迎✌关注、点赞、✌收藏、订阅专栏
推荐阅读
LabVIEW图形化的AI视觉开发平台(非NI Vision),大幅降低人工智能开发门槛
LabVIEW图形化的AI视觉开发平台(非NI Vision)VI简介
LabVIEW AI视觉工具包OpenCV Mat基本用法和属性
手把手教你使用LabVIEW人工智能视觉工具包快速实现图像读取与采集
使用LabVIEW实现基于pytorch的DeepLabv3图像语义分割
使用LabVIEW实现 DeepLabv3+ 语义分割含源码
技术交流 · 一起学习 · 咨询分享,请联系