DPDK技术介绍
DPDK是INTEL公司开发的一款高性能的网络驱动组件,旨在为数据面应用程序提供一个简单方便的,完整的,快速的数据包处理解决方案,主要技术有用户态、轮询取代中断、零拷贝、网卡RSS、访存DirectIO等。
一、主要特点
1、UIO(Linux Userspace I/O)
提供应用空间下驱动程序的支持,也就是说网卡驱动是运行在用户空间的,减下了报文在用户空间和应用空间的多次拷贝。如图:DPDK绕过了Linux内核的网络驱动模块,直接从网络硬件到达用户空间,不需要进行频繁的内存拷贝和系统调用。根据官方给出的数据,DPDK裸包反弹每个包需要80个时钟周期,而传统Linux内核协议栈每包需要2k~4k个时钟周期。DPDK能显著提升虚拟化网络设备的数据采集效率。
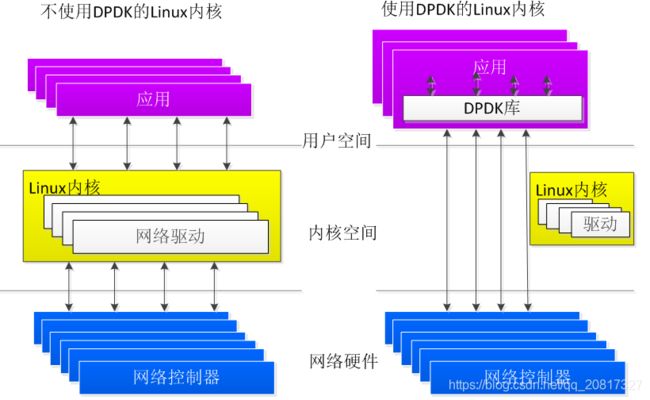
下图为UIO技术的工作原理图

UIO技术将设备驱动分为用户空间驱动和内核空间驱动两部分,内核空间驱动主要负责设备资源分配、UIO设备注册以及小部分中断响应函数,驱动的大部分工作在用户空间的驱动程序下完成。通过UIO框架提供的API接口将UIO的驱动注册到内核,注册完成后将生成存有设备物理地址等信息的map文件,用户态进程访问该文件将设备对应的内存空间地址映射到用户空间,即可直接操作设备的内存空间,UIO技术使得应用程序可以通过用户空间驱动直接操作设备的内存空间,避免了数据在内核缓冲区和应用程序缓冲区的多次拷贝,提供数据处理效率。
简单地说,DPDK使高速数据包网络应用程序的开发变得更快,这意味着它允许构建能够更快地处理数据包的应用程序,这多亏了内核的绕过。实际上,它使用了快速路径,而不是正常的网络层路径和上下文切换路径。包被直接传递到用户空间(作为原始包)。如下图为linux内核包处理和dpdk包处理的区别。
linux内核处理包:
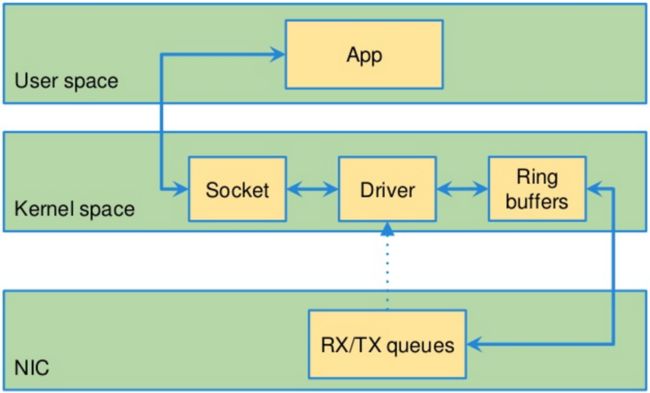
dpdk处理包:
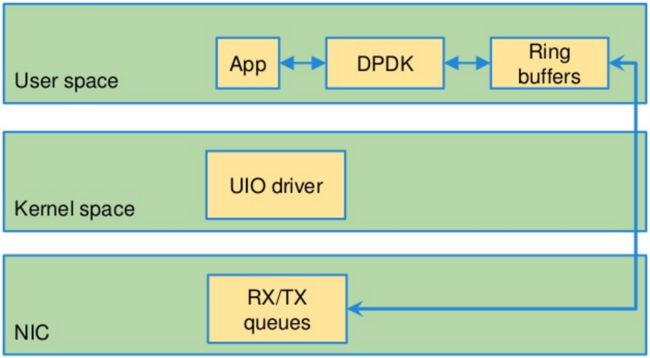
下图为slow路径和fast路径比较:

2、用户空间轮询模式(PMD)
传统中断模式: 传统Linux系统中,当网络设备检测到数据帧过来的时候,会使用DMA(直接内存访问)将帧发送到预先分配好的内核缓冲区里面,然后更新相应的接收描述符环,之后产生中断通知有数据帧过来。Linux系统会进行相应的响应,然后更新相应的描述符环,再将接收到的数据帧交给内核中的网络堆栈进行处理,网络堆栈处理完之后会将相应的数据拷贝到相应的套接字,从而数据就被复制到了用户空间,应用程序就可以使用这些数据了,数据帧的接收过程如图:

在发送的时候,一旦用户程序处理完了数据,会通过一个系统调用将数据写入到套接字,将数据从用户空间拷贝到内核空间的缓冲区,交由网络堆栈进行处理,网络堆栈根据需要对数据进行封装并调用网卡设备的驱动程序,网卡设备驱动程序会更新传输描述符环,然后向网卡设备告知有数据帧需要传输。网卡设备会将数据帧从内核中的缓冲区拷贝到自己的缓冲区中并发送到网络链路上,传送到链路上之后,网卡设备会通过一个中断告知成功发送,然后内核会释放相应的缓冲区。数据的发送如图:

由于linux系统是通过中断的方式告知CPU有数据包过来的,当网络的流量越来越大,linux系统会浪费越来越多的时间去处理中断,当流量速率达到10G的时候,linux系统可能会被中断淹没,浪费很多CPU资源。
DPDK用户空间的轮询模式驱动:用户空间驱动使得应用程序不需要经过linux内核就可以访问网络设备卡。网卡设备可以通过DMA方式将数据包传输到事先分配好的缓冲区,这个缓冲区位于用户空间,应用程序通过不断轮询的方式可以读取数据包并在原地址上直接处理,不需要中断,而且也省去了内核到应用层的数据包拷贝过程。
因此相对于linux系统传统中断方式,Intel DPDK避免了中断处理、上下文切换、系统调用、数据复制带来的性能上的消耗,大大提升了数据包的处理性能。同时由于Intel DPDK在用户空间就可以开发驱动,与传统的在内核中开发驱动相比,安全系数大大降低。因为内核层权限比较高,操作相对比较危险,可能因为小的代码bug就会导致系统崩溃,需要仔细的开发和广泛的测试。而在应用层则相反,比较安全,且在应用层调试代码要方便的多。
3、大页内存
Linux操作系统通过查找TLB来实现快速的虚拟地址到物理地址的转化。由于TLB是一块高速缓冲cache,容量比较小,容易发生没有命中。当没有命中的时候,会触发一个中断,然后会访问内存来刷新页表,这样会造成比较大的时延,降低性能。Linux操作系统的页大小只有4K,所以当应用程序占用的内存比较大的时候,会需要较多的页表,开销比较大,而且容易造成未命中。相比于linux系统的4KB页,Intel DPDK缓冲区管理库提供了Hugepage大页内存,大小有2MB和1GB页面两种,可以得到明显性能的提升,因为采用大页内存的话,可以需要更少的页,从而需要更少的TLB,这样就减少了虚拟页地址到物理页地址的转换时间。‘
DPDK中的内存管理如图,最下面是连续的物理内存,这些物理内存是由2MB的大页组成,连续的物理内存上面是内存段,内存段之上则是内存区,我们分配的基本单元对象是在内存区中分配的,内存区包含了ring队列,内存池、LPM路由表还有其他一些高性能的关键结构。
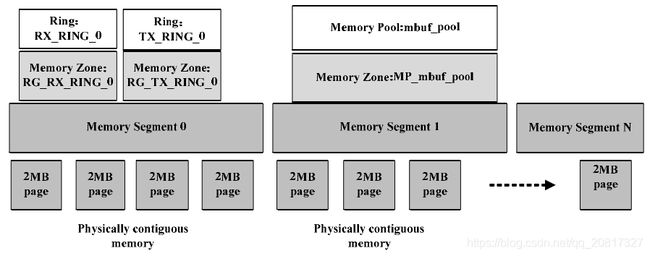
4、CPU亲和性
CPU的亲和性(CPU affinity),它是多核CPU发展的结果。随着核心的数量越来越多,为了提高程序工作的效率必须使用多线程。但是随着CPU的核心的数目的增长,Linux的核心间的调度和共享内存争用会严重影响性能。利用Intel DPDK的CPU affinity可以将各个线程绑定到不同的cpu,可以省去来回反复调度带来的性能上的消耗。
在一个多核处理器的机器上,每个CPU核心本身都存在自己的缓存,缓冲区里存放着线程使用的信息。如果线程没有绑定CPU核,那么线程可能被Linux系统调度到其他的CPU上,这样的话,CPU的cache命中率就降低了。利用CPU的affinity技术,一旦线程绑定到某个CPU后,线程就会一直在指定的CPU上运行,操作系统不会将其调度到其他的CPU上,节省了调度的性能消耗,从而提升了程序执行的效率。
多核轮询模式:多核轮询模式有两种,分别是IO独占式和流水线式。IO独占式是指每个核独立完成数据包的接收、处理和发送过程,核之间相互独立,其优点是其中一个核出现问题时不影响其他核的数据收发。流水线式则采用多核合作的方式处理数据包,数据包的接收、处理和发送由不同的核完成。流水线式适合面向流的数据处理,其优点是可对数据包按照接收的顺序有序进行处理,缺点是当某个环境(例如接收)所涉及的核出现阻塞,则会造成收发中断。
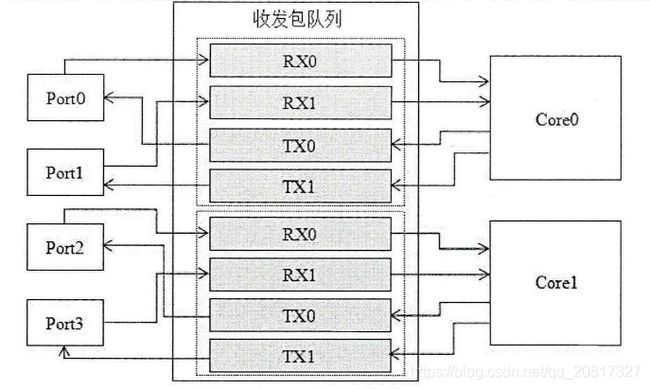
IO独占式多核轮询模式中每个网卡只分配给一个逻辑核进行处理。每个逻辑核给所接管的网卡分别分配一个发送队列和一个接收队列,并且独立完成数据包的接收、处理和发送的过程,核与核之间相互独立。系统数据包的处理由多个逻辑核同时进行,每个网卡的收发包队列只能由一个逻辑核提供。当数据包进入网卡的硬件缓存区,用户空间提供的网卡驱动通过轮询得知网卡收到数据包,从硬件缓冲区中取出数据包,并将数据包存入逻辑核提供的收包队列中,逻辑核取出收包队列中的数据包进行处理,处理完毕后将数据包存入逻辑核提供的发包队列,然后由网卡驱动取出发往网卡,最终发送到网络中。
IO独占式多核轮询模式架构图:
5、内存池和无锁环形缓存管理
此外Intel DPDK将库和API优化成了无锁,比如无锁队列,可以防止多线程程序发生死锁。然后对缓冲区等数据结构进行了cache对齐。如果没有cache对齐,则可能在内存访问的时候多读写一次内存和cache。
内存池缓存区的申请和释放采用的是生产者-消费者模式无锁缓存队列进行管理,避免队列中锁的开销,在缓存区的使用过程中提高了缓冲区申请释放的效率。
无锁环形队列生产过程:

无锁环形队列消费过程:

如图所示,生产者往队列里存放内容的方向和消费者从队列里取内容的方向一致,均以顺时针方向进行。当缓存区向内存池申请内存块,或者应用程序进行内存块的释放时,缓存区的无锁环形队列的生产者指针顺时针移动,往队列中存入内存块地址信息,进行缓存队列的生产过程。当应用程序需要向缓冲区申请内存块使用时,缓冲区的无锁环形队列的消费者指针以顺时针的方向取出队列的内存块地址,分配给应用程序使用,该过程为缓存队列的消费过程。
生产n个对象过程:首先生产者头指针往顺时针方向移n个位置获得新的头指针,然后从生产者尾指针指的区域开始逐个存入n个对象,最后生产者尾指针顺时针移动n个位置获得新的生产者尾指针
消费n个对象过程:首先消费者头指针顺时针移动n个位置获得新的消费者头指针,然后从消费者尾指针处开始逐个读取n个对象,最后消费者尾指针顺时针移动n个位置获得新的消费者尾指针。
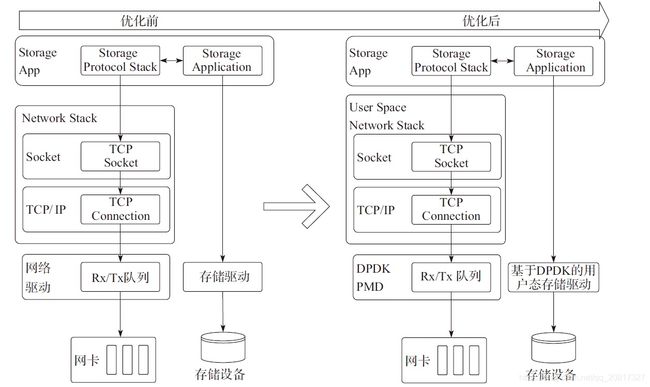
6、网络存储优化
二、架构与核心组件
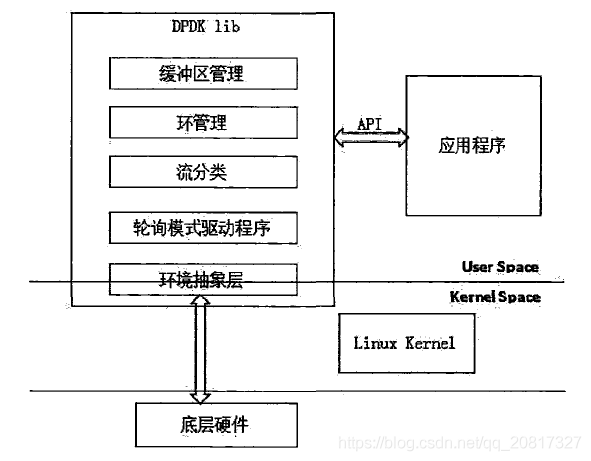
1、 DPDK总体架构

2、核心组件
DPDK主要有六个核心组件
1、 环境抽象层(EAL):为DPDK其他组件和应用程序提供一个屏蔽具体平台特性的统一接口,环境抽象层提供的功能主要有:DPDK加载和启动;支持多核和多线程执行类型;CPU核亲和性处理;原子操作和锁操作接口;时钟参考;PCI总线访问接口;跟踪和调试接口;CPU特性采集接口;中断和告警接口等。
2、 堆内存管理组件(Malloc lib):堆内存管理组件为应用程序提供从大页内存分配对内存的接口。当需要分配大量内存小块时,使用这些接口可以减少TLB缺页。
3、 环缓冲区管理组件(Ring lib):环缓冲区管理组件为应用程序和其他组件提供一个无锁的多生产者多消费者FIFO队列API:Ring。Ring是借鉴了Linux内核kfifo无锁队列,可以无锁出入对,支持多消费/生产者同时出入队。
4、 内存池管理组件(Mem pool lib):为应用程序和其他组件提供分配内存池的接口,内存池是一个由固定大小的多个内存块组成的内存容器,可用于存储相同对象实体,如报文缓存块等。内存池由内存池的名称来唯一标识,它由一个环缓冲区和一组核本地缓存队列组成,每个核从自己的缓存队列分配内存块,当本地缓存队列减少到一定程度时,从内存缓冲区中申请内存块来补充本地队列。
5、 网络报文缓存块管理组件(Mbuf lib):提供应用程序创建和释放用于存储报文信息的缓存块的接口,这些MBUF存储在内存池中。提供两种类型的MBUF,一种用于存储一般信息,一种用于存储报文信息。
6、 定时器组件(Timer lib):提供一些异步周期执行的接口(也可以只执行一次),可以指定某个函数在规定的时间异步的执行,就像LIBC中的timer定时器,但是这里的定时器需要应用程序在主循环中周期调用rte_timer_manage来使定时器得到执行。定时器组件的时间参考来自EAL层提供的时间接口。
除了以上六个核心组件外,DPDK还提供以下功能:
1) 以太网轮询模式驱动(PMD)架构:把以太网驱动从内核移到应用层,采用同步轮询机制而不是内核态的异步中断机制来提高报文的接收和发送效率。
2)报文转发算法支持:Hash 库和LPM库为报文转发算法提供支持。
3) 网络协议定义和相关宏定义:基于FreeBSD IP协议栈的相关定义如:TCP、UDP、SCTP等协议头定义。
4)报文QOS调度库:支持随机早检测、流量整形、严格优先级和加权随机循环优先级调度等相关QOS 功能。
5)内核网络接口库(KNI):提供一种DPDK应用程序与内核协议栈的通信的方法、类似普通Linux的TUN/TAP接口,但比TUN/TAP接口效率高。每个物理网口可以虚拟出多个KNI接口。
3、KNI组件
KNI是DPDK平台提供的用于将数据重入内核协议栈的一个组件,其目的是充分运用传统内核协议栈已实现的较稳定的协议处理功能。DPDK平台对数据包的处理绕过了内核协议栈,直接交给用户空间处理,而用户空间没有完善的协议处理栈,如果让开发人员在用户空间实现完整独立的协议栈,开发工作是非常复杂的,因此DPDK平台提供了KNI组件,开发人员可以在用户空间实现一些特殊的协议处理功能,再通过KNI重入内核协议栈功能将普通常见的协议交由传统内核协议栈处理。KNI通信机制如下:
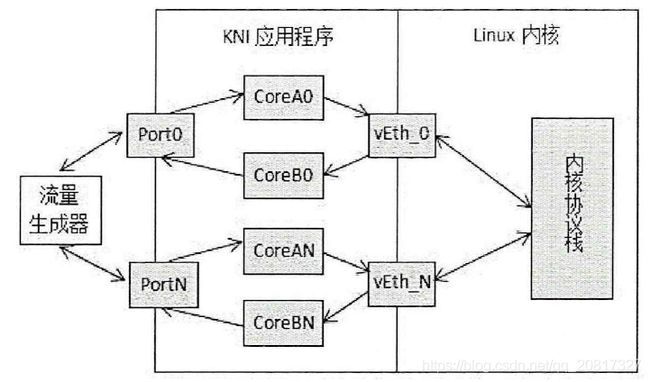
KNI组件通过创建KNI虚拟接口设备,将数据包经过虚拟接口实现用户空间和内核协议栈间的通信。当网卡接收到数据包时,应用程序通过用户空间驱动将数据包获取到用户空间,KNI组件将需要数据包发送至KNI虚拟接口,由KNI虚拟接口交给内核协议栈处理,处理后若有响应报文,则再交给KNI虚拟接口返回给应用程序。其中发送数据包至内核协议栈以及接收内核协议栈回复的数据包,是由两个不同的逻辑核分别进行处理,不阻塞应用程序让内核协议栈发送数据包或从内核协议栈接收数据包的过程。
KNI接口实际上是一个虚拟出来的设备,该虚拟设备定义了四个队列,分别是接收队列(rx_q)、发送队列(tx_q)、已分配内存块队列(alloc_q)、待释放内存块队列(free_q)。接收队列用于存放用户空间程序发往KNI虚拟设备的报文,发送队列用于存放内核协议栈要往KNI虚拟设备的报文。已分配内存块队列存放已向内存中申请的内存块,供内核协议栈发送报文时取出使用。待释放内存块队列用于记录KNI虚拟设备从用户空间程序处接收到报文后将不再使用的内存块,然后将该队列中的内存块释放回内存。用户空间程序从网卡接收到报文时,将报文发送给KNI虚拟设备,KNI虚拟设备接收到用户空间程序发来的报文后,交给内核协议栈进行协议解析。发送报文时,原始数据先由内核协议栈进行协议封装,然后将报文发送给KNI虚拟设备,KNI虚拟设备接收到报文后,再将报文发送给用户空间程序。

————————————————
原文链接:https://blog.csdn.net/qq_20817327/article/details/105587309