SUNet: Swin Transformer UNet for ImageDenoising
Abstract
图像恢复是一个具有挑战性的不适定问题,也是一个长期存在的问题。在过去的几年中,卷积神经网络(cnn)几乎主导了计算机视觉,并在不同层次的视觉任务中取得了相当大的成功,包括图像恢复。然而,最近基于Swin transformer的模型也表现出了令人印象深刻的性能,甚至超过了基于cnn的方法,成为高级视觉任务的最先进的技术。在本文中,我们提出了一个名为SUNet的恢复模型,它使用Swin Transformer层作为我们的基本块,然后应用到UNet体系结构中进行图像去噪。源代码和经过训练的模型可以在https://github.com/FanChiMao/SUNet上找到。
I. INTRODUCTION
图像恢复是一种重要的底层图像处理方法,可以提高目标检测、图像分割和图像分类等高级视觉任务的性能。在一般的恢复任务中,损坏的图像Y可以表示为:

其中X为干净图像,D(.)为退化函数,n为加性噪声。一些常见的恢复任务是去噪、去模糊和块化。
传统的图像恢复方法通常是基于算法的,称为基于先验或基于模型的方法,如BM3D[1]、WNNM[2]进行去噪;反卷积[3],图像优先于[4]去模糊。虽然大多数基于卷积神经网络(CNN)的方法已经取得了很好的性能[5]-[10],但朴素卷积层存在一些问题。首先,卷积核与图像是内容无关的。使用相同的卷积核来恢复不同的图像区域可能不是最好的解决方案[11],[12]。其次,因为卷积内核可以被看作是一个小的patch,其中获取的特征是局部信息,也就是说,在我们进行远程依赖建模时,会丢失全局信息。虽然在一些论文中提出了自适应卷积[13]、[14]、非局部卷积[15]、全局平均池化[16]等方法来克服这些缺陷,但直到Swin Transformer的出现才有效地解决了这些问题。
最近,[11]提出了一种新的基于transformer的骨干网——Swin transformer,并在图像分类方面取得了令人印象深刻的性能。此外,在越来越多的计算机视觉任务中,包括图像分割[11]、[17]-[19]、物体检测[11]、嵌绘[20]、超分辨率[12]、[21],使用Swin Transformer作为骨干已经超越了基于cnn的方法,达到了最先进的水平。在本文中,我们也将Swin Transformer作为我们的主要骨干,并将其集成到名为SUNet的UNet架构中,用于图像去噪。
总体而言,本文的主要贡献可归纳如下:
- 我们提出了一种基于图像分割Swin-UNet模型的Swin Transformer网络,用于图像去噪。
- 我们提出了一种双上采样块架构,其包括子像素和双线性上采样方法以防止棋盘伪影。实验结果表明,该方法优于原来的转置卷积上采样方法。
- 据我们所知,我们的模型是第一个将Swin Transformer和UNet纳入去噪的模型。
- 我们在两个常见的图像去噪数据集中展示了我们的SUNet的竞争结果。
II. RELATED WORK
随着硬件的快速发展(例如基于学习的方法在执行速度和性能上都击败了传统的基于模型的方法。在本节中,我们首先将介绍以前关于去噪的工作。然后,我们将描述UNet和Swin Transformer的相关工作。
A. Image Restoration
如前所述,传统的图像恢复方法是基于图像先验或通常称为基于模型的方法的算法,例如自相似性[1],[22],备用编码[23],[24]和全变差[25]。这些方法在解决不适定问题上的性能是可以接受的,但也存在一些缺点,如耗时、计算量大、难以恢复复杂的图像纹理等。与传统的复原方法相比,基于学习的方法,特别是卷积神经网络(CNN),由于其令人印象深刻的性能,已经成为包括图像复原在内的计算机视觉领域的主流。
B. UNet
目前,UNet [5]是许多图像处理应用中众所周知的架构,因为它具有分层特征映射以获得丰富的多尺度上下文特征。此外,它使用编码器和解码器之间的跳跃连接来增强图像的重建过程。UNet广泛用于许多计算机视觉任务,如分割,恢复[9],[26]。此外,它还有各种改进版本,如Res-UNet [27],Dense-UNet [28],Attention UNet [29]和Non-local UNet [30]。由于强大的自适应骨干,UNet可以很容易地应用于不同的提取块,以提高性能。
C. Swin Transformer
Transformer[31]模型在自然语言处理(NLP)领域取得了成功,在图像分类[32]、[33]方面也具有与cnn相当的性能。然而,直接将转换器用于视觉任务的两个主要问题是:1)图像与序列的尺度差异较大。由于需要一维序列参数的平方倍左右,transform存在长序列建模的缺陷。2) Transformer不擅长解决实例分割等密集的预测任务,这是一个像素级任务[34]。而Swin Transformer[11]通过移动窗口来降低参数,解决了上述问题,并在大量像素级视觉任务中取得了目前最先进的性能。
III. PROPOSED METHOD
A. SUNet
本文提出的Swin Transformer UNet (SUNet)的架构基于图像分割模型[19],如图1所示。SUNet由三个模块组成:1)浅层特征提取;2) UNet特征提取;3)重建模块。
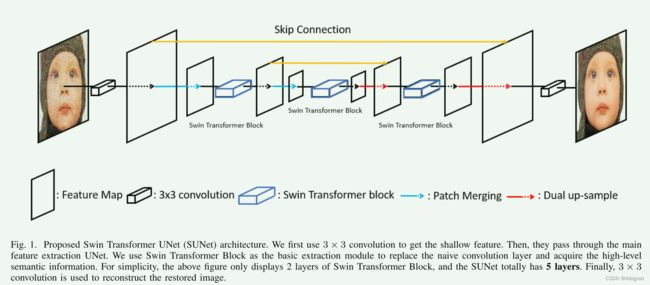



B. Swin Transformer Block
在UNet提取模块中,我们使用STB代替传统的卷积层,如图2所示。STL[11]是基于NLP原始的Transformer层[31]。STL的个数总是2的倍数,其中一个是窗口型多头自我注意(W-MSA),另一个是移窗型多头自我注意(SWMSA)。正如在第II-C节中提到的,在CV任务中直接使用Transformer存在一些问题。因此,他们提出循环移位技术,以减少计算时间,并保持卷积的特性,包括接收场与层之间关系的平移不变性、旋转不变性和大小不变性。由于页面的限制,我们在本文中没有解释SW-MSA的原理以及它可以减少多少计算复杂度。但我们想强调Swin Transformer的一个关键属性(即,我们可以像卷积运算一样控制输出特性的分辨率(H,W)和通道数(C))。以图2(b)为例,整个过程表示为:

其中LN(.)表示层归一化,MLP为多层感知器,具有两个全连通层,具有高斯误差线性单元(GELU)激活函数。
C. Resizing module
由于UNet具有不同尺度的特征图,因此需要调整大小模块(如下采样和上采样)。在我们的SUNet中,我们使用patch merge和提出的双上样本分别作为下采样和上采样模块。
Patch merging.
对于下采样模块,我们按照[11],[19]将每组2 × 2相邻patch的输入特征串接起来,然后利用线性层得到指定的输出特征通道数。我们也可以把这看作是做卷积运算的第一步,也就是展开输入的特征图。
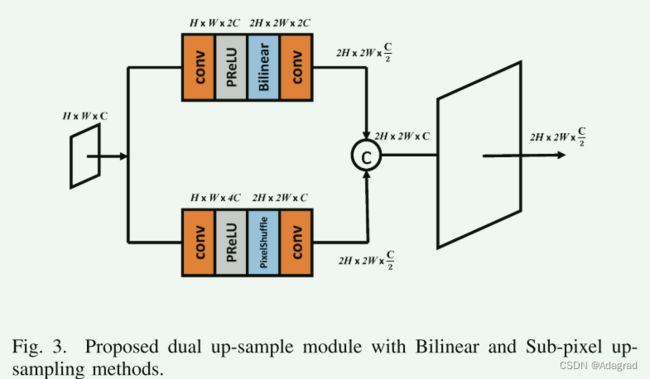
Dual up-sample.
对于上采样,原来的Swin-UNet[19]采用的是patch展开方法,相当于上采样模块的转置卷积。然而,转置卷积很容易面对块效应。在这里,我们提出了一个名为dual up-sample的新模块,它由两个现有的上样方法(即Bilinear和PixelShuffle[35])组成,以防止棋盘伪像。所提出的上采样模块的结构如图3所示。
IV. EXPERIMENTS
我们将我们的SUNet与基于先验的方法(如CBM3D[38])、基于cnn的方法(如DnCNN[6]、IrCNN[10]、FFDNet[7])和基于UNet的方法(如UNet[5]、DHDN[8]、RDUNet[9])进行了比较。图4为图像去噪后[39]、[40]结果的视觉比较。在表1中,我们对去噪后的图像进行了客观的质量评价[41]-[43],观察到以下三点:1)我们的SUNet具有有竞争力的SSIM值,因为Swin-Transformer是基于全局信息的,这使得去噪后的图像在感知上更加可信。2)与基于unet的方法(DHDN、RDUNet)相比,所提出的SUNet在三种模型中参数(↓60%)、FLOPs(↓3%)均较低,在PSNR和SSIM上均保持较高的分数。3)与基于cnn的方法(DnCNN、IrCNN、FFDNet)相比,我们的PSNR和SSIM结果最好,FLOPs几乎相同。虽然我们的模型的参数最大(99M),但这是由于自注意操作不能共享核的权值造成的。然而,更合理的是,不同层中的特性应该使用不同的内核值,正如我们在第1节中讨论的那样。
V. CONCLUSION
本文提出了基于Swin Transformer新骨干的SUNet架构,并在去噪方面取得了较好的效果。此外,我们提出了双上样例模块,以避免棋盘效应。现在说Swin Transformer可以取代卷积还为时过早。然而,Swin Transformer的潜力在未来仍然值得期待。我们未来的工作将尝试更复杂的恢复任务,如真实世界的噪音和真实世界的模糊,而模型仍然基于Swin-Transformer层。