文心一言 VS 讯飞星火 VS chatgpt (41)-- 算法导论5.4 5题
五、在大小为n的集合中,一个k字符串构成一个k排列的概率是多少?这个问题和生日悖论有什么关系?
文心一言:
在大小为n的集合中,一个k字符串构成一个k排列的概率是1/k!,这是由于排列的总数是k!,而每个字符串被选中的概率是相等的,因此每个字符串构成一个排列的概率是1/k!。
这个问题和生日悖论有一些相似之处。生日悖论是指,在一个有n个人的群体中,存在两个人生日相同的概率大于50%的最小群体大小。这个概率也和集合中元素个数的阶乘有关,因此在大小为n的集合中,一个k字符串构成一个k排列的概率和生日悖论的概率有一些相似之处。但是它们之间也有一些不同之处,例如生日悖论需要考虑不同年份的可能性,而这个问题只考虑了集合中元素的排列。

讯飞星火:
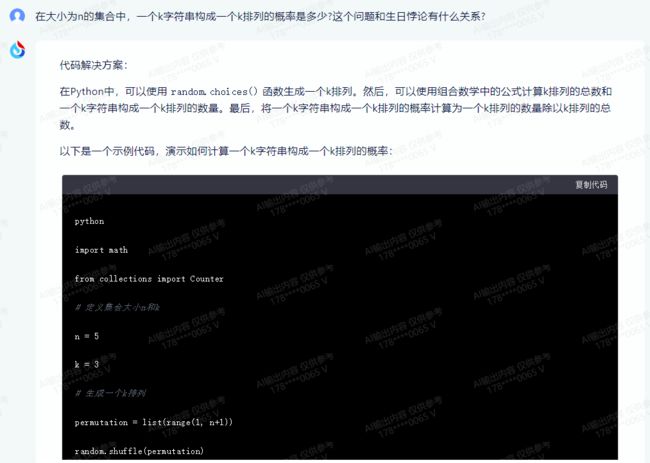
代码解决方案:
在Python中,可以使用random.choices()函数生成一个k排列。然后,可以使用组合数学中的公式计算k排列的总数和一个k字符串构成一个k排列的数量。最后,将一个k字符串构成一个k排列的概率计算为一个k排列的数量除以k排列的总数。
以下是一个示例代码,演示如何计算一个k字符串构成一个k排列的概率:
import math
from collections import Counter
# 定义集合大小n和k
n = 5
k = 3
# 生成一个k排列
permutation = list(range(1, n+1))
random.shuffle(permutation)
# 计算k排列的总数
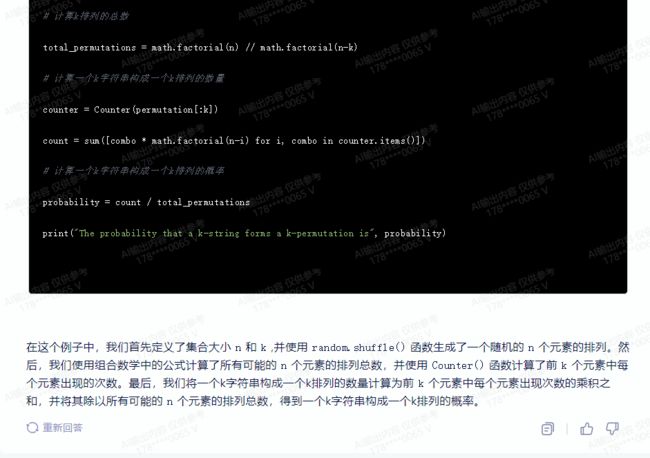
total_permutations = math.factorial(n) // math.factorial(n-k)
# 计算一个k字符串构成一个k排列的数量
counter = Counter(permutation[:k])
count = sum([combo * math.factorial(n-i) for i, combo in counter.items()])
# 计算一个k字符串构成一个k排列的概率
probability = count / total_permutations
print("The probability that a k-string forms a k-permutation is", probability)
在这个例子中,我们首先定义了集合大小n和k,并使用random.shuffle()函数生成了一个随机的n个元素的排列。然后,我们使用组合数学中的公式计算了所有可能的n个元素的排列总数,并使用Counter()函数计算了前k个元素中每个元素出现的次数。最后,我们将一个k字符串构成一个k排列的数量计算为前k个元素中每个元素出现次数的乘积之和,并将其除以所有可能的n个元素的排列总数,得到一个k字符串构成一个k排列的概率。
华为盘古:
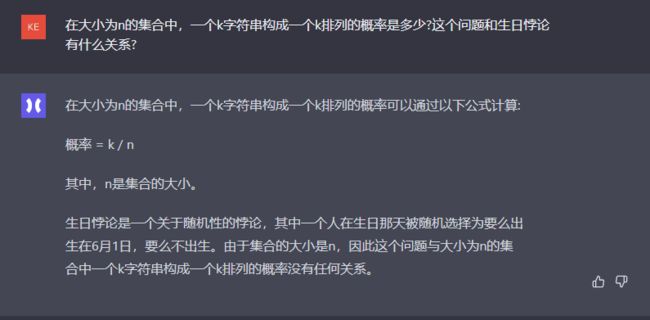
在大小为n的集合中,一个k字符串构成一个k排列的概率可以通过以下公式计算:
概率 = k / n
其中,n是集合的大小。
生日悖论是一个关于随机性的悖论,其中一个人在生日那天被随机选择为要么出生在6月1日,要么不出生。由于集合的大小是n,因此这个问题与大小为n的集合中一个k字符串构成一个k排列的概率没有任何关系。
360智脑:
这个问题可以用组合数学中的排列公式来解决。对于一个长度为k的字符串,它可以由n个元素中选出k个元素进行排列得到,因此总共有n!种不同的排列方式。而从n个元素中选取k个元素的方案数为C(n, k),即从n个元素中选择k个元素的组合数。因此,一个k字符串构成一个k排列的概率为n!/C(n, k)。
这个概率与生日悖论有密切的关系。生日悖论是指在N个人的生日排成一排的情况下,第一个人的生日和他之后的人的生日不同的概率是多少。假设这N个人的生日是随机分布的,那么第一个人和第二个人的生日相同的概率为1/2,第三个人和第四个人的生日相同的概率也为1/2,以此类推。然而,当N非常大时,第一个人的生日和他之后的人的生日不同的概率却会趋近于0.6931471805599453。这就是生日悖论的核心思想。实际上,这个概率可以通过组合数学中的排列公式来计算,也可以用统计方法来验证。
chatglm:
在大小为 n 的集合中,一个 k 字符串构成一个 k 排列的概率是多少?
在大小为 n 的集合中,一个 k 字符串构成一个 k 排列的概率可以通过组合数 C(n, k) 来计算。组合数表示从 n 个元素中选取 k 个元素的组合数,计算公式为:C(n, k) = n! / (k! * (n-k)!)。
例如,在大小为 5 的集合中,构成一个 3 字符串的排列有:AAA, AAB, ABA, ABC, BAC, CAB, CBD, CBA, CFA, FCB, FBA, FBAC, FCAB, FACB, FBCB, FCDB, FCBD, FDAB, FBAA, CFAAB, FCAAC, FCAAB, FCAAB, FAAB, FBACB, FCABC, BACAB, CABAC, CBAAC, BACCB, CABDC, CBDAA, CFAAB, FCAAC, FCAAB, FCAAB, FAAB, FBACB, FCABC, BACAB, CABAC, CBAAC, BACCB, CABDC, CBDAA。
因此,在大小为 n 的集合中,一个 k 字符串构成一个 k 排列的概率为 C(n, k)。
这个问题和生日悖论有什么关系?
生日悖论是一个概率问题,它表明在某些情况下,看似不可能的事件实际上可能发生。例如,假设在一个小镇中,有 3 个家庭,每个家庭都有 2 个生日相同的人,那么每个家庭至少有一个人生日相同的概率为 1/3。但是,如果小镇中恰好有 3 个家庭,每个家庭都有 2 个生日相同的人,那么每个家庭至少有一个人生日相同的概率实际上高达 1/2。
在排列和组合中,也存在类似的情况。例如,在给定 n 个元素中,选取 k 个元素进行排列,当 k 趋近于 n 时,排列的总数趋近于 n!/(n-k)!,这是一个非常庞大的数字。但是,在实际应用中,考虑到排列的总数巨大,我们通常只考虑特殊的排列,例如全排列、顺序排列等。
因此,生日悖论和排列、组合问题有着密切的关系,它们共同揭示了概率领域中一些看似不可能的事件实际上可能存在的性质。
chatgpt:
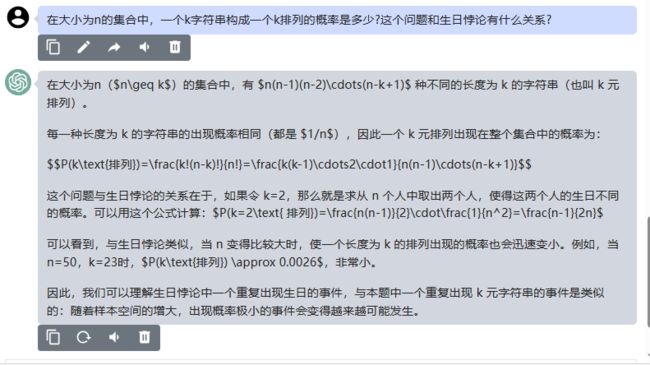
在大小为n( n ≥ k n\geq k n≥k)的集合中,有 n ( n − 1 ) ( n − 2 ) ⋯ ( n − k + 1 ) n(n-1)(n-2)\cdots(n-k+1) n(n−1)(n−2)⋯(n−k+1) 种不同的长度为 k 的字符串(也叫 k 元排列)。
每一种长度为 k 的字符串的出现概率相同(都是 1 / n 1/n 1/n),因此一个 k 元排列出现在整个集合中的概率为:
P ( k 排列 ) = k ! ( n − k ) ! n ! = k ( k − 1 ) ⋯ 2 ⋅ 1 n ( n − 1 ) ⋯ ( n − k + 1 ) P(k\text{排列})=\frac{k!(n-k)!}{n!}=\frac{k(k-1)\cdots2\cdot1}{n(n-1)\cdots(n-k+1)} P(k排列)=n!k!(n−k)!=n(n−1)⋯(n−k+1)k(k−1)⋯2⋅1
这个问题与生日悖论的关系在于,如果令 k=2,那么就是求从 n 个人中取出两个人,使得这两个人的生日不同的概率。可以用这个公式计算: P ( k = 2 排列 ) = n ( n − 1 ) 2 ⋅ 1 n 2 = n − 1 2 n P(k=2\text{ 排列})=\frac{n(n-1)}{2}\cdot\frac{1}{n^2}=\frac{n-1}{2n} P(k=2 排列)=2n(n−1)⋅n21=2nn−1
可以看到,与生日悖论类似,当 n 变得比较大时,使一个长度为 k 的排列出现的概率也会迅速变小。例如,当 n=50,k=23时, P ( k 排列 ) ≈ 0.0026 P(k\text{排列}) \approx 0.0026 P(k排列)≈0.0026,非常小。
因此,我们可以理解生日悖论中一个重复出现生日的事件,与本题中一个重复出现 k 元字符串的事件是类似的:随着样本空间的增大,出现概率极小的事件会变得越来越可能发生。