【自监督学习1】SimCLR论文阅读
文章目录
- 一、摘要
- 二、引言
- 三、方法
-
- 3.1 主要框架
- 3.2 训练一个大的batchsize
- 四、数据增强
-
- 4.1 实验一 数据增强的组合对学习好的特征表达非常重要
- 4.2 对比学习需要更多的数据增强
- 五、一些实验证明
-
- 5.1 大模型更有利于无监督对比学习
- 5.2 非线性层的预测头增加了特征表示
- 5.3可调节的归一化交叉熵损失函数由于其他方法
- 5.4 对比学习更受益于大的batchsize和更长的训练时间
- 六、结论
- 七、其他
paper地址:https://arxiv.org/abs/2002.05709
github地址:https://github.com/google-research/simclr
一、摘要
这篇文章提出了一个对比学习的简单的框架,用来学习视觉的表征。主要贡献如下:
- 提出了一个简化的视觉表征对比学习框架,不再需要特殊的架构或者memory bank;
- 展示了数据增强组合的重要性,特别是再想定义一个有效的预测任务时,数据增强起着关键作用;
- 引入了一个可学习的非线性变换,并嵌入在特征表示和损失之间,可以明显提高表征 学习的质量
- 表示了,对比学习相比于监督学习,对比学习受益于更大的batchsize和train step
这篇文章提出时,在ImageNet上,由SimCLR学习的自监督表示训练的线性分类器达到76.5%的精度,和ResNet50相当,超过了之前提出的一些自监督学习算法约7%。 在仅有1%的数据集上微调时,也获得了85.8%的top-5准确率,比AlexNet少了100倍的标签,却得到了可媲美的精度。

二、引言
自监督视觉表征学习方法主流有两种,生成式和判别式:
- 生成式方法在输入空间中学习如何生成或者建模像素,但是pixel-level的生成器计算量大,且对表征学习来说可能是不必要的;
- 判别式方法然后用类似监督学习的目标函数来学习表征,训练时的输入和标签都来自未标注的数据。但是很多方法都依赖于定义一个pretext的启发式训练任务,可能限制表征学习的通用性
然后本文继续介绍了提出的方法SimCLR,不仅精度超过之前的方法,而且简单,不需要特殊的空间结构和memory bank. 然后系统的研究了本文的主要贡献:
- 数据增强的组合是非常重要的,产生了高效的表征,数据表明了,对比学习相对监督学习更受益于数据增强;
- 介绍了一个可学习的非线性变换,这个非线性变换在表征和对比损失之间加了一层MLP,极大的增加了表征学习的质量;
- 对比交叉熵损失的表征学习受益于归一化的embedding和一个可适当调整的温度参数;
- 对比学习更受益于大的batchsize和更长的训练时间。与监督学习类似,对比学习也受益于深又宽的网络。
此外,除了在ImageNet上取得比较好的效果外,还评估了其他的数据集,在12个数据集中,有10个都超过了监督学习的base。
三、方法
3.1 主要框架
SimCLR学习表征,经过一个潜在空间的对比损失,这个对比损失是最大化同一数据中不同增强视图之间的一致性来实现的。
本文的框架如下:同一数据增强族中随机采用两个独立的数据增强算子,并应用于每个数据示例中以获得两个相关的视图。并训练一个基础的encoder网络和一个projection 头,使用对比损失来最大化一致性。
训练结束后,丢弃projection头,使用encoder部分的表征来服务于下游任务
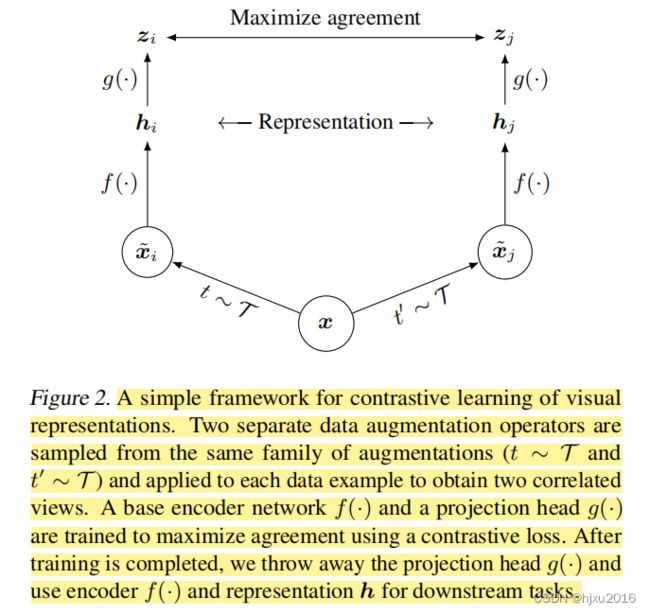
框架流程如下:

由于一个batch内有很多图像对,除了自己本身外,其他图像对都看成负样本。
比如图像1和图像1之间,为正样本。 图1和其他图则为负样本对,负样本对也参与损失的计算。
- 对一张图做两次随机数据数据增强,彩色两张图片。本文采用随机裁剪、随机颜色变换、随机高斯;
- 将这个数据增强后的图像送到网络 f ( ⋅ ) f(·) f(⋅) 中, 产生两个特征向量 h h h;
- h h h 再经过一个投影操作 g ( ⋅ ) g(·) g(⋅),其实就是一个MLP全连接操作,生成 z z z
- 两个 z z z,通过对比损失函数,计算相似度
- 最终应用于下游任务的,表征采用的是 h h h,特征提取器是 f ( ⋅ ) f(·) f(⋅)。 投影操作 g ( ⋅ ) g(·) g(⋅)则被丢弃了。
本文还定义了一个归一化后的交叉熵损失函数,如下:
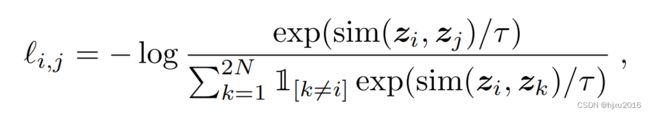
其中 s i m ( z i , z j ) sim(z_i, z_j ) sim(zi,zj)就是余弦相似度。值得注意的是,A图和B等其他图组成一对,B也需要和A等其他图组成一对,所以最终的损失,是奇数对于偶数对之前相加,再求平均。
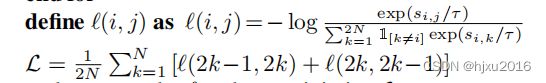
关于这里的损失函数,如何完成同类相吸,异类互斥,知乎一篇文档有详细的讲解。
https://zhuanlan.zhihu.com/p/258958247
3.2 训练一个大的batchsize
本文将Batchsize从256尝试到8192,每个正样本对应双倍的增强,比如batchsize=8192时,就有16282个负样本。
当使用具有线性学习率尺度时SGD/Momentum,大的batchsize可能不稳定,因此,本文使用LARS优化器
值得注意,本文采用GlobalBN 来解决普通BN之间信息泄漏的问题,有些方法是采用shuffle-BN(每个节点的均值方差互换)或者layer norm。
- 标准的ResNet使用batch normalization,在分布式训练中,BN的均值和方差都是在当前的device上计算,回导致信息泄漏。特别在本文,所有的正样本对都在同一个device上计划,模型很可能会利用局部信息的泄漏来提高预测准确率,但是却不增加表征。
本文采用globanBN,在所有的设备上,聚合方差和均值,其他方法比如在交叉设备上shuffling data ,或者用layer norm替代BN
四、数据增强
这篇文章以前,尽管数据增强已经被广泛应用,但都没有系统性应用数据增强到对比学习中。
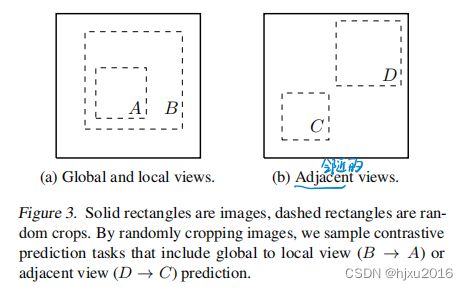
以前的通常都是改变网络结构,比如:
- 通过压缩网络的感受野来实现全局到局部的预测
- 通过固定图像切割过程和上下文聚合网络实现相邻视图的预测
这些过程,可以通过随机裁剪来实现,如下图
4.1 实验一 数据增强的组合对学习好的特征表达非常重要

实验一、数据增强的组合对学习好的特征表达非常重要,数据论证了:
1、没有一个单一的论证可以学到好的特征表示;
2、随机crop和随机颜色变换组合是最佳的
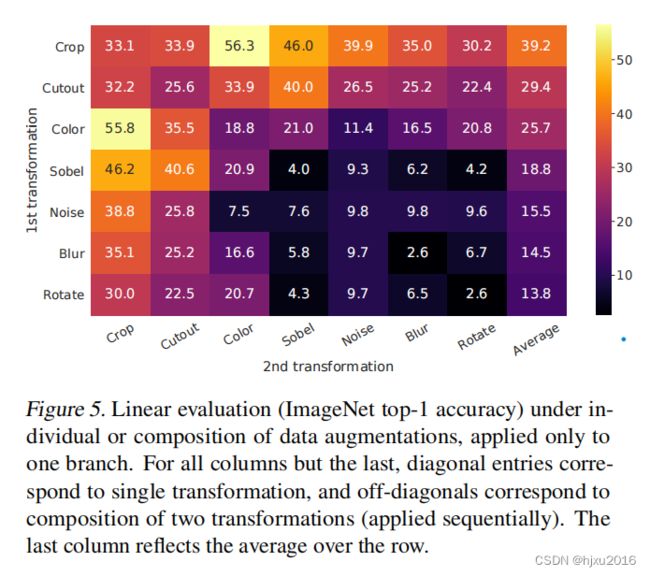
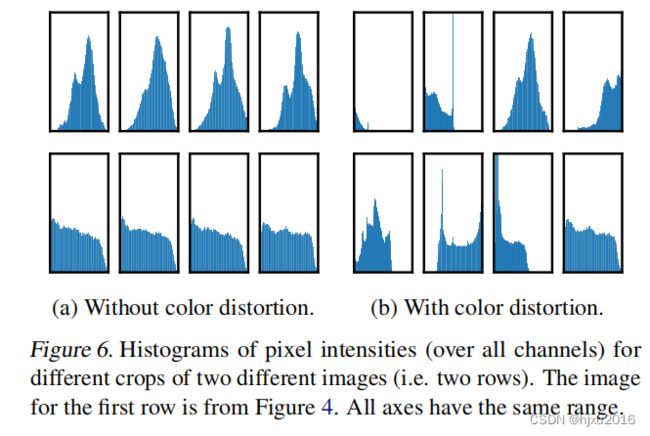
颜色失真也很重要,不然的化,仅仅靠直方图就能判断两个图像是不是同一个图crop的
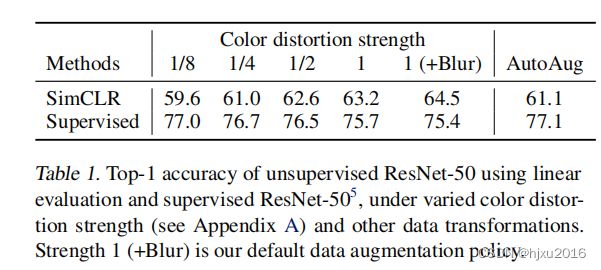
4.2 对比学习需要更多的数据增强
表1表示了,对比学习需要更多的数据增强,且本文还对比了监督学习算法中的一种自动数据增强,发现在对比学习中,效果也不是很好。
五、一些实验证明
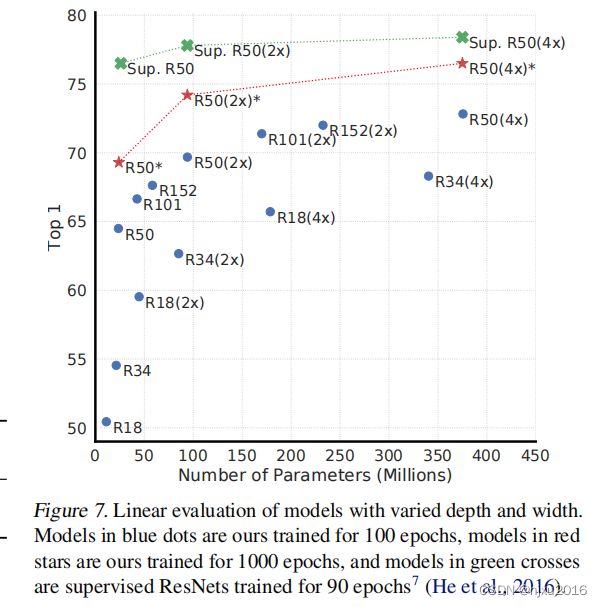
5.1 大模型更有利于无监督对比学习
图7表示了,无监督学习更受益于大模型。
5.2 非线性层的预测头增加了特征表示
图8表示,加了非线性层的预测头后,特征表示更好了。
这里有个有趣的现象,也就是非线性层预测头的维度,对特征表示没有多大影响。
文中如此解释: z = g ( h ) z=g(h) z=g(h) 被训练为对数据的变换是不变的(同一图,做不同的数据增强,都是求相似度),因此失去了对下游任务支持的信息。

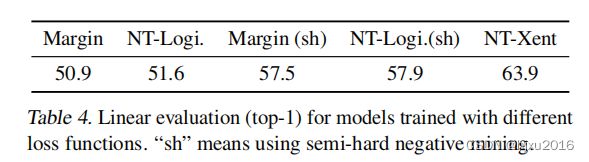
5.3可调节的归一化交叉熵损失函数由于其他方法
这里也做了一系列的对比实验
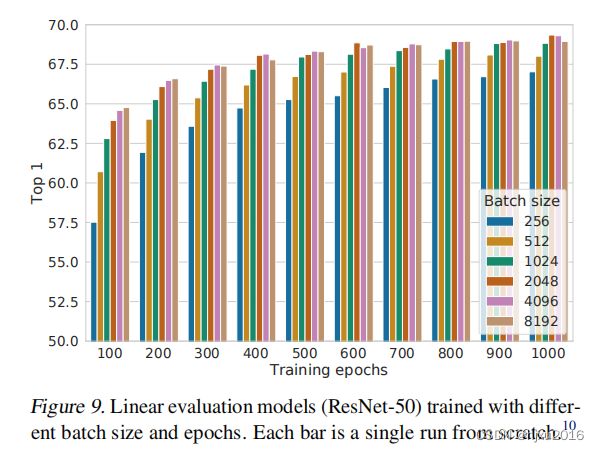
5.4 对比学习更受益于大的batchsize和更长的训练时间
图9也实验证明了这点,文中表示,大的batchsize提供了更多的负样本,有利于收敛。
but, 动不动就4096的batchsize, 小实验一般玩不起啊!
六、结论
本文提出了一个简单的框架及其实例化的对比视觉表示学习。并仔细研究了其组成部分,展示了不同设计选择的影响。通过结合,大大改进了以前的自我监督、半监督和迁移学习的方法。
然后是,本文方法与ImageNet上的标准监督学习仅在3个方面不同:数据增强的选择、在网络末端使用非线性头部和损失函数方面。
这个简单框架的优势表明,尽管最近人们的兴趣激增,但自监督学习仍然被低估了。
七、其他
还有更多的实验在附录中,如在验证集中随机选择了10个类别,应用t-SNE降维后,视觉表征层相比投影层的特征界限,更加明显。
