jupyter notebook 电影数据分析
一、数据探索
导入需要用到的库
import numpy as np
import pandas as pd
1.1 读取user文件
- 关于用户的人口统计信息
- 使用 | 分隔列表
- 用户编号 | 年龄 | 性别 | 职业 | 邮政编码
- 用户编号被data 数据集引用
df_user = pd.read_csv("./data/user", delimiter="|", header=None, names=["用户编号", "年龄", "性别", "职业", "邮政编码"])
df_user.head()结果展示:

1.2 查看文件信息
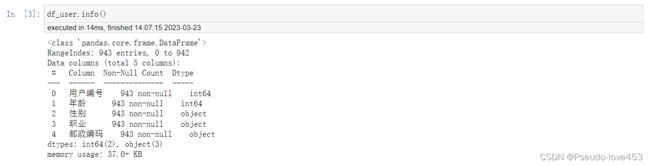
df_user.info()结果展示:
2.1 读取data文件
- 完整的 u 数据集,943 个用户对 1682 个项目的 100000 个评分。每个用户至少评价了 20 部电影。用户和项目是从1开始连续编号
- 使用制表符(\t)分隔列表
- 字段信息:用户编号 | 商品编号 | 评价 | 时间戳 (时间戳是自 1/1/1970 UTC 以来的 unix 秒数)
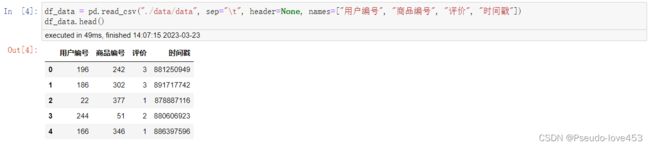
df_data = pd.read_csv("./data/data", sep="\t", header=None, names=["用户编号", "商品编号", "评价", "时间戳"])
df_data.head()结果展示:
2.2 查看文件信息
df_data.info()结果展示:

3.3 读取item文件
- 物品信息(电影)
- 使用 | 分隔列表
- 字段名:电影编号 | 电影名称 | 发布日期 | 视频发布日期 | IMDb 网址 | 未知 | 行动 | 冒险 | 动画 | 儿童 | 喜剧 | 犯罪 | 纪录片 | 戏剧 | 奇幻 | 黑色电影 | 恐怖 | 音乐剧 | 谜| 浪漫 | 科幻 | 惊悚 | 战争 | 西方 |
- 最后 19 个字段是流派,1 表示电影属于那种类型,0 表示不是;电影可以在几个流派一次
- 电影编号 是 data 数据集中使用的商品编号
col_names = '电影编号 | 电影名称 | 发布日期 | 视频发布日期 | IMDb 网址 | 未知 | 行动 | 冒险 | 动画 | 儿童 | 喜剧 | 犯罪 | 纪录片 | 戏剧 | 奇幻 | 黑色电影 | 恐怖 | 音乐剧 | 谜| 浪漫 | 科幻 | 惊悚 | 战争 | 西方 '.split('|')
col_names = [col.strip() for col in col_names] # 去掉空格
df_item = pd.read_csv("./data/item", sep="|", header=None, names=col_names, encoding="ISO-8859-1")
df_item.head()结果展示:

3.2 查看文件信息
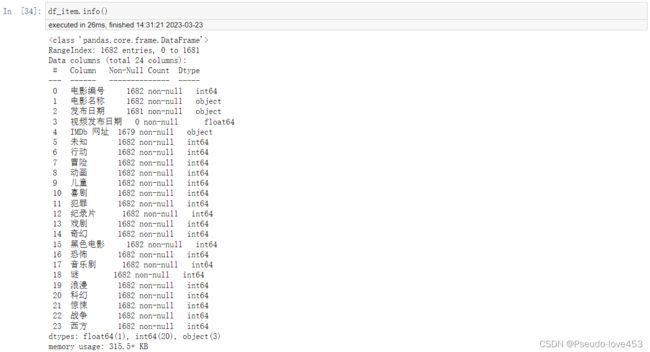
df_item.info()结果展示:
二、问题
1.查询每个用户的平均打分
df_score_mean = df_data.groupby("用户编号")["评价"].mean()
df_score_mean.apply(lambda x:round(x,1))结果展示:

3.查看不同职业、性别的平均打分
df_user_data = df_user.merge(df_data) # 先将user和data表连接起来
df_all = df_user_data.merge(df_item, left_on="商品编号", right_on="电影编号") # 再将user_data和item表通过两个字段连接起来
df_all.head() # 展示得到的新表df_all结果展示:

df_all[["性别", "职业", "评价"]].groupby(by=["性别", "职业"]).mean().apply(lambda x: round(x, 1)).head()由于数据太多只显示几行
结果展示:

4.查询电影平均分排名
df1 = df_all[["商品编号","电影名称","评价"]]
df1.groupby("商品编号").mean().sort_values("评价",ascending=False).head(10)结果展示:

5.查询大于平均分的电影的数量
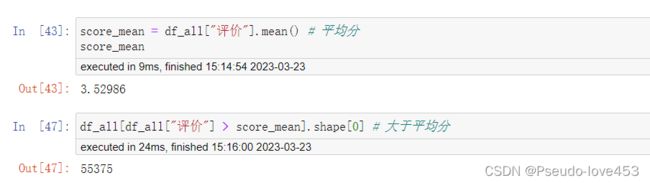
score_mean = df_all["评价"].mean() # 平均分
score_meandf_all[df_all["评价"] > score_mean].shape[0] # 大于平均分结果展示:
6.查询高分电影中(>3)打分次数最多的用户,并求出此人打的平均分
df_count = df_all[df_all["评价"] > 3].groupby("用户编号").count()
df_count # 先统计出评价大于3的用户次数结果展示:

uid = df_count.sort_values("年龄",ascending=False).index[0]
uid # 取出这个用户的id
df_all[df_all["用户编号"] == uid]["评价"].mean() # 该用户的平均评价结果展示:

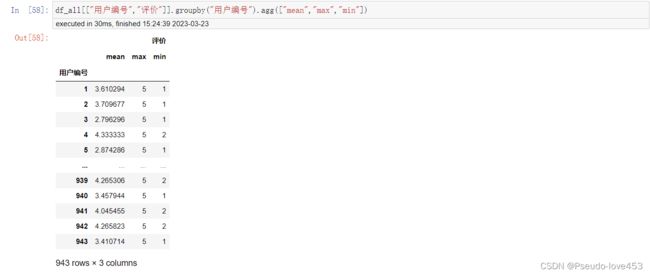
7.查询每个用户的平均打分,最低打分,最高打分
df_all[["用户编号","评价"]].groupby("用户编号").agg(["mean","max","min"])结果展示:
8.查询被评分超过100次的电影的平均分排名 TOP10
df_grp = df_all[["商品编号","评价"]].groupby("商品编号")
df_grp # 提取出字段df_gt_100 = df_grp.count() > 100 # 评价总数大于100的
df_gt_100 = df_gt_100.reset_index() # 获取评价总数大于100的索引
df_gt_100.head() # 展示前几行结果展示:

df_result = df_gt_100.merge(df_data,left_on="商品编号",right_on="商品编号")
df_result # df_gt_100和df_data连接起来结果展示:

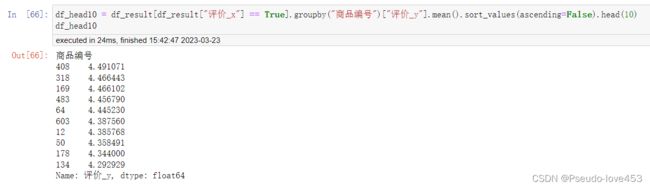
df_head10 = df_result[df_result["评价_x"] == True].groupby("商品编号")["评价_y"].mean().sort_values(ascending=False).head(10)
df_head10结果展示: