【网关建设】03-APISIX实战之插件使用
前言
我们在设计公共服务网关的功能时,共验证并对业务系统开放了如下插件:
1、 prometheus 插件
2、 log-rotate 插件
3、 ip-restriction、real-ip、response-rewrite 插件
4、 api-breaker 插件
5、 limit-req、limit-conn插件
6、 server-info 插件
这些插件中,有些是直接开箱即用,没有做单独的讨论和设计,基本都符合业务的基本需求。
这些插件我会分别在 【开箱即用】 和 【稍加改造】的章节中集中说明。
关于更多APISIX的基本背景以及参考资料,详情请参考 :【网关建设】01-APISIX实战之概要设计
插件使用 - 开箱即用
prometheus 插件
该插件负责APISIX与Prometheus集成的插件。
开启后,apisix的配置文件中配置好prometheus的服务后。
prometheus就可以获取到apisix的各项指标:比如路由的QPS、带宽、HTTP状态、上下游的延迟等等。除此之外。
这次设计我们还结合业务,实现了诸如访问次数、异常率、平均响应时间等到监控能力。
关于监控告警的功能设计、配置文件、告警公式等需求,详见 【监控告警】01-网关的需求与改造
log-rotate 插件
自带的日志分割插件。
一开始在手册中没有注意到,自己写的Nginx日志分割脚本。
但是官方自带的经过验证会更好用一些。
server-info 插件
该插件在分布式环境下,可以在Dashboard中查看节点机器的信息
limit-req、limit-conn 插件
该插件负责路由服务的限流操作:
关于limit-req 插件 与 limit-conn 插件 ,我们讨论了:APISIX是否能在支持 服务级别的限流 的前提下,支持 IP级别的限流 ?
这是其实是在原有的 服务级别限流 的基础上,又更加细分的一个维度。
因为在实际的业务场景中,面对同样的一个服务,可能会有多个机构来使用。当服务触发限流后,正常情况下,这个路由下所有服务的访问都是被拒绝的。
但是,业务场景中并不想因为某些机构的原因,导致整个服务的限流不可用。所以在服务级别限流的基础上,提出了IP级别限流的需求。 在服务熔断时,进一步区分IP,对触发限流的某一个机构进行访问限制。
类似于电商里面的对于单个刷单IP进行限流的操作。
当然对于同一个上游服务,也可以通过配置多路由的方法,来对解决上面说到的问题。 但这样一来,一旦有新的机构介入业务平台,网关的配置也要随之增加。所以这个方案在我们的讨论中,并没有被采用。
而只依靠现有的 limit-req 插件 + ip-restriction 插件 的简单组合,是无法实现这个需求的,除非开发自己的自定义插件,但目前来讲我们还没有这个改造计划。
api-breaker 插件
该插件负责路由服务的熔断操作:
关于api-breaker 插件 ,我们在实际与业务部门的交流中,遇到了下面的这些情况:
有些情况下,业务部门的开发者,在思考 服务熔断 问题的时候,容易将Sentinel的那一套理论体系,亦或叫解决方案,套用到他们的项目中。然后以此为标准来要求APISIX提供相类似的支持。
然而一旦APISIX套用了这套理论体系就会发现,APISIX:
1.没有多种熔断策略
2.也不具备降级策略
3.没有不同维度隔离机制
4.也没有滑动窗口概念
5.无法与prometheus进行密切联动,就没办法将服务熔断的情况进行详细直观的展示
如果非要以Sentinel的标准来要求APISIX,那APISIX就显得十分的一无是处了。
此时我们需要回归到服务熔断的本质上来:为什么我们在微服务中,需要熔断降级这个功能?其实就是为了实现对客户端与上游服务进行保护的目的。
1.从客户端角度来看,防止客户端频繁的访问导致频繁报错,影响用户体验。
2.从上游服务角度来看,防止上游服务段时间内无法处理错误导致服务崩溃,给予上游服务充分的自我修复的反应和排查的时间。
那么我们结合官方手册的说明来重新审视APISIX提供的解决方案:这无不是一种在轻量化的、单一职责化的,与业务系统解耦需求下的,最优选择。
官方手册说明如下:
由代码逻辑自动按触发不健康状态的次数递增运算:
每当上游服务返回 unhealthy.http_statuses 配置中的状态码(比如:500),达到 unhealthy.failures 次时(比如:3 次),认为上游服务处于不健康状态。
第一次触发不健康状态,熔断 2 秒。
然后,2 秒过后重新开始转发请求到上游服务,如果继续返回 unhealthy.http_statuses 状态码,记数再次达到 unhealthy.failures 次时,熔断 4 秒(倍数方式)。
依次类推,2, 4, 8, 16, 32, 64, ..., 256, 最大到 300。 300 是 max_breaker_sec 的最大值,允许自定义修改。
在不健康状态时,当转发请求到上游服务并返回 healthy.http_statuses 配置中的状态码(比如:200),达到 healthy.successes 次时(比如:3 次),认为上游服务恢复健康状态。
当上游服务异常的时候,APISIX可以接收到异常返回的错误码,并为客户端返回一个指定的错误码,
客户端在获取到指定错误码后,就可以去定制化自己的异常或降级逻辑。
而上游服务是通过max_breaker_sec 与 unhealthy.failures 参数,来控制对上游服务的访问频率,以达到保护上游服务的目的。
插件使用 - 稍加改造
ip-restriction、real-ip、response-rewrite 插件
该插件集负责解决黑白名单路由,我们在实际的使用当中,遇到了如下几个问题:
问题描述:
解决通过Nginx 向 ip-restriction 插件 传递真实IP的问题
背景描述:
一开始我们是单纯的利用 ip-restriction 插件 ,对客户端服务的访问进行限制
后来发现,由于客户端与网关之间,还设计了一层Nginx,如下图所示:
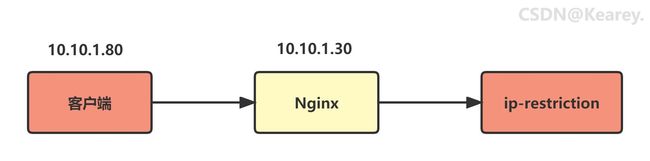
客户端-Nginx-apisix
如果不做任何配置,那么 ip-restriction 插件 获取到的IP地址,最后会变成Nginx的10.10.1.30
这显然跟我们的预期不相符。
解决办法:
就是利用 real-ip 插件 和 Nginx 配置,让客户端的IP地址传递到 ip-restriction 插件
real-ip具体配置如下:
"plugins": {
"`ip-restriction 插件`": {
"message": "welcome !!!",
"whitelist": [
"192.168.2.100",
"192.168.8.120"
]
},
"real-ip": {
"disable": false,
"source": "http_x_forwarded_for"
},
"response-rewrite": {
"headers": {
"remote_addr": "$remote_addr",
"remote_port": "$remote_port"
}
}
}其中 real-ip :source 中的 "http_x_forwarded_for",需要与Nginx进行同步配置,内容如下:
location /apisix/ip{
proxy_pass http://apisix;
proxy_set_header X-Forwarded-For $remote_addr;
}配置完成后,利用 response-rewrite 插件,我们通过apisix访问服务的时候,就可以打印真实IP信息
curl 'http://127.0.0.1:9080/index.html?realip=1.2.3.4:9080' -I
...
remote-addr: 10.10.1.80
remote-port: 9080以上,问题得以解决。
请求路径改写
问题描述:
解决apisix 接收 Nginx的统一改写路径后,利用正则表达式对路径进行提取并转发至上游的问题。
背景描述:
业务部门的某个项目的技术栈比较古早,并非是前后端分离的,且没有用到SpringMVC。
由于后台请求路径与静态资源路径无法梳理和统一,所以借助了Nginx,将客户端请求统一转发至APISIX。这中间利用Nginx在所有客户端请求前面增加了统一的前缀,例如:/qianzhui/***
此时问题就来了:
APISIX接收到的是由Nginx改写过的路径 /qianzhui/***
然而实际的上游服务的路径为 /***
解决方法:
利用APISIX的路径匹配改写功能
匹配公式 ^/qianzhui/(.*) 表示:
将 /qianzhui/ 之后的部分,作为第一个匹配到的值,变量名为 $1
转发路径模板 /$1 即取上一个匹配后的参数拼接转发

域名匹配
问题:
解决APISIX匹配路径相通的情况
背景:
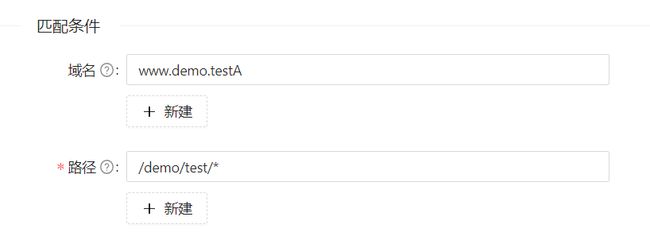
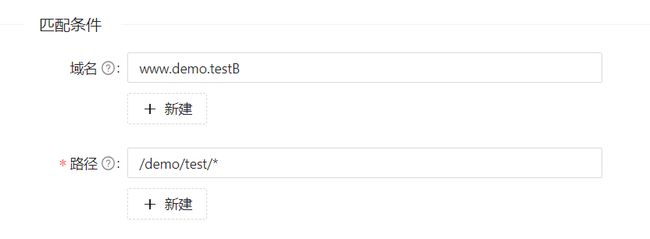
业务部门的某个项目,由于设计原因,两个上游服务公用了同样的路由匹配路径/demo/test/*
并且经过沟通,由于是老项目,也无法在短时间内进行修改。
解决方法:
理论上,可以通过Nginx改写请求路径来对这两个上游服务,进行区分。
但是更简单的方法是利用apisix的多条件匹配的能力,使用业务部门提供的两个上游服务的域名,通过 请求路径 + 域名 的方式,进行区分。
如下图所示: