数据挖掘项目——新零售无人智能售货机商务数据分析
数据挖掘项目——新零售无人智能售货机商务数据分析
-
- 前言
- 一、 原始数据分析
- 二、数据清洗
-
- 1、处理附件1
- 2、处理附件2
- 三、数据分析
-
- 1、描述性分析
- 2、数据可视化
- 结果如下:
前言
本文所使用的代码和数据集请关注公众号: CV市场, 后台回复“零售机项目”获取,感谢支持。
一、 原始数据分析
原数据中包含两个附件annex_1和annex_2。
其中annex_1中有数据:订单号、设备ID、应付金额、实际金额、商品、支付时间、地点、状态、提现。具体如下:
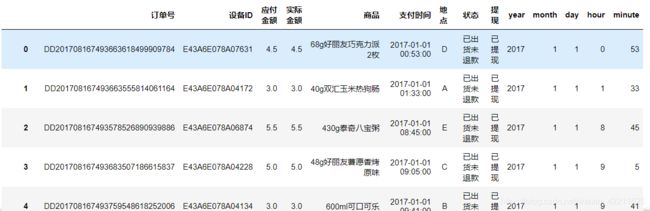
#原始数据
detail = pd.read_csv('annex_1.csv',parse_dates=[0],encoding='gbk')
detail.head()

annex_2是对附件1(annex_1)中出售商品的具体分类:
goods = pd.read_csv('annex_2.csv',encoding='gbk')
goods.head()

二、数据清洗
1、处理附件1
查看附件1的数据信息:
detail.info()
#查看是否有缺失值
(detail.isnull()).sum()

可以看到附件1没有空值,那么再继续仔细分析每个数据,这里使用pandas.to_datetime处理“支付时
间”列,由于"创建时间"列包含AM和PM这样的字段,所以使用如下处理:
import pandas as pd
from dateutil.parser import parse
import datetime as dt
detail['支付时间']=detail['支付时间'].apply(lambda x:parse(x))
print(detail['支付时间'])
但是报错了:
![]()
意思是日期超过了当前月份的天数,那么具体些代码分析:
#解析出每条数据的年、月、日
detail['year'] = detail['支付时间'].apply(lambda x : int(str(x).split('/')[0]))
detail['month'] = detail['支付时间'].apply(lambda x : int(str(x).split('/')[1]))
detail['day'] = detail['支付时间'].apply(lambda x : int(str(x).split('/')[-1].split(' ')[0]))
detail['year'].unique()
可以看到附件1中只包含2017年的数据
![]()
依次检验每个月的天数是否正确:
for i,j in enumerate([31,28,31,30,31,30,31,31,30,31,30,31]):
if len(detail.loc[(detail['month'] == (i+1))& (detail['day'] > j)]) != 0:
print(detail.loc[(detail['month'] == (i+1))& (detail['day'] > j)].index.values)
![]()
可以看到显示的是行索引为70679的数据,那么打印下该条数据:
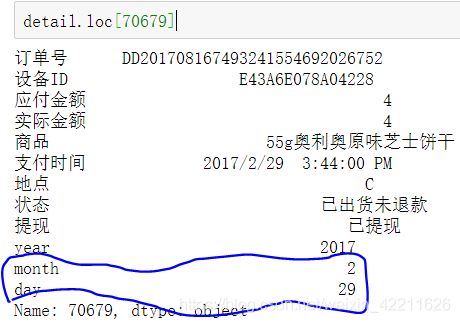
很明显,2017年的2月是没有第29天的,所以drop掉:
detail.drop(index = 70679,axis = 0,inplace = True)
这回再根据时间提取年、月、日、时、分、秒:
from dateutil.parser import parse
detail['支付时间']=detail['支付时间'].apply(lambda x:parse(x))
detail['year'] = detail['支付时间'].dt.year
detail['month'] = detail['支付时间'].dt.month
detail['day'] = detail['支付时间'].dt.day
detail['hour'] = detail['支付时间'].dt.hour
detail['minute'] = detail['支付时间'].dt.minute
再次检查是否有空值:

查看有没有重复行:
from collections import Counter
#判断是否有重复行
print(Counter(detail.duplicated()))
![]()
没有空值,没有重复行。
下面再深入观察“商品”列数据:
detail['商品'].unique()
发现里面有很多类似于“商品”
+数字的格式,这样的数据是没有意义的,应该drop掉

detail['商品'] = detail['商品'].astype(str)
detail=detail[~detail['商品'].str.contains('商品')]
现在数据清洗算是做完了,将清洗后的数据存入到文件中:
detail.to_csv('cleared_annex_1.csv',index = False)
goods.to_csv('cleared_annex_2.csv',index = False)
2、处理附件2
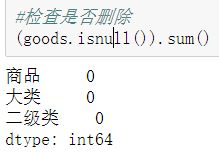
没空值,暂时不需要处理。
三、数据分析
先读取上面做好数据清洗的csv文件:
cleared_annex_1 = pd.read_csv('cleared_annex_1.csv')
cleared_annex_2 = pd.read_csv('cleared_annex_2.csv')
commodity_sale = pd.read_csv('./result/commodity_sale.csv',encoding='gbk')
这里多读了一个文件,用来描述每件商品的订单量和交易额:
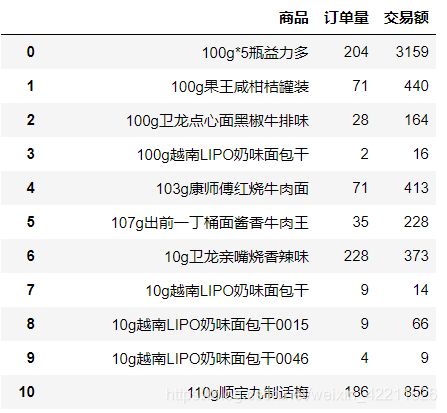
1、描述性分析
#描述性分析
cleared_annex_1.describe()

cleared_annex_2.describe()

commodity_sale.describe()

查看实际支付的分布散点图:
cleared_annex_1['实际金额'].plot(style='k.',figsize=(30,15),c = 'r')
plt.tick_params(labelsize=30)
plt.grid()

可以看到上面有些离群点,但此时并不能说明是异常值,要根据商品名字再做判断:
cleared_annex_1[cleared_annex_1['实际金额'] > 80][['商品','实际金额','应付金额']]

我去某东查了一下价格,好像也差不多,所以这里就不算是异常数据了。
2、数据可视化
(1)查看每个‘实际金额’的频率
#直方图
cleared_annex_1['实际金额'].plot(kind='hist',bins=50)
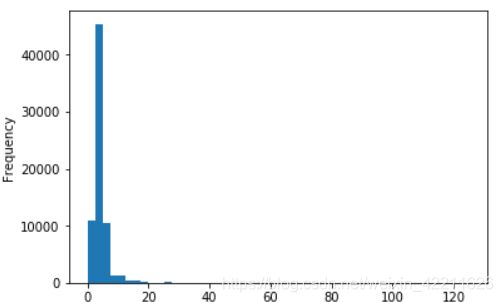
#概率密度图
cleared_annex_1['实际金额'].plot(kind='kde')

可以看到在价格在0~20之间出现的频率最高。
(2)订单量的统计图
#订单量概率密度图
commodity_sale["订单量"].plot(kind='kde')
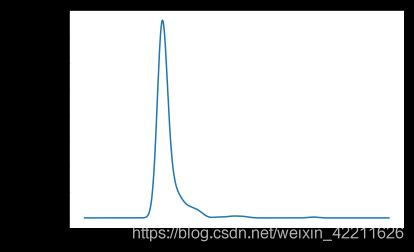
#交易额概率概率图
data["交易额"].plot(kind='kde')

3、实际交易金额数量直方图
bins = [0,2,3,4,8,10,12,24,48,130]
pd.cut(cleared_annex_1['实际金额'],bins).value_counts().plot.bar(rot=30,color='green',title='实际支付分析')

4、销售量最多的前5个商品
cleared_annex_1['商品'].value_counts()[:5].plot.barh(color='brown',title='商品排名')

5、每个地点所有商品价格的平均值
cleared_annex_1.groupby(['地点'])['实际金额'].mean().plot.barh(color='g',title='每个地点所有商品价格的平均值')

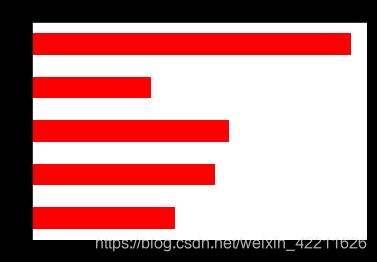
6、每个地点销售商品的数量
cleared_annex_1.groupby(['地点'])['订单号'].count().plot.barh(color='r',title='每个地点销售商品的数量')
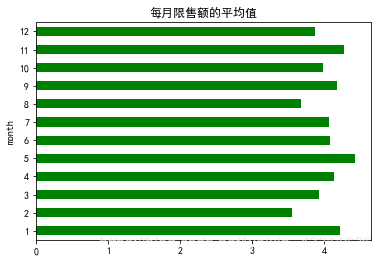
7、每月限售额的平均值
cleared_annex_1.groupby(['month'])['实际金额'].mean().plot.barh(color='g',title='每月限售额的平均值')
8、每月的销售量
cleared_annex_1.groupby(['month'])['订单号'].count().plot.barh(color='g',title='每月的销售量')

9、每个地点每月的销售总额
cleared_annex_1.groupby(['地点','month'])['实际金额'].sum().plot.barh(color='g',title='每个地点每月的销售总额',figsize=(10,20))

10、每个地点每个商品的销售量
cleared_annex_1.groupby(['地点','商品'])['商品'].count()
结果如下:
地点 商品
A 100g*5瓶益力多 40
100g卫龙点心面黑椒牛排味 6
100g果王咸柑桔罐装 20
100g越南LIPO奶味面包干 1
103g康师傅红烧牛肉面 15
107g出前一丁桶面酱香牛肉王 12
10g卫龙亲嘴烧香辣味 25
10g越南LIPO奶味面包干 5
10g越南LIPO奶味面包干0015 4
10g越南LIPO奶味面包干0046 2
110g顺宝九制话梅 41
117gUFO炒面铁板色拉鱿鱼风味 5
120g达利园蔓越莓提子面包 1
123gUFO炒面XO酱海鲜风味 2
12g劲仔小鱼卤香味 20
12g劲仔小鱼麻辣味 103
130g果王玉带蚕豆 5
13g无穷烤鸡小腿蜂蜜味 201
13g雀巢咖啡1+2特浓 4
145g果王迷你山楂包装 4
145ml旺仔牛奶盒装 131
145ml旺仔牛奶罐装 2
148g富甲一方紫薯仔 39
14g德芙巧克力 2
150g健能酸奶原味 28
150g洽洽原香瓜子 11
150抽诗竹竹纤维面巾纸 9
160g盼盼手撕面包 28
180g统一满汉全席台式半筋半肉牛肉面 6
180ml雀巢咖啡罐装 22
…
E 维他柠檬茶 169
维他柠檬茶330ml(罐) 2
美年达(罐) 133
美汁源果粒橙 27
脉动 996
脉动(椰子菠萝口味) 9
脉动(青柠) 44
芙蓉王 6
芦荟汁 44
芬达330ml 382
茉莉蜜茶 83
营养快线 805
诗竹竹纤维面巾纸 21
越南LIPO奶味面包干100g 11
迷你纸巾 13
银鹭八宝粥 220
阿萨姆奶茶 792
阿萨姆煎茶奶绿 11
雀巢咖啡 97
雪力矿泉水 35
雪碧 38
雪碧330ml 173
雪碧最新款 309
雪碧(500ml) 172
韩国海牌海苔 49
顺宝九制梅 15
香脆肠 76
香豆干 251
鸡爪 6
鸭翅 282
Name: 商品, Length: 1303, dtype: int64
---------------------------------------------------------------------------------
11、Top5商品占总商品比例
top5 = ["怡宝纯净水","脉动","东鹏特饮","阿萨姆奶茶","营养快线"]
cleared_annex_1_top5 = cleared_annex_1[cleared_annex_1['商品'].isin(top5)]
print('Top5商品占总商品比例:%.2f%%'%(cleared_annex_1_top5.shape[0]/cleared_annex_1.shape[0]*100))
![]()
12、Top5商品中每个商品的数量
cleared_annex_1_top5['商品'].value_counts().plot.barh(color='g',title='Top5商品中每个商品的数量')

占比:
plt.axes(aspect='equal') #将横轴,纵轴坐标标准化处理,保证饼图是一个正圆,否则为椭圆
plt.pie(cleared_annex_1_top5['商品'].value_counts(),explode=[0.05,0.05,0,0,0],startangle=0,labels=top5,autopct='%.2f%%',radius=1)

13、以6、7、8月的销售量为例,画出热力图
#原始数据
data = pd.read_csv('./result/6th_8th_month_order/6th_month_order.csv',encoding='gbk')
data.head()

画出6月的热力图:
data = data.pivot_table(index='hour',columns='day',values="number", aggfunc=np.mean)
sns.heatmap(data,linewidths=0.001,vmin=0,vmax=2)
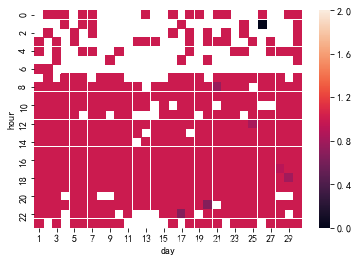
同样的方式,分别画出7月和8月的热力图:

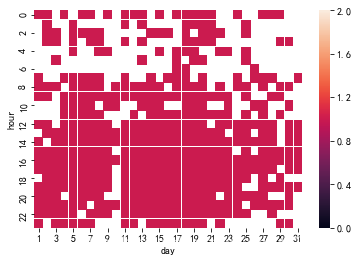
从以上面三个图,可以看到6,7,8三个月份每一天的订单量随时间的变化。6月全月的订单量基本集中在8时至21时这段时间内;7月订单量有两段较为集中的时段,一段是7月1日至7月5日的8时至20时,另一段是7月22日至7月31日的9时至22时;8月订单量基本集中在8月1日至8月23日的9时至22时。因此,可以基本推测消费者在这三个月中的消费时间在8时至22时。运营者需要定期检查,保证在这段时间前将受欢迎的商品补充到售货机中。
本文所使用的代码和数据集请关注公众号: CV市场, 后台回复“零售机项目”获取,感谢支持。