【AAAI2023】Head-Free Lightweight Semantic Segmentation with Linear Transformer
Head-Free Lightweight Semantic Segmentation with Linear Transformer, AAAI2023
解读:阿里团队新作 | AFFormer:利用图像频率信息构建轻量化Transformer语义分割架构 (qq.com)
论文:https://arxiv.org/abs/2301.04648
代码:GitHub - dongbo811/AFFormer
导读
本文提出了一种名为Adaptive Frequency Transformer(AFFormer)的语义分割架构。AFFormer采用并行架构来利用原型表示(prototype representations)作为特定可学习的局部描述,其取代了解码器并在高分辨率特征上保留丰富的图像语义。 虽然删除了解码器能够压缩大部分的推理计算,但并行架构的精度仍受到低计算资源的限制。因此,采用异构运算符(CNN和Vision Transformer)进行像素嵌入(pixel embedding)和原型表示,以进一步节省计算成本。此外,从空间域的角度线性化Vision Transformer的复杂度非常困难。由于语义分割对频率信息非常敏感,论文构建了一个轻量级原型学习块,其具有复杂度O(n)的自适应频率滤波器,以替换标准自注意力的O(n^2)复杂度。
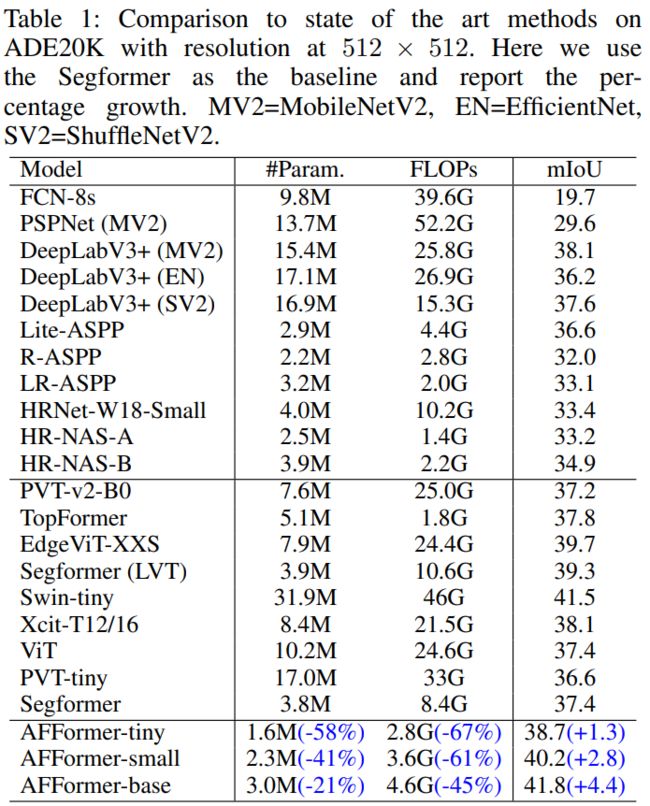
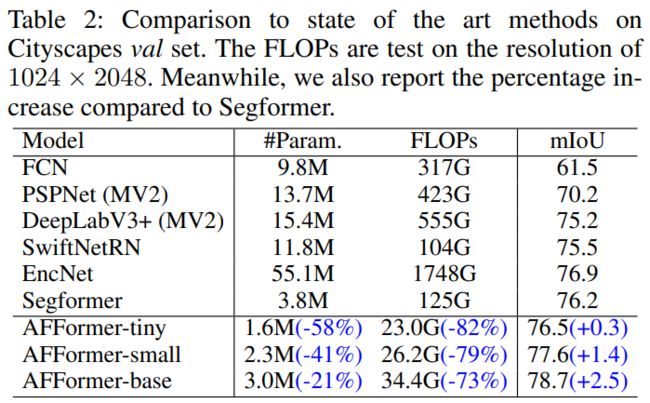
在广泛使用的数据集上进行的大量实验表明,AFFormer在保持3M参数的同时实现了优异的精度。在ADE20K数据集上,AFFormer达到41.8 mIoU和4.6 GFLOPs,比Segformer高4.4 mIoU,GFLOPs减少45%。在Cityscapes数据集上,AFFormer达到78.7 mIoU和34.4 GFLOPs,比Segformer高2.5 mIoU,GFLOPs减少72.5%。
引言
 AFFormer achieves better accuracy on ADE20K and Cityscapes datasets with significantly lower FLOPs
AFFormer achieves better accuracy on ADE20K and Cityscapes datasets with significantly lower FLOPs
语义分割是将图像划分为子区域(像素集合)的任务,有两个独特的特点:像素级稠密预测和多类表示,需要图像语义的全局归纳能力。以前的语义分割方法主要关注使用分类网络作为骨干来提取多尺度特征,并设计复杂的解码器头来建立多尺度特征之间的关系。然而,需要以巨大参数量和高计算成本为代价。这种固有的设计限制了其发展,阻碍了其应用。因此,论文提出了一个问题:语义分割是否像图像分类一样简单?
视觉Transformer(ViTs)很有潜力,但面临着平衡性能和内存使用的挑战。现有方法通过减少token数量或滑动窗口来缓解这种情况,但它们对计算复杂度的减少是有限的,甚至会妥协分割任务的全局或局部语义。 同时,语义分割作为一个基础研究领域,具有广泛的应用场景,需要处理各种分辨率的图像。 如上图所示,尽管高效Segformer相比PSPNet和DeepLabV3+取得了巨大突破,但仍面临着更高分辨率的巨大计算负担。论文提出了另一个问题:能否为超低计算场景设计高效灵活的Transformer网络用于语义分割?
本文提出了一种名为Adaptive Frequency Transformer(AFFormer)的轻量级语义分割架构。AFFormer采用了一种并行架构,利用原型表示作为特定的可学习局部描述来取代解码器,并在高分辨率特征上保留丰富的图像语义。此外,采用异构运算符来处理像素嵌入特征和局部描述特征,以节省更多的计算成本。基于Transformer的模块称为原型学习(PL)用于学习原型表示,而基于卷积的模块称为像素描述符(PD),将像素嵌入特征和学习的原型表示作为输入,将它们转换回全像素嵌入空间以保留高分辨率语义。
然而,从空间域的角度来线性化ViT的复杂度仍然非常困难。论文发现语义分割对频率信息也非常敏感。因此,构建了一个复杂度为O(n)的轻量级自适应频率滤波器,其作为原型学习来代替标准自注意力O(n^2)。该模块的核心由频率相似核,动态低通和高通滤波器组成,分别从强调重要频率分量和动态过滤频率的角度捕获对语义分割有益的频率信息。最后,通过在高频和低频提取和增强模块中共享权重来进一步减少计算成本。还在前馈网络(FFN)层中嵌入了一个简化的深度卷积层,以增强融合效果,减小两个矩阵变换的大小。
通过并行异构架构和自适应频率滤波器的帮助,仅使用一个卷积层作为分类层(CLS)用于单尺度特征,实现最佳性能,使语义分割和图像分类一样简单。 我们在三个广泛使用的数据集上证明了AFFormer的优势:ADE20K,Cityscapes和COCO-stuff。仅使用3M个参数,AFFormer显着优于最先进的轻量级方法。
方法

自适应频率Transformer。首先展示了并行异构网络的总体结构。具体来说,首先对补丁嵌入后的特征F进行聚类,得到原型特征G,从而构建一个包括两个异构算子的并行网络结构。一个基于Transformer的模块作为原型学习,捕捉G中有利的频率分量,得到原型表示G'。最后,G'由基于CNN的像素描述符恢复,得到下一阶段的F'。
Parallel Heterogeneous Architecture
语义解码器将编码器获得的图像语义传播到每个像素,并恢复下采样中丢失的细节。提出了一种新策略,用原型语义描述像素语义信息。对于每个阶段,给定一个特征F ∈ R^ (H×W×C),首先初始化一个网格G ∈ R^(h×w×C)作为图像的原型,其中G中的每个点都作为局部簇中心,初始状态仅包含周围区域的信息。这里使用1 × C向量来表示每个点的局部语义信息。对于每个具体的像素,由于周围像素的语义不一致,每个簇中心之间存在重叠语义。簇中心在其相应区域α^2中被加权初始化,并且每个簇中心的初始化表示为:

其中n=α×α,wi表示xi的权重,α设置为3。目的是更新网格G中的每个簇中心s,而不是直接更新特征F。由于h×w
这里使用基于Transformer的模块作为原型学习来更新每个聚类中心,其中总共包含L层,并更新的中心被称为G'(s)。对于每个更新的聚类中心,通过像素描述符恢复它。设F'i表示恢复的特征,它不仅包含来自F的丰富像素语义,而且还包含由聚类中心G'(s)收集的原型语义。 由于聚类中心聚合了周围像素的语义,导致局部细节的损失,PD首先用像素语义对F中的局部细节进行建模。具体来说,F被投影到低维空间,建立像素之间的局部关系,使每个局部块保持明显的边界。然后将G'(s)嵌入到F中,通过双线性插值恢复到原始空间特征F'。最后,它们通过线性投影层进行整合。
Prototype Learning by Adaptive Frequency Filter Motivation
 The effect of different frequency components on semantic segmentation.
The effect of different frequency components on semantic segmentation.
语义分割是一项极其复杂的像素级分类任务,容易出现类别混淆。频率表示可以作为学习类别差异的新范式,可以挖掘人类视觉忽略的信息。如上图所示,除非大部分频率分量被过滤,人类对频率信息移除具有鲁棒性。然而,模型对频率信息移除非常敏感,甚至移除少量信息也会导致显著的性能下降。这表明,对于模型来说,挖掘更多的频率信息可以增强类别之间的差异,使每个类别之间的边界更加清晰,从而提高语义分割的效果。

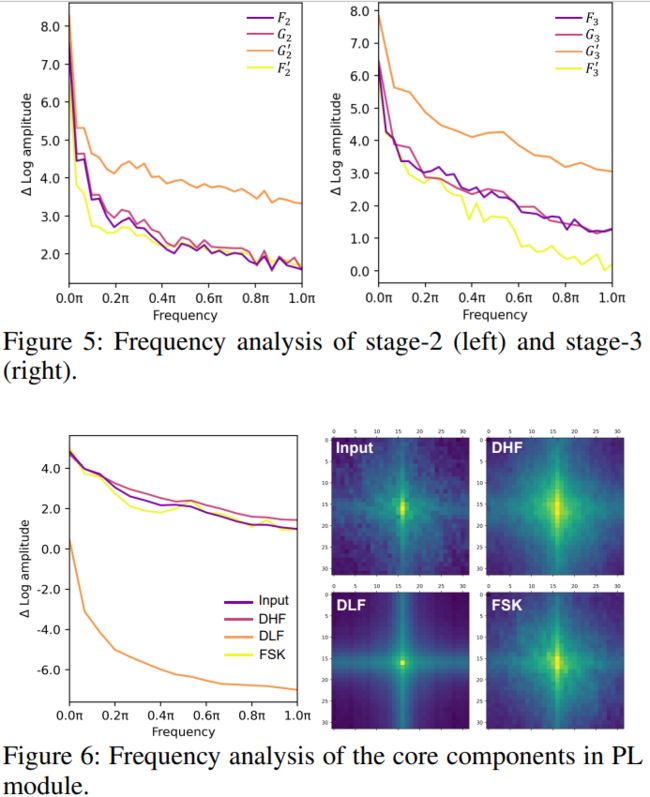
由于特征 F 包含丰富的频率特征,因此网格 G 中的每个聚类中心也收集了这些频率信息。为了提取不同的频率特征,之前的工作提出了一种基于 Fourier 变换和反 Fourier 变换的方法。然而,这种方法带来了额外的计算开销,并且不能在许多硬件上使用。因此,论文提出了一种基于视觉 Transformer 的自适应频率滤波块,直接在空间域中捕获重要的高频和低频特征。 其核心组件如上图所示,公式定义如下:

上面的公式定义了一种自适应频率滤波块的操作。其中,D^(fc)h、D^(lf)m(X)和D^(hf)n(X)分别表示具有H组的频率相似性内核、具有M组的动态低通滤波器和具有N组的动态高通滤波器。||·||表示Concatenation。值得注意的是,这些操作采用并行结构来进一步减少计算成本,这是通过共享权重来实现的。
Frequency Similarity Kernel (FSK)
不同的频率分量分布在G中,目的是选择和增强有助于语义解析的重要分量。为此,设计了一个频率相似性内核模块。给定一个X∈R^((hw)×C)的特征,通过卷积层在G上进行相对位置编码。首先使用固定大小的相似性内核A∈R^(C/H×C/H)来表示不同频率分量之间的对应关系,并通过查询相似性内核来选择重要的频率分量。通过线性层计算频率分量的键K和值V,并通过Softmax操作在频率分量之间归一化键。每个分量都集成了一个相似性内核Ai,j,计算如下:

其中ki表示K中第i个频率分量,vj表示V中第j个频率分量。还通过线性层将输入X转换为查询Q,并通过对固定大小相似性内核的交互获徖分量增强输出。
Dynamic Low-Pass Filters (DLF)
低频分量占据绝对图像的大部分能量,并表示大部分语义信息。低通滤波器允许低于截止频率的信号通过,而高于截止频率的信号被阻挡。因此,采用典型的平均池化作为低通滤波器。然而,不同图像的截止频率是不同的。为此,在多组中控制不同的内核和步幅来生成动态低通滤波器。对于第m组:

其中Λk×k表示具有核大小为k×k的深度卷积层。此外,使用查询和高频特征的Hadamard积来抑制物体内部的高频,这些高频是分割的噪声。FFN有助于融合捕获的频率信息,但具有大量计算,在轻量级设计中通常被忽略。通过引入卷积层来减少隐藏层的维数,以弥补由于维度压缩而缺失的能力。
讨论
对于频率相似性内核,计算复杂度为O(hwC^2)。每个动态高通滤波器的计算复杂度为O(hwCk^2),这比频率相似性内核的复杂度小得多。由于动态低通滤波器是通过每组的自适应平均池实现的,其计算复杂度约为O(hwC)。因此,模块的计算复杂度与分辨率呈线性关系,这对于语义分割的高分辨率是有利的。
实验


关键代码
afformer.py
# https://github.com/dongbo811/AFFormer/blob/main/tools/afformer.py
class DWConv(nn.Module):
def __init__(self, dim=768):
super(DWConv, self).__init__()
self.dwconv = nn.Conv2d(dim, dim, 3, 1, 1, bias=True, groups=dim)
def forward(self, x, H, W):
B, N, C = x.shape
x = x.transpose(1, 2).view(B, C, H, W)
x = self.dwconv(x)
x = x.flatten(2).transpose(1, 2)
return x
class Mlp(nn.Module):
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Linear(in_features, hidden_features)
self.dwconv = DWConv(hidden_features)
self.act = act_layer()
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop = nn.Dropout(drop)
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
elif isinstance(m, nn.Conv2d):
fan_out = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
fan_out //= m.groups
m.weight.data.normal_(0, math.sqrt(2.0 / fan_out))
if m.bias is not None:
m.bias.data.zero_()
def forward(self, x, size):
H, W = size
x = self.fc1(x)
x = self.act(x + self.dwconv(x, H, W))
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x
class Conv2d_BN(nn.Module):
"""Convolution with BN module."""
def __init__(
self,
in_ch,
out_ch,
kernel_size=1,
stride=1,
pad=0,
dilation=1,
groups=1,
bn_weight_init=1,
norm_layer=nn.BatchNorm2d,
act_layer=None,
):
super().__init__()
self.conv = torch.nn.Conv2d(in_ch,
out_ch,
kernel_size,
stride,
pad,
dilation,
groups,
bias=False)
self.bn = norm_layer(out_ch)
torch.nn.init.constant_(self.bn.weight, bn_weight_init)
torch.nn.init.constant_(self.bn.bias, 0)
for m in self.modules():
if isinstance(m, nn.Conv2d):
# Note that there is no bias due to BN
fan_out = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(mean=0.0, std=np.sqrt(2.0 / fan_out))
self.act_layer = act_layer() if act_layer is not None else nn.Identity(
)
def forward(self, x):
x = self.conv(x)
x = self.bn(x)
x = self.act_layer(x)
return x
class DWConv2d_BN(nn.Module):
def __init__(
self,
in_ch,
out_ch,
kernel_size=1,
stride=1,
norm_layer=nn.BatchNorm2d,
act_layer=nn.Hardswish,
bn_weight_init=1,
):
super().__init__()
# dw
self.dwconv = nn.Conv2d(
in_ch,
out_ch,
kernel_size,
stride,
(kernel_size - 1) // 2,
groups=out_ch,
bias=False,
)
# pw-linear
self.pwconv = nn.Conv2d(out_ch, out_ch, 1, 1, 0, bias=False)
self.bn = norm_layer(out_ch)
self.act = act_layer() if act_layer is not None else nn.Identity()
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2.0 / n))
if m.bias is not None:
m.bias.data.zero_()
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(bn_weight_init)
m.bias.data.zero_()
def forward(self, x):
x = self.dwconv(x)
x = self.pwconv(x)
x = self.bn(x)
x = self.act(x)
return x
class DWCPatchEmbed(nn.Module):
def __init__(self,
in_chans=3,
embed_dim=768,
patch_size=16,
stride=1,
act_layer=nn.Hardswish):
super().__init__()
self.patch_conv = DWConv2d_BN(
in_chans,
embed_dim,
kernel_size=patch_size,
stride=stride,
act_layer=act_layer,
)
def forward(self, x):
x = self.patch_conv(x)
return x
class Patch_Embed_stage(nn.Module):
def __init__(self, embed_dim, num_path=4, isPool=False, stage=0):
super(Patch_Embed_stage, self).__init__()
if stage == 3:
self.patch_embeds = nn.ModuleList([
DWCPatchEmbed(
in_chans=embed_dim,
embed_dim=embed_dim,
patch_size=3,
stride=4 if (isPool and idx == 0) or (stage > 1 and idx == 1) else 1,
) for idx in range(num_path + 1)
])
else:
self.patch_embeds = nn.ModuleList([
DWCPatchEmbed(
in_chans=embed_dim,
embed_dim=embed_dim,
patch_size=3,
stride=2 if (isPool and idx == 0) or (stage > 1 and idx == 1) else 1,
) for idx in range(num_path + 1)
])
def forward(self, x):
att_inputs = []
for pe in self.patch_embeds:
x = pe(x)
att_inputs.append(x)
return att_inputs
class ConvPosEnc(nn.Module):
def __init__(self, dim, k=3):
super(ConvPosEnc, self).__init__()
self.proj = nn.Conv2d(dim, dim, k, 1, k // 2, groups=dim)
def forward(self, x, size):
B, N, C = x.shape
H, W = size
feat = x.transpose(1, 2).view(B, C, H, W)
x = self.proj(feat) + feat
x = x.flatten(2).transpose(1, 2)
return x
class LowPassModule(nn.Module):
def __init__(self, in_channel, sizes=(1, 2, 3, 6)):
super().__init__()
self.stages = []
self.stages = nn.ModuleList([self._make_stage(size) for size in sizes])
self.relu = nn.ReLU()
ch = in_channel // 4
self.channel_splits = [ch, ch, ch, ch]
def _make_stage(self, size):
prior = nn.AdaptiveAvgPool2d(output_size=(size, size))
return nn.Sequential(prior)
def forward(self, feats):
h, w = feats.size(2), feats.size(3)
feats = torch.split(feats, self.channel_splits, dim=1)
priors = [F.upsample(input=self.stages[i](feats[i]), size=(h, w), mode='bilinear') for i in range(4)]
bottle = torch.cat(priors, 1)
return self.relu(bottle)
class FilterModule(nn.Module):
def __init__(self, Ch, h, window):
super().__init__()
self.conv_list = nn.ModuleList()
self.head_splits = []
for cur_window, cur_head_split in window.items():
dilation = 1 # Use dilation=1 at default.
padding_size = (cur_window + (cur_window - 1) *
(dilation - 1)) // 2
cur_conv = nn.Conv2d(
cur_head_split * Ch,
cur_head_split * Ch,
kernel_size=(cur_window, cur_window),
padding=(padding_size, padding_size),
dilation=(dilation, dilation),
groups=cur_head_split * Ch,
)
self.conv_list.append(cur_conv)
self.head_splits.append(cur_head_split)
self.channel_splits = [x * Ch for x in self.head_splits]
self.LP = LowPassModule(Ch * h)
def forward(self, q, v, size):
B, h, N, Ch = q.shape
H, W = size
# Shape: [B, h, H*W, Ch] -> [B, h*Ch, H, W].
v_img = rearrange(v, "B h (H W) Ch -> B (h Ch) H W", H=H, W=W)
LP = self.LP(v_img)
# Split according to channels.
v_img_list = torch.split(v_img, self.channel_splits, dim=1)
HP_list = [
conv(x) for conv, x in zip(self.conv_list, v_img_list)
]
HP = torch.cat(HP_list, dim=1)
# Shape: [B, h*Ch, H, W] -> [B, h, H*W, Ch].
HP = rearrange(HP, "B (h Ch) H W -> B h (H W) Ch", h=h)
LP = rearrange(LP, "B (h Ch) H W -> B h (H W) Ch", h=h)
dynamic_filters = q * HP + LP
return dynamic_filters
class Frequency_FilterModule(nn.Module):
def __init__(
self,
dim,
num_heads=8,
qkv_bias=False,
qk_scale=None,
attn_drop=0.0,
proj_drop=0.0,
shared_crpe=None,
):
super().__init__()
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = qk_scale or head_dim ** -0.5
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
# Shared convolutional relative position encoding.
self.crpe = shared_crpe
def forward(self, x, size):
B, N, C = x.shape
# Generate Q, K, V.
qkv = (self.qkv(x).reshape(B, N, 3, self.num_heads,
C // self.num_heads).permute(2, 0, 3, 1, 4))
q, k, v = qkv[0], qkv[1], qkv[2]
# Factorized attention.
k_softmax = k.softmax(dim=2)
k_softmax_T_dot_v = einsum("b h n k, b h n v -> b h k v", k_softmax, v)
factor_att = einsum("b h n k, b h k v -> b h n v", q,
k_softmax_T_dot_v)
# Convolutional relative position encoding.
crpe = self.crpe(q, v, size=size)
# Merge and reshape.
x = self.scale * factor_att + crpe
x = x.transpose(1, 2).reshape(B, N, C)
# Output projection.
x = self.proj(x)
x = self.proj_drop(x)
return x
class MHCABlock(nn.Module):
def __init__(
self,
dim,
num_heads,
mlp_ratio=3,
drop_path=0.0,
qkv_bias=True,
qk_scale=None,
norm_layer=partial(nn.LayerNorm, eps=1e-6),
shared_cpe=None,
shared_crpe=None,
):
super().__init__()
self.cpe = shared_cpe
self.crpe = shared_crpe
self.factoratt_crpe = Frequency_FilterModule(
dim,
num_heads=num_heads,
qkv_bias=qkv_bias,
qk_scale=qk_scale,
shared_crpe=shared_crpe,
)
self.mlp = Mlp(in_features=dim, hidden_features=dim * mlp_ratio)
self.drop_path = DropPath(
drop_path) if drop_path > 0.0 else nn.Identity()
self.norm1 = norm_layer(dim)
self.norm2 = norm_layer(dim)
def forward(self, x, size):
if self.cpe is not None:
x = self.cpe(x, size)
cur = self.norm1(x)
x = x + self.drop_path(self.factoratt_crpe(cur, size))
cur = self.norm2(x)
x = x + self.drop_path(self.mlp(cur, size))
return x
class MHCAEncoder(nn.Module):
def __init__(
self,
dim,
num_layers=1,
num_heads=8,
mlp_ratio=3,
drop_path_list=[],
qk_scale=None,
crpe_window={
3: 2,
5: 3,
7: 3
},
):
super().__init__()
self.num_layers = num_layers
self.cpe = ConvPosEnc(dim, k=3)
self.crpe = FilterModule(Ch=dim // num_heads,
h=num_heads,
window=crpe_window)
self.MHCA_layers = nn.ModuleList([
MHCABlock(
dim,
num_heads=num_heads,
mlp_ratio=mlp_ratio,
drop_path=drop_path_list[idx],
qk_scale=qk_scale,
shared_cpe=self.cpe,
shared_crpe=self.crpe,
) for idx in range(self.num_layers)
])
def forward(self, x, size):
H, W = size
B = x.shape[0]
for layer in self.MHCA_layers:
x = layer(x, (H, W))
# return x's shape : [B, N, C] -> [B, C, H, W]
x = x.reshape(B, H, W, -1).permute(0, 3, 1, 2).contiguous()
return x
class Restore(nn.Module):
def __init__(
self,
in_features,
hidden_features=None,
out_features=None,
act_layer=nn.Hardswish,
norm_layer=nn.BatchNorm2d,
):
super().__init__()
out_features = out_features or in_features
hidden_features = in_features // 2
self.conv1 = Conv2d_BN(in_features,
hidden_features,
act_layer=act_layer)
self.dwconv = nn.Conv2d(
hidden_features,
hidden_features,
3,
1,
1,
bias=False,
groups=hidden_features,
)
self.norm = norm_layer(hidden_features)
self.act = act_layer()
self.conv2 = Conv2d_BN(hidden_features, out_features)
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Conv2d):
fan_out = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
fan_out //= m.groups
m.weight.data.normal_(0, math.sqrt(2.0 / fan_out))
if m.bias is not None:
m.bias.data.zero_()
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
def forward(self, x):
identity = x
feat = self.conv1(x)
feat = self.dwconv(feat)
feat = self.norm(feat)
feat = self.act(feat)
feat = self.conv2(feat)
return identity + feat
class MHCA_stage(nn.Module):
def __init__(
self,
embed_dim,
out_embed_dim,
num_layers=1,
num_heads=8,
mlp_ratio=3,
num_path=4,
drop_path_list=[],
id_stage=0,
):
super().__init__()
self.Restore = Restore(in_features=embed_dim, out_features=embed_dim)
if id_stage > 0:
self.aggregate = Conv2d_BN(embed_dim * (num_path),
out_embed_dim,
act_layer=nn.Hardswish)
self.mhca_blks = nn.ModuleList([
MHCAEncoder(
embed_dim,
num_layers,
num_heads,
mlp_ratio,
drop_path_list=drop_path_list,
) for _ in range(num_path)
])
else:
self.aggregate = Conv2d_BN(embed_dim * (num_path),
out_embed_dim,
act_layer=nn.Hardswish)
def forward(self, inputs, id_stage):
if id_stage > 0:
att_outputs = [self.Restore(inputs[0])]
for x, encoder in zip(inputs[1:], self.mhca_blks):
# [B, C, H, W] -> [B, N, C]
_, _, H, W = x.shape
x = x.flatten(2).transpose(1, 2)
att_outputs.append(encoder(x, size=(H, W)))
for i in range(len(att_outputs)):
if att_outputs[i].shape[2:] != att_outputs[0].shape[2:]:
att_outputs[i] = F.interpolate(att_outputs[i], size=att_outputs[0].shape[2:], mode='bilinear',
align_corners=True)
out_concat = att_outputs[0] + att_outputs[1]
else:
out_concat = self.Restore(inputs[0] + inputs[1])
out = self.aggregate(out_concat)
return out
class Cls_head(nn.Module):
"""a linear layer for classification."""
def __init__(self, embed_dim, num_classes):
super().__init__()
self.cls = nn.Linear(embed_dim, num_classes)
def forward(self, x):
# (B, C, H, W) -> (B, C, 1)
x = nn.functional.adaptive_avg_pool2d(x, 1).flatten(1)
# Shape : [B, C]
out = self.cls(x)
return out
def dpr_generator(drop_path_rate, num_layers, num_stages):
"""Generate drop path rate list following linear decay rule."""
dpr_list = [
x.item() for x in torch.linspace(0, drop_path_rate, sum(num_layers))
]
dpr = []
cur = 0
for i in range(num_stages):
dpr_per_stage = dpr_list[cur:cur + num_layers[i]]
dpr.append(dpr_per_stage)
cur += num_layers[i]
return dpr
class AFFormer(BaseModule):
def __init__(
self,
img_size=224,
num_stages=4,
num_path=[4, 4, 4, 4],
num_layers=[1, 1, 1, 1],
embed_dims=[64, 128, 256, 512],
mlp_ratios=[8, 8, 4, 4],
num_heads=[8, 8, 8, 8],
drop_path_rate=0.0,
in_chans=3,
num_classes=1000,
strides=[4, 2, 2, 2],
pretrained=None, init_cfg=None,
):
super().__init__()
if isinstance(pretrained, str):
self.init_cfg = pretrained
self.num_classes = num_classes
self.num_stages = num_stages
dpr = dpr_generator(drop_path_rate, num_layers, num_stages)
self.stem = nn.Sequential(
Conv2d_BN(
in_chans,
embed_dims[0] // 2,
kernel_size=3,
stride=2,
pad=1,
act_layer=nn.Hardswish,
),
Conv2d_BN(
embed_dims[0] // 2,
embed_dims[0],
kernel_size=3,
stride=2,
pad=1,
act_layer=nn.Hardswish,
),
)
self.patch_embed_stages = nn.ModuleList([
Patch_Embed_stage(
embed_dims[idx],
num_path=num_path[idx],
isPool=True if idx == 1 else False,
stage=idx,
) for idx in range(self.num_stages)
])
self.mhca_stages = nn.ModuleList([
MHCA_stage(
embed_dims[idx],
embed_dims[idx + 1]
if not (idx + 1) == self.num_stages else embed_dims[idx],
num_layers[idx],
num_heads[idx],
mlp_ratios[idx],
num_path[idx],
drop_path_list=dpr[idx],
id_stage=idx,
) for idx in range(self.num_stages)
])
# Classification head.
# self.cls_head = Cls_head(embed_dims[-1], num_classes)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
elif isinstance(m, nn.Conv2d):
fan_out = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
fan_out //= m.groups
m.weight.data.normal_(0, math.sqrt(2.0 / fan_out))
if m.bias is not None:
m.bias.data.zero_()
def init_weights(self):
if isinstance(self.init_cfg, str):
logger = get_root_logger()
load_checkpoint(self, self.init_cfg, map_location='cpu', strict=False, logger=logger)
else:
self.apply(self._init_weights)
def freeze_patch_emb(self):
self.patch_embed1.requires_grad = False
@torch.jit.ignore
def no_weight_decay(self):
return {'pos_embed1', 'pos_embed2', 'pos_embed3', 'pos_embed4', 'cls_token'} # has pos_embed may be better
def get_classifier(self):
return self.head
def reset_classifier(self, num_classes, global_pool=''):
self.num_classes = num_classes
self.head = nn.Linear(self.embed_dim, num_classes) if num_classes > 0 else nn.Identity()
def forward(self, x):
# x's shape : [B, C, H, W]
x = self.stem(x) # Shape : [B, C, H/4, W/4]
out = []
for idx in range(self.num_stages):
att_inputs = self.patch_embed_stages[idx](x)
x = self.mhca_stages[idx](att_inputs, idx)
out.append(x)
return out
@BACKBONES.register_module()
class afformer_base(AFFormer):
def __init__(self, **kwargs):
super(afformer_base, self).__init__(
img_size=224,
num_stages=4,
num_path=[1, 1, 1, 1],
num_layers=[1, 2, 6, 2],
embed_dims=[32, 96, 176, 216],
mlp_ratios=[2, 2, 2, 2],
num_heads=[8, 8, 8, 8], **kwargs)
@BACKBONES.register_module()
class afformer_small(AFFormer):
def __init__(self, **kwargs):
super(afformer_small, self).__init__(
img_size=224,
num_stages=4,
num_path=[1, 1, 1, 1],
num_layers=[1, 2, 4, 2],
embed_dims=[32, 64, 176, 216],
mlp_ratios=[2, 2, 2, 2],
num_heads=[8, 8, 8, 8], **kwargs)
@BACKBONES.register_module()
class afformer_tiny(AFFormer):
def __init__(self, **kwargs):
super(afformer_tiny, self).__init__(
img_size=224,
num_stages=4,
num_path=[1, 1, 1, 1],
num_layers=[1, 2, 4, 2],
embed_dims=[32, 64, 160, 216],
mlp_ratios=[2, 2, 2, 2],
num_heads=[8, 8, 8, 8], **kwargs)