CIKM是信息检索、知识管理和数据库领域中顶级的国际学术会议,自1992年以来,CIKM成功汇聚上述三个领域的一流研究人员和开发人员,为交流有关信息与知识管理研究、数据和知识库的最新发展提供了一个国际论坛。大会的目的在于明确未来知识与信息系统发展将面临的挑战和问题,并通过征集和评估应用性和理论性强的顶尖研究成果以确定未来的研究方向。
今年的CIKM大会原计划10月份在爱尔兰的Galway举行,由于疫情原因改为在线举行。美团AI平台/搜索与NLP部/NLP中心/知识图谱组共有六篇论文(其中4篇长文,2篇短文)被国际会议CIKM 2020接收。
这些论文是美团知识图谱组与西安交通大学、中国科学院大学、电子科技大学、中国人民大学、西安电子科技大学、南洋理工大学等高校院所的科研合作成果,是在多模态知识图谱、MT-BERT、Graph Embedding和图谱可解释性等方向上的技术沉淀和应用。希望这些论文能帮助到更多的同学学习成长。
01 《Query-aware Tip Generation for Vertical Search》
| 本论文系美团知识图谱组与西安交通大学郝俊美同学、中国科学院大学李灿佳同学、西安电子科技大学汪自力同学的合作论文。
可解释性理由(又称推荐理由)是在搜索结果页和发现页(场景决策、必吃榜单等)展示给用户进行亮点推荐的一句自然语言文本,可以看作是真实用户评论的高度浓缩,为用户解释召回结果,挖掘商户特色,吸引用户点击,并对用户进行场景化引导,辅助用户决策从而优化垂直搜索场景中的用户体验。
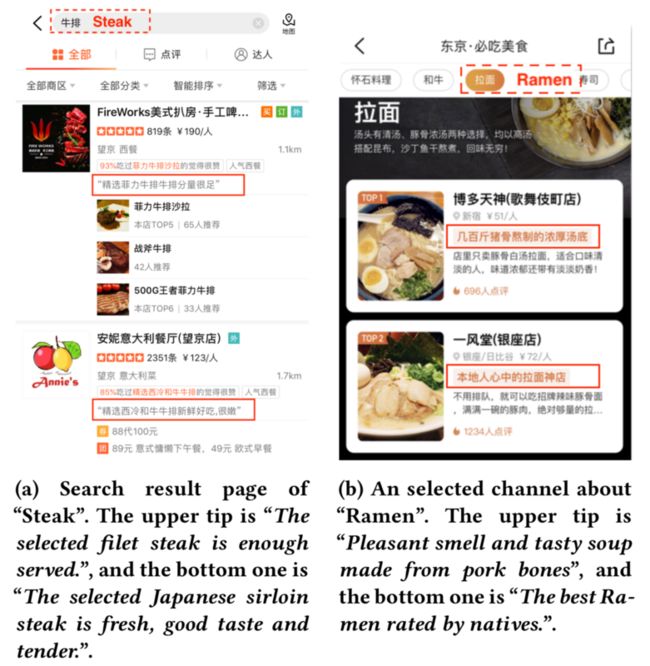
现有的文本生成工作大部分并未考虑用户的意图信息,这限制了生成式推荐理由在场景化搜索中的落地。本文提出一种Query感知的推荐理由生成框架,将用户Query信息分别嵌入到生成模型的编码和解码过程中,根据用户Query不同会自动生成适配不同场景的个性化推荐理由。本文分别对Transformer和递归神经网络(RNN)两种主流模型结构进行了改造。基于Transformer结构,本文通过改进Self-Attention机制来引入Query信息,包括在Encoder引入Query-aware Review Encoder使得在评论编码最初阶段就开始考虑Query相关的信息,在Decoder端引入Query-aware Tip Decoder使得在评论编码最后阶段考虑Query相关的信息。基于RNN结构,在Encoder端通过Selective Gate方式过滤掉Query无关信息,选择原始评论中跟Query相关的信息进行编码,并在解码器端将Query表示向量加入Attention机制的Context向量计算,指导解码的过程,一定程度上解决了生成方法解码不可控的问题,从而生成Query个性化的推荐理由。
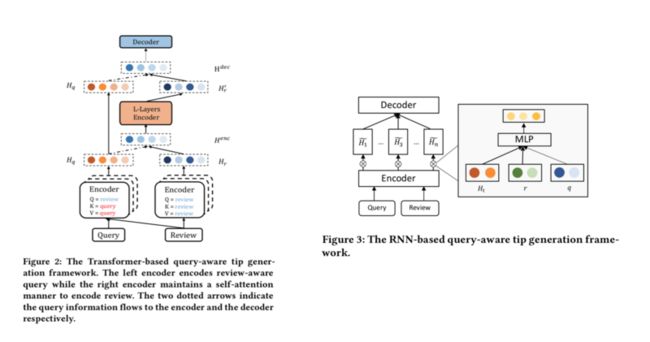
在公开数据集和美团业务数据集上分别进行实验,该论文提出的方法优于现有方法。该论文提出的算法已应用上线,目前在美团的搜索、推荐、类目筛选和榜单等多场景落地。

02 《TABLE: A Task-Adaptive BERT-based ListwisE Ranking Model for Document Retrieval》
| 本论文系美团知识图谱组与中国科学院软件研究所唐弘胤同学、金蓓弘老师的合作论文。
近年来,为了提高模型的自然语言理解能力,越来越多的MRC和QA数据集开始涌现。但是,这些数据集或多或少存在一些缺陷,比如数据量不够、依赖人工构造Query等。针对这些问题,微软提出了一个基于大规模真实场景数据的阅读理解数据集MS MARCO (Microsoft Machine Reading Comprehension)。该数据集基于Bing搜索引擎和Cortana智能助手中的真实搜索查询产生,包含100万查询、800万文档和18万人工编辑的答案。
基于MS MARCO数据集,微软提出了两种不同的任务:一种是给定问题,检索所有数据集中的文档并进行排序,属于文档检索和排序任务;另一种是根据问题和给定的相关文档生成答案,属于QA任务。在美团业务中,文档检索和排序算法在搜索、广告、推荐等场景中都有着广泛的应用。此外,直接在所有候选文档上进行QA任务的时间消耗是无法接受的,QA任务必须依靠排序任务筛选出排名靠前的文档,而排序算法的性能直接影响到QA任务的表现。基于上述原因,我们主要将精力放在基于MS MARCO的文档检索和排序任务上。
自2018年10月MACRO文档排序任务发布后,迄今吸引了包括阿里巴巴达摩院、Facebook、微软、卡内基梅隆大学、清华等多家企业和高校的参与。在美团的预训练MT-BERT平台上,我们提出了一种针对该文本检索任务的BERT算法方案,称之为TABLE。值得注意的是,该论文提出的TABLE模型在信息检索领域的权威评测微软 MARCO排行榜上首个超过0.4%的模型。

如上图所示,该论文提出了一种基于BERT的文档检索模型TABLE。在TABLE的预训练阶段,使用了一种领域自适应策略。在微调阶段,该论文提出了两阶段的任务自适应训练过程,即查询类型自适应的Pointwise微调以及List微调。实验证明这种任务自适应过程使模型更具鲁棒性。这项工作可以探索查询和文档之间更丰富的匹配特性。因此,该论文显著提升了BERT在文档检索任务中的效果。随后在TABLE的基础上我们又提出了两个解决OOV(Out of Vocabulary)错误匹配的方法:精准匹配方法和词还原机制,进一步提升了模型的效果,我们把这个改进后的模型称为DR-BERT。DR-BERT的细节详见我们的技术博客: 《MT-BERT在文本检索任务中的实践》。
03 《Multi-Modal Knowledge Graphs for Recommender Systems》
| 本论文系美团知识图谱组与中国科学院软件研究所唐弘胤同学、金蓓红老师的合作论文。
随着知识图谱技术发展,其结构化数据被成功的应用在了一系列下游应用当中。在推荐系统方向中,结构化的图谱数据可以利用目标商品更加全面的辅助信息,通过图谱关联进行信息传播,从而有效地对目标商品进行表征建模,缓解推荐系统中用户行为稀疏及冷启动等问题。近年来,已经有不少研究工作利用图谱路径特征、基于图嵌入的表征学习等方式,成功的将图谱数据和推荐系统进行结合,使得推荐系统准确率得到提升。
在已有的图谱和推荐系统结合的工作当中,人们往往仅关注于图谱节点和节点关系,而没有利用多模态知识图谱中的各个模态的数据进行建模。多模态数据包括图像模态如电影的剧照,文本模态如商户的评论等。这些多模态数据同样可以通过知识图谱图关系进行传播和泛化,并为下游的推荐系统带来高价值的信息。然而,由于多模态知识建模往往是不同模态的辅助信息关系,而非传统图谱中三元组所代表的语义关联关系,故传统的图谱建模方式并不能很好地对多模态知识图谱进行建模。
因此,本文针对多模态知识图谱的特点提出了MKGAT模型,首次提出利用多模态知识图谱的结构化信息提升下游推荐系统的预测准确度。MKGAT的整体模型框架如下图所示:
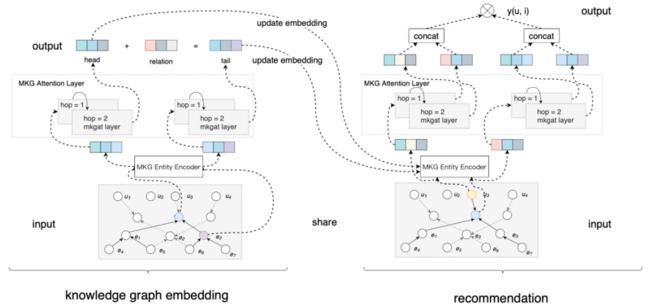
在MKGAT模型中,多模态图谱的嵌入表示学习主要分为三个主要部分:1)我们首先利用多模态实体编码模块(MKG Entity Encoder),将不同类型的输入数据(图像、文本、标签等)编码为高阶隐向量;2)接下来,我们基于多模态图注意力机制模块(MKG Attention Layer),利用实体节点周围的节点(包括多模态及实体节点)来为该节点的刻画提供相应的信息;3)在利用注意力机制综合了多模态信息之后,再利用传统h+r=t的训练方法进行图谱嵌入表示学习。
在接入下游推荐系统模型时,我们同样是复用了多模态实体编码和多模态图注意力机制模块对目标实体进行表征,接入推荐系统模型当中。通过上述方法,我们在美团的美食搜索场景和公开数据集MovieLens这两个真实数据集上进行了详尽的实验,结果表明在这两个场景中MKGAT显著地提高了推荐系统的质量。
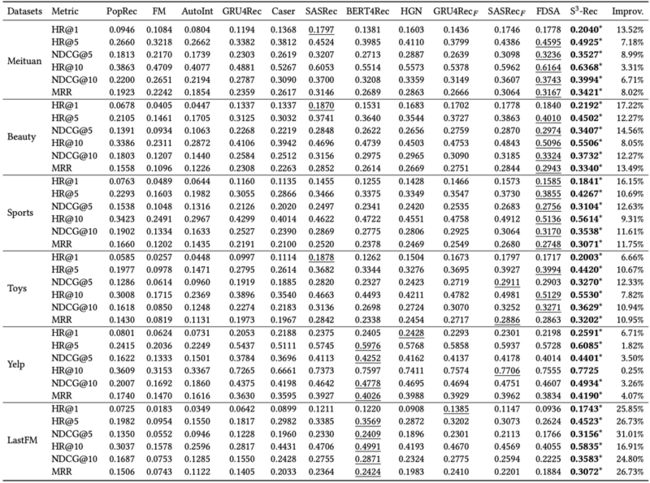
04 《S^3-Rec: Self-Supervised Learning for Sequential Recommendation with Mutual Information Maximization》
| 本论文系美团知识图谱组与中国人民大学周昆同学、王辉同学、朱余韬同学、赵鑫老师、文继荣老师的合作论文。
序列推荐是指利用用户长期的交互历史序列,预测用户未来交互的商品,其通过建模序列信息来增强给用户推荐的准确度。现有的序列推荐模型利用商品预测这一任务来进行模型的参数训练,但是也受限于唯一的训练任务,该类模型很容易受数据稀疏问题影响;它虽然优化的是最终的推荐目标,但是并没有充分地建模上下文数据中的潜在关系,更没有利用该部分信息帮助序列推荐模型。
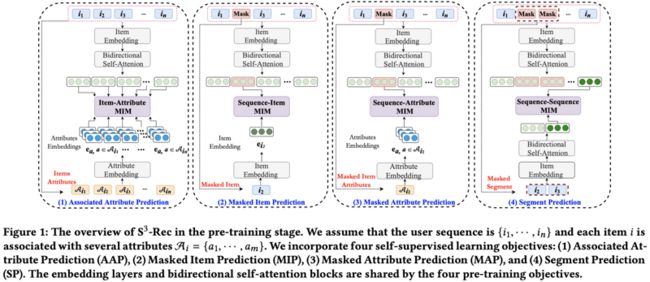
为解决以上问题,本文提出了一个新模型S^3-Rec,它基于自注意力网络结构,采用自监督学习策略进行表示学习,进而优化序列化推荐任务。该模型基于四种特殊的自监督任务,这些任务分别对属性、商品、自序列和原始序列之间的潜在关系进行学习。由于以上四种信息表示输入数据的四种不同信息粒度视角,本文采用互信息最大化策略来建模这四种信息的潜在关系,进而强化该类数据的表示。本文在包括美团场景的六个真实数据集上进行了大量的实验,以证明该论文提出方法比现有的序列推荐先进方法的优越性,其中在有限的训练数据场景下该模型依旧能保持较好的表现。
05《Leveraging Historical Interaction Data for Improving Conversational Recommender System》
| 本论文系美团知识图谱组与中国人民大学周昆同学、王辉同学、赵鑫老师、文继荣老师的合作论文。
近年来,会话推荐系统已经成为了一项重要的研究方向,它在现实生活中也有很多的应用。一个会话推荐系统需要能够通过与用户的对话来了解用户的意图,进而给出合适的推荐,因此它包含一个会话模块和推荐模块。现有的会话推荐系统往往基于学习好的用户表示来完成推荐,这需要对对话内容进行编码。但是实际上仅仅使用对话数据难以准确地预测用户的偏好信息,本论文期望能够通过利用用户的历史交互序列,帮助完成推荐。

基于该设想,会话推荐系统需要同时考虑用户的历史交互序列和会话数据,本论文提出了一种新的预训练方法,通过预训练方法将基于商户的偏好序列(来自历史交互数据)和基于商户属性的偏好序列(来自对话数据)结合起来,提升了会话推荐系统的效果。为了进一步提高性能,该论文还设计了一种负样本生成器,以产生高质量的负样本来帮助训练。该论文在两个真实数据集上进行了实验,并证明了该方法对改进会话推荐系统是有效的。
06 《Structural relationship representation learning with graph embedding for personalized product search》
| 本论文系美团知识图谱组与南洋理工大学刘尚同学、丛高老师的合作论文。
[论文下载](https://dl.acm.org/doi/abs/10...
)
个性化在商品搜索中非常重要,用户的偏好在很大程度上影响着用户的购买决策。例如,当一个年轻用户在电子商务平台上搜索一件“宽松T恤”时,他更有可能购买他感兴趣、有品牌的时尚款式或衬衫。个性化商品搜索(PPS)的目的是针对给定的查询生成用户特有的商品建议,在很多电子商务平台中起着至关重要的作用。
在这项工作中,我们利用从用户-查询-商品中学习的逻辑结构表示,自然地保留用户/查询/商品之间的协作信号和交互信息在逻辑路径上,以改进个性化的商品搜索。我们把这些逻辑结构称为“Conjunctive Graph Pattern”。例如,如图1所示,有三个关键模式。注意,当分支有三个或更多分支时,我们可以随机抽样其中的两个分支,得到以下模式:

具体来说,我们提出一个新方法:基于逻辑结构表示学习的图嵌入模型(GraphLSR)。GraphLSR的概念优势在于,它是一个基于嵌入的框架,可以有效地学习逻辑结构的表示,以及用户(查询或商品)在几何操作中的近似关系,并将其整合到个性化的商品搜索中。它背后的关键思想是,我们学习了如何将三种类型的连接图模式嵌入到低维空间中,通过嵌入图来增强个性化商品搜索,框架如图2所示,它由两个主要组件组成:图嵌入模块和个性化搜索模块。图2下方的图嵌入模块利用设计的三种连接图模式学习嵌入节点进行逻辑表示学习,也便于学习用户(查询或商品)之间的相似度。然后将表示信息引入个性化搜索模块。
个性化搜索模块以用户、查询、商品以及从图嵌入中学习的表示作为输入,使用多层感知器(MLP)集成相应的信息。将提取出来的用户、查询和商品的短特征和密集特征分别输入到MLP网络中,学习用户特有的查询代表和用户特有的商品表示,然后我们将它们一起输入另一个MLP来计算预测的概率分数。
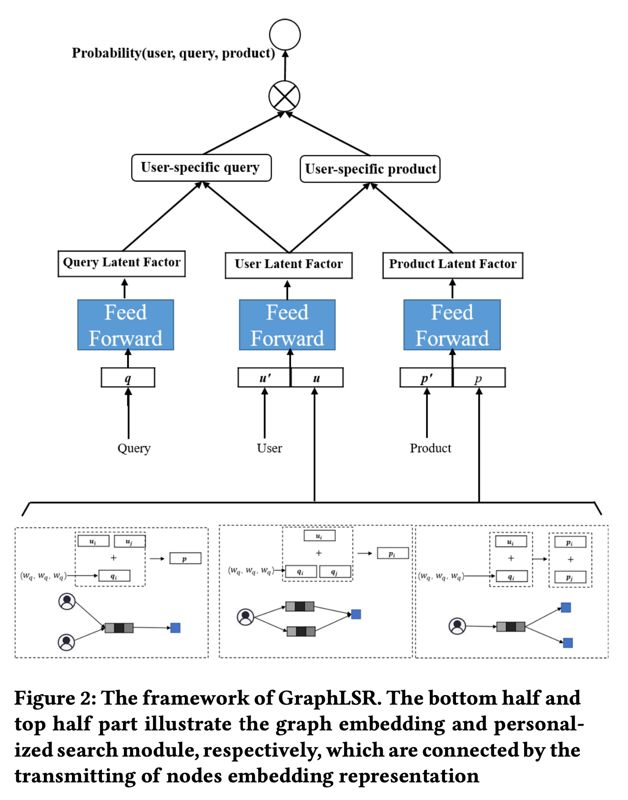
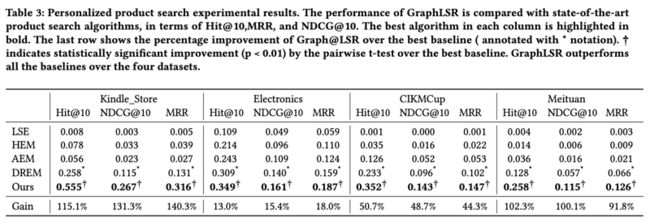
表3比较了GraphLSR与四种个性化搜索方法在个性化商品搜索任务中的MRR、NDCG@10和Hit@10方面的性能:
总结
以上是搜索与NLP部知识图谱组在多模态知识图谱、MT-BERT、Graph-Embedding、图谱可解释性上所做的一些研究工作,论文成果也是我们在实际工作场景中遇到并解决的具体问题,大部分工作已经在实际业务场景如内容搜索、商品搜索、推荐理由等项目上落地,并取得不错的业务收益。美团AI平台/搜索与NLP中心一直致力于通过产研结合,不断将学术成果转化为技术生产力,同时也欢迎更多有志之士加入我们团队。
| 想阅读更多技术文章,请关注美团技术团队(meituantech)官方微信公众号。在公众号菜单栏回复【2019年货】、【2018年货】、【2017年货】、【算法】等关键词,可查看美团技术团队历年技术文章合集。
