三月有很多的重大产品发布,包括刚刚发布的GPT4,还有Meta刚发布就被泄露的LLaMA,midjourney V5,还有ChatGPT的API(非常便宜)等等。
但是本文整理的是本月应该阅读的10篇论文,将包括多模态语言模型、扩散模型、机器翻译等主题。
1、LLaMA: Open and Efficient Foundation Language Models
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, Guillaume Lample
https://arxiv.org/pdf/2302.13971
开源的LLaMA,并且开放了模型权重,但是需要申请才可以下载,不过有网友已经将它全部公开下载了,这对我们来说是个好事。这个模型在超过一万亿令牌上进行训练,主要包括以下几个模型:
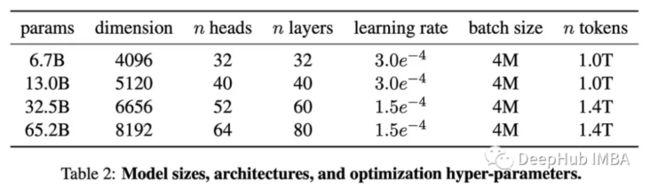
这些模型是在完全公开的数据上进行训练的,它们在各种QA和常识推理任务中都能在零样本和少样本中取得出色的表现。
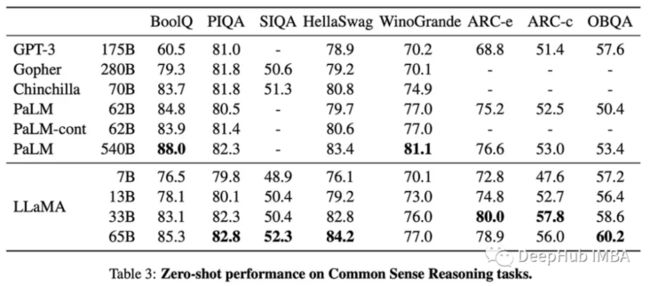
这些开源的模型既没有经过微调,也没有RLHF化,所以还需要我们自行调教,这也正好适合我们的弯道超车,下载地址我们以前已经发布过了,有兴趣的可以去看看。
2、Consistency Models
Yang Song, Prafulla Dhariwal, Mark Chen, Ilya Sutskever.
https://github.com/cloneofsimo/consistency_models
扩散模型的计算是非常耗时的,因为他们需要解码输出迭代多次,使其比一次向前传递所允许的更具表现力。但这使得它们很慢,不像GANs、vae那样。
这个论文提出学习一个模型,该模型预测在任意深度水平上扩散过程的输出(见下图)。

构建这些模型的关键是认识到任何跳跃 f(x, t) 都需要与其步骤的组合保持一致;当从噪声到数据时,不同的跳跃需要以相同的图像结束;这就是他们需要保持一致,所以才叫Consistency Models 。
在之前的Progressive Distillation 研究中已经展示了一种将扩散模型提炼成需要更少解码步骤(例如,只有 4 个)的方法,但在本文中,提出了一种训练独立一致性模型的方法。

3、PaLM-E: An Embodied Multimodal Language Model
Danny Driess, Fei Xia, Mehdi S. M. Sajjadi, Corey Lynch, Aakanksha Chowdhery, Brian Ichter, Ayzaan Wahid, Jonathan Tompson, Quan Vuong, Tianhe Yu, Wenlong Huang, Yevgen Chebotar, Pierre Sermanet, Daniel Duckworth, Sergey Levine, Vincent Vanhoucke, Karol Hausman, Marc Toussaint, Klaus Greff, Andy Zeng, Igor Mordatch, Pete Florence.
https://arxiv.org/abs/2303.03378
这时google的多模态模型,为了编码图像,他们使用视觉转换器(ViT)和编码文本PaLM,模型菜蔬高达5620亿个(分别为22B + 540B)。

虽然这项工作标榜自己是端到端的解决方案,但事实是仍然严重依赖于传统技术,而且语言模型只提供高级动作指令。
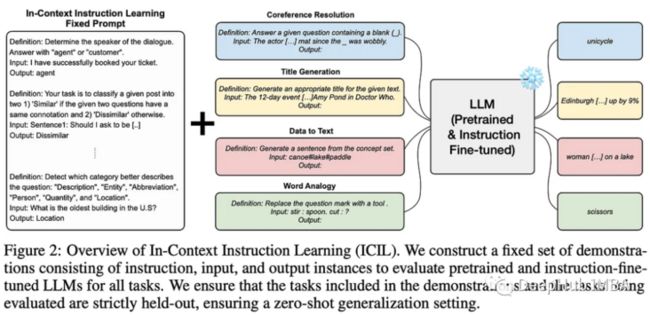
4、In-context Instruction Learning
Seonghyeon Ye, Hyeonbin Hwang, Sohee Yang, Hyeongu Yun, Yireun Kim, Minjoon Seo.
https://arxiv.org/abs/2302.14691
指令调优是一种以自然语言指令格式在训练语料库中包含标记数据集的技术,该技术已被证明可以推广到训练任务之外的新任务,并在人类给出指令时使lm更可用。
本文研究了当在提示中这样做时会发生什么;给模型提供各种其他语言任务的例子,然后提示执行一个新的任务,而不是添加手头任务的例子(即少量学习)。这再次证明了非常复杂的信息可以通过上下文学习引入
5、How Good Are GPT Models at Machine Translation? A Comprehensive Evaluation
Amr Hendy, Mohamed Abdelrehim, Amr Sharaf, Vikas Raunak, Mohamed Gabr, Hitokazu Matsushita, Young Jin Kim, Mohamed Afify, and Hany Hassan Awadalla.
https://arxiv.org/abs/2302.09210
ChatGPT最不受重视的技能之一是翻译。论文将测试GPT模型的性能是否接近SOTA和传统机器翻译模型,并发现现有的神经机器翻译和基于GPT的翻译显示出互补的优势。
考虑到GPT 没有在并行语料库上进行训练,它避免了常见的缺陷,如噪声或低质量样本的数据记忆问题,或长尾错误,如物理单位或货币的翻译等。
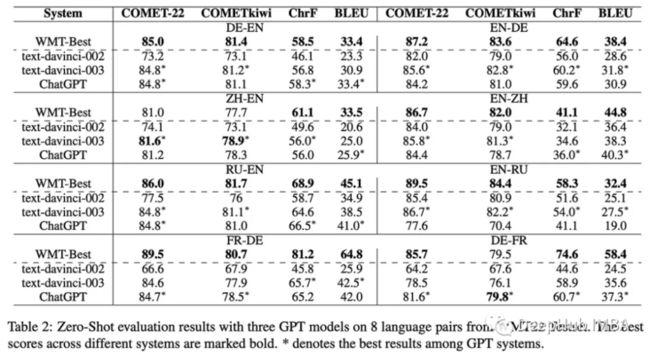
翻译性能在很大程度上来自于无监督的修饰、指令调优和RLHF,而RLHF并不是特别针对翻译的,但是取得的结果令人印象深刻和兴奋。
6、Composer: Creative and Controllable Image Synthesis with Composable Conditions
Lianghua Huang, Di Chen, Yu Liu, Yujun Shen, Deli Zhao, Jingren Zhou.
https://arxiv.org/abs/2302.09778
扩散模型的基本优势之一是在使用条件数据进行训练时的便利性,这就是为什么它们在文本引导中如此成功。这项工作将可控性提升到了一个新的高度。作者开发了一种方法,允许在图像生成过程中控制更广泛的图像属性:空间布局、调色板、风格、强度等。
组合性是该模型背后的核心思想,它将图像分解为具有代表性的因子,然后在这些因子的条件下使用扩散模型重新组合输入。图像分解的元素包括标题(文本)、语义和风格(通过CLIP嵌入)、颜色(通过直方图统计)、草图(通过边缘检测模型)、实例(对象分割)、深度图(通过预训练的单目模型)、强度(通过灰度图像)和掩蔽。图像生成可以根据所有这些属性进行调整,并且可以使用之前的输出作为新的条件输入进行迭代优化。

这项工作展示了如何设计图像生成技术来更多地控制人类的创造力,并提升创造过程。
8、Prismer: A Vision-Language Model with Multi-Modal Experts
Shikun Liu, Linxi Fan, Edward Johns, Zhiding Yu, Chaowei Xiao, Anima Anandkumar
https://arxiv.org/abs/2303.02506
专家系统的回归?这篇论文采用了一种相当结构化的多模态语言建模方法,并带来了一些令人信服的好处:
- 该论文采用结构化方法进行多模态语言建模,与其他模型相比,在减少一到两个数量级的数据的情况下实现了可比的性能。
- “专家”是指在处理图像时输出深度图或对象分割等信息的冻结计算机视觉模型。只有适配器经过训练,允许设计与其他黑盒视觉模型即插即用。
- 最大的 Prismer 模型有 1.6B 个参数,只有 360M 个可训练参数,性能低于大型模型但效率更高。
- Prismer 对带有噪声的“专家”表现出很强的鲁棒性,并随着更多/更高质量的专家而改进,表明它在大规模多模态学习中的实用性。


总的来说,本文提出了一种有效的技术,可以在不降低性能的情况下安全地包括许多模态专家,从而实现一种实用的方法来缩小多模态学习。
8、Augmented Language Models: a Survey
Grégoire Mialon, Roberto Dessì, Maria Lomeli, Christoforos Nalmpantis, Ram Pasunuru, Roberta Raileanu, Baptiste Rozière, Timo Schick, Jane Dwivedi-Yu, Asli Celikyilmaz, Edouard Grave, Yann LeCun, Thomas Scialom.
https://arxiv.org/abs/2302.07842
LM 在稳健推理和准确性方面的局限性是众所周知的,这就是为什么有一个活跃的研究领域通过计算设备来增强它们的能力, 例如,LM 使用编译和运行生成的代码,或调用任意 API 来收集数据。
检索增强生成 (RAG) 是最常见的案例之一(我们在我们的平台上使用它,Bing 和 Google 都在积极致力于此)。例如,这里有 4 个研究检索增强 LM(RAG)以及对比:
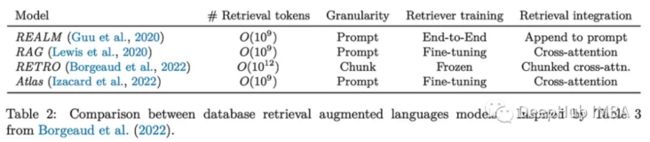
该调查提出的一个有趣的观点是,使用工具和显式结构增强lm使其更具可解释性,因为它们的输出可以显式地归因于其模块,这使它们更适合人类使用。
9、Symbolic discovery of optimization algorithms
Xiangning Chen, Chen Liang, Da Huang, Esteban Real, Kaiyuan Wang, Yao Liu, Hieu Pham, Xuanyi Dong, Thang Luong, Cho-Jui Hsieh, Yifeng Lu, Quoc V. Le.
https://arxiv.org/abs/2302.06675
Adam 一直是我们默认的优化器,Lion可以应用符号搜索来学习一个训练器函数,该函数输出给定权重、梯度和网络的学习率的更新权重值。这里的学习优化器不是通过梯度下降学习的,而是通过符号发现学习的。这种方法在论文中展示的实验中效果非常好,与Adam等优化器相比,可以实现大约2倍的训练速度。

Lion我们已经在前几天优化器的文章中介绍了,个人测试效果并不好,反正我现在是使用 LookaHead + RAdam,各位需要的话请自行测试。
10、 MarioGPT: Open-Ended Text2Level Generation through Large Language Models
Shyam Sudhakaran, Miguel González-Duque, Claire Glanois, Matthias Freiberger, Elias Najarro, Sebastian Risi.
https://arxiv.org/abs/2302.05981
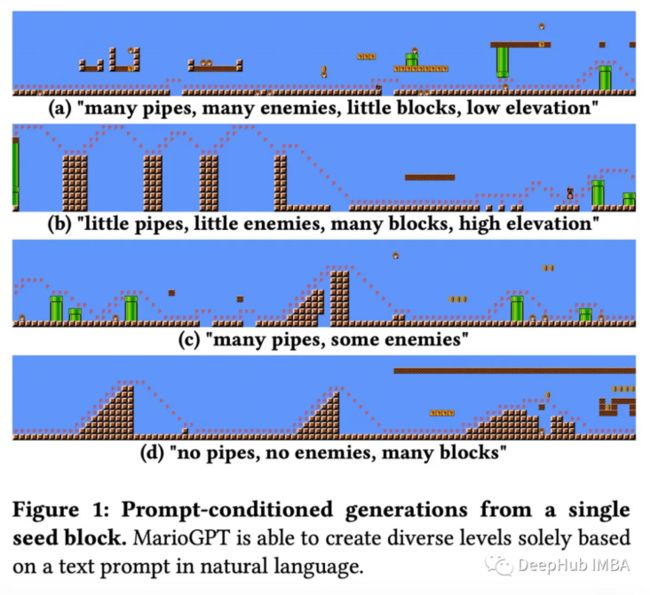
使用GPT-2生成马里奥兄弟世界。作者通过将《马里奥兄弟》中的元素标记成角色并训练基于文本提示的语言模型来实现程序内容生成(PCG,即基于算法生成游戏内容的想法)。
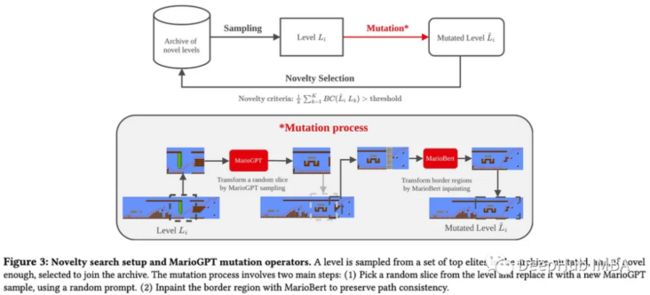
他们通过进化计算进一步增加了生成关卡的多样性,将MarioGPT嵌入到新奇搜索循环中,对现有关卡进行采样,更改,并应用选择标准来保留或丢弃它们。
结果关卡88%的时间是可玩的,并通过文本提示还可以提高可控性。这只是一个令人兴奋的开始,潜在的更具表现力和个性化的游戏体验!
https://avoid.overfit.cn/post/f1efb21c3ca54c9aa266aa9a623a42f6
作者:Sergi Castella i Sapé