提示学习soft prompt浅尝,启发了p-tuing
一、前言
在高质量标注数据稀缺的工业界来说,少样本学习或者零样本学习的方法特别受欢迎,后面出现过一些少样本和零样本的方法,例如对比学习和prompt等,主流prompt的工作分为离散型和连续型模板。离散型主要还是插入bert特殊的token为主,连续型则是插入数字token。离散型可解释性强于连续型,我这里讲的soft prompt则是连续型的。
大型预训练语言模型的规模不断扩大,在许多自然语言处理 (NLP) 基准测试中取得了最先进的结果。自GPT和BERT开发以来,标准做法一直是在下游任务上微调模型,这涉及调整网络中的每个权重(即模型调整)。然而,随着模型变得越来越大,为每个下游任务存储和提供模型的微调变得不切实际。
一个吸引人的替代方案是在所有下游任务中共享一个单一的冻结预训练语言模型,其中所有权重都是固定的。在一个令人兴奋的发展中,GPT-3令人信服地表明,可以通过“上下文”学习来调节冻结模型以执行不同的任务。使用这种方法,用户通过提示设计为给定任务准备模型,即手工制作带有手头任务描述或示例的文本提示。例如,要为情感分析设置模型,可以附加提示“以下电影评论是正面的还是负面的?” 在输入序列之前,“这部电影太棒了!”
二、soft prompt
跨任务共享相同的冻结模型极大地简化了服务并允许有效的混合任务推理,但不幸的是,这是以牺牲任务性能为代价的。文本提示需要人工设计,即使是精心设计的提示与模型调优相比仍然表现不佳。例如,在SuperGLUE基准测试中冻结的 GPT-3 175B 参数模型的性能比使用少 800 倍参数 的微调T5 模型低 5 个点。
在EMNLP 2021上发表的“参数高效提示调整的规模力量”中,我们探索了提示调整,一种使用可调软提示调节冻结模型的更有效方法。就像工程文本提示一样,软提示连接到输入文本。但不是从现有的词汇项目中选择,软提示的“标记”是可学习的向量。这意味着可以在训练数据集上端到端优化软提示。除了消除手动设计的需要之外,这还允许提示从包含数千或数百万个示例的数据集中压缩信息。相比之下,由于模型输入长度的限制,离散文本提示通常限制在 50 个以下示例。
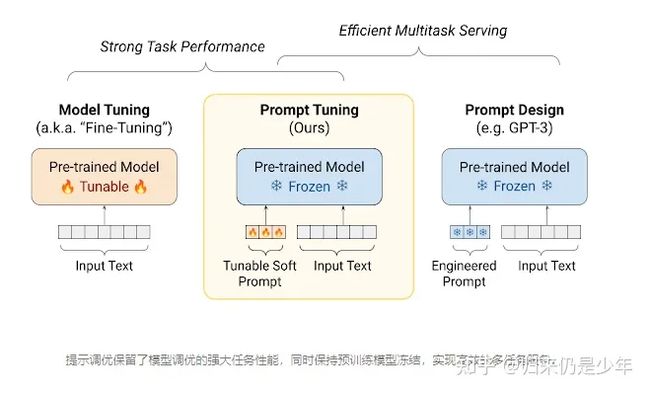
要为给定任务创建软提示,我们首先将提示初始化为固定长度的向量序列(例如,20 个token长)。我们将这些向量附加到每个嵌入输入的开头,并将组合序列输入模型。将模型的预测与目标进行比较以计算损失,并将误差反向传播以计算梯度,但是我们仅将这些梯度更新应用于我们的新可学习向量——保持核心模型冻结。虽然以这种方式学习的软提示不能立即解释,但在直观的层面上,软提示正在从标记的数据集中提取有关如何执行任务的证据,其作用与手动编写的文本提示相同,但不需要限于离散的语言。
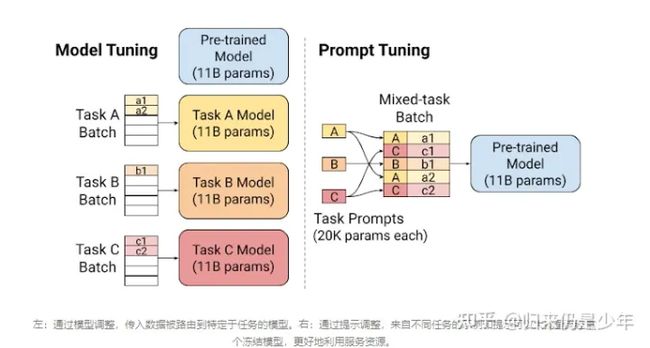
soft prompt是参数越多效果越好,引自Google发表原文。

三、soft prompt实现
import torch
import torch.nn as nn
class SoftEmbedding(nn.Module):
def __init__(self,
wte: nn.Embedding,
n_tokens: int = 10,
random_range: float = 0.5,
initialize_from_vocab: bool = True):
"""appends learned embedding to
Args:
wte (nn.Embedding): original transformer word embedding
n_tokens (int, optional): number of tokens for task. Defaults to 10.
random_range (float, optional): range to init embedding (if not initialize from vocab). Defaults to 0.5.
initialize_from_vocab (bool, optional): initalizes from default vocab. Defaults to True.
"""
super(SoftEmbedding, self).__init__()
self.wte = wte
self.n_tokens = n_tokens
self.learned_embedding = nn.parameter.Parameter(self.initialize_embedding(wte,
n_tokens,
random_range,
initialize_from_vocab))
def initialize_embedding(self,
wte: nn.Embedding,
n_tokens: int = 10,
random_range: float = 0.5,
initialize_from_vocab: bool = True):
"""initializes learned embedding
Args:
same as __init__
Returns:
torch.float: initialized using original schemes
"""
if initialize_from_vocab:
return self.wte.weight[:n_tokens].clone().detach()
return torch.FloatTensor(n_tokens, wte.weight.size(1)).uniform_(-random_range, random_range)
def forward(self, tokens):
"""run forward pass
Args:
tokens (torch.long): input tokens before encoding
Returns:
torch.float: encoding of text concatenated with learned task specifc embedding
"""
input_embedding = self.wte(tokens[:, self.n_tokens:])
learned_embedding = self.learned_embedding.repeat(input_embedding.size(0), 1, 1)
return torch.cat([learned_embedding, input_embedding], 1)from transformers import AutoConfig, AdamW, AutoTokenizer, AutoModel
import torch
import torch.nn as nn
from soft_embedding import SoftEmbedding
n_tokens = 20
initialize_from_vocab = True
tokenizer = AutoTokenizer.from_pretrained("nezha-base-wwm")
config = AutoConfig.from_pretrained("nezha-base-wwm", num_labels=num_class)
config.output_hidden_states = True # 需要设置为true才输出
model = AutoModel.from_pretrained(self.model_path, config=config)
s_wte = SoftEmbedding(model.get_input_embeddings(),
n_tokens=n_tokens,
initialize_from_vocab=initialize_from_vocab)
model.set_input_embeddings(s_wte)
inputs = tokenizer("May the force be", return_tensors="pt")
# need to pad attention_mask and input_ids to be full seq_len + n_learned_tokens
# even though it does not matter what you pad input_ids with, it's just to make HF happy
inputs['input_ids'] = torch.cat([torch.full((1,n_tokens), 50256), inputs['input_ids']], 1)
inputs['attention_mask'] = torch.cat([torch.full((1,n_tokens), 1), inputs['attention_mask']], 1)
outputs = model(**inputs)四、总结
soft prompt比较依赖于模型参数大小,更加适合零样本和小样本,如果用来大数据量下微调模型,效果可能会比普通微调差不多或者更差点。