【EfficientDet】《EfficientDet:Scalable and Efficient Object Detection》

CVPR-2020
文章目录
- 1 Background and Motivation
- 2 Related Work
- 3 Advantages / Contributions
- 4 Method
-
- 4.1 BiFPN
- 4.2 EfficientDet
- 5 Experiments
-
- 5.1 Datasets
- 5.2 EfficientDet for Object Detection
- 5.3 EfficientDet for Semantic Segmentation
- 5.4 Ablation Study
- 6 Conclusion(own)
1 Background and Motivation
现在的轻量级网络 only focus on a specific or a small range of resource requirements
Is it possible to build a scalable detection architecture with both higher accuracy and better efficiency across a wide spectrum of resource constraints.
本文在 efficientNet 的基础上,
- 提出 bi-directional feature pyramid network (BiFPN) ,双向特征金字塔
- 提出 compound scaling method,不仅 scale 主干,也同时 scale 特征金字塔,scale 头部检测器,
使得目标检测器(分割器)更快更准
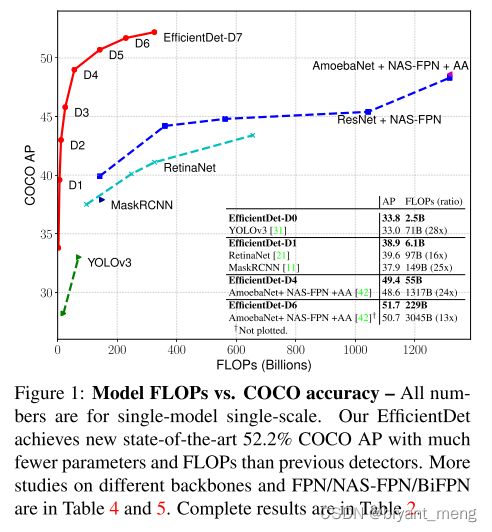
2 Related Work
- One-Stage Detectors
- Multi-Scale Feature Representations
- Model Scaling
3 Advantages / Contributions
- BiFPN
- compound scaling method(主干 / 金字塔 / 头)
4 Method
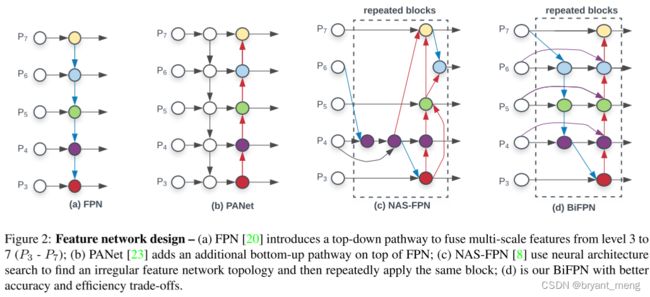
注意会 repeated
4.1 BiFPN
efficient bidirectional cross-scale connections and weighted feature fusion.

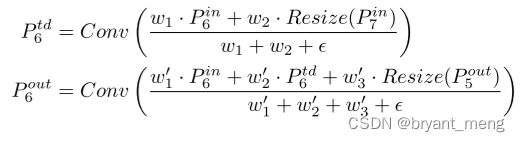
P 6 t d P_6^{td} P6td 表示 intermediate feature at level 6
特征图融合的时候做了加权,有如下两种方式
(1)Softmax-based fusion
O = ∑ i e w i ε + ∑ j e w j O = \sum_i \frac{e^{w_i}}{\varepsilon + \sum_j e^{w_j}} O=i∑ε+∑jewjewi
缺点速度比较慢
(2)Fast normalized fusion
O = ∑ i w i ε + ∑ j w j O = \sum_i \frac{w_i}{\varepsilon + \sum_j w_j} O=i∑ε+∑jwjwi
效果和 Softmax-based fusion 差不多,速度快很多
金字塔采用的卷积都是 depthwise separable convolution
4.2 EfficientDet

(1)EfficientDet Architecture
one-stage 的框架
金字塔会重复堆叠
(2)Compound Scaling
uses a simple compound coefficient φ to jointly scale up all dimensions of backbone network, BiFPN network, class/box network, and resolution.
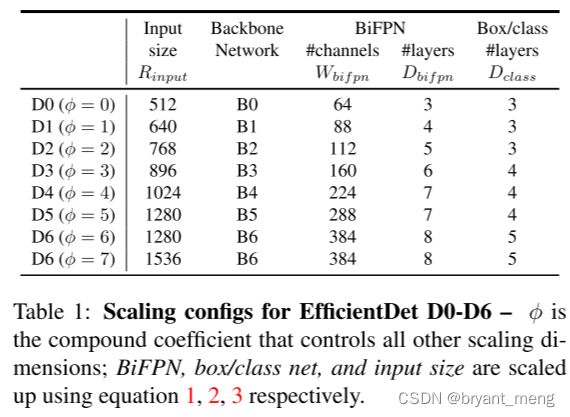
2.1 主干网络的缩放采用的是 EfficientNet 的 B0~B6
2.2 BiFPN network 的缩放规则是

W 表示 width,也即通道数,D 表示 depth,也即重复的次数
2.3 Box/class prediction network 的缩放规则是
W 同 BiFPN,

2.4 Input image resolution 的缩放规则是
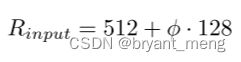
5 Experiments
5.1 Datasets
COCO
5.2 EfficientDet for Object Detection

速度

5.3 EfficientDet for Semantic Segmentation
use P2 for the final per-pixel classification

5.4 Ablation Study
COCO validation set
(1)Disentangling Backbone and BiFPN
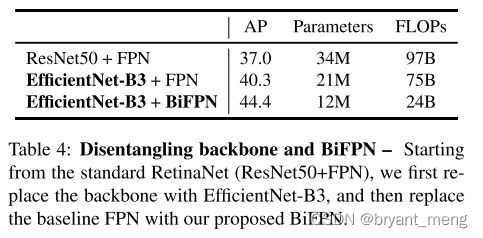
设计的 BiFPN 还是特别的猛
(2)BiFPN Cross-Scale Connections
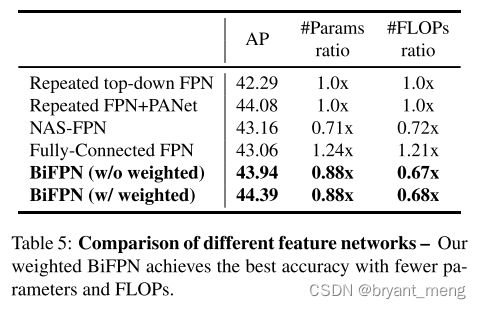
weighted + BiFPN 最猛
(3)Softmax vs Fast Normalized Fusion

效果仅差一点点,速度快了一些

横坐标应该是迭代次数,特征图融合的权重数值上(纵坐标)还是没有太大差异的
(4)Compound Scaling
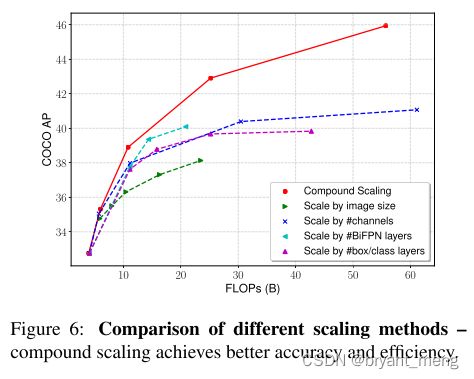
一起 scale 效果最好
6 Conclusion(own)
金字塔也可以堆叠
scale 也可以包含金字塔和头部结构一起