RLlib简介
参考:
https://ray.readthedocs.io/en/latest/rllib.html
https://zhuanlan.zhihu.com/p/79613212
https://blog.csdn.net/weixin_43255962/article/details/91628492
https://blog.csdn.net/u013166171/article/details/89139756
文章目录
- B站视频讲解
- 1. RLlib: 可扩展强化学习
-
- 1.1. custom env example
- 1.2. API documentation
- 1.3. concepts and custom algorithms
- 2. 一分钟熟悉RLlib
-
- 2.1. 运行RLlib
- 2.2. Policies
- 2.3. Samples
- 2.4. Training(对,没错,不是Trainer)
- 3. 定制化
B站视频讲解
《超强的强化学习系统怎么实现?Ray是啥?tune和rllib又是什么?》
https://www.bilibili.com/video/BV1VE411w73P?from=search&seid=7805537164306264282
超强的强化学习系统怎么实现?Ray是啥?tune和rllib又是什么?
1. RLlib: 可扩展强化学习
RLlib是一个开源强化学习库,提供了高度可扩展能力和不同应用的统一的API。RLlib原生支持Tensorflow,Tensorflow Eager,以及PyTorch,但其内部与这些框架无关。
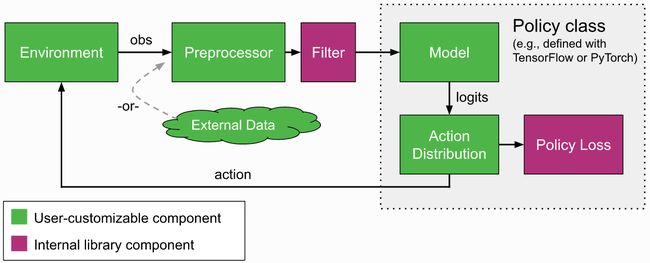
开始之前,请阅读custom env example和API documentation。 如果你想使用RLlib开发自定义算法,还请查看concepts and custom algorithms.
1.1. custom env example
https://github.com/ray-project/ray/blob/master/rllib/examples/custom_env.py
"""Example of a custom gym environment and model. Run this for a demo.
This example shows:
- using a custom environment
- using a custom model
- using Tune for grid search
You can visualize experiment results in ~/ray_results using TensorBoard.
"""
import numpy as np
import gym
from ray.rllib.models import ModelCatalog
from ray.rllib.models.tf.tf_modelv2 import TFModelV2
from ray.rllib.models.tf.fcnet_v2 import FullyConnectedNetwork
from gym.spaces import Discrete, Box
import ray
from ray import tune
from ray.rllib.utils import try_import_tf
from ray.tune import grid_search
tf = try_import_tf()
class SimpleCorridor(gym.Env):
"""Example of a custom env in which you have to walk down a corridor.
You can configure the length of the corridor via the env config."""
def __init__(self, config):
self.end_pos = config["corridor_length"]
self.cur_pos = 0
self.action_space = Discrete(2)
self.observation_space = Box(
0.0, self.end_pos, shape=(1, ), dtype=np.float32)
def reset(self):
self.cur_pos = 0
return [self.cur_pos]
def step(self, action):
assert action in [0, 1], action
if action == 0 and self.cur_pos > 0:
self.cur_pos -= 1
elif action == 1:
self.cur_pos += 1
done = self.cur_pos >= self.end_pos
return [self.cur_pos], 1 if done else 0, done, {}
class CustomModel(TFModelV2):
"""Example of a custom model that just delegates to a fc-net."""
def __init__(self, obs_space, action_space, num_outputs, model_config,
name):
super(CustomModel, self).__init__(obs_space, action_space, num_outputs,
model_config, name)
self.model = FullyConnectedNetwork(obs_space, action_space,
num_outputs, model_config, name)
self.register_variables(self.model.variables())
def forward(self, input_dict, state, seq_lens):
return self.model.forward(input_dict, state, seq_lens)
def value_function(self):
return self.model.value_function()
if __name__ == "__main__":
# Can also register the env creator function explicitly with:
# register_env("corridor", lambda config: SimpleCorridor(config))
ray.init()
ModelCatalog.register_custom_model("my_model", CustomModel)
tune.run(
"PPO",
stop={
"timesteps_total": 10000,
},
config={
"env": SimpleCorridor, # or "corridor" if registered above
"model": {
"custom_model": "my_model",
},
"vf_share_layers": True,
"lr": grid_search([1e-2, 1e-4, 1e-6]), # try different lrs
"num_workers": 1, # parallelism
"env_config": {
"corridor_length": 5,
},
},
)
1.2. API documentation
https://ray.readthedocs.io/en/latest/rllib-toc.html
1.3. concepts and custom algorithms
https://ray.readthedocs.io/en/latest/rllib-concepts.html
2. 一分钟熟悉RLlib
The following is a whirlwind overview of RLlib. For a more in-depth guide, see also the full table of contents and RLlib blog posts. You may also want to skim the list of built-in algorithms. Look out for the tensorflow and pytorch icons to see which algorithms are available for each framework.
2.1. 运行RLlib
RLlib需要依赖上层ray,所以首先需要安装PyTorch或者Tensorflow,然后安装RLlib,
pip install ray[rllib] # also recommended: ray[debug]
然后执行
rllib train --run=PPO --env=CartPole-v0
或者等价的
from ray import tune
from ray.rllib.agents.ppo import PPOTrainer
tune.run(PPOTrainer, config={"env": "CartPole-v0"}) # "log_level": "INFO" for verbose,
# "eager": True for eager execution,
# "torch": True for PyTorch
如果开始训练了,会打印results和status,
Result for PPO_CartPole-v0_0:
custom_metrics: {}
date: 2019-08-24_18-49-14
done: false
episode_len_mean: 197.11
episode_reward_max: 200.0
episode_reward_mean: 197.11
episode_reward_min: 53.0
episodes_this_iter: 20
episodes_total: 443
experiment_id: e03973024c8d4d9e808f6fd5952cd4de
hostname: yang-XPS-15-9570
info:
grad_time_ms: 1409.056
learner:
default_policy:
cur_kl_coeff: 0.01875000074505806
cur_lr: 4.999999873689376e-05
entropy: 0.516711950302124
entropy_coeff: 0.0
kl: 0.002535391366109252
policy_loss: -0.00021844537695869803
total_loss: 310.5483093261719
vf_explained_var: 0.439888060092926
vf_loss: 310.54852294921875
load_time_ms: 0.905
num_steps_sampled: 44000
num_steps_trained: 43648
sample_time_ms: 1174.697
update_time_ms: 2.682
iterations_since_restore: 11
node_ip: 183.172.155.88
num_healthy_workers: 2
off_policy_estimator: {}
pid: 3071
policy_reward_mean: {}
sampler_perf:
mean_env_wait_ms: 0.041131808772434005
mean_inference_ms: 0.48330258724109676
mean_processing_ms: 0.08932465366594158
time_since_restore: 30.216412782669067
time_this_iter_s: 2.5869903564453125
time_total_s: 30.216412782669067
timestamp: 1566643754
timesteps_since_restore: 44000
timesteps_this_iter: 4000
timesteps_total: 44000
training_iteration: 11
trial_id: bc206cee
== Status ==
Using FIFO scheduling algorithm.
Resources requested: 3/12 CPUs, 0/1 GPUs
Memory usage on this node: 4.8/33.3 GB
Result logdir: /home/yang/ray_results/PPO
Number of trials: 1 ({'RUNNING': 1})
RUNNING trials:
- PPO_CartPole-v0_0: RUNNING, [3 CPUs, 0 GPUs], [pid=3071], 30 s, 11 iter, 44000 ts, 197 rew
并且会默认在~/ray_results文件夹下保存该次训练超参数、训练过程、参数、结果等数据文件。
下面介绍RLlib中的三个重要概念:Policies, Samples, and Trainers.
2.2. Policies
Policies是 RLlib中的核心概念,简单来说,policies是python一个类,定义了智能体如何在环境中行动。Rollout workers根据policy来决定智能体的动作。在gym环境中,只有一个单独的智能体和策略。在向量环境中(一个策略,多个智能体),policy同时为多个智能体提供动作。在多智能体环境中,可能有不只一个策略,每个策略控制一个或多个智能体:

策略可以用任何框架实现。对于TensorFlow和PyTorch,rllib有build_tf_policy和build_torch_policy这两个函数,帮你用函数化的API来定义训练策略,例如:
def policy_gradient_loss(policy, model, dist_class, train_batch):
logits, _ = model.from_batch(train_batch)
action_dist = dist_class(logits, model)
return -tf.reduce_mean(
action_dist.logp(train_batch["actions"]) * train_batch["rewards"])
# 2.3. Samples
不管程序运行在单进程或者大规模集群上,RLLib所有的数据交换都以sample batches的形式进行。Sample batches编码一条轨迹的一个或多个碎片。通常,RLlib从rollout worker收集rollout_fragment_length大小的batch,将这些batch级联成一个大小为 train_batch_size 的batch送入优化器。
典型的sample batch如下所示,所有值以array形式储存,允许高效的编码和网络之间的转移。
{ 'action_logp': np.ndarray((200,), dtype=float32, min=-0.701, max=-0.685, mean=-0.694),
'actions': np.ndarray((200,), dtype=int64, min=0.0, max=1.0, mean=0.495),
'dones': np.ndarray((200,), dtype=bool, min=0.0, max=1.0, mean=0.055),
'infos': np.ndarray((200,), dtype=object, head={}),
'new_obs': np.ndarray((200, 4), dtype=float32, min=-2.46, max=2.259, mean=0.018),
'obs': np.ndarray((200, 4), dtype=float32, min=-2.46, max=2.259, mean=0.016),
'rewards': np.ndarray((200,), dtype=float32, min=1.0, max=1.0, mean=1.0),
't': np.ndarray((200,), dtype=int64, min=0.0, max=34.0, mean=9.14)}
在多智能体模式,每个policy分别收集sample batch
2.4. Training(对,没错,不是Trainer)
Policies each define a learn_on_batch() method that improves the policy given a sample batch of input. For TF and Torch policies, this is implemented using a loss function that takes as input sample batch tensors and outputs a scalar loss. Here are a few example loss functions:
- Simple policy gradient loss
- Simple Q-function loss
- Importance-weighted APPO surrogate loss
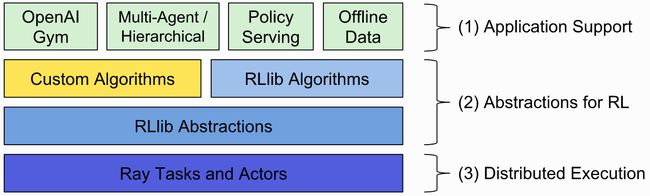
RLlib的 Trainer类用来统筹规划分布式的rollout和策略优化。这是通过选择恰当的policy optimizer来实现相应的计算模式。下图是最简化的同步采样。

RLlib使用Ray actors从单核训练拓展到集群的多核训练。你能通过改变num_workers这个参数来配置并行程度。
3. 定制化
RLlib提供了自定义训练的方法,包括环境,神经网络模型,动作分布,和策略定义。