Oracle 查询优化改写(第五章)
第五章 使用字符串
1.遍历字符串

SELECT '天天向上' 内容,level,substr('天天向上', LEVEL, 1) 汉字拆分
FROM Dual
CONNECT BY LEVEL <= Length('天天向上');
2.计算字符在字符串中出现的次数


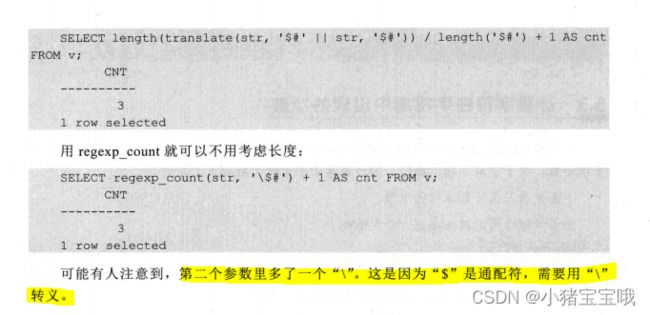
3.从字符中删除不需要的字符
若员工姓名有元音字母AEIOU,现在要求把这写元音字母去掉。
SELECT 'aAbcdef', Translate('abcdef', '1AEIOUaeiou', '1') FROM Dual;
SELECT 'aAbcdef', Regexp_Replace('abcdef', '[AEIOUaeiou]') FROM Dual;

将字符和数字数据分离也可以通过regexp_replace分离:
regexp_replace(data,'[0-9],'') 字符
regexp_replace(data,'[^0-9],'') 数字

4.正则表达式 regexp_like


4.1^和$的含义

4.2+和*的含义
![]()

4.3 ^和$与+和*联合使用

5.提取姓名的大写字母缩写


6.按字符串中的数值排序

7. 根据表中的行创建一个分割列表
SELECT Deptno,
SUM(Sal) AS Total_Sal,
Listagg(Ename, ',') Within GROUP(ORDER BY Ename) AS Total_Name
FROM Emp
GROUP BY Deptno;

8.提取第n个分隔的子串
--function REGEXP_SUBSTR(String, pattern, position, occurrence, modifier)
--参数二:-^在方括号里表示否的意思,+表示匹配1次以上,[^,]+表示匹配不包含逗号的多个字符。
--参数三:1表示从第一个字符开始。
--参数四:2表示第二个能匹配'[^,]+'的字符串。
--参数五:模式(‘i’不区分大小写进行检索;‘c’区分大小写进行检索。默认为’c’)针对的是正则表达式里字符大小写的匹配
SELECT Regexp_Substr(Total_Name, '[^,]+', 1, 2) AS 第二个子串
FROM (SELECT Listagg(Ename, ',') Within GROUP(ORDER BY Ename) AS Total_Name
FROM Emp);
9.分解IP的地址
--分解ip地址192.168.1.1
SELECT Regexp_Substr(Ip, '[^.]+', 1, 1) AS a,
Regexp_Substr(Ip, '[^.]+', 1, 2) AS b,
Regexp_Substr(Ip, '[^.]+', 1, 3) AS c,
Regexp_Substr(Ip, '[^.]+', 1, 4) AS d
FROM (SELECT '192.168.1.1' AS Ip FROM Dual);
10.将分隔数据转换为多值in列表


DECLARE
CURSOR c_Emps(v_Emps VARCHAR2) IS
SELECT *
FROM Emp
WHERE Ename IN
(SELECT Regexp_Substr(v_Emps, '[^,]+', 1, LEVEL) AS Ename
FROM Dual
CONNECT BY LEVEL <=
Length(Translate(v_Emps, ',' || v_Emps, ',')) + 1);
c_Emp_Rec c_Emps%ROWTYPE;
BEGIN
OPEN c_Emps('&InputString');
LOOP
FETCH c_Emps
INTO c_Emp_Rec;
EXIT WHEN c_Emps%NOTFOUND;
Dbms_Output.Put_Line(c_Emp_Rec.Ename);
END LOOP;
END;
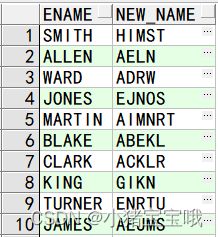
11.按字母顺序排列字符串
SELECT Ename,
(SELECT Listagg(Substr(Ename, LEVEL, 1))
Within GROUP(ORDER BY Substr(Ename, LEVEL, 1))
FROM Dual
CONNECT BY LEVEL <= Length(Ename)) AS New_Name
FROM Emp;

SELECT Ename,
(SELECT Listagg(min(Substr(Ename, LEVEL, 1)))
Within GROUP(ORDER BY (Substr(Ename, LEVEL, 1)))
FROM Dual
CONNECT BY LEVEL <= Length(Ename)
GROUP BY Substr(Ename, LEVEL, 1)) AS New_Name
FROM Emp;
12.判别可作数值的字符串






