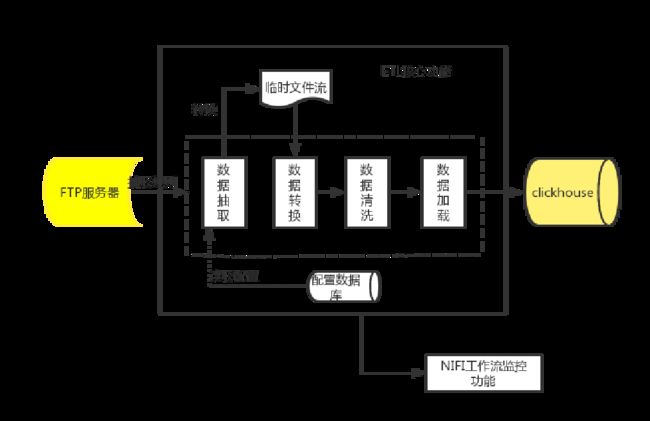
NIFI-实现从FTP服务器拉取文件入到clickhouse数据库
一、需求梳理:
1、从FTP服务器上拉取文件(文件名按照固定格式命名)。
2、提取文件名上的一些字符串信息合并到数据流中,入库。
3、替换文件流中的一些字段值。
实现ETL的功能,其流程图如下:
NIFI处理器的选择:
| 处理器 |
主要功能 |
| ListFTP |
列出服务器文件列表 |
| FetchFTP |
根据列表拉取数据 |
| UpdateAttribute |
新增流文件属性 |
| UpdateRecord |
新增流文件内容或路由逻辑 |
| MergeRecord |
文件流纵向合并 |
| MergeContent |
文件流横向合并 |
| QueryRecord |
从合并流文件中查询结果 |
| InvokeHTTP |
结果数据入库 |
| RouteOnAttribute |
路由结果数据 |
| HashContent |
释放掉结果数据 |
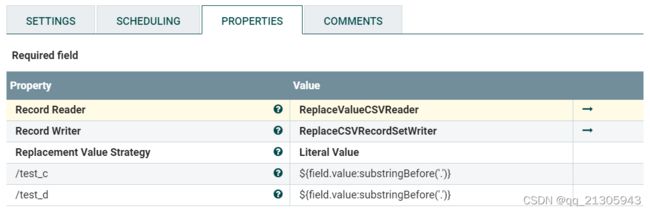
二、文件流数据替换
选用UpdateRecord处理器、选用Schema Text格式。
{
"type":"record",
"name":"nifiRecord",
"namespace":"org.apache.nifi",
"fields":[
{
"name":"test_a",
"type":[
"null",
"string"
]
},
... {"name":"test_e",
"type":["null"
]"string"]
}] }
三、从FTP拉取csv文件
监控FTP服务器:ListFTP处理器
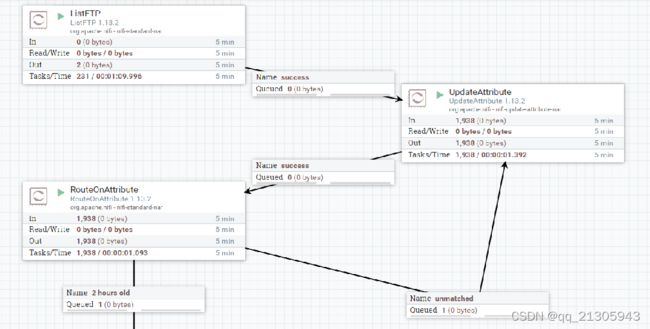
拉取FTP服务器两个小时之后的数据:新增路由规则
ListFTP-> UpdateAttribute-> RouteOnAttribute-> FetchFTP
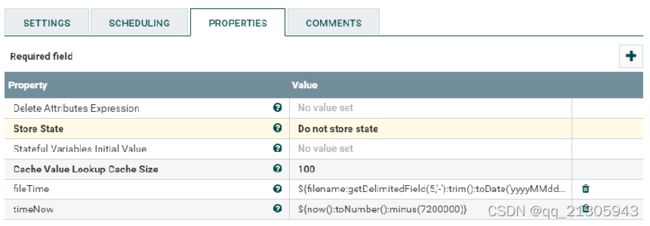
新增自定义属性:UpdateAttribute处理器
fileTime: ${filename:getDelimitedField(5,'-'):trim():toDate('yyyyMMddHHmmss'):toNumber()} timeNow: ${now():toNumber():minus(7200000)}
延时拉取方案实现:
2 hours old ${fileTime:le(${timeNow})}
四、文件实现纵向合并
1、将文件格式转为avro数据格式(avro数据格式在大量数据合并时效率高):updateRecord处理器
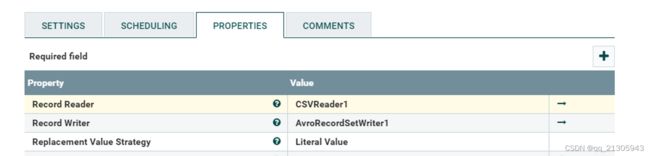
2、文件合并:MergeRecord处理器
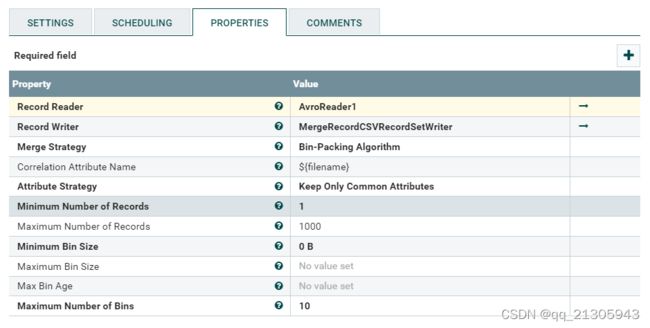 3、AvroReader控制器服务:通过 Schema Name 和定义的Avro格式的数据字段连接映射关系。
3、AvroReader控制器服务:通过 Schema Name 和定义的Avro格式的数据字段连接映射关系。
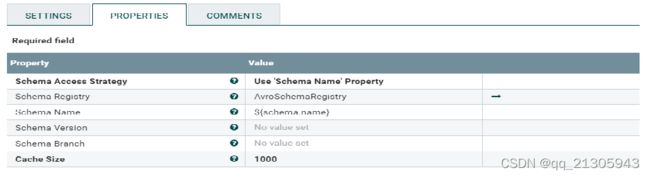
AvroSchemaRegistry 的配置:

dafafile字段值包含性能文件和设备信息文件数据的所有的字段:
{
"name":"datafile",
"type":"record",
"fields":[
{
"name":"d",
"type":"string"
},
{
"name":"xxx",
"type":[
"null",
"string"
]
},
...... { "name": "data_update_time",
"type": ["null"
]"string"]
}]}五、从合并后的flowfile中查询结果:QueryRecord处理器
新增路由关系:query 读控制器服务:AvroReader 写控制器服务:CSVRecordSetWriter
查询语句:

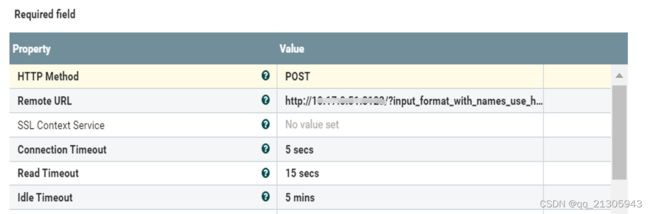
六、clickhouse入库:InvokeHTTP处理器
HTTP请求方式:POST
配置clickhouse入库方式:用|分割的方式入库
http://ip:port/?input_format_with_names_use_header=0&format_csv_delimiter=%7C&query=INSERT INTO 库名.表名 FORMAT CSVWithNames
七、单机版本测试
一个34M大小的csv文件、合并、提取1000个字段。从服务器拉取文件到实现文件纵向、入库整个流程用时1分半。
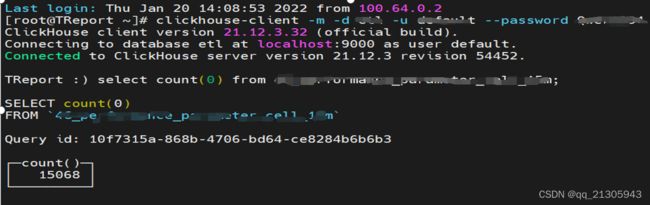
10万行888个字段的340M的csv大小文件,转为avro后数据451,整个流程用时15分钟左右。

结论:对于大数据量计算,目前nifi在ETL中的性能瓶颈在QueryRecord中从大量的Avro格式的数据中查找部分数据,存在较大的计算量,用时较多。
八、版本控制
NiFi 中,其实是可以对一组Data Pipieline 来做一个『版本控制』,就类似于git 一样,git 可以将每次修改好的版本commit 出去且push 到Github 或Gitlab 平台上对应的respository。那NiFi 是如何做到的呢?答案是今天的主角- NiFi Registry。 使用 NiFi Registry 在 Apache NiFi 中自动化工作流部署 可以在多个环境下切换。 参考资料:https://ithelp.ithome.com.tw/articles/10266633 https://pierrevillard.com/2018/04/09/automate-workflow-deployment-in-apache-nifi-with-the-nifi-registry/
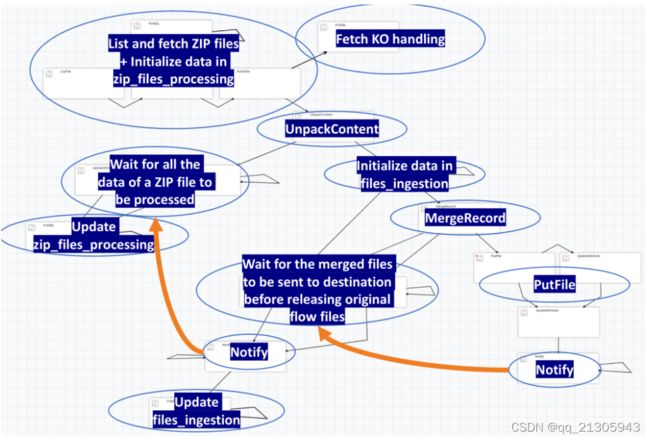
九、NiFi 工作流监控 – 带有拆分和合并的等待/通知模式
考虑到当文件数量较大时,监控ETL合并及入库的情况,参考nifi的等待/通知模式,构思监控性能文件、设备文件合并日志,及入库clickhouse的日志记录信息。 参考资料:https://pierrevillard.com/2018/06/27/nifi-workflow-monitoring-wait-notify-pattern-with-split-and-merge/
十、了解 NiFi 的内容存储库归档的工作原理
参考资料: https://community.cloudera.com/t5/Community-Articles/Understanding-how-NiFi-s-Content-Repository-Archiving-works/ta-p/249418 https://community.cloudera.com/t5/Support-Questions/Need-to-restart-Nifi-1-13-2-to-clean-content-repository/td-p/316610
配置文件:nifi.properties和bootstrap.conf